










Author: Max, always on the move, 01Founder
If summarizing OpenAI's 2025 in stages, many would likely describe it as平淡甚至略显被动.
Over the past year and a half, they have systematically validated the reasoning pipeline, densely releasing a series of reasoning models from o3pro to o4mini, and introducing entirely new base models such as GPT-4.5 and GPT-5.
But in the field of visual generation, where ordinary users are most likely to perceive and spontaneously share content, their presence is gradually diminishing.
After the initial shock of Sora's release, OpenAI seems to have entered a long period of silence in this space.
Meanwhile, the other players at the table were not idle.
In the open-source ecosystem, models like Flux have completely broken down the barriers to high-quality local image generation;
On the business side, not only do established competitors maintain an extreme aesthetic barrier, but new entrants like Nano-banana, equipped with built-in web search functionality, have also emerged.
In comparison, OpenAI’s previous flagship image-generation model, GPT-Image-1.5, has already become outdated:
The image quality is poor, the layout is rigid, and it frequently crashes when handling complex text.
Gradually, a consensus emerged within the industry:
OpenAI has hit a technical bottleneck in visual generation and is struggling under pressure from various competitors.
Until a few weeks ago, the turning point appeared in a very subtle way.
On the well-known large model blind testing platform LM Arena, a mysterious image model coded as Duct Tape quietly slipped in.
Users participating in the blind test quickly realized something was off:
This model not only controls extreme aspect ratios with exceptional precision but also produces flawless layout posters containing extensive multilingual text, as if there were an invisible logical planning process before generating the image.
For a time, various tech communities speculated which company had quietly launched this major move, but OpenAI remained silent.
This morning, the other shoe finally dropped.
No lengthy launch event, no overwhelming marketing campaign—OpenAI directly named the codenamed tape model ChatGPT GPT-Image-2 and launched it fully to market.
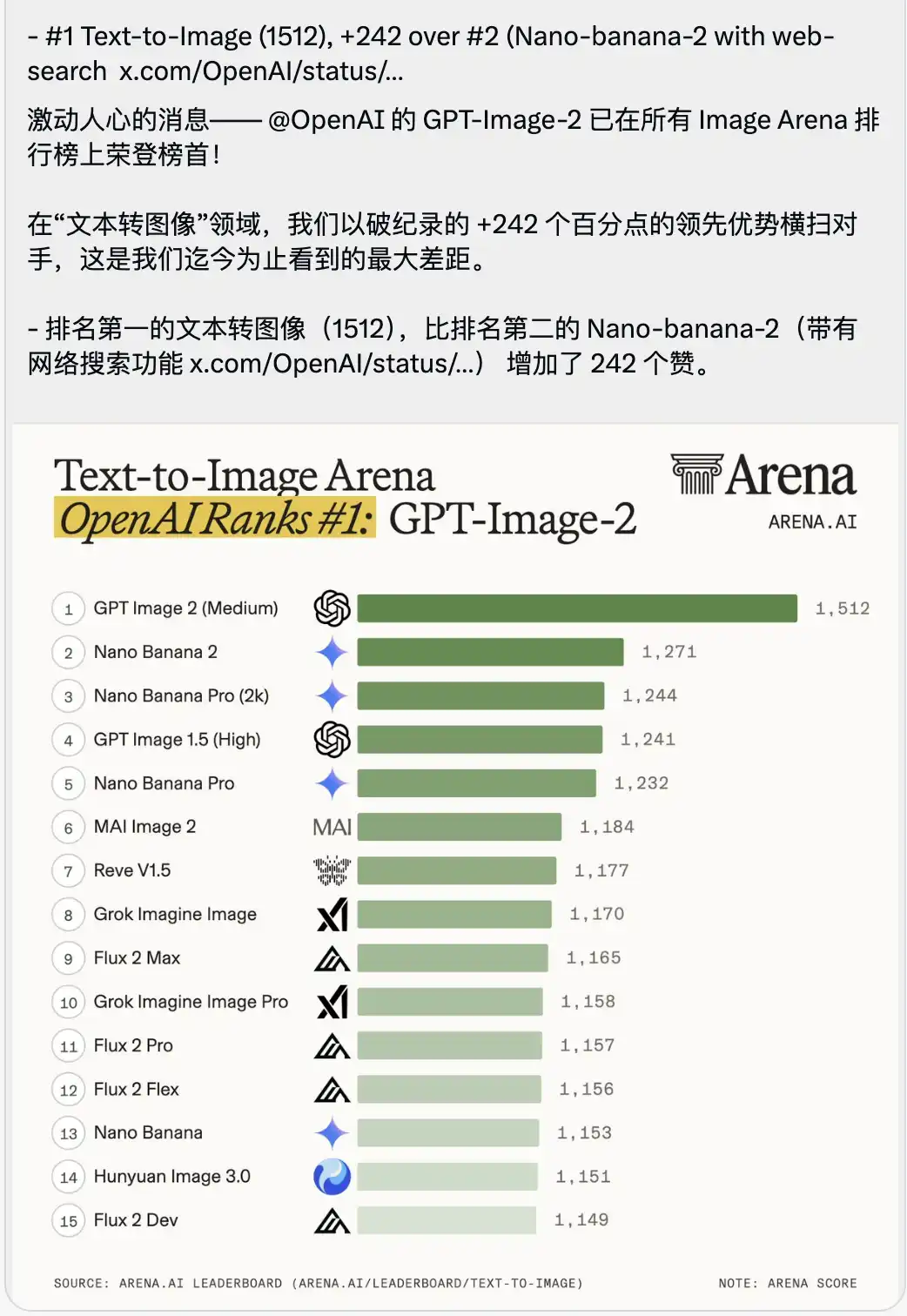
Along with it was released a text-to-image arena leaderboard that feels somewhat overwhelming.
