









The model is the brain of OpenClaw and directly impacts its performance.
Author: Zhang Haining
Source: Henry's Notes
I recently tried various methods to install and deploy OpenClaw, including physical machines, cloud servers, virtual machines, containers, and models and networks both domestically and internationally. Overall, the process is quite complex and involves many factors to consider. I plan to write a comprehensive article summarizing these insights. This piece serves as a prelude, focusing first on a critical aspect: model selection.
The model is the brain of OpenClaw and directly impacts its performance. Currently, there is a consensus that overseas models are somewhat more intelligent than domestic ones. However, overseas models require a scientific internet connection, come at a higher cost, and necessitate overseas payment methods—any misstep may result in account suspension. Even though intermediary services offer more affordable options, they operate in a gray area and carry inherent uncertainties. As a result, users prioritizing stable service typically opt for domestic models.
This article compares the usage and pricing of various models domestically and provides some recommendations for reference.
After OpenClaw, an open-source AI agent framework, rapidly gained popularity in China, it brought about a productivity revolution alongside startlingly high bills.
OpenClaw operates fundamentally differently from conversational AI in traditional browsers or apps. After a user issues a command, the tool autonomously triggers dozens or even hundreds of model calls, reading files, generating code, and debugging execution—all of which consume tokens throughout the entire process.
A moderately complex full-stack development task may involve 10 to 40 model calls; using a flagship model that supports 200K context, the cost per task can easily reach several dozen yuan.
📊 Real Cost Calculation
As an example of a moderately complex task: OpenClaw triggers approximately 30 rounds of conversation, with an average input of 20,000 tokens and output of 2,000 tokens per round, using a mainstream model (approximately ¥0.005 per 1,000 input tokens and ¥0.02 per 1,000 output tokens):
Single-task cost ≈ 30 × (20,000 × 0.005 ÷ 1000 + 2,000 × 0.02 ÷ 1000) = 30 × (0.1 + 0.04) = 4.2 CNY
Serious developers complete 5 to 10 tasks per day, with monthly costs ranging from 630 to 1,260 yuan. This estimate is based on mid-tier models; using flagship models would double the cost.
Against this backdrop, China’s leading cloud providers and large model companies collectively entered the market between late 2025 and March 2026, launching subscription plans called "Coding Plans" that replace token-based pricing with fixed monthly fees. The price war began when Zhipu AI率先 launched the GLM Coding Plan in late 2025, followed by Alibaba Cloud’s Bailian entering with an aggressively low introductory rate of 7.9 yuan for the first month, and Tencent Cloud completing the final piece of the puzzle on March 5, 2026.
This article systematically compares the coding plans of China’s six major platforms, organized along two main lines: cloud providers (Alibaba Cloud Bailian, ByteDance Volcano Ark, Tencent Cloud) and model providers (Zhipu GLM, Kimi Moonshot, MiniMax), to provide guidance for OpenClaw users.
OpenClaw requires a Coding Plan. Yes, the same usage model as programmers use with IDEs like Cursor or Trae, because OpenClaw and tools like Cursor are essentially agents. If you don’t purchase the Coding Plan (commonly referred to as an API internationally), your funds can only be used for browser-based access to large models.
(Foreign models are outside the scope of this article)
Cloud service provider
The three major cloud providers: The battle of the model marketplace
The core logic of cloud provider offerings is "aggregation platform": bundling multiple open-source large models—such as Qwen, GLM, Kimi, and MiniMax—into a single package, allowing developers to switch freely between them using just one API key, without needing to recharge on multiple platforms separately. These packages are billed in units of "requests," not prompts, making the numbers appear larger, but they must be converted to actual usage for accurate comparison.
The specific details of the three cloud providers are as follows:



Large model providers
Top three model providers: Specialized in depth
Unlike cloud providers’ “model marketplaces,” the model vendor-type Coding Plan follows a “specialty store” approach: offering only their own models, but with deep optimization and more refined design of model capabilities and quota allocation. These plans typically use “Prompts” as the unit of measurement, where 1 Prompt ≈ 15 model calls (based on MiniMax’s estimation), making the numbers appear much smaller, yet each prompt supports a greater volume of conversation.



