

Imagine this scenario:
You asked an AI agent to fix a code bug. It opened the project, read 20 files, made some changes, ran the tests—they failed. It made more changes, ran the tests again—they still failed. After more than a dozen iterations, it still couldn’t fix it.
You shut down your computer and sighed in relief. Then you received the API invoice.
The numbers above might make you gasp—on overseas official APIs, an AI Agent autonomously fixing bugs often consumes over a million tokens per unpatched task, costing tens to over a hundred dollars.
In April 2026, a research paper jointly published by Stanford, MIT, the University of Michigan, and others for the first time systematically opened the "black box" of AI Agent spending on coding tasks—revealing where the money was spent, whether it was worth it, and whether costs could be predicted in advance—with surprising results.
Finding 1: The cost of having an agent write code is 1,000 times higher than that of a regular AI conversation.
You might think that paying AI to write code for you costs about the same as paying AI to chat with you about code.
The paper presents a comparative display showing:
The token consumption for agentic coding tasks is approximately 1,000 times that of standard code Q&A and code reasoning tasks.
Three full orders of magnitude apart.
Why is this the case? The paper highlights a fact—money is not spent on "writing code," but on "reading code."
Here, "reading" does not refer to humans reading code, but rather to the Agent continuously feeding the model the entire project context, historical operation logs, error messages, and file contents during its workflow. With each additional conversation round, this context grows longer; and since the model is billed based on the number of tokens, the more you feed it, the more you pay.
For example, it’s like hiring a mechanic who, before turning each wrench, requires you to read aloud the entire building’s blueprints from start to finish—the cost of reading the blueprints far exceeds the cost of tightening the bolts.
The paper summarizes this phenomenon in one sentence: The cost of driving Agent is due to the exponential growth of input tokens, not output tokens.
Finding two: Running the same bug twice can result in costs differing by a factor of two—and the more expensive the bug, the more unstable it tends to be.
What’s even more frustrating is the randomness.
Researchers ran the same agent on the same task four times and found:
- Between different tasks, the most expensive task burns approximately 7 million more tokens than the cheapest task (Figure 2a).
- Across multiple runs of the same model and task, the most expensive run was approximately twice the cost of the cheapest run (Figure 2b).
- When comparing the same task across different models, the highest and lowest consumption can differ by up to 30 times.
The last number is particularly noteworthy: it means the cost difference between choosing the right model and the wrong one isn't just "a little more expensive," but an order of magnitude higher.
Even more sobering—spending more doesn’t mean doing better.
The paper found a "U-shaped" curve:
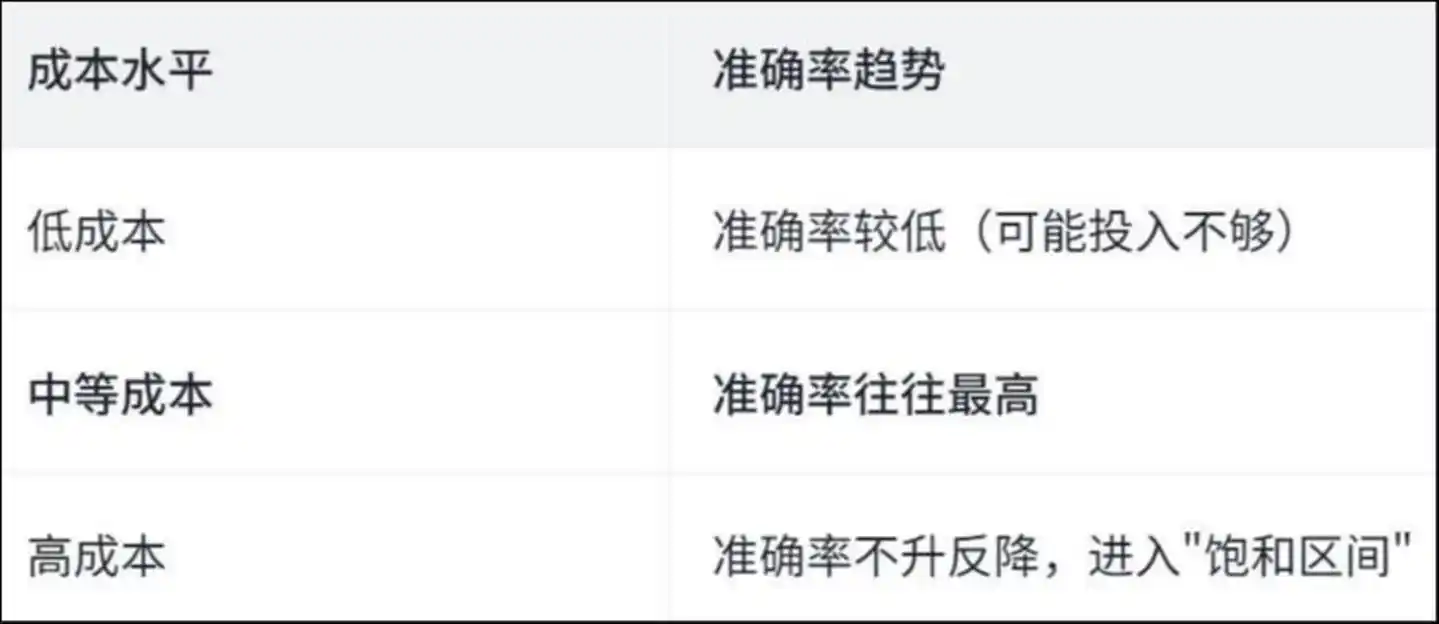
