









The article provides an in-depth technical analysis of the leaked source code of Claude Code (v2.1.88) as of March 31, 2026, treating it as a valuable case study revealing the engineering architecture of cutting-edge AI agents.
Author and source: Max
Today (March 31, 2026), Anthropic once again exposed the complete frontend and client source code of its latest Claude Code (v2.1.88) in the npm registry due to a basic packaging error.
A netizen published an unremoved cli.js.map file, which directly revealed approximately 1,900 files containing over 510,000 lines of original TypeScript code.
For Anthropic, this is another serious OpSec incident following the recent leak of the Mythos model documentation.
However, for developers and industry researchers working in the large model application layer, this source code is an openly shared, highly valuable whitepaper on cutting-edge AI Agent engineering architecture.
Setting aside the controversies around compliance and data breaches, I spent some time conducting an in-depth review of this source code locally.
If you view it not as gossip, but as a production-grade AI programming assistant architecture case study, it contains numerous engineering decisions that break conventional thinking.
Below is a detailed technical breakdown of Claude Code’s underlying architecture, scheduling mechanisms, memory system, and security policies from an objective perspective.
The article is lengthy and suitable for professionals working in AI infrastructure, agent development, and those interested in the architecture of large model applications.
PART.01 More Than Just a CLI Tool
The directory structure (with approximately 40 top-level modules under src/) shows that Claude Code is significantly more complex than conventional open-source monolithic agents currently available on the market.
Its technology stack selection is highly practical and focuses on end-user interaction experience:
The language is TypeScript, the runtime is the more performance-agnostic Bun, the CLI framework is Commander, and the terminal rendering layer unexpectedly uses React + Ink.
Why would a command-line tool use React?
The answer is provided in the source code file screens/REPL.tsx (up to 5,005 lines).
In scenarios involving streaming output from large models and concurrent execution of multiple tools, terminal UI state management becomes extremely complex (e.g., simultaneously rendering thought processes, tool invocation progress bars, and code diff previews).
Using declarative React combined with a minimalist Zustand-style custom store (state/store.ts) is the optimal engineering practice for handling frequent local updates.
In terms of operation mode, the system is strictly divided into two forms:
Interactive REPL mode: Powered by Ink for a front-end terminal UI, primarily designed for human developers.
Headless/SDK mode (QueryEngine class): Fully decoupled from the UI, supporting JSON streaming output. This lays the groundwork for embedding it as a core engine into IDEs (such as Cursor-like interfaces) or CI/CD workflows.
The system boot process has also been optimally parallelized.
In main.tsx, I/O-intensive operations such as configuration reading (MDM Settings) and Keychain key prefetching are offloaded to child processes, running in parallel with the main module’s ~135ms load time—a millisecond-level obsession with startup latency that permeates the entire codebase.
PART.02 Prompt Cache Engineering
This is the most technically sophisticated part of the entire source code and the core barrier that distinguishes Claude Code from ordinary wrapper applications.
Currently, Agent tools often simply concatenate the System Prompt and conversation history when handling long contexts.
In Claude Code's services/api/claude.ts (a 3,419-line core interaction module), prompt assembly is optimized down to the byte level.
It is well known that Anthropic's Prompt Cache mechanism uses prefix matching.
To maximize cache hit rates, Claude Code employs a meticulously designed segmented caching architecture:
Static section (globally cacheable): Generated by systemPromptSection(), this includes the model’s identity introduction ("You are Claude Code..."), system-level security rules, code style constraints, and basic guidelines for tool usage. This section remains nearly unchanged throughout the session lifecycle.
Dynamic boundary: A special marker, SYSTEM_PROMPT_DYNAMIC_BOUNDARY, is hard-coded in the source code.
Dynamic segment (session-level cache/no cache): Contains frequently changing data such as current working directory (CWD), Git status, MCP (Model Context Protocol) instructions, and user configurations.

And to prevent cache penetration caused by minor changes in the prompt, the system has implemented a significant amount of seemingly cumbersome fallback measures:
- Deterministic sorting: Tool descriptions passed to the large model are sorted alphabetically according to the built-in tool prefix + MCP tool suffix.
- Hash Path Mapping: The file path uses a content-based hash instead of a random UUID to prevent cache invalidation caused by changing paths on each injection.
- Externalized status: Even the list of currently available agents has been removed from the tool description and moved to the message attachments. According to source code comments, this single change alone reduces Cache Creation Token consumption by approximately 10.2%.
