









The second half of AI programming is no longer about raw context length, but about task decomposition, error correction, and execution stability over extended time periods.
Article author, source: 0x9999in1, ME News
TL;DR
- The open-source comeback: Kimi K2.6 is now officially open-sourced and its API is publicly available, directly surpassing closed-source giants like GPT-5.4 and Claude Opus 4.6 on core programming benchmarks such as SWE-Bench Pro, reshaping the industry landscape.
- Unyielding endurance: Breaking through the “sprint” limitations of traditional AI, K2.6 demonstrates long-range execution capabilities of up to 12 hours and over 4,000 tool calls, transforming AI from a mere “code completion tool” into a fully independent outsourced team.
- The Rise of the Digital Legion: Agent Swarm receives an epic upgrade, capable of orchestrating 300 parallel sub-agents in a single run, effortlessly handling high-concurrency, high-complexity system-level reconstruction tasks.
- Full-stack and around-the-clock: Address frontend animation gaps with support for complex 3D effects; deliver 24/7 proactive agent capabilities, marking the beginning of a new era of “human-machine collaboration with machine leadership.”
- Clear conclusion: In the second half of programming AI, the competition is no longer about raw context length, but about task decomposition, error correction, and execution stability over extended time spans. K2.6 has secured this extremely expensive ticket.
Intro: While the world sleeps, machines race forward
At three a.m., Zhongguancun is quiet, and the office buildings in Silicon Valley are quiet too.
The human programmer's optic nerves are dry and aching from staring at the screen for too long; the stimulant effect of caffeine has long been swallowed by exhaustion. They close their laptop and fall into a deep sleep.
But in the unseen server room, the fans are roaring.
Thousands of lines of code were deleted and rewritten. Compilation failed. Debugging. Rewritten again.
The tool has been invoked a thousand times, two thousand times, three thousand times.
No emotions. No complaints. No tired physical body in need of a vacation.
This is not science fiction. This is a deep-sea bomb just thrown into the tech world by Moonshot AI—the new generation of open-source flagship programming model, Kimi K2.6.
Last year, we were spoiled by large models. We got used to giving AI a prompt and watching it magically spit out dozens of lines of Python code. We called it a “productivity revolution.”
But is this really a revolution?
No, it's just a slightly smarter typewriter.
Real programming is messy. It requires diving into hundreds of thousands of lines of legacy code to untangle complex, intertwined dependencies; it demands configuring cumbersome environments and getting compilers for obscure languages to work; and when bugs arise, it demands the ability to iterate and fix them yourself—not just shrugging and throwing an Error and leaving you to figure it out.
Kimi K2.6 tells you that the typewriter era is over.
The era of fully automated driving has officially arrived.
Top Rankings and Breakthrough: The Open Source Camp’s “D-Day Landing”
The world has long suffered from closed-source systems.
In the past, models were seen as two types: one category included closed-source flagship models like GPT-5.4 or Claude Opus, which stood at the pinnacle of performance; the other consisted of open-source models, which were affordable and flexible but often struggled when faced with demanding engineering challenges.
Open source always seems to be looked down upon.
Until K2.6 slammed a cold, hard report card on the table.
This is not just a victory in performance. It is a precise strike against the closed-source iron curtain.
Let’s look at this data. On the authoritative ranking evaluating AI’s ability to solve real GitHub issues, K2.6 didn’t play around in niche corners—it drew its sword right on the most demanding battlefield.
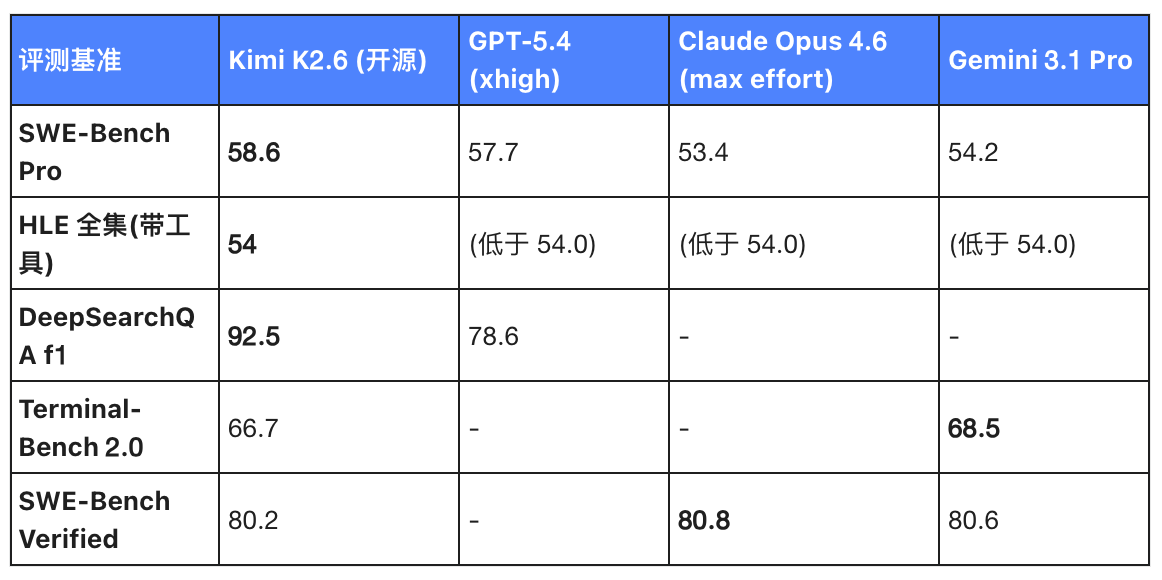
Table 1: Comparison of Kimi K2.6 with leading proprietary flagship models on programming benchmarks
Do you understand these numbers?
