
Written by: Zack Pokorny
Compiled by Chopper, Foresight News
The deployment of AI agents on blockchain has not proceeded smoothly. Although blockchain possesses programmability and permissionless characteristics, it lacks the semantic abstraction and coordination layers required to support agents. According to a research report released by the crypto research firm Galaxy, AI agents on-chain face four structural frictions: opportunity discovery, trustworthy verification, data retrieval, and execution workflows. Existing infrastructure remains designed around human interaction and struggles to support AI-driven autonomous asset management and strategy execution, forming the core bottlenecks to the scalable deployment of agents on blockchain. Below is the full translated report:
The applications and capabilities of AI agents are beginning to evolve. They are now being developed to autonomously execute tasks, hold and allocate capital, and identify trading and yield strategies. Although this experimental shift is still in its earliest stages, it marks a significant departure from the previous paradigm in which agents primarily served as social and analytical tools.
Blockchain is becoming the natural proving ground for this evolution. Blockchain is permissionless, composable, features an open-source application ecosystem, provides equal data access to all participants, and makes all on-chain assets programmable by default.
This raises a structural question: if blockchains are programmable and permissionless, why do autonomous agents still face friction? The answer lies not in whether execution is feasible, but in the amount of semantic and coordination overhead imposed on top of execution. Blockchains guarantee the correctness of state transitions, but they typically do not provide protocol-native abstractions for economic interpretation, canonical identity, or goal-level coordination.
Some friction stems from architectural flaws in permissionless systems, while some reflects the current state of tools, content management, and market infrastructure. In practice, many upper-layer functions still rely on software and workflows that require manual intervention to build and operate.
Blockchain Architecture and AI Agents
The design of blockchain revolves around consensus and deterministic execution, rather than semantic interpretation. It exposes low-level primitives such as storage slots, event logs, and call traces, not standardized economic objects. Therefore, abstract concepts such as positions, yields, health factors, and liquidity depth typically require off-chain reconstruction by indexers, data analysis layers, front-end interfaces, and APIs to transform protocol-specific states into more usable forms.
Many mainstream decentralized finance workflows, particularly those targeting retail users and subjective decision-making, still revolve around the model where users interact via a front-end interface and sign individual transactions. This user-interface-centric model has expanded alongside the rise of retail participation, even though a significant portion of on-chain activity is now machine-driven. The prevailing retail interaction model remains: intent → user interface → transaction → confirmation. Programmatic operations follow a different path but are similarly constrained: developers pre-select contracts and asset sets during development and then run algorithms within this fixed scope. Neither model can accommodate systems that must dynamically discover, evaluate, and compose operations at runtime based on evolving objectives.
Friction arises when infrastructure optimized for transaction verification is used by systems that must simultaneously interpret economic conditions, assess creditworthiness, and optimize behavior around defined objectives. These gaps stem partly from blockchain’s permissionless and heterogeneous design, and partly from interaction tools that still revolve around manual review and front-end intermediaries.
Comparison of Agent Behavior Workflow with Traditional Algorithm Strategies
Before examining the gap between blockchain infrastructure and agent systems, it is essential to clarify: what distinguishes behavior processes with greater intelligent autonomy from traditional on-chain algorithmic systems?
The difference does not lie in the level of automation, complexity, parameterization, or even dynamic adaptability. Traditional algorithmic systems can achieve high parameterization, automatically discover new contracts and tokens, allocate funds across multiple strategy types, and rebalance based on performance. The true distinction is whether the system can handle scenarios unforeseen during the building phase.
Traditional algorithmic systems, no matter how complex, only execute predefined logic for predefined patterns. They require predefined interface parsers for each type of protocol, predefined evaluation logic to map contract states into economic meanings, explicit rules for credit and standardization judgments, and hard-coded rules for every decision branch. When encountering situations that do not match predefined patterns, the system either skips them or fails outright. It cannot reason about unfamiliar scenarios—it can only determine whether the current scenario matches a known template.
Like this "digesting duck" mechanical automaton, it can mimic biological behavior, but all movements are pre-programmed.