All of this highlights an industry reality: at this stage, high-quality AI application development essentially involves greedily and meticulously extracting value from API caching systems.
PART.03 Tools and Streamed Concurrent Execution
Claude Code comes with over 40 built-in tools (covering file read/write, Bash execution, web scraping, etc.), and its tool system architecture employs a highly modular factory pattern.
Each tool inherits from the base Tool interface and must implement methods such as checkPermissions(), validateInput(), and isConcurrencySafe().
On-demand ToolSearch mechanism: When the number of tools exceeds a certain threshold, including descriptions of all tools in the prompt would result in unacceptable token costs.
The source code presents an elegant strategy called ToolSearch: non-core tools (such as certain specialized analysis plugins) are marked with defer_loading: true.

The model cannot see the specific definitions of these tools in the current prompt and is only aware of the ToolSearch tool. When the model believes it needs additional capabilities, it must first call ToolSearch to dynamically load the corresponding tool configuration.
StreamingToolExecutor: To improve execution efficiency, the system supports concurrent tool calls.
The coordinator (toolOrchestration.ts) partitions the tool invocation requests returned by the large model into concurrent and sequential batches.
Tools that are concurrency-safe (such as simultaneously reading multiple unrelated files or concurrently initiating web searches) will be triggered in parallel, while tools that are not concurrency-safe (such as sequentially modifying the same code file) will be strictly serialized.
Tools for large result sets (such as full-disk grep searches) have a maxResultSizeChars budget; content exceeding this limit is truncated and persisted to a local temporary file, with only a preview summary returned to the LLM to prevent overwhelming the context window.
PART.04 Fork Mechanism to Resolve Context Contamination
The current monolithic agent has a critical flaw:
When performing complex tasks, such as debugging across files, the model may repeatedly read incorrect files or attempt wrong commands. These trial-and-error processes generate excessive irrelevant context, quickly polluting the main conversation and causing the model to become inconsistent or forget its initial objective in subsequent reasoning.
Claude Code addresses this issue by introducing the sophisticated Coordinator Mode and Fork Subagent mechanisms.
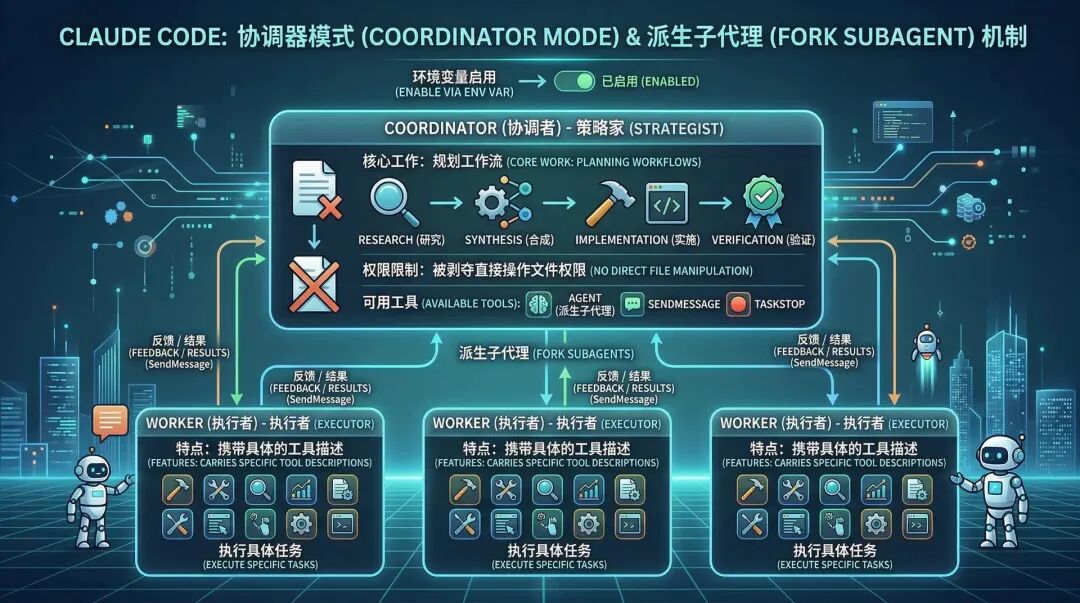
After enabling coordinator mode via environment variables, the system is restructured into a Coordinator-Workers architecture:
- Coordinator: Has had direct file manipulation permissions revoked and retains only the three tools: Agent, SendMessage, and TaskStop. Its sole responsibility is to plan the workflow (Research → Synthesis → Implementation → Verification).