GPT-Image-2 scored an exceptional 1512, directly claiming the top spot, leading the second-place model, Nano-banana-2 with web search, by a full 242 points.
In the context of large model benchmarking, people often greatly emphasize small advantages of a few tenths or single-digit points, as the scores between top models are extremely close.
A 242-point lead gap has never been seen in the arena's history.
This is not a minor version update—it’s a brutal generational overhaul.
I spent most of the day carefully reviewing its various capabilities and the latest API documentation.
The biggest takeaway is just one:
OpenAI is still the same OpenAI.
When it decided to reclaim its territory, it did so by overturning the old table.
Before this model, visual design work that we thought would take two or three more years to be fully replaced by AI is essentially finished today.
PART.01 Image Generation from Models to Visual Agents
To understand why GPT-Image-2 achieves such a dramatic score gap, you must first let go of traditional assumptions about text-to-image models.
Previously, when we used AI to generate images, it was essentially like opening a blind box—entering a few prompts and waiting for it to arrange pixels into what you wanted.
But GPT-Image-2 is more like an agent with an integrated visual engine.
The most obvious change is that it directly distinguishes two completely different modes in its mechanism.
One is Instant Mode, available to all users.
This mode emphasizes ultra-fast responsiveness and seamless integration into your daily workflows.
For example, if you send it a command from your phone, it can generate a fully structured diagram within seconds.
Its underlying visual understanding capability is extremely strong, but it primarily addresses high-frequency, one-time visual conversion needs.
The Thinking Mode, available to paying users.
Before it renders even a single pixel, it undergoes over a dozen seconds of logical reasoning and online searching.
It is this model that addresses an extremely core yet extremely difficult proposition:
For the first time, the model truly knew what it should draw.
Let’s take the most straightforward example.
Type in the chat box:
Help me create a poster. Search online for people’s reviews of the mysterious Duct Tape model and include ChatGPT’s QR code.

With the old model, it wouldn’t understand what the netizen said at all—it would just generate a poster filled with garbled fake characters, and the QR code would be a fake image that can’t be scanned.
But in thinking mode, its workflow is as follows:
It will first pause the drawing, activate the online search tool, and scrape real user reviews from Reddit, Threads, or LinkedIn;
Then, it began planning the poster’s layout, white space, and typography hierarchy;
Finally, it generates a real, functional QR code that can be scanned to redirect directly, and renders the entire image.

This is no longer just about drawing—it’s essentially handling end-to-end work including research, planning, copy extraction, and layout design.
A parallel comparison is required here.
Anyone following the large model community knows that image generation models with internet connectivity and search capabilities were not pioneered by OpenAI.
The second-ranked Nano-banana has long had this mechanism.
However, when using Nano-banana in practice, you'll find it can be a bit clumsy in many places.
The thinking of Nano-banana is often a mechanical stitching of logic.
For example, if you ask it to research industry trends for a poster, it will indeed search, but usually just copies sentences verbatim from Wikipedia and forcibly pastes them onto the design.
It easily becomes confused when faced with instructions requiring interpretation of abstract business demands.

It’s like having an intern who understands instructions but has zero work experience—knows how to execute, but has no grasp of strategy.
But GPT-Image-2's performance in this regard can only be described as extraordinary.
Its thinking is not merely perfunctory, but a genuine understanding of the underlying cultural context and business intent.
During testing, I entered a minimal Chinese instruction: Help me create a screenshot of Musk live streaming on TikTok to sell Doubao.
Using older image generation models, you’d likely get a picture of a white person resembling Musk holding a baozi, with a blurry background and no idea what TikTok looks like.
