









Author: Shenchao TechFlow
A paper claiming to reduce AI memory usage by 1/6 caused over $90 billion in market value to evaporate for global memory chip stocks, including Micron and SanDisk, last week.
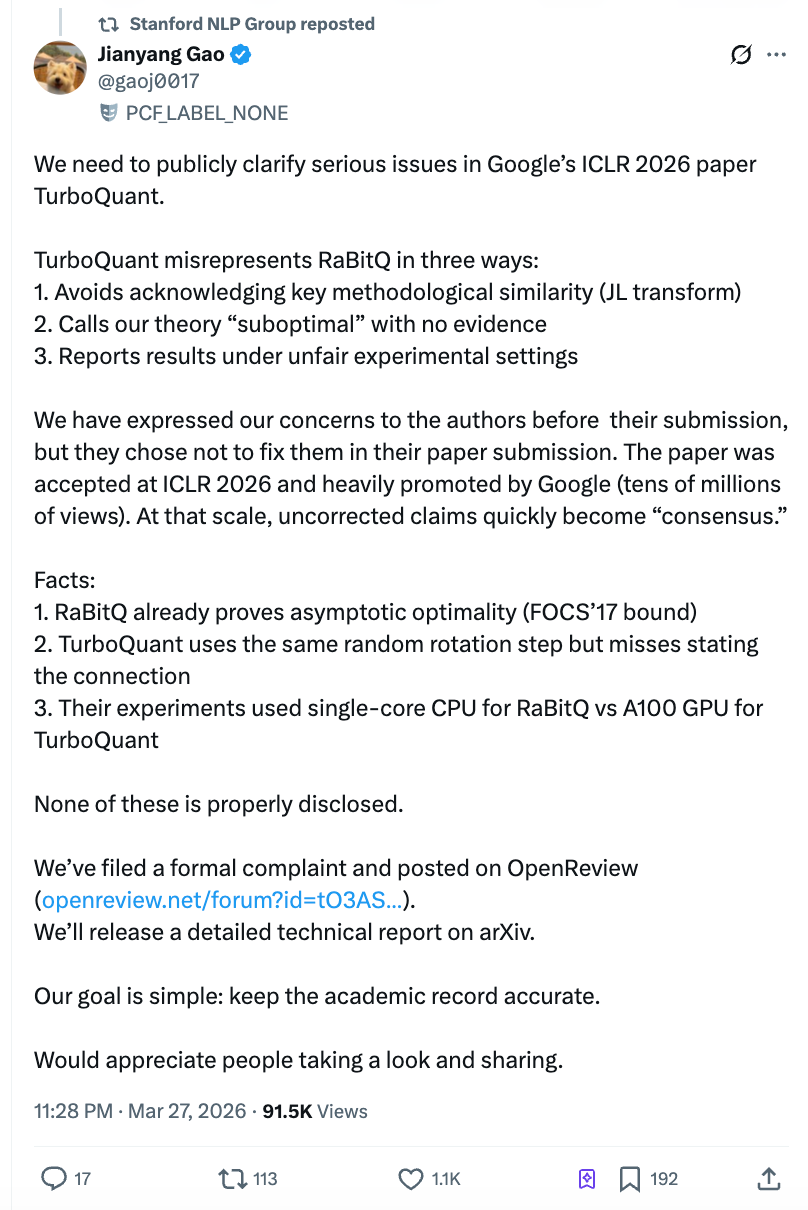
However, just two days after the paper's release, Gao Jianyang, a postdoctoral researcher at ETH Zurich—the team whose algorithm was allegedly "crushed"—published a 10,000-word open letter accusing the Google team of testing their opponent using a single-core CPU Python script while using an A100 GPU for their own tests, and refusing to correct the issue even after being informed prior to submission. The post quickly surpassed 4 million reads on Zhihu, was shared by the official Stanford NLP account, and sent shockwaves through both academia and the market.
(Reference reading: A paper that brought down the storage stock)
The core issue of this controversy is not complicated: Did an AI conference paper, heavily promoted by Google and directly triggering panic selling in the global chip sector, systematically misrepresent a previously published prior work and create a false narrative of performance superiority through deliberately unfair experiments?
What TurboQuant does: reduces AI's "scratch paper" to one-sixth of its original size
When large language models generate responses, they need to continuously write while referring back to previously computed content. These intermediate results are temporarily stored in GPU memory, a practice known in the industry as "KV Cache" (key-value cache). The longer the conversation, the thicker this "scratchpad" becomes, leading to higher GPU memory consumption and increased costs.
Google's research team developed the TurboQuant algorithm, whose key selling point is compressing this draft to just 1/6 of its original size, while claiming zero accuracy loss and up to 8x faster inference. The paper was first published on the academic preprint platform arXiv in April 2025, accepted by ICLR 2026, one of the top conferences in AI, in January 2026, and then repackaged and promoted by Google’s official blog on March 24.
From a technical standpoint, the concept behind TurboQuant can be simply understood as follows: first, apply a mathematical transformation to clean and standardize chaotic data, then compress it individually using a precomputed optimal compression table, and finally correct any computational errors introduced by compression with a single-bit error-correction mechanism. Independent community implementations have verified that the compression results are largely accurate, and the mathematical contributions at the algorithmic level are genuine.
The issue is not whether TurboQuant can be used, but what Google did to prove it was "far superior to competitors."
Gao Jianyang's Open Letter: Three Accusations, Each Hitting the Mark
On the evening of March 27, Gao Jianyang published a long article on Zhihu and simultaneously submitted a formal review on the ICLR official peer-review platform, OpenReview. Gao Jianyang is the first author of the RaBitQ algorithm, which was published in 2024 at SIGMOD, the premier conference in the field of databases, and addresses the same class of problems—efficient compression of high-dimensional vectors.