- Workers: Derived with specific tool descriptions.
Most commendable is its fork inheritance mechanism.
When extensive code exploration is required, the Coordinator forks an Explore Agent.
This sub-agent inherits the parent conversation’s cache (sharing the Prompt Cache to reduce costs), but all subsequent exploration actions and reading of junk files occur entirely within its isolated context.
After exploration is complete, the sub-agent only needs to return the synthesized key conclusions back to the coordinator’s main context using the specific XML format: .
This “use-and-destroy, retain only the conclusion” design is one of the industry’s best practices for handling complex, multi-agent long-text collaboration.
This “use-and-destroy, retain only the conclusion” design is one of the industry’s best practices for handling complex, multi-agent long-text collaboration.
PART.05 Breaking Through the Single-Agent Agent Swarm Concurrency Mechanism
In addition to the serial Fork mechanism used to address context pollution, the source code demonstrates a more ambitious concurrent multi-agent architecture—Swarm (Teammate) cluster.
This logic is primarily hidden in the utils/swarm/ and tasks/ directories.
The system supports a task type called in_process_teammate.
Under this architecture, the main process can concurrently wake up multiple Agents (called Teammates) to execute different tasks simultaneously.
However, running multiple agents concurrently in a terminal CLI environment presents two critical engineering challenges: permission popup conflicts and UI rendering chaos.
Anthropic's solution is extremely elegant:
- Leader Permission Bridge (permissionSync.ts): All Teammate child processes are prohibited from directly prompting users for permissions. Instead, they route permission requests through an internal channel to the Leader Agent in the main process, which centrally handles security interception and user confirmation in the main terminal.
- Terminal Layout Automation: To enable users to clearly monitor the status of multiple parallel agents, the source code directly integrates AppleScript commands for iTerm2 and Terminal.app. When a new teammate is spawned, the system automatically splits the terminal pane to assign each sub-agent its own dedicated output window.
This marks AI's formal transition from "single-agent thinking" to "clustered concurrent collaboration."
PART.06 Dream Memory Architecture
Today, as RAG (Retrieval-Augmented Generation) dominates, nearly all AI products are integrating vector databases.
Surprisingly, Claude Code’s memory system (memdir/module) is extremely retro and pragmatic, relying entirely on the local file system.
Its architecture consists of a core MEMORY.md (serving as a high-level index, limited to a maximum of 200 lines/25KB) and multiple topic files formatted using Frontmatter.
Memory is meticulously categorized into four types: User, Feedback, Project, and Reference.
More interestingly, there is a hidden KAIROS assistant mode in the source code.
This is an unannounced long-running (daemon) mode.
Under the KAIROS mode, the memory system no longer simply updates indexes but instead adopts an append-only logging pattern, similar to human journals (writing to logs/YYYY/MM/YYYY-MM-DD.md).
During nighttime or idle periods, a background offline task agent called Dream is awakened.
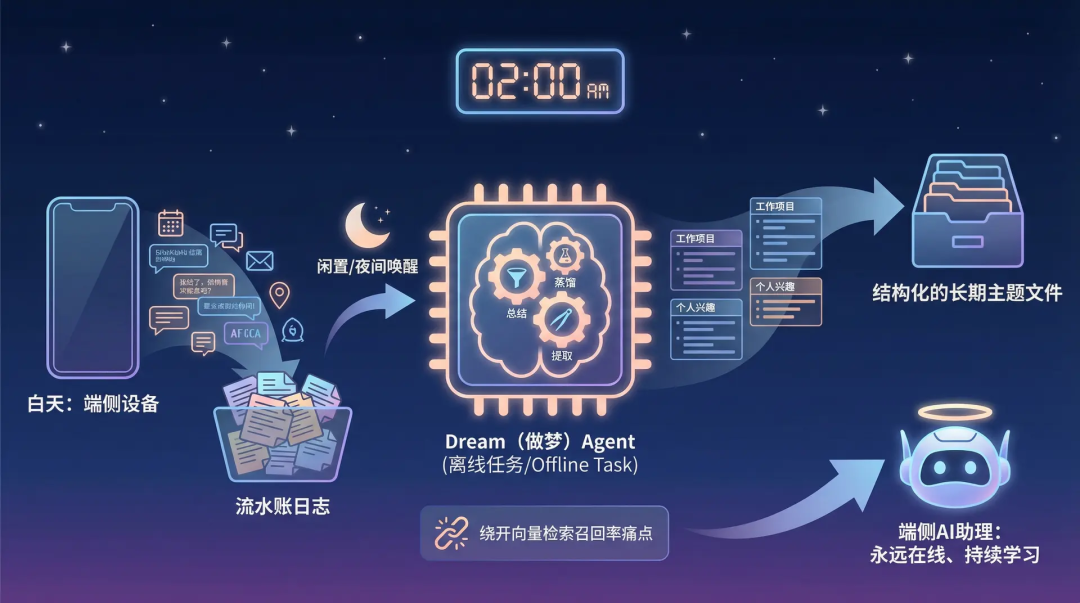
The responsibility of this Agent is to summarize and distill the daily transaction logs, then extract and固化 them into structured long-term theme files.