However, in thinking mode, GPT-Image-2 produces results that are somewhat unsettling.
It didn't simply piece together elements, but autonomously applied its understanding of Chinese internet culture to generate a screenshot of a TikTok Live interface that is pixel-perfectly replicated.
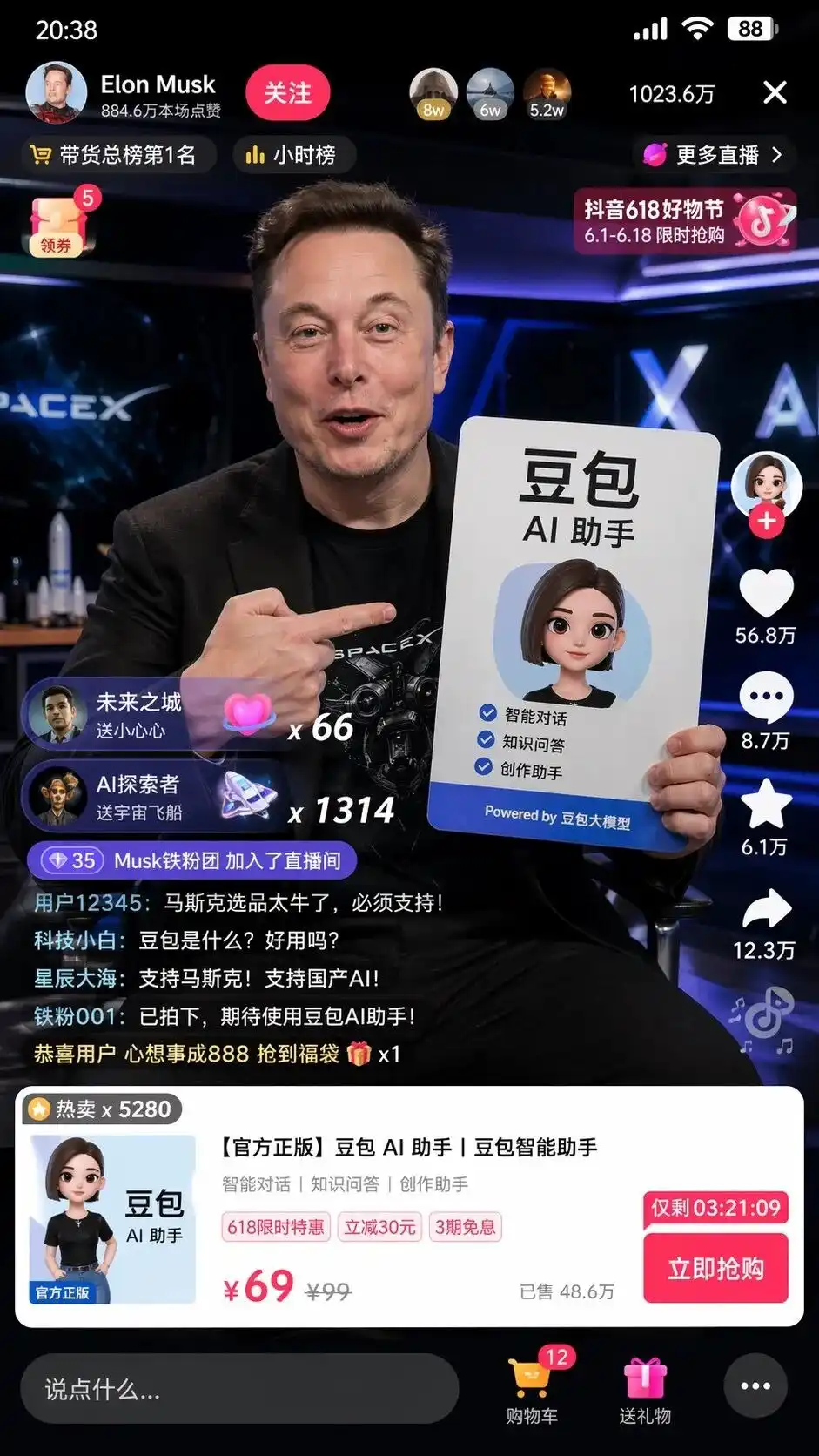
The screen not only features a lifelike Musk holding a sign for the Doubao AI assistant with perfect typography, but even more unsettling are the details that weren’t mentioned in the prompt:
The follow button in the top-left corner, the hourly ranking, the 10.23 million online users in the top-right corner, the standard product card that pops up at the bottom, and even the strikethrough price of 99, the discounted price of 69, and the “Buy Now” button with a countdown timer.
Most chilling is the extremely realistic user comment stream scrolling in the bottom-left corner:
Tech novice: What is Doubao? Is it useful?
To the stars and oceans: Support Musk! Support domestic AI!