Comparison Table of Core Data Across Platforms
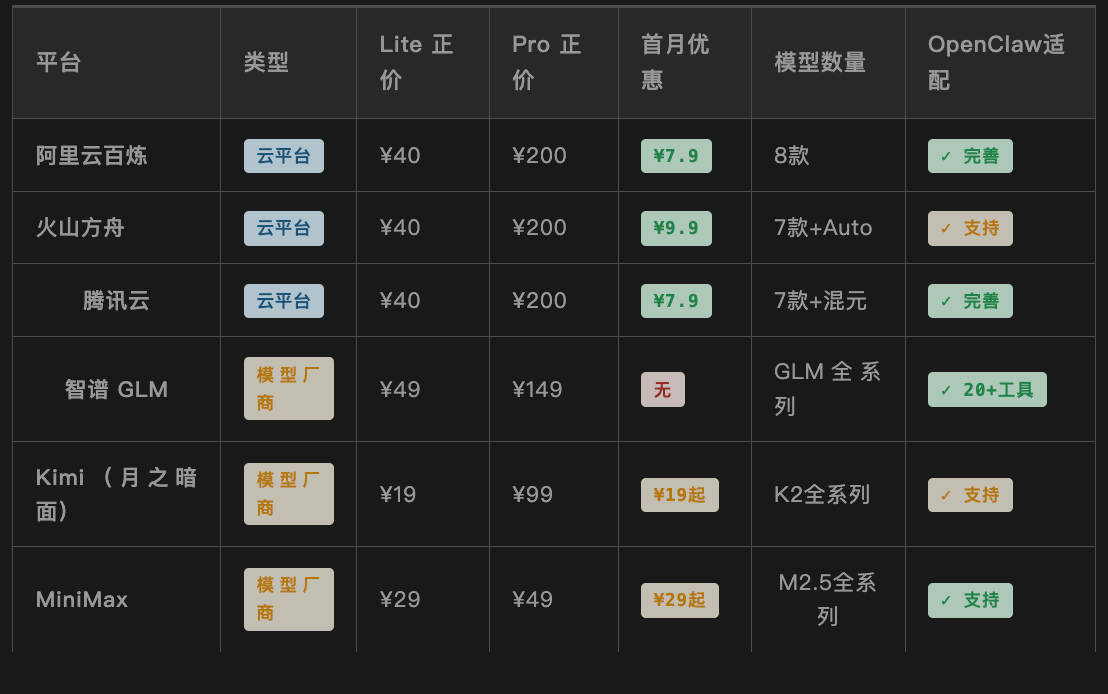
Note: Prices are based on the official retail price as of the end of March 2026. The first-month discount is exclusive to new users; details are subject to the checkout page. OpenClaw’s compatibility rating is based on the completeness of official documentation and community feedback.
Avoiding Common Pitfalls
Breakdown of Billing Methods: The Truth Behind the Numbers
The biggest information barrier in the Coding Plan market lies in the fact that different platforms use entirely different units of measurement, making direct numerical comparisons meaningless. This section outlines the three key billing factors to help you make an informed decision before purchasing.
1. Inconsistent units of measurement
Currently, two pricing systems coexist in the market: cloud providers (Alibaba Cloud, Volcano, Tencent) charge per "request," while model providers (Zhipu, MiniMax) charge per "Prompt." The key conversion rate is: 1 Prompt ≈ 15 model calls.
Billing is charged per user-initiated interaction round: regardless of how many times the model is called in the background, only one unit of credit is deducted per question. Usage-based billing, typical of traditional cloud providers, charges per API call—if a single user query triggers multiple model calls, multiple fees are deducted. The former is more favorable for agents like OpenClaw that frequently invoke models in the background, offering predictable costs; the latter strictly charges based on actual request counts and can lead to unexpected bills due to internal calls.
Both methods are suitable for light users of OpenClaw, as they count only the number of transactions rather than tokens, and include a monthly cap, eliminating token-related anxiety.
2. Conversion Examples
The Alibaba Cloud Bailian Pro plan offers 90,000 requests per month, equivalent to approximately 6,000 prompts.
The Zhipu GLM Lite plan provides approximately 120 prompts every 5 hours, equivalent to about 1,800 requests.
Therefore, "90,000" and "120" are not numbers that can be directly compared.
3. The sliding window/5-hour period is the real bottleneck
Almost all platforms impose a "5-hour quota" limit—this figure, not the monthly total, is the key determinant of whether you can sustain intensive usage. The 5-hour window operates on a rolling basis (not fixed calendar periods): if you start using at 14:00 and exhaust your quota at 15:00, you must wait until 19:00 for the first quota reset. Continuous usage for 2–3 hours during the afternoon peak easily reaches the limit.
4. Hidden Demotion Rules of Zhipu GLM-5
The Zhipu GLM Coding Plan has an exclusive rule: during peak hours (14:00–18:00 UTC+8), the actual number of available GLM-5 uses is only one-third of the non-peak hours. No other platforms currently have this rule—please pay special attention to your primary usage times when making a purchase.
5. Refunds and cancellations are not supported.
All platforms explicitly state that subscriptions are non-refundable and non-cancellable after purchase. Please confirm your needs before buying. New users are advised to first try the discounted first-month plan rather than purchasing an annual subscription upfront.