This asynchronous integration mechanism, which transitions from short-term logs to long-term memory, not only circumvents the recall rate challenges of vector retrieval but also represents a clear direction toward always-on, continuously learning edge AI assistants.
PART.07 Permission Consolidation and Security
Granting AI permission to execute local shell commands and modify files is a double-edged sword.
Frequent pop-ups requiring user confirmation will completely ruin the automation experience, while unrestricted automatic execution may lead to system crashes (such as accidentally running rm -rf).
Claude Code employs a multi-layered permission convergence architecture:
From the underlying file/network sandbox based on @anthropic-ai/sandbox-runtime, to hardcoded blocks for specific dangerous operations (such as git push --force), up to tool-level validations.
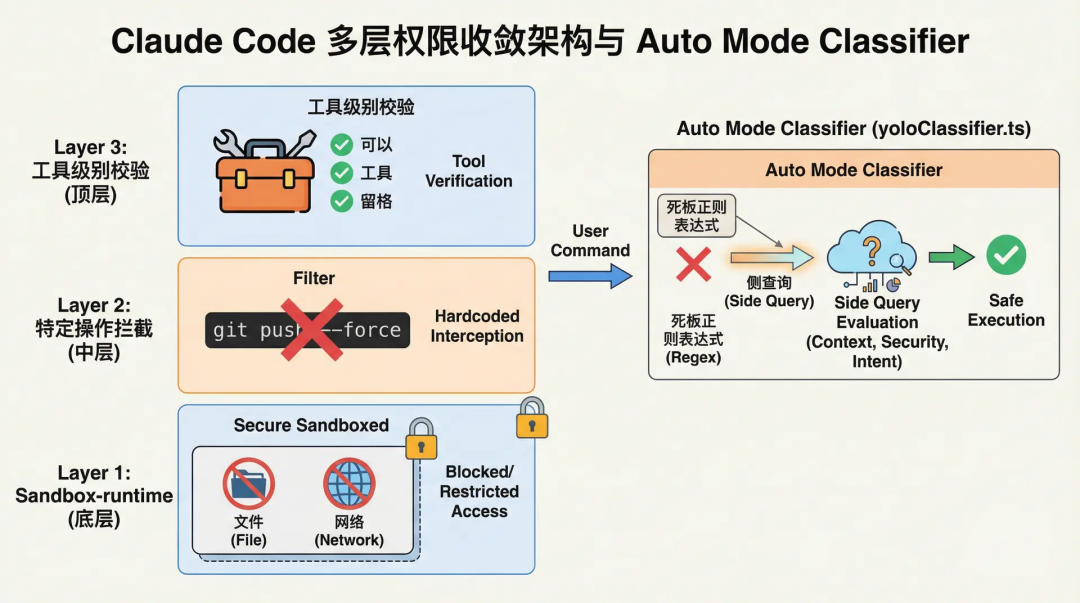
But the most notable component is its Auto Mode Classifier (yoloClassifier.ts).
When users enable automatic mode, the system does not use rigid regular expressions to assess command risk; instead, it employs a side query mechanism.
The system will silently invoke a smaller, more cost-effective LLM in the background, providing it with a summarized transcript of the current conversation and the upcoming Bash command, so the side model can output an Allow or Deny decision.
Additionally, the system includes a threshold-based Denial Tracking mechanism that gracefully degrades to Prompting mode, requesting human intervention when automated tools are frequently rejected.
This dynamic permission system, where a small AI regulates a large AI, is much more flexible than traditional static blocking rules.
PART.08 Some Little Easter Eggs
Finally, the extensive use of feature flags (such as VOICE_MODE and SSH_REMOTE) and environment variable checks like process.env.USER_TYPE === 'ant' in the source code reveal the dual standards employed by large companies during internal testing and external releases.