No one told it what to write in the barrage, how the product UI should look, or how to set the price.
This is the complete business UI design and operational strategy generated and executed by the model after analyzing the tags "Douyin e-commerce" and "Doubao Large Model."
At this moment, the evaluation criteria for large models in image generation have officially evolved from merely whether the image looks good to whether it understands strategy and layout logic.
PART.02 Real-World Testing of Core Capabilities
To test its limits, I tried it out with several high-frequency and complex scenarios according to commercial design standards.
It turned out that the granularity with which it solves problems is eerily precise.
First scenario: Visual understanding and business closure (dressing the model)
In traditional e-commerce visuals or fashion planning, the execution cost between having an idea and seeing the final look on a model is extremely high.
You need to find models, borrow clothing, set up a studio, and perform post-production retouching.
Later, with the advent of AI, people began training LoRA models to fix facial features, but this still required dozens of reference images and a significant learning curve.
In GPT-Image-2, this process has been compressed to the extreme.
I uploaded a casual selfie of myself and told it I’m going on a beach vacation next month, asking it to help me put together a few outfits.
It first showed me eight completely different styles of summer clothing lookbooks, laid out like professional e-commerce lookbooks, with each item accompanied by accurate text labels.
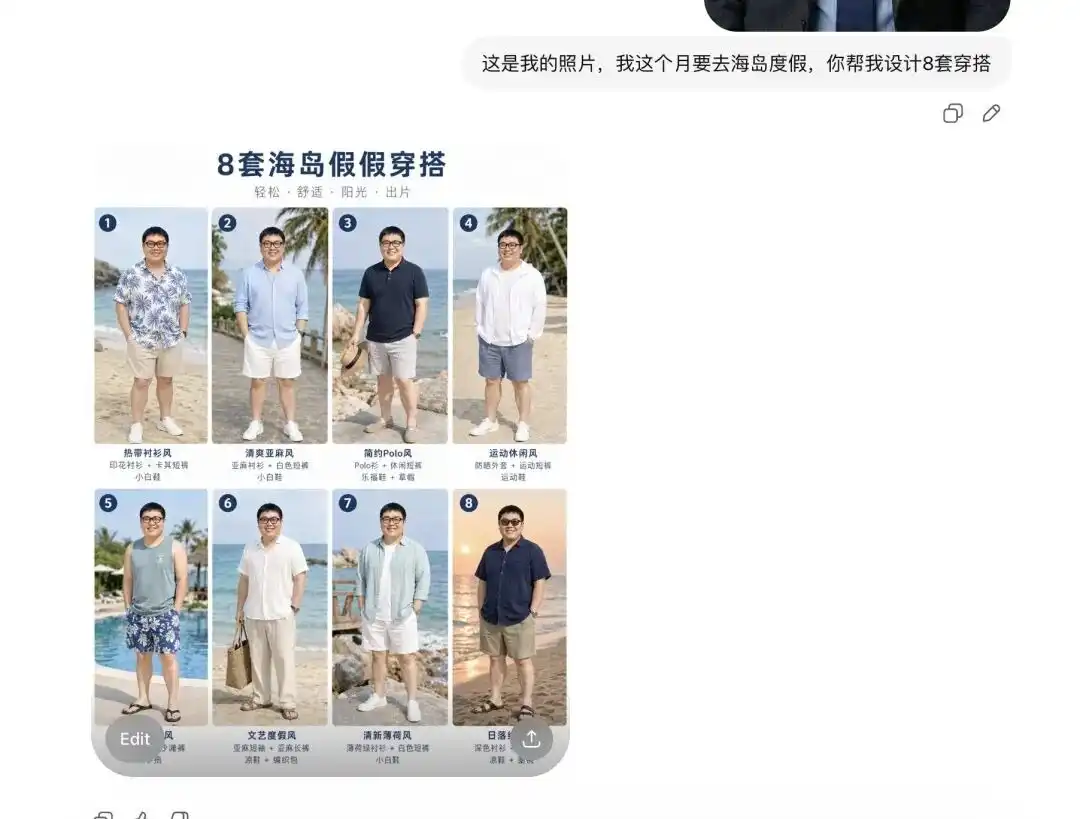
More importantly, it had already precisely analyzed my facial features and body proportions in that instant.
When I told it I wanted to see how the first outfit looked on me and requested detailed photos from different angles, it directly extracted the person from my selfie, replaced them with the summer outfit, and generated images from side, half-body, and other perspectives.

This transition is extremely smooth. This means the moat for basic clothing styling rendering or outsourced model fitting services has been completely eliminated.
Second scenario: Solving consistency and continuous storytelling (generating a comic from a single sentence)
Anyone who has used AI image generation knows that it’s not hard to get AI to draw one beautiful image, but it’s challenging to get it to draw ten images of the same person with consistent actions and perspectives.
