









No launch event, no technical blog, no corporate backing—HappyHorse-1.0, a text-to-video model, quietly rose to the top of the AI Video Arena ranking on the authoritative AI evaluation platform Artificial Analysis, surpassing Seedance 2.0 with a higher Elo score and leaving mainstream competitors like KeLing and Tiangong far behind, sparking a “code-breaking race” within the tech community.
The ranking of Artificial Analysis is not based on technical specifications, but rather on Elo scores aggregated from real user blind tests, reflecting the genuine perceptions of ordinary users. This makes the ranking harder to dismiss than typical benchmark lists, and turns the question “Who actually made this?” into an unavoidable one.
"Happy Horse" quietly rises to the top, sparking a guessing game in the tech community
Speculation on X came quickly. The first thing noticed was the language order on the official website: Mandarin and Cantonese appeared before English. For a product targeting global users, this ordering was unusual—if led by a U.S. team, English would almost certainly be first. This strongly suggests the team behind it is based in China.
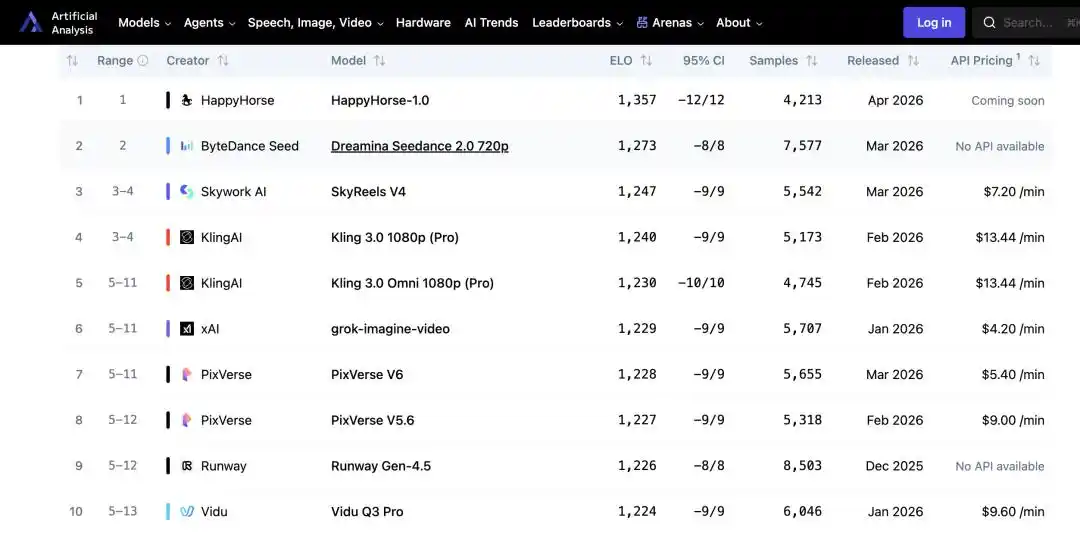
The name itself is also a clue. 2026 is the Year of the Horse in the Chinese zodiac, and the name "HappyHorse" contains a rather unsubtle pun on this theme—similar to how "Pony Alpha" played the same trick earlier this year. The list of suspects quickly grew: both the founders of Tencent and Alibaba share the surname "Ma," making them natural candidates; some speculated about Xiaomi, reasoning that Lei Jun is typically low-key but enjoys making surprise moves; others felt its vibe more closely resembled DeepSeek, given that DS had previously quietly launched and then quietly removed a vision model. Speculation ran rampant, but none of the theories came with concrete evidence.
The true identification of the target was achieved through technical line-by-line comparison. X user Vigo Zhao compared the public benchmark data of HappyHorse-1.0 with known models one by one, and found a highly matching match: daVinci-MagiHuman—the open-source model "Da Vinci MagiHuman" released on GitHub in March.
