









Want to know which large model is truly the strongest on OpenClaw's real-world agent tasks?
MyToken has developed a transparent benchmark, compiled from evaluation websites, focused solely on assessing the real-world capabilities of AI coding agents, using success rate as the only core metric (speed and cost are treated as separate dimensions to be analyzed later). The benchmark is fully open and reproducible, presenting only rigorous evaluation criteria and the latest Top 10 success rate rankings.
I. Evaluation Dimension: Success Rate
Specific criterion: The percentage of tasks completed fully and accurately by the AI agent. Each task follows a highly standardized process:
Precise user prompt
Send the complete request to the agent to simulate a real user request scenario.
Expected Behavior
Both indicate acceptable implementation methods and key decision points.
Evaluation Criteria (Checklist)
List a checklist of atomic success criteria that can be verified item by item
Two, three scoring methods
This evaluation primarily uses three scoring methods.
Automated verification: Python scripts directly validate file contents, execution logs, tool calls, and other objective outcomes.
LLM Large Model Judge: Claude Opus scores according to a detailed scale (content quality, appropriateness, completeness, etc.)
Hybrid mode: Automated objective checks combined with LLM-based qualitative evaluation
All task definitions, prompts, and scoring logic are publicly disclosed to enable retesting and verification.
III. Tasks Used for Evaluation
This benchmark covers 23 distinct categories of tasks, encompassing dimensions such as basic interactions, file/code operations, content creation, research and analysis, system tool invocation, and memory persistence, closely mirroring developers' everyday use cases of OpenClaw:
Sanity Check (Automated) — Handle simple commands and respond correctly to greetings
Calendar Event Creation (Automation) — Natural Language Generation of Standard ICS Calendar Files
Stock Price Research (Automated) — Real-time stock price inquiry with formatted report generation
Blog Post Writing (LLM Judge) — Write a structured Markdown blog post of approximately 500 words.
Weather Script Creation (Automation) — Write a Python weather API script with error handling
Document Summarization (LLM Judge) — Three-paragraph concise summary of core themes
Tech Conference Research (LLM Judge)—Research and compile information from five real tech conferences (name, date, location, link)
Professional Email Drafting (LLM Judge) — Politely Decline Meeting and Propose Alternative
Contextual Memory Retrieval (Automated) — Precisely extract dates, team members, tech stack, and more from project notes
File Structure Creation (Automation) — Automatically generate standard project directories, README, and .gitignore
Multi-step API Workflow (Hybrid) — Read Configuration → Write Invocation Script → Fully Document
Install ClawdHub Skill (Automation) — Install and verify availability from the Skills Repository
Search and Install Skill (Automation) — Search for and correctly install a weather-related skill
AI Image Generation (Hybrid) — Generate and save images based on descriptions
Humanize AI-Generated Blog (LLM Judge)—Turn machine-like content into natural, conversational language
Daily Research Summary (LLM Judge) — Consolidating multiple documents into a coherent daily summary
Email Inbox Triage (Hybrid) — Analyze multiple emails and organize them into a report by urgency
Email Search and Summarization (Hybrid) — Search archived emails and extract key information
Competitive Market Research (Hybrid) — Competitive Analysis in the Enterprise APM Space
CSV and Excel Summarization (Hybrid) — Analyze tabular files and generate insights
ELI5 PDF Summarization (LLM Judge) — Summarize technical PDFs in language a 5-year-old can understand
OpenClaw Report Comprehension (Automation) — Accurately answer specific questions from research report PDFs
Second Brain Knowledge Persistence (Hybrid) — Store and accurately recall information across sessions
Four: Key Conclusion: Top 10 Large Models by Success Rate (Best % / Avg %)
Data updated as of April 7, 2026
Best % represents the highest single success rate, while Avg % represents the average success rate over multiple attempts, better reflecting stability.
Here are the top ten most successful models.