On the highly prestigious SWE-Bench Pro "practical simulator," K2.6 scored 58.6.
What concept? It outperformed all three of the leading models: GPT-5.4, Claude Opus 4.6, and Gemini 3.1 Pro.
In the HLE full set (with tools) test, K2.6's score of 54.0 far outperformed all others, leaving all three closed-source giants behind.
Regarding the DeepSearchQA F1 score for deep reasoning, K2.6’s 92.5 significantly outperforms GPT-5.4’s 78.6, demonstrating a decisive generational advantage.
Although K2.6 is only on par with (or even slightly behind) Gemini 3.1 Pro and Opus 4.6 in Terminal-Bench 2.0 and SWE-Bench Verified, this is entirely inconsequential.
Why? Because it is open source.
In the open-source community, there have historically been almost no options capable of matching the performance of proprietary flagship programs at this level of programming benchmarks. This is the harsh reality.
And now, K2.6 is like the D-Day invasion of World War II—it not only breached the closed-source防线, but also successfully established a beachhead. It tells all developers: the highest level of programming expertise is no longer a proprietary asset locked away in API safes by just a few big companies.
Say goodbye to the “passenger” and embrace the “digital contractor”
The benchmark score is very high. Great. But can a benchmark score put food on the table?
No.
What truly sent a chill down my spine were the two sets of "long-range execution" test results casually released on the Moonshot official blog.
Previous AI was like a sprinter—extremely powerful in bursts, capable of writing a short function of dozens of lines and leaving everyone amazed.
But what if you ask it to maintain a large-scale project? Sorry, its memory will fade, its logic will collapse, it will get stuck in an endless loop, and ultimately output a jumble of meaningless gibberish.
What about K2.6? It’s a marathon runner—and a steel monster that doesn’t need water or breath.
Twelve hours of silent battle
Let's look at the first case.
Task: Rewrite the Qwen3.5-0.8B inference code in Zig on a local Mac.
Zig is what? A highly niche, hardcore systems programming language. This is not a beginner-friendly language like Python, which has libraries available everywhere. Writing a reasoning engine in Zig is like tightrope walking off a cliff with your eyes closed.
A human programmer taking on this task would first need to spend a week learning the syntax, then another half-month tuning memory.
How does K2.6 work?
It ran continuously for 12 hours.
The tool was invoked over 4,000 times.
14 rounds of downtrend have been completed.
Fourteen rounds of iteration mean it’s constantly experimenting and learning from mistakes: writing code, compiling, encountering errors, analyzing them, making corrections, and compiling again.
By the third error, humans might already be smashing their keyboards.
Machines won't. Machines will coldly execute the next make.
The result? Throughput surged from about 15 tokens/sec to 193 tokens/sec—roughly 20% faster than the established LM Studio.
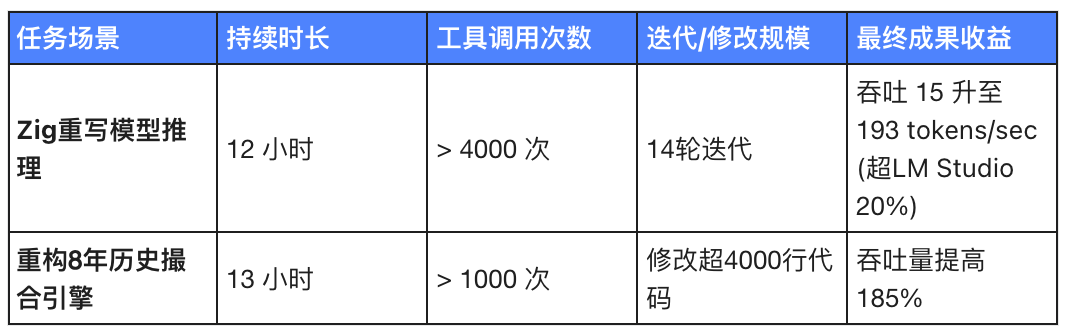
Table 2: Breakdown of Real-World Long-Range Execution Data for Kimi K2.6
Surgical removal of legacy code
The second case is even more extreme: taking over an 8-year-old open-source matching engine exchange-core.
Experienced programmers know what it means to take over “eight-year-old open-source code.”
It's like taking over a minefield that could explode at any moment, filled with unknown patches, untraceable dependencies, and baffling design philosophies.
When faced with this kind of code, humans typically have only one strategy: "If it works, don't touch it."
K2.6 Don't believe in superstition.
It went in.