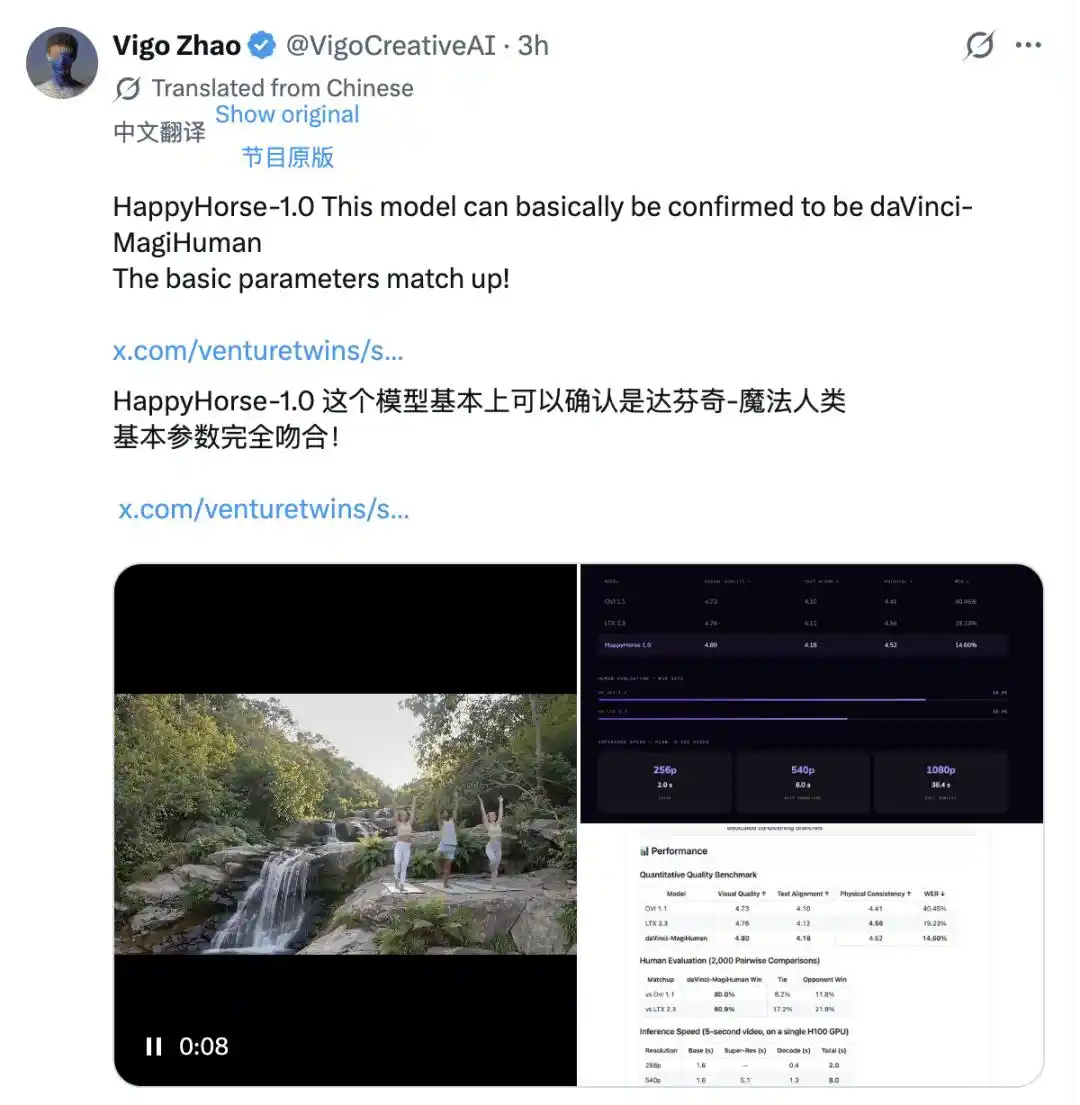
Visual quality: 4.80, text alignment: 4.18, physical consistency: 4.52, speech word error rate: 14.60%—the two datasets match item by item. The website structure is nearly identical: the presentation style of the architecture description, performance tables, and demo videos appears to come from the same template. Both use a single-stream Transformer architecture, jointly generate audio and video, and support identical language lists. Such a high degree of overlap is difficult to attribute to coincidence.
The most widely accepted conclusion in the tech community is that HappyHorse is an optimized iterative version developed by Sand.ai, one of the co-developers of daVinci-MagiHuman, with the primary goal of testing the upper limits of model performance under real user preferences, laying the groundwork for future commercialization.