This is what is known as the consistency problem.
But in this real-world test, I encountered a case that strongly contradicts past experience.
You can upload just one photo of you and your friend from yesterday, then enter a very simple prompt:
Turn us into the main characters and create a three-part, three-page Japanese-style manga with a plot of your choosing.
A few seconds later, it directly output three pages of black-and-white comics with standard storyboards.
The most terrifying part is that these two真人-generated comic characters appear in different panels across three pages.

Whether it’s a close-up, a distant running shot, or a back view, even their facial features, hair details, and wrinkles in their clothing are all perfectly consistent.
Even more remarkable, the comic’s plot is completely coherent, and even the text within the speech bubbles forms a logical, cohesive story.

The ability to achieve consistency in time and space indicates that it has moved beyond the scope of single-image generation and possesses the directional capability for continuous storytelling.
Third scenario: Crossing the final threshold of text rendering (multilingual typography)
If consistency solved the narrative problem, then precise rendering of multilingual text is what truly pushed graphic designers into a corner.
Previously, whenever there was any text in an image, the large model would start producing gibberish.
Because the model understands text as tokens (semantic blocks), while generating images as pixels, these two were previously disconnected.
GPT-Image-2 has completely solved this issue.
I generated a French fashion magazine cover, created a Japanese restaurant menu filled with hiragana and kanji, and even tried typesetting densely packed Russian annotations.

The result is flawless, with zero spelling errors.
What’s most devastating is that it not only gets the characters right, but also adapts to local cultural aesthetics and typography for each language.
For example, the Chinese characters in the Japanese flyer use authentic Japanese vintage calligraphic fonts, and the hiragana are laid out in accordance with traditional Japanese vertical reading conventions.
Layout design was once the exclusive domain of graphic designers.
Adjusting letter spacing, establishing visual hierarchy, and achieving balance between text and background all require extensive practice.
But when AI can handle so many languages with zero errors and comes with advanced typographic aesthetics, there’s no longer a need for humans to manually align guidelines for everyday posters, brochures, or feed ads.
Scenario four: Distorted aspect ratio and extreme micro-control (engraving on a grain of rice)
Finally, to see just how obedient it was, I gave it several very tricky commands.
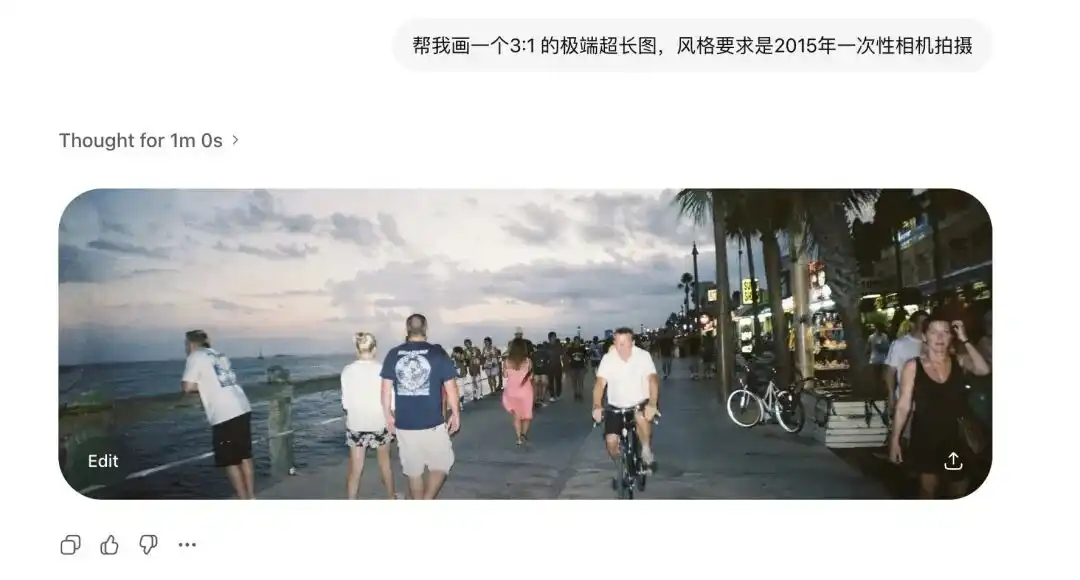
I first tested its extreme aspect ratio.
Traditional diffusion models are extremely sensitive to non-standard aspect ratios.
Previously, slightly stretching the image would cause two heads to appear.
But I requested Images 2.0 to generate ultra-wide 3:1 images and tall vertical 1:3 images, and not only did it not break down, it even produced seamless, logically closed 360-degree panoramic images.