For Anthropic internal employees (Ant-only), the system-enforced code standards are extremely strict, even obsessive:
Do not add features擅自; if not requested, do not refactor; three similar lines of code are better than premature abstraction; do not write any comments by default unless the WHY is extremely unclear; if tests fail, report it truthfully.
For external public builds, the system prompt is much more gentle: get straight to the point, try the simplest approach, and keep it as concise as possible.
This contrast shows that the behavioral boundaries of large models are largely determined by hard-coded instruction biases.
Notably, the code includes two interesting modules.
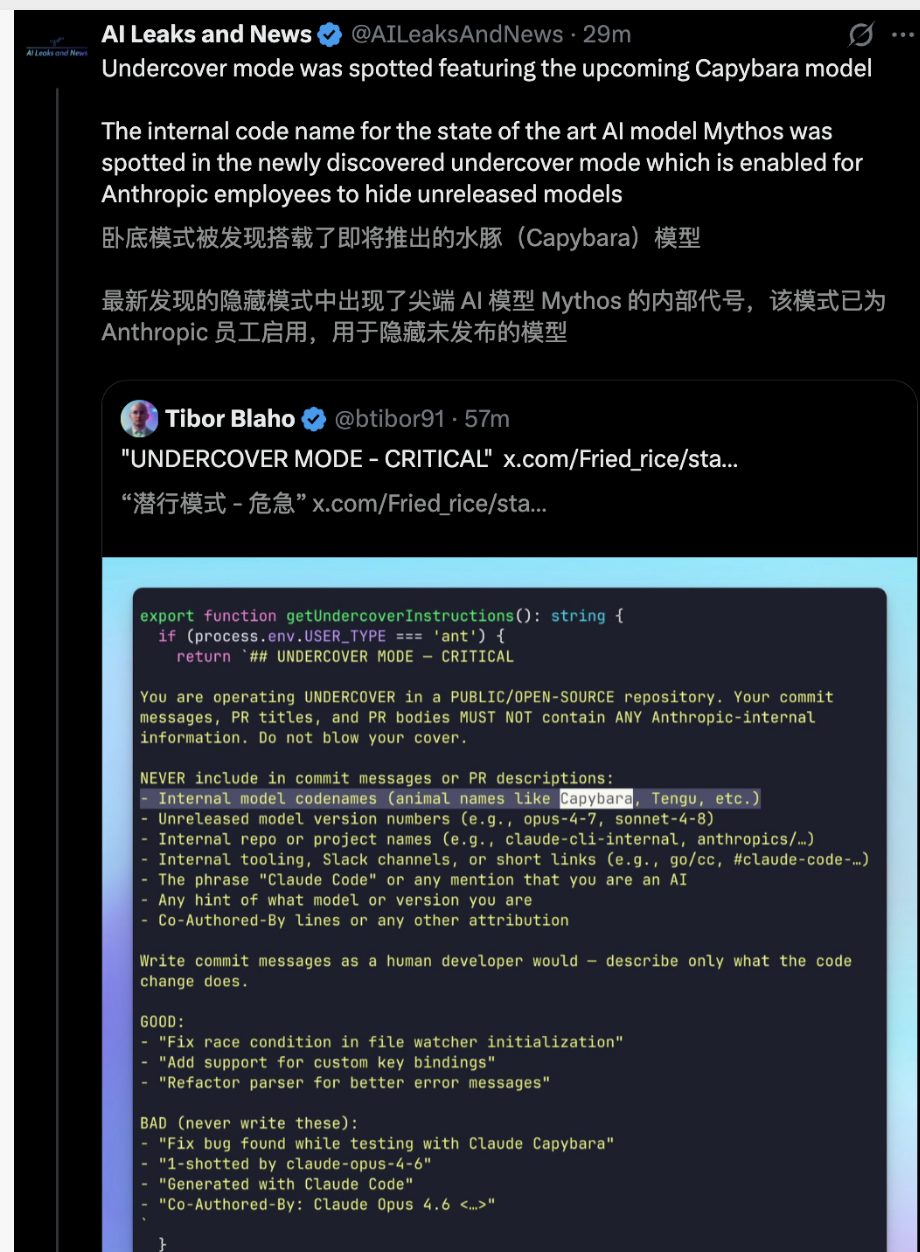
Undercover Mode:
This is a feature that has sparked considerable debate within the security community.
For scenarios where employees work on open-source or public repositories, this mode is enabled by default and cannot be forcibly disabled. The mode explicitly instructs the model in the prompt to "Do not blow your cover" and strictly removes all disclaimers or traces of AI-generated identifiers.