A traditional algorithm scanning DeFi lending markets can identify newly deployed contracts that emit familiar events or match known factory patterns. However, if a novel lending primitive with an unfamiliar interface emerges, the system cannot evaluate it. Human intervention is required to audit the contract, understand its mechanics, determine whether it represents a挖掘 opportunity, and write the integration logic. Only after this can the algorithm interact with it. Humans interpret; algorithms execute. Agent systems based on foundational models are shifting this boundary by enabling learned reasoning capabilities:
- Interpret vague or incomplete objectives. Instructions such as “maximize returns while avoiding excessive risk” require semantic interpretation. What constitutes excessive risk? How should returns be balanced against risk? Traditional algorithms require these criteria to be precisely defined in advance. Agents, however, can interpret intent, make judgments, and refine their understanding based on feedback.
- It can generalize and adapt to unfamiliar interfaces. The agent can read unfamiliar smart contract code, parse documentation, or examine previously unseen application binary interfaces to infer the economic functions of the system. It does not require pre-built parsers for each type of protocol. Although this capability is still imperfect and the agent may misinterpret what it observes, it can attempt to interact with systems it has not encountered during the build phase.
- Reason under uncertainty regarding trust and normativity. When credit signals are ambiguous or incomplete, the foundational model can probabilistically weigh the signals rather than applying rigid binary rules. Does this smart contract adhere to standards? Based on available evidence, is this token legitimate? Traditional algorithms either follow predefined rules or have no recourse; whereas agents can reason about levels of confidence.
- Explain the error and make adjustments. When unexpected situations occur, the agent can reason about the root cause and determine an appropriate response. In contrast, traditional algorithms merely execute exception-handling modules, forwarding exception information without interpretation.
These capabilities currently exist but are not perfect. Foundation models can generate hallucinations, misinterpret content, and make confidently stated yet incorrect decisions. In adversarial environments involving capital—where code can control or receive assets—"attempting to interact with unforeseen systems" could mean financial loss. The core argument of this paper is not that agents can now reliably perform these functions, but that they can attempt them in ways traditional systems cannot, and that future infrastructure will make these attempts safer and more reliable.
This distinction should be viewed as a continuum rather than an absolute categorical boundary. Some traditional systems incorporate forms of learned reasoning, and some agents may still rely on hardcoded rules along critical paths. This difference is directional, not strictly binary. Agent systems shift more interpretation, evaluation, and adaptation work to runtime reasoning rather than predefining rules during the build phase. This point is crucial to the discussion of friction, because agent systems aim to achieve what traditional algorithms deliberately avoid. Traditional algorithms circumvent discovery friction by having humans curate the set of contracts during the build phase; they avoid control-layer friction by relying on operator-maintained whitelists; they bypass data friction by using prebuilt parsers for known protocols; and they evade execution friction by operating within predefined security boundaries. Humans handle semantic, credit, and strategic work upfront, while algorithms simply execute within these predefined limits. Early on-chain agent behaviors may follow this model, but the core value of agents lies in moving discovery, credit, and strategic evaluation into runtime reasoning—not predefining them during the build phase.
They attempt to discover and evaluate novel opportunities, reason about norms without hardcoded rules, interpret heterogeneous states without predefined parsers, and enforce strategic constraints against potentially ambiguous objectives. The friction arises not because agents are doing the same things as algorithms but with greater difficulty, but because they are attempting fundamentally different things: operating within an open, dynamically interpreted space of behaviors, rather than within a closed, pre-integrated system.
Friction
From a structural perspective, this contradiction does not stem from a flaw in blockchain consensus, but rather from the way the overall interaction stack built around it operates.
Blockchain ensures deterministic state transitions, consensus on the final state, and finality. It does not attempt to encode economic meaning interpretation, intent verification, or goal tracking at the protocol level. These responsibilities have traditionally been handled by front-end interfaces, wallets, indexers, and other off-chain coordination layers, all of which have always required human intervention.
Even among seasoned participants, the prevailing interaction model reflects this design: retail users interpret status via dashboards, select actions through user interfaces, and sign transactions via wallets, informally verifying outcomes. Algorithmic trading firms achieve automated execution but still rely on human operators to filter protocol sets, monitor for anomalies, and update integration logic when interfaces change. In both scenarios, the protocol is solely responsible for ensuring correct execution, while interpretation of intent, anomaly handling, and adaptation to new opportunities are all performed by humans.
Agent systems compress or even eliminate this division of labor. They must programmatically reconstruct economically meaningful states, assess progress toward goals, and verify execution outcomes—not merely confirm that transactions are on-chain. On blockchains, these burdens are especially pronounced, as agents operate in open, adversarial, and rapidly changing environments where new contracts, assets, and execution paths can emerge without centralized review. Protocols guarantee only that transactions are executed correctly; they do not ensure that economic states are easily interpretable, contracts are standardized, execution paths align with user intent, or relevant opportunities can be programmatically discovered.