His allegations consist of three points, each supported by email records and a timeline.
Accusation one: Used someone else's core methodology without mentioning it anywhere in the text.
A key common step in the technical cores of TurboQuant and RaBitQ is performing a "random rotation" on the data before compression. This step transforms irregularly distributed data into a predictable uniform distribution, significantly reducing the complexity of compression. This is the most central and closely aligned part of both algorithms.
The author of TurboQuant also acknowledged this in their peer review response, yet never explicitly stated the connection between this method and RaBitQ anywhere in the full paper. More critically, in January 2025, Majid Daliri, the second author of TurboQuant, proactively reached out to the Gao Jianyang team to request help debugging a Python version he had modified from the RaBitQ source code. The email detailed the reproduction steps and error messages—indicating that the TurboQuant team had extensive knowledge of RaBitQ’s technical details.
An anonymous reviewer for ICLR also independently noted that both used the same technology and requested adequate discussion. However, in the final version of the paper, the TurboQuant team not only failed to add further discussion but also moved the (already incomplete) description of RaBitQ from the main text to the appendix.
Charge two: Unfoundedly labeling the other party's theory as "suboptimal."
TurboQuant's paper directly labels RaBitQ as "suboptimal," claiming its mathematical analysis is "crude." However, Gao Jianyang points out that the extended RaBitQ paper has rigorously proven its compression error achieves the theoretical optimal bound—a conclusion published at a top-tier conference in theoretical computer science.
In May 2025, Gao Jianyang's team provided detailed explanations via multiple emails regarding the optimality of the RaBitQ theory. Daliri, the second author of TurboQuant, confirmed that all authors had been informed. However, the paper ultimately retained the wording "suboptimal" without providing any counterarguments.
Charge three: In the experimental comparison, "left hand binds a person, right hand holds a knife."
This is the most damaging point in the entire article. Gao Jianyang points out that the TurboQuant paper added two layers of unfair conditions in the speed comparison experiments:
First, RaBitQ’s official team provided optimized C++ code (with multi-threading parallelism enabled by default), but the TurboQuant team did not use it; instead, they tested RaBitQ using their own translated Python version. Second, the RaBitQ test was conducted on a single-core CPU with multi-threading disabled, while TurboQuant used an NVIDIA A100 GPU.
The combined effect of these two conditions is that readers conclude that "RaBitQ is orders of magnitude slower than TurboQuant," without realizing that this conclusion is based on the Google team handicapping their opponent before the race. The paper does not adequately disclose these differences in experimental conditions.
Google's response: "Random rotation is a general technique; it's not feasible to cite every instance."
According to Gao Jianyang, the TurboQuant team stated in a March 2026 email reply: "The use of random rotations and Johnson-Lindenstrauss transforms is already standard practice in this field, and we cannot cite every paper that employs these methods."
Gao Jianyang's team believes this is a case of equivocation: the issue is not whether all papers using random rotation should be cited, but that RaBitQ was the first work to combine this method with vector compression and prove its optimality under exactly the same problem setup, and the TurboQuant paper should accurately describe the relationship between the two.
The Stanford NLP Group's official X account retweeted Gao Jianyang's statement. Gao Jianyang's team has published a public comment on the ICLR OpenReview platform and submitted a formal complaint to the ICLR conference chair and ethics committee, with a detailed technical report to be released on arXiv next.
Independent tech blogger Dario Salvati provided a relatively neutral assessment in his analysis: TurboQuant does make genuine contributions in its mathematical approach, but its relationship with RaBitQ is much closer than the paper suggests.
$90 billion in market cap evaporates: paper controversy叠加 market panic
The timing of this academic controversy was extremely delicate. After Google released TurboQuant via its official blog on March 24, the global memory chip sector suffered a sharp sell-off. According to multiple media outlets including CNBC, Micron Technology declined for six consecutive trading days, accumulating a loss of over 20%; SanDisk fell 11% in a single day; South Korea’s SK Hynix dropped about 6%, Samsung Electronics declined nearly 5%, and Japan’s Kioxia fell approximately 6%. The market’s panic logic was straightforward: if software compression can reduce AI inference memory requirements by sixfold, the future demand for memory chips will face a structural downgrade.
Morgan Stanley analyst Joseph Moore refuted this logic in a research report on March 26, maintaining an "Overweight" rating on Micron and SanDisk. Moore noted that TurboQuant compresses only this specific type of cache—KV Cache—not overall memory usage, and characterized it as "a normal productivity improvement." Wells Fargo analyst Andrew Rocha similarly invoked Jevons' Paradox, arguing that efficiency gains that reduce costs may instead stimulate larger-scale AI deployment, ultimately increasing memory demand.
Old papers, new packaging: The transmission chain risk from AI research to market narratives
According to tech blogger Ben Pouladian, the TurboQuant paper was publicly released in April 2025 and is not new research. On March 24, Google repackaged and promoted it via its official blog, yet the market priced it as a groundbreaking breakthrough. This “old paper, new release” marketing strategy, combined with potential experimental biases in the paper, highlights systemic risks in the transmission chain from academic research to market narratives in AI.
For investors in AI infrastructure, when a paper claims to have achieved performance improvements of "several orders of magnitude," the first question to ask is whether the benchmarking conditions were fair.
Gao Jianyang's team has clearly stated that they will continue to push for the formal resolution of the issue. Google has not yet issued a formal response to the specific allegations in the open letter.