Even the distortion from old lenses and the poor flash reflection on walls, captured by disposable cameras in 2015, are rendered with perfect clarity.
Another demonstration of its micro-control capability was the slightly crazy grain-of-rice test shown by the official at the launch event.
Researchers invoked an experimental 4K API still in internal testing, without adding any embellishments such as macro photography or 8K ultra-high definition—only issuing one extremely abstract, straightforward instruction:
A pile of rice. On one single grain of rice in this pile, it says GPT Image 2.
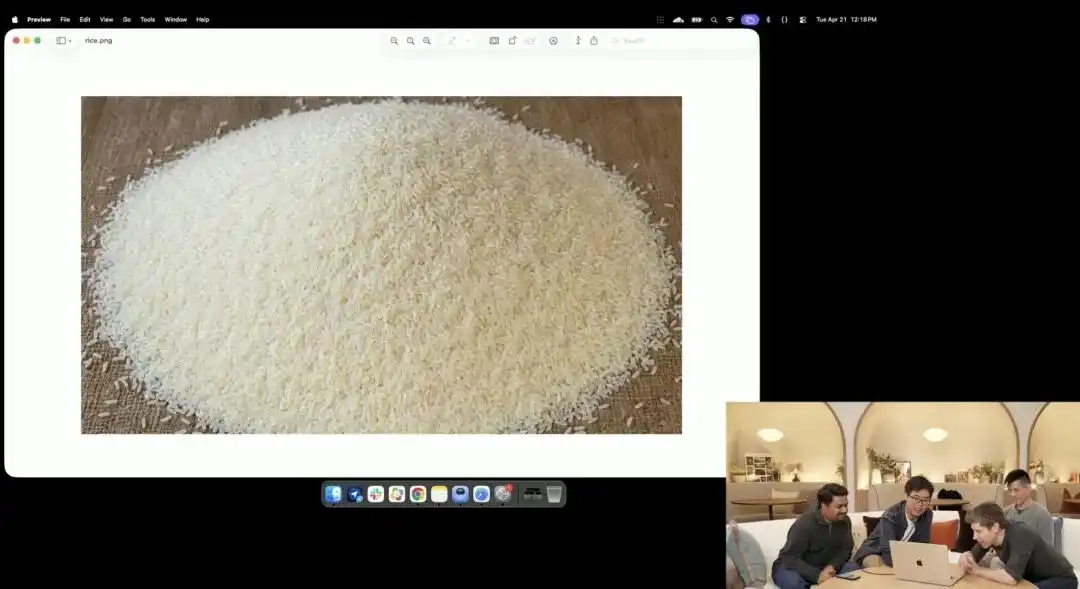
When the screen is zoomed in dozens of times, even revealing pixelation, can you really find that one tiny grain with a word engraved on it amid a pile of rice?
The texture of this grain of rice still conforms to the laws of physics, with the text precisely embedded along the subtle curvature of the grain.
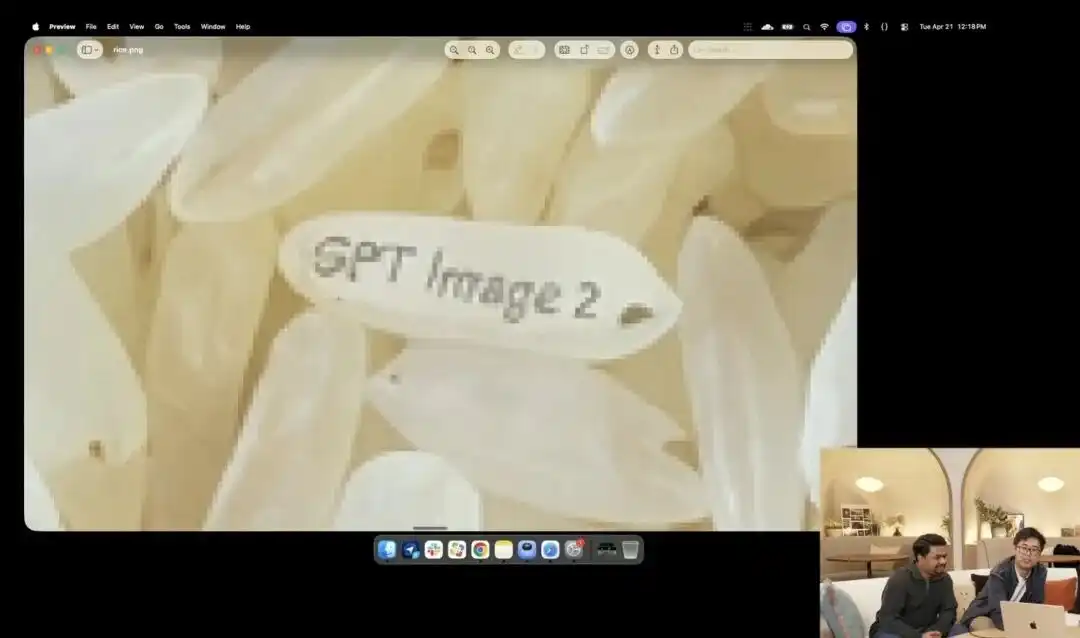
All remaining tasks—activating the macro perspective, calculating depth of field, locating the physical coordinates of the grain of rice in latent space, and printing the text—were automatically imagined and completed by the large model in thinking mode.