Ran for 13 hours and invoked thousands of tools.
It acted like a cold-hearted surgeon, cutting into this giant, modifying over 4,000 lines of code, and even reconfiguring the core thread topology—from 4ME+2RE directly overhauled to 2ME+1RE.
As a result, throughput increased by 185%.
What does this indicate?
This demonstrates that K2.6 possesses exceptional depth of generalization across timeframes, languages, and tasks.
From frontend to DevOps, from performance optimization to core architecture refactoring, it is no longer just an advanced toy that can only write "Hello World"—it now has the capability to independently handle complex engineering transformations.
It is no longer your Copilot.
It’s your Tech Lead, your senior outsourced team, the digital foreman who never takes the system down.
From solo operations to a "digital swarm": the dimensional reduction strike of computing power
The power of the monolithic model is only half the story.
K2.6 brings another terrifying weapon: the epic evolution of Agent Swarm.

Table 3: Agent Swarm Evolution Comparison (K2.5 vs K2.6)
Imagine you need to develop a mid-sized e-commerce backend.
In the past, you broke tasks into pieces and assigned them to ten programmers, held daily stand-ups, coordinated interfaces, and argued with each other.
Now, give K2.6 an instruction.
In an instant, K2.6 splits into 300 parallel sub-agents.
Agent 1 writes the database table creation statements;
Agent 2 configures the Docker environment;
Agent 3 writes the user login logic;
……
Agent #300 is writing unit tests.
Generate over a hundred files with a single command.
This isn't coding anymore; this is "dumping" code.
The RL infrastructure team at Moonshot has run an autonomous operations agent for five days using this system.
5 days, 120 hours. No human intervention.
Server alert, Agent check the logs; out of memory, Agent kill the process and restart the service.
What does this mean? It means that basic DevOps roles are facing a genuine survival crisis.
Machines don't suffer from insomnia, don't need coffee, and won't curse when woken up at midnight by PagerDuty. They simply silently resolve the issue and log a cold, unemotional inspection entry.
Frontend awakening and around-the-clock "ghost"
If the backend's mundane code is K2.6's foundation, then this enhancement in frontend animations is its showcase of flair.
Previous large models could handle writing HTML/CSS fine, but would struggle with complex animations.
But K2.6 fully maxed out the frontend skill tree: video backgrounds, WebGL shaders, GSAP/Framer Motion, and even Three.js 3D effects.
Is this going to smash the front-enders' lunchboxes too?
Maybe not quite yet. But imagine a designer creating a stunning 3D interaction in Figma—a task that previously required a frontend engineer to spend a week fine-tuning WebGL. Now, K2.6 might build the underlying framework with just a few prompts, significantly raising the productivity ceiling for independent developers and small teams.
More interestingly, it supports "active agents."
K2.6 provides 24/7 autonomous operation for OpenClaw, Hermes Agent, and others.
Meanwhile, the newly added Claw Groups research preview feature supports “bring your own agent and command other agents.”
This sounds a bit awkward.
Machines are beginning to manage machines.
As a human, you become the "overall coordinator." You issue strategic intent, and K2.6 dispatches a lead agent, who then allocates tasks to 300 worker agents.
Humans have shifted from “doers” to “observers.”
This is a new form of human-machine collaboration. However, in this collaboration, the role of humans is becoming increasingly minimal.
Epilogue: When the tide goes out, who's swimming naked?
The release of Kimi K2.6 is a watershed moment.
It ruthlessly tore away the veil currently covering the AI programming field.
While you're still proud of your model generating Snake code, K2.6 is already performing surgical upgrades on an open-source matching engine that is eight years old.
While you're still figuring out how to improve your prompt, K2.6 has already invoked tools 4,000 times and completed a closed-loop iteration.
The full launch of K2.6 on Kimi.com, the Kimi App, the Open Platform API, and Kimi Code means that this incredibly powerful productivity has now been brought to the forefront, becoming an accessible infrastructure for everyone.
For the past month, it has been lurking internally under the name code-preview. Today, the giant has broken free from its cage.
We always like to ask: When will AI truly replace human programmers?
Actually, this is a false proposition.
Machines don’t need to “replace” you—they’re simply creating a whole new dimension of productivity, where producing 100,000 lines of high-quality, tested, and thoroughly validated code in a single day becomes standard.
Developers who can't keep up with this dimension don't need to be replaced—they will naturally be left behind by the times.
In the first half of the large model era, the competition was about writing poetry, painting, and delivering clever one-liners;
The second half of large models is about endurance, stability, and long-term execution.
The Dark Side of the Moon proved with K2.6: after turning sand into chips, humanity finally taught these chips how to think and work endlessly.
And all we need to do is wake up, sip our coffee, and review the empires they’ve built.
That's crazy, right?
But this is the truth.
Source:
- [1] Moonshot AI Official Blog. (2026). Kimi K2.6: The Next Generation Open-Source Coding Model and Agent Swarm. * [2] SWE-Bench Project Contributors. (2026). SWE-Bench Pro Leaderboard & Performance Analysis.
- [3] Kimi Code Release Notes. (2026). From code-preview to General Availability: The 12-Hour Autonomy Run.