anthropic/claude-opus-4.6 (Anthropic) — 93.3% / 82.0%
arcee-ai/trinity-large-thinking (Arcee AI) — 91.9% / 91.9%
openai/gpt-5.4 (OpenAI) — 90.5% / 81.7%
qwen/qwen3.5-27b (Qwen) — 90.0% / 78.5%
Minimax/Minimax-M2.7 (Minimax) — 89.8% / 83.2%
anthropic/claude-haiku-4.5 (Anthropic) — 89.5% / 78.1%
qwen/qwen3.5-397b-a17b (Qwen) — 89.1% / 80.4%
Xiaomi/Mimo-V2-Flash (Xiaomi) — 88.8% / 70.2%
qwen/qwen3.6-plus-preview (Qwen) — 88.6% / 84.0%
NVIDIA/Nemotron-3-Super-120B-A12B (NVIDIA) — 88.6% / 75.5%
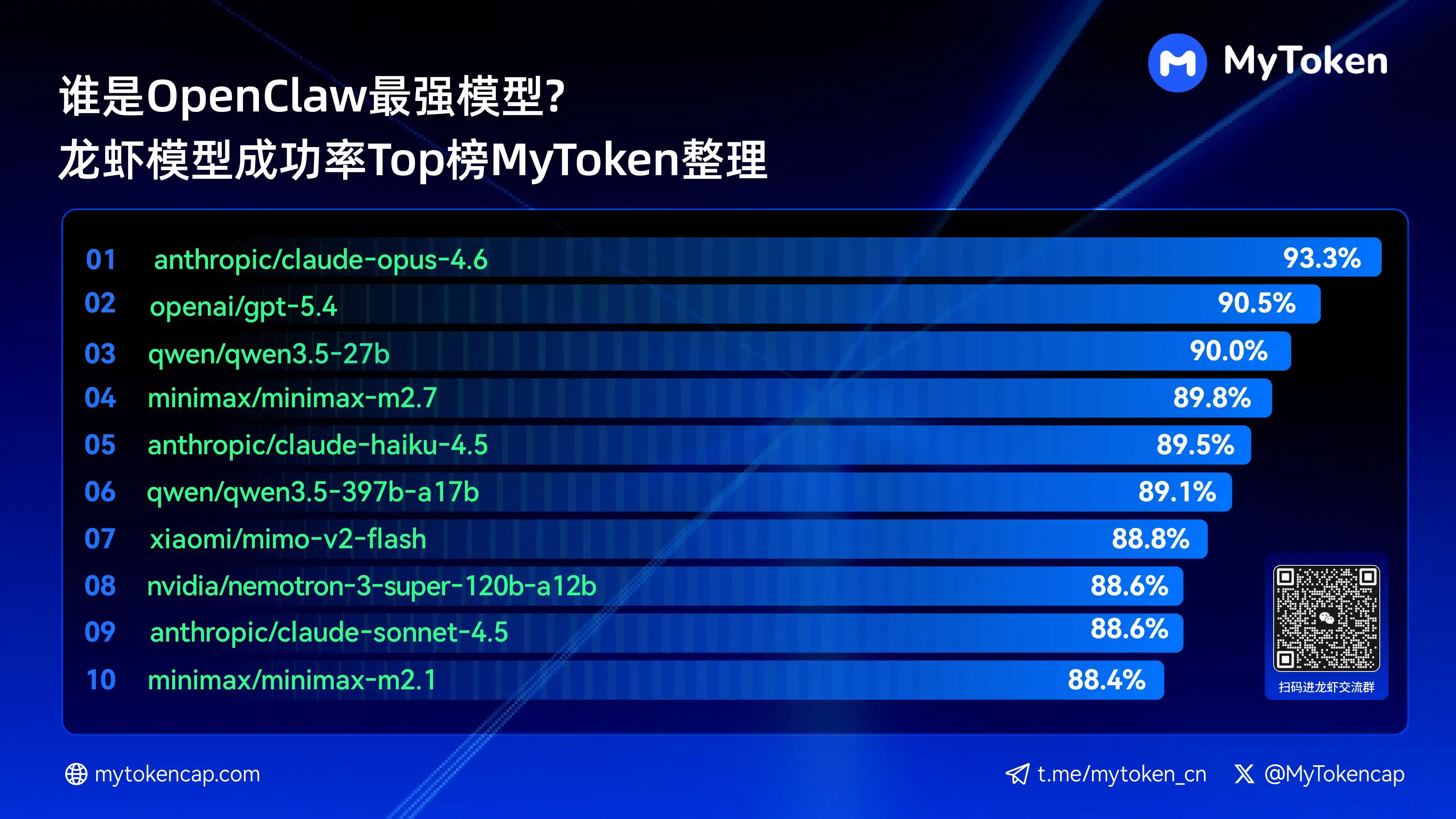
Claude Opus 4.6 is currently leading with the highest success rate at 93.3%, but Arcee's Trinity stands out for its average stability, and several models from the Qwen series have also entered the top ten, demonstrating strong potential for cost-effectiveness. Success rate is a baseline threshold; speed and cost will further influence real-world experience going forward.
This 23-task benchmark is fully transparent, and we strongly recommend testing it according to your own use cases. For more model rankings, stay tuned for MyToken’s upcoming Agent Leaderboard feature.
(Data sourced from PinchBench's publicly available OpenClaw proxy benchmark, continuously updated.)