This case clearly demonstrates that the model’s understanding of spatial position has reached pixel-level surgical precision.
This means that in future practical work, you can precisely modify any small detail in the design file—targeting exactly what you want—rather than, as before, changing a collar and having the entire image shift unexpectedly.
PART.03 Some Technical Details
This level of extreme control and strategic intelligence cannot possibly be achieved by simply brute-forcing with computational power.
To figure out what its true capabilities are, I conducted some probe tests on GPT-Image-2.
An interesting point was discovered.
Although the official documentation states that the overall knowledge base of GPT-Image-2 has been updated to December 2025, in my actual testing,
The training data cutoff date for Instant Mode remains at the end of May 2024;

The thinking mode that requires deep consideration has a native knowledge base that largely stops at June 2024 (but can access the current accurate date through real-time internet connectivity).

Based on these two time points, the underlying development of GPT-Image-2 seems to follow a discernible pattern.
First, let’s talk about the instant mode, optimized for high-frequency image generation.
The May 2024 deadline suggests it is most likely a direct adaptation of o4-mini, or a lightweight version within the GPT-5 family (such as GPT-5 mini or even a very small parameter GPT-5 nano).
It is precisely because this lightweight base has already developed strong spatial planning capabilities and the ability to understand complex instructions that the upper-layer image generation can remain stable and avoid confusion.
And that extremely intelligent, business-strategy-oriented way of thinking cannot be based on the GPT-5 base model.
Because GPT-5's foundational knowledge base is current up to September 2024.
The thinking mode is highly likely connected to the continuously iterated O-series reasoning models in the background (such as o4 or an updated o3).
The large model first uses the unique long-thought mechanism of the O series to thoroughly calculate the business logic, audience psychology, and layout coordinates in the latent space, before handing over to the visual module for final pixel rendering.
Of course, there is another possible path:
Under OpenAI’s highly refined computational resource allocation mechanism, the fast mode may directly invoke GPT-5 nano as a baseline, while the thought mode uses a slightly larger GPT-5 mini combined with external tools.
But regardless of which base combination you choose, if you’ve been following OpenAI’s API ecosystem, you’ll realize its underlying generation logic has long been on a completely different level from Midjourney.
PART.04 Pricing Most Concerned by Everyone
But more than guessing the base layer, what truly matters for developers and enterprises looking to integrate it into their workflows is that highly realistic and counterintuitive API pricing table.
Previously, DALL-E 3 was charged per image (e.g., $0.04 per image).
But starting with the first generation, GPT-Image-1, OpenAI has completely changed it to a token-based billing model.
GPT-Image-2 continues to meet this standard, and even goes a step further by offering more features at a lower price.
According to the pricing table just released by the official team, the price per million tokens is as follows.
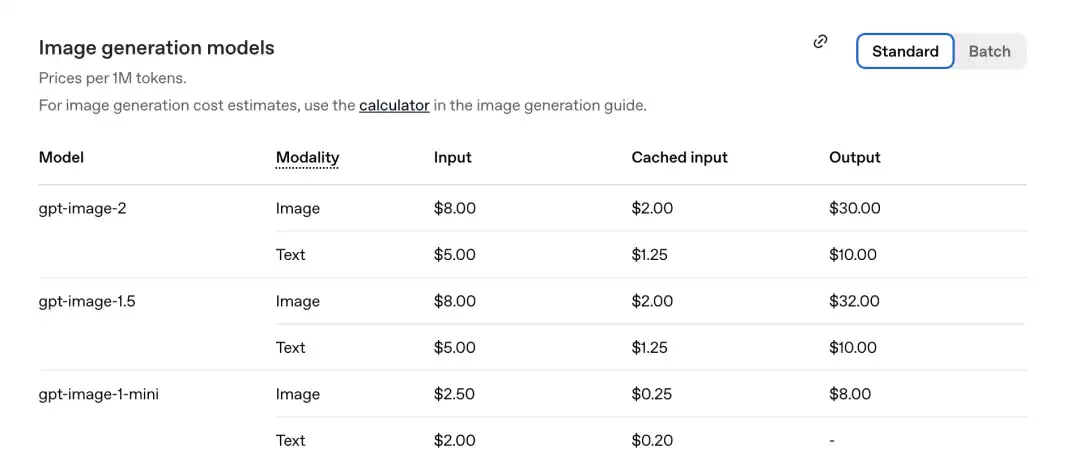
GPT-Image-2 Image portion: Input 8.00, cached inputs 2.00, output $30.00.