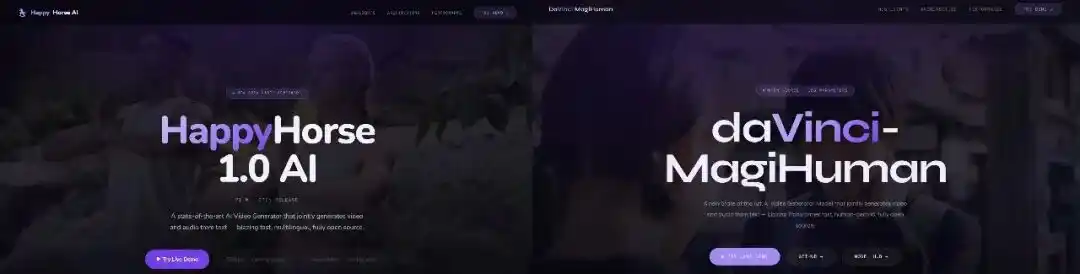
daVinci-MagiHuman was officially open-sourced on March 23, 2026, as a collaboration between two young teams. One team is from the Generative Artificial Intelligence Research Lab (GAIR) at the Shanghai Institute of Innovation (SII), led by scholar Liu Pengfei; the other is Sand.ai (Sand Tech) in Beijing, founded by Cao Yue, who also has an academic background, with the company focused on autoregressive world models.
The model uses a 15-billion-parameter, purely self-attention, single-stream Transformer that jointly models tokens from text, video, and audio within a single sequence—no one in the open-source community has previously conducted true audio-video joint pre-training from scratch; most approaches simply concatenate single-modal representations.
How can an open-source video model achieve a remarkable turnaround in two weeks?
Once identity is confirmed, another question becomes even harder to answer: How could HappyHorse-1.0 achieve a higher Elo score than Seedance 2.0 in just two weeks, when daVinci-MagiHuman was only open-sourced at the end of March?
According to information disclosed on the official website, HappyHorse has not made any modifications to its underlying architecture; a more reasonable assumption is that it has been specifically optimized for evaluation scenarios in its default generation strategy.
The Elo system is essentially an accumulation of user preferences; slightly improving on sensitive perceptual factors—such as whether facial expressions are stable or unstable, whether audio and video are synchronized, and whether the visuals are pleasing—makes a model more likely to be selected in blind tests. The model’s upper capability limit remains unchanged, but its “evaluation performance” can be refined.
In fact, in the blind test samples of Artificial Analysis, portrait generation and script-based content account for over 60%. daVinci-MagiHuman has been focused on portrait performance since the training phase, giving it a natural advantage in these scenarios—this is the core reason for its higher blind test win rate. If the blind test samples are primarily close-ups of portraits, models skilled in portraits will systematically gain an advantage, which has no direct correlation with their actual performance in complex scenarios involving multiple characters, intricate camera movements, or long-form storytelling.
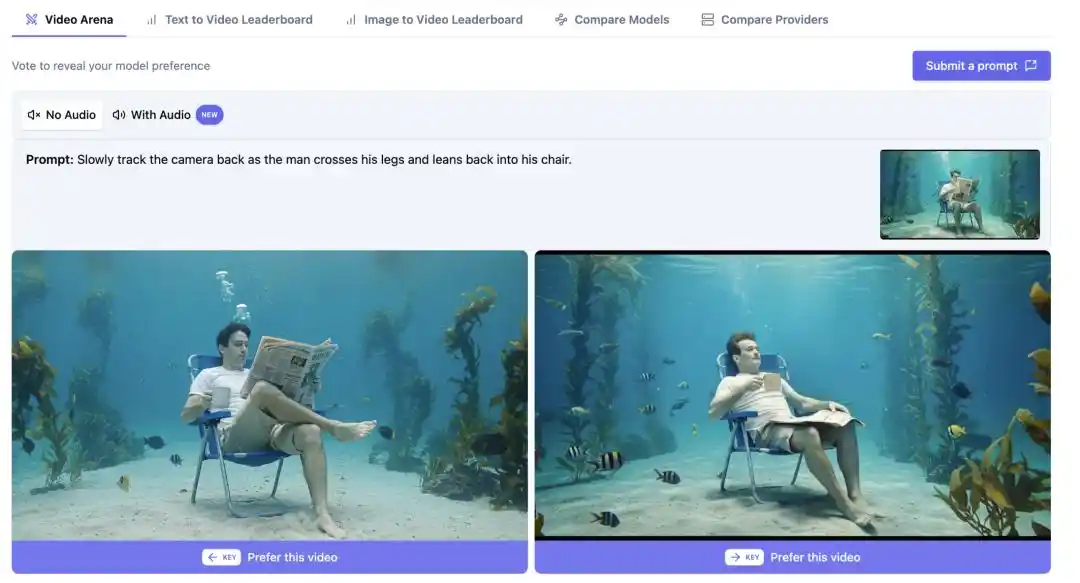
As a result, there is a noticeable gap between the rankings and real-world performance, with discussions on X splitting into two camps. The skeptical camp, after testing, believes that HappyHorse-1.0 still shows visible differences from Seedance 2.0 in character detail and motion fluidity, leading them to question the representativeness of the Elo scores themselves.