Cost level accuracy trend: Low cost yields lower accuracy (possibly due to insufficient investment); medium cost often achieves the highest accuracy; high cost sees no further improvement or even a decline, entering a "saturation zone."
Why is this the case? The paper provides the answer by analyzing the specific actions of the Agent—
In high-cost operations, agents spend a significant amount of time on "repetitive tasks."
Research shows that in high-cost operations, about 50% of file views and file modifications are redundant—meaning the Agent repeatedly reads the same file and modifies the same line of code, like a person spinning in circles inside a room, growing more dizzy the more they spin.
The money wasn't spent on solving the problem—it was spent on getting lost.
Finding Three: There is a huge difference in "energy efficiency" between models—GPT-5 is the most efficient, while some models consume up to 1.5 million additional tokens.
The paper evaluated the performance of eight state-of-the-art large models' agents on SWE-bench Verified, a industry-standard benchmark consisting of 500 real GitHub issues. In monetary terms, models with higher token efficiency can afford to spend tens of dollars more per task. In enterprise applications—where hundreds of tasks are run daily—this difference translates into real financial impact.
An even more interesting finding is that token efficiency is an "inherent trait" of the model, not a result of the task.
Researchers isolated the tasks that all models solved successfully (230 tasks) and the tasks that all models failed (100 tasks) for comparison, finding that the relative rankings of the models changed very little.
This indicates that some models are inherently more verbose, regardless of task difficulty.
Another thought-provoking finding: the model lacks "stop-loss awareness."
When faced with difficult tasks that no model can solve, an ideal agent should give up early rather than continue wasting resources. But in reality, models commonly consume more tokens on failed tasks—they don’t “quit,” instead persistently exploring, retrying, and rereading context, like a car without a fuel warning light driving until it breaks down.
Finding Four: What humans find difficult isn't necessarily expensive for an Agent—the perception of difficulty is completely misaligned.
You might think: At least I can estimate the cost based on the difficulty of the task?
The paper enlisted human experts to rate the difficulty of 500 tasks and then compared these ratings with the actual token consumption of the Agent.
Result: There is only a weak correlation between the two.
Tasks that humans find extremely difficult might be easily and cheaply handled by an agent; meanwhile, tasks that humans think are simple might cause an agent to burn through massive resources.
This is because the difficulty perceived by humans and AI is fundamentally different:
- Humans consider: logical complexity, algorithmic difficulty, and barriers to business understanding.
- The agent considers: how large the project is, how many files need to be read, how long the exploration path is, and whether the same file will be modified repeatedly.