Compared to the previous generation gpt-image-1.5: the output is $32.00.
The new model is even cheaper.
Let’s do the math.
In previous models, generating a high-quality image typically required consuming 1,000 to 1,500 output tokens.
At a rate of $30 per million output tokens, the actual cost to generate an image is approximately $0.03 to $0.045 (about RMB 2 to 3 cents).
If you don't need instant responses and instead use the official Batch API mode, this price will be halved again (output drops directly to $15.00).
Overall, generating one image costs just over 10 cents.
The price of this single sheet is already highly cost-effective, but its real advantage lies in the cached inputs listed in the pricing table.
Previously, when creating comic strips or designing posters in the same series, you had to re-upload large volumes of character references, background summaries, and lengthy prompts every time you regenerated, resulting in extremely high input costs.
However, under the current token-based billing model, when you request it to generate eight consecutive comics at once, the visual elements of the first image are directly cached as context.
Starting from the second image, the input cost for the image dropped directly from $8.00 to $2.00 (i.e., only 25% is charged).
This means that when performing large-scale commercial batch generation or requiring high character consistency in continuous generation, its marginal cost drops sharply.
The smarter the model and the more images it generates, the lower the average cost per image.
This industrialized billing logic is what truly pushes line artists to the brink.
PART.05 Behind-the-Scenes Team Revealed
Finally, let’s revisit the internal OpenAI visual dream team that demonstrated on stage during the live launch event—many features that previously seemed implausible now make perfect sense.
For example, how exactly does it solve the challenges of multilingual complex layout and garbled text?
This would not have been possible without senior scientist Gabriel Goh on the team.

In the academic community, he is best known as a core author of the groundbreaking multimodal model CLIP.
CLIP established the foundation for modern AI to understand how human language corresponds to image pixels.
With this scholar leading cross-modal semantic mapping, GPT-Image-2 no longer guesses the shapes of text randomly, but truly writes at the pixel level.
For example, how does it understand three-dimensional spatial relationships, create extreme aspect ratio 360-degree panoramas, and even comprehend macro lighting on a grain of rice?
This is thanks to another core member, Alex Yu.

Before joining OpenAI, he was a co-founder and former CTO of Luma AI, a leading startup in the 3D generation space, and a top researcher specializing in 3D neural rendering (such as NeRF).
With him, GPT-Image-2 has already moved beyond traditional 2D pixel manipulation.
It likely first constructs a three-dimensional scene in your mind, sets up the lighting, and then renders an accurate 2D slice for you.
How is such an incredibly terrifying multi-page comic consistency achieved?
This refers to the young duo from the team who just graduated from MIT CSAIL:
Boyuan Chen (left) and Kiwhan Song (right).
Their core focus in academia is called World Models and Embodied Intelligence.
Teaching machines to understand how the physical world works, ensuring characters maintain identical features and remain undeformed across different time and space shots, is precisely the problem these two scholars have been trying to solve.
Finally, add Nithanth Kudige (left, key author of the O-series inference models), who has long been dedicated to bridging large inference models with the foundational logic of vision, and Kenji Hata (right, former Google researcher and graduate of Stanford’s Vision Lab).

When this group came together, the underlying logical reasoning, 3D space rendering, pixel-perfect text-image alignment, and laws of the physical world were naturally integrated into a single model.
PART.06 Boundary of GPT-Image-2
All models have boundaries.
The official also acknowledges that it still struggles in the face of certain extreme scenarios.
For example, origami instructions requiring precise physical folding, solving a Rubik’s Cube, or extremely dense repetitive details like grains of sand still push its capabilities to the limit.
But in a commercial application context, this is an extremely minor flaw.
For the entire design industry, there's no need to spread anxiety—this does not represent the death of aesthetics.
People with taste, business insight, and strategic understanding can still create excellent things with it.
But the objective reality is that the moat protecting the profession of designers has been substantially eroded.
Previously, I made a living by memorizing keyboard shortcuts for design software, knowing how to align fonts neatly and evenly, understanding layout techniques for different languages, and mastering detailed image editing and masking.
But it will be much harder going forward, because skills that used to be openly priced and traded are now basic commands that anyone can invoke for free with a single prompt.
After a period of silence, OpenAI has once again proven, in a very quiet but extremely powerful way, who truly holds the best cards on this table.
The old execution toolchain is breaking down; the question facing the industry is no longer whether AI will replace us, but how we can adapt to this entirely new production line.