OpenClaw User Special Purchase Guide
As an autonomous agent framework, OpenClaw has specialized requirements for Coding Plan that exceed those of typical IDE plugins: high tolerance for concurrent calls, stable long-context handling capabilities, and native compatibility with the Anthropic protocol (since OpenClaw is fundamentally designed on the Claude protocol). Specific recommendations are provided below, categorized by use case.
🌱 Beginner-Friendly Trial
Recommended: Alibaba Cloud BAILIAN Lite, first month for ¥7.9 (discontinued), or Tencent Cloud, first month for ¥7.9.
New to the Coding Plan and looking to experience the full OpenClaw workflow at the lowest cost. Baidu’s model diversity (8 models) allows you to horizontally explore Qwen, GLM-5, and Kimi within a single plan, helping you quickly build intuitive judgment. Currently, Alibaba Cloud offers only the Pro plan at 200 RMB/month, while Tencent Cloud still has Lite plans at 7.9 RMB and 40 RMB—but users report these sell out instantly; the 200 RMB/month plan is likely the most accessible option.
💼 Daily Development
Recommended: MiniMax Plus ¥49/month
Daily programming tasks are fixed but not continuously intensive. MiniMax’s ultra-fast response (101 tokens/s) and no weekly limit on the Starter plan make it ideal for fragmented yet frequent development workflows.
⚡ Heavy Continuous
Recommended: Tencent Cloud or Alibaba Cloud Pro at ¥200/month
More than 6 hours of continuous development daily requires handling large codebases and complex agent workflows. Tencent’s and Bailian Pro’s monthly quota of 90,000 requests and 6,000 requests per 5-hour window offer the best overall balance of cost-effectiveness and stability among cloud platforms.
🎨 Frontend/Multimodal
Recommended: Kimi Moderato ¥99/month
Frequently needing to upload design mockups and UI sketches as screenshots for AI analysis and code generation. Kimi-K2.5 is the only official plan on the Coding Plan market that supports multimodal input via screenshots, making it ideal for frontend and Vibe Coding scenarios.
🔬 Complex Engineering Type
Recommended: Zhipu GLM Pro ¥149/month
Suitable for scenarios requiring top-tier model capabilities, such as handling large monolithic projects, complex agent scheduling, and high-concurrency automated testing. With 754 billion parameters, GLM-5 boasts the largest parameter scale among open-source models in China, offering code capabilities approaching Claude Opus, with long-term costs further reducible through a 30% discount on annual packages.
Summary
Purchase Strategy
The domestic Coding Plan market in 2026 has entered a phase of intense competition. Developers and users are the direct beneficiaries of the price war: for less than 10 yuan in the first month, users can experience multiple leading models—a scenario that was unimaginable just a year ago.
However, lowering the package threshold does not mean choosing becomes easier: differences in units, hidden limit rules, and price increase trends are all variables that require careful consideration.
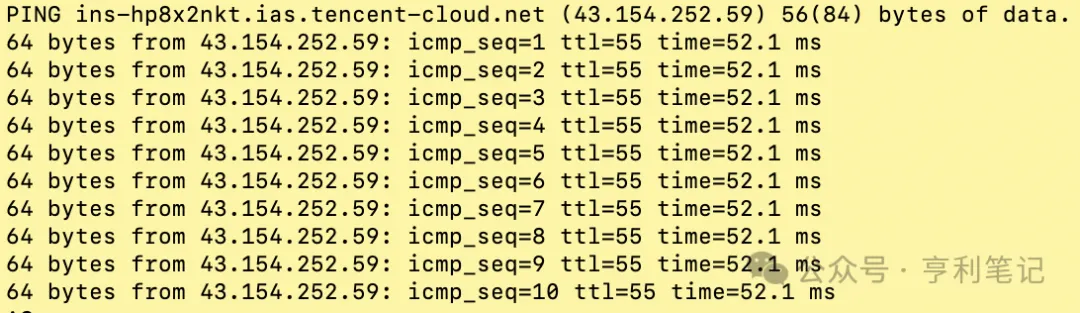
Another important point is to check which large model service your OpenClaw machine accesses more quickly. The simplest way is to use the ping command on the OpenClaw machine to check network latency and packet loss.
For example, this is checking the network condition from the OpenClaw host to Tencent Cloud endpoints; pay attention to whether there is packet loss in icmp_seq and whether the latency time is low:
$ ping api.lkeap.cloud.tencent.com
Based on the previous analysis, we summarize as follows:

📌 Final Tip
Data in this article is current as of the end of March 2026. Given frequent price policy adjustments across platforms (e.g., Zhipu has increased prices, and Alibaba Cloud Bailian Lite has ceased new purchases), please always refer to the latest official announcements from each platform before making a purchase. Subscriptions are non-refundable; we recommend starting with the lowest-cost monthly plan to test tool compatibility and personal usage habits before committing to a long-term plan.
Next, let’s discuss the various trade-offs to consider when deploying OpenClaw.