A human expert might think a bug requires fixing just one line, but an agent may first need to understand the entire codebase’s structure to locate that line—simply “reading” it consumes a large number of tokens. Meanwhile, an algorithm problem that a human finds confusingly complex might be exactly the kind an agent recognizes as having a standard solution, resolving it quickly and easily.
This leads to an awkward reality: developers find it nearly impossible to intuitively estimate the operating cost of an Agent.
Finding five: Even the model can't accurately predict how much it will cost itself.
Since humans can't predict accurately, why not let AI predict on its own?
Researchers designed a clever experiment: before actually fixing the bug, the Agent first "inspects" the codebase and estimates how many tokens it would consume—without actually performing the fix.
How did it turn out?
All models have failed.
The best performance was Claude Sonnet-4.5, with a prediction correlation of 0.39 for output tokens (out of a maximum of 1.0). Most models had prediction correlations between 0.05 and 0.34, with Gemini-3-Pro performing the worst at just 0.04—essentially equivalent to random guessing.
Even more striking: all models systematically underestimated their token consumption. In the scatter plot in Figure 11, nearly all data points fall below the “perfect prediction” line—the models believed they would use fewer tokens than they actually did. Moreover, this underestimation bias is even more pronounced when no examples are provided.
More ironically—the prediction itself costs money.
The prediction cost of Claude Sonnet-3.7 and Sonnet-4 can be more than twice the cost of the task itself—meaning it’s more expensive to have them estimate the price than to simply perform the task directly.
The paper's conclusion is straightforward:
At this stage, advanced models cannot accurately predict their own token usage. Clicking “Run Agent” is like opening a blind box—you won’t know the cost until the bill arrives.
Behind this "confusing ledger" lies a larger industry issue.
At this point, you might be wondering: What do these findings mean for businesses?
The "monthly subscription" pricing model is being cracked open by Agents.
The paper points out that subscription models like ChatGPT Plus are viable because token consumption for ordinary conversations is relatively controllable and predictable. However, agent tasks completely break this assumption—a single task could consume massive amounts of tokens if the agent gets stuck in a loop.
This means that pure subscription pricing may not be sustainable for Agent scenarios, and pay-as-you-go will remain the most practical option for the foreseeable future. However, the issue with pay-as-you-go is that usage itself is unpredictable.
2. Token efficiency should be the "third metric" for model selection.
Traditionally, companies evaluate models based on two dimensions: capability (whether they can do it) and speed (how quickly they can do it). This paper introduces a third equally important dimension: energy efficiency (how much it costs to accomplish it).
A model that is slightly less capable but three times more efficient may have greater economic value in scalable scenarios than the "strongest but most expensive" model.
3. The agent needs a "fuel gauge" and a "brake"
The paper highlights a noteworthy future direction: budget-aware tool-use policies. In simple terms, this means giving the agent a "fuel gauge"—when token consumption approaches the budget, it is forced to stop unproductive exploration rather than continuing to exhaust resources.
Currently, almost all major agent frameworks lack this mechanism.
The agent's "burning money problem" is not a bug, but an inevitable pain point in the industry.
The paper reveals not a flaw in a specific model, but a structural challenge inherent to the Agent paradigm—when AI evolves from “one-question, one-answer” interactions to autonomous planning, multi-step execution, and iterative refinement, unpredictable token consumption becomes almost inevitable.
The good news is that this is the first time someone has systematically uncovered and analyzed this financial ambiguity. With this data, developers can make more informed decisions about model selection, budgeting, and designing stop-loss mechanisms; model providers also have a new optimization target—not just building stronger models, but also more cost-efficient ones.
After all, before AI agents truly enter production environments across industries, spending every dollar wisely is more important than writing every line of code beautifully. (This article was first published on the Titanium Media APP, author | Silicon Valley Tech News, editor | Zhao Hongyu)
Note: This article is based on the preprint paper *How Do AI Agents Spend Your Money? Analyzing and Predicting Token Consumption in Agentic Coding Tasks* (Bai, Huang, Wang, Sun, Mihalcea, Brynjolfsson, Pentland, Pei), published on arXiv on April 24, 2026. The authors are affiliated with institutions including the University of Virginia, Stanford University, MIT, and the University of Michigan. This research has not yet undergone peer review.