Supporters, however, have high hopes for HappyHorse’s potential to address the industry pain point of maintaining visual consistency across multi-shot sequences—a challenge that current leading video models have yet to solve effectively. If daVinci-MagiHuman truly makes breakthrough progress in this area, it could be far more significant than any ranking on a leaderboard.
The limitations of the model itself shouldn't be obscured by numbers. The Xiaohongshu creator @JACK's AI Vision was among the first to deploy and test daVinci-MagiHuman, discovering that it requires an H100 GPU—standard consumer-grade graphics cards are essentially unusable. Although the community is exploring quantization solutions, local deployment by individual users remains difficult in the short term.
In practice, it currently excels at single-person scenes; when multiple people appear or the scene becomes more complex, the quality drops significantly—this isn’t something that can be fixed by tuning parameters, as it’s directly tied to its design focus on portraits. Generation typically lasts around 10 seconds; longer outputs tend to become unstable, and high-definition output still requires super-resolution plugins for enhancement.
@JACK's AI Perspective concludes that the daVinci-MagiHuman has lower overall usability compared to LTX 2.3 and is not suitable for daily use until the community improves its quantification capabilities.
Is the video generation sector about to welcome its true "catfish"?
Of course, leading a leaderboard once doesn't reveal much. Next, HappyHorse must undergo more thorough testing in stability, high-concurrency response speed, cross-scenario consistency, role control precision, and generalization ability beyond evaluation datasets—these are the core metrics that determine whether a model can truly integrate into creators' workflows.
But if we broaden our perspective to the larger industry landscape, the signal this sends is already clear enough.
Open-source video models are not new. However, a noticeable gap in performance has always existed between open-source and closed-source models—in scenarios requiring delivery to customers, the generation quality of open-source models has long failed to cross the threshold from “usable” to “deliverable.” The pricing power of closed-source products like Keling and Seedance is largely built upon this very gap.
The significance of this lies in the fact that a product based on an open-source model has, for the first time, directly competed with leading proprietary competitors on a blind benchmark ranked by real user perception. Regardless of how much optimization was tailored to the evaluation scenario, this represents at least a signal worthy of serious attention from proprietary vendors whose pricing power relies on this gap.
For developers, this inflection point has more specific implications. In vertical use cases such as avatars, digital humans, and virtual streamers, once the generation quality of open-source foundations reaches a “production-ready” threshold, the cost structure of self-deployment undergoes a substantive shift—not only through reduced API invocation costs, but more importantly, by fully bringing data, models, and inference pipelines under one’s own control, gaining flexibility in customization depth and privacy compliance that closed-source solutions cannot match.
HappyHorse-1.0 will not undermine Seedance 2.0 or KeLing's market position in the short term, but once it becomes widely recognized that open-source models can match the performance of proprietary ones, community-driven quantitative optimization, vertical fine-tuning, and inference acceleration will continue to advance at a pace far exceeding that of proprietary products.
This Year of the Horse, what truly matters may not be which horse runs the fastest, but that the track itself is widening.
This article is from the WeChat official account "AI Value Officer," authored by Xingye and edited by Meiqi.