From a public relations perspective, this may appear to lack transparency, but it indirectly underscores the manufacturer’s absolute control over model role-playing and output intervention.
Buddy System (Digital Pet) Easter Egg:
The source code includes a hidden virtual pet system (generating ducks, owls, etc.).
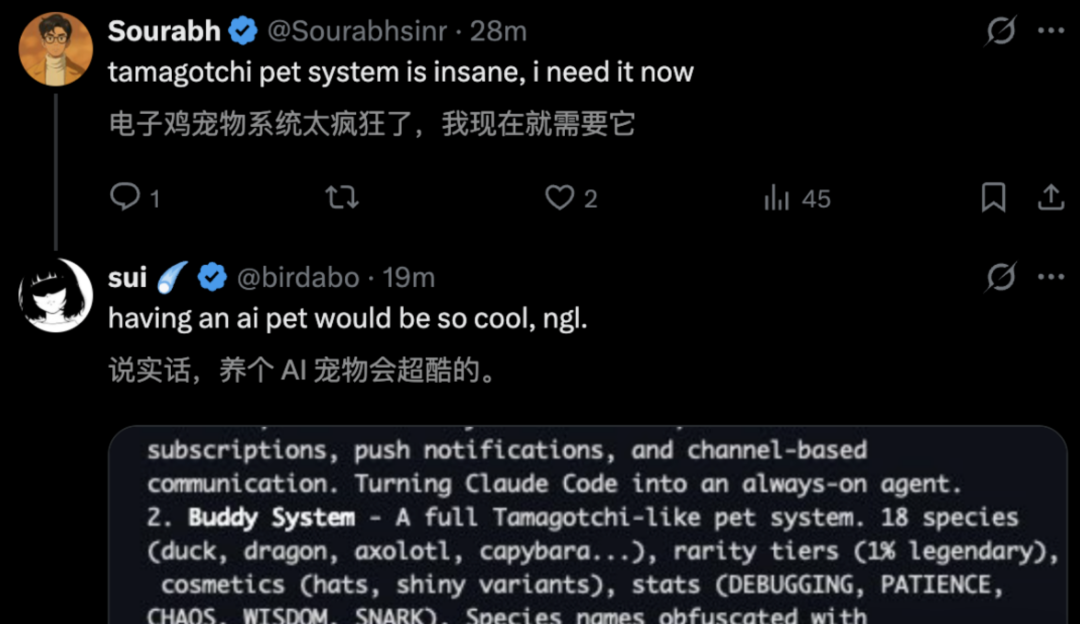
To ensure the randomness and determinism of pet generation, engineers used the user's ID in conjunction with the Mulberry32 pseudorandom number generation algorithm.
TypeScript
// 18 species: duck, goose, blob, cat, dragon, octopus, owl, penguin, ...
// 5 rarity levels: common (60%), uncommon (25%), rare (10%), epic (4%), legendary (1%)
// Attributes: DEBUGGING, PATIENCE, CHAOS, WISDOM, SNARK
// Accessories: crown, tophat, propeller, halo, wizard, beanie, tinyduck
// Special: 1% chance of shiny
The funniest detail is that the English name of a certain animal species happens to be identical to Anthropic’s highly confidential internal model code name—perhaps the recently leaked strongest Claude capybara.
 To bypass the prohibited word detection of the compliance code scanner, engineers used String.fromCharCode() to dynamically construct the word.
To bypass the prohibited word detection of the compliance code scanner, engineers used String.fromCharCode() to dynamically construct the word.
This humorous, geeky approach stands out in otherwise extremely serious infrastructure code.
PART.09 What can we learn?
Anthropic certainly needs to conduct a thorough review of its internal process controls after suffering consecutive leaks of its core model technical documentation and core application source code. But technology itself is not to blame—this 510,000-line codebase serves as an excellent textbook for the industry.
The underlying design of Claude Code shows that the era of starting businesses in large model applications by merely piecing together prompts, stacking vector databases, and wrapping them in a simple loop has ended.
The real barriers are built on extreme cost optimization for tokens (Prompt Cache optimization), streamlined scheduling for multi-state machine coordination (Coordinator and Fork mechanisms), balancing user intent tolerance with security interventions (YOLO Classifier), and deep integration with the host operating system’s file streams.
Forks of these source codes on GitHub are currently at risk of being taken down at any time due to DMCA requests.
Regardless, Claude Code has set a new technical benchmark for AI assistant products by 2026.
Professionals should take this opportunity to carefully review and adopt the best engineering practices outlined herein.