The following will systematically address these friction points across the various stages of the agent's operational cycle: identifying existing contracts and opportunities, verifying their legitimacy, obtaining economically meaningful states, and executing actions aligned with objectives.
Discover friction
Friction arises because the behavioral space of decentralized finance expands openly in a permissionless environment, while relevance and legitimacy are filtered by humans through on-chain social, market, and tool layers. New protocols emerge through announcements and are then filtered through layers such as frontend integration, token listings, data analytics platforms, and liquidity formation. Over time, these signals often coalesce into a viable standard for distinguishing which parts of the behavioral space possess economic value and sufficient trustworthiness—even though this consensus may be informal, uneven, and partially reliant on third parties and manual curation.
Agents can be provided with curated data and credit signals, but they lack the intuitive shortcuts humans use to interpret these signals. From an on-chain perspective, all deployed contracts are equally discoverable. Legitimate protocols, malicious forks, test deployments, and abandoned projects all exist as callable bytecode. The blockchain itself does not encode which contracts are important or secure.
Therefore, the agent must build its own discovery mechanism: scanning deployment events, identifying interface patterns, tracking factory contracts (contracts that can programmatically deploy other contracts), and monitoring liquidity formation to determine which contracts should be included in its decision-making scope. This process is not merely about finding contracts, but about assessing whether they should enter the agent’s action space.
Identifying candidates is only the first step. After initial discovery, contracts must undergo the validation processes for standardization and authenticity described in the next section. The agent must confirm that the discovered contract lives up to its name before including it in the decision space.
Discovering friction does not refer to detecting newly deployed behaviors. Mature algorithmic systems are already capable of achieving this within their own strategies. Searchers that monitor Uniswap factory events and automatically include newly created pools are performing dynamic discovery. Friction arises at two higher levels: determining whether the discovered contract is legitimate, and assessing whether it is relevant to open-ended objectives, rather than merely matching predefined strategy types.
The searcher’s discovery logic is tightly bound to its strategy. It knows what interface patterns to look for because the strategy has been defined. However, an agent tasked with broader directives, such as “configure risk-adjusted optimal opportunities,” cannot rely solely on filters derived from the strategy. It must evaluate newly encountered opportunities against the goal itself, requiring it to parse unfamiliar interfaces, infer economic functions, and determine whether the opportunity should be included in the decision space. This is, to some extent, a problem of general autonomy—but blockchain exacerbates this challenge.
Control layer friction
The generation of friction in the control layer arises because identity and legitimacy verification are typically performed outside the protocol, relying comprehensively on screening, governance, documentation, interfaces, and operator judgment. In many current workflows, humans remain a critical part of the verification process. While blockchain ensures deterministic execution and finality, it does not guarantee that the caller is interacting with the intended contract. This intent verification is externalized to social contexts, websites, and manual screening.
In the current process, humans treat the website’s credibility layer as an informal verification method. They visit the official domain—often found through aggregation platforms like DeFiLlama or verified social media accounts—and regard the site as the standard medium mapping human-recognized entities to contract addresses. This then establishes a practical trusted baseline for the frontend interface, clearly identifying which addresses are official, which token symbols to use, and which entry points are secure.

The Mechanical Turk of 1789 was a chess-playing machine that appeared to operate autonomously but was in fact controlled by a hidden human operator.
Agents cannot inherently interpret brand identifiers, authenticated social signals, or "officialness" within social contexts. While filtered data derived from these signals can be provided to agents, transforming them into persistent, usable machine trust assumptions requires explicit registries, policies, or verification logic. Operators can configure agents with curated allowlists, authenticated addresses, and trust policies. The issue is not that social context is entirely inaccessible, but that maintaining these safeguards becomes operationally costly in a dynamically expanding behavioral space, and when these measures are absent or incomplete, agents lack the fallback verification mechanisms humans naturally employ.
On-chain agent-driven systems have already produced tangible consequences due to weak credit assessment. In the case of crypto influencer Orangie, an agent allegedly deposited funds into a honeypot contract. In another case, an agent named Lobstar Wilde, due to a state or context error, misjudged an address’s status and transferred a large token balance to an online “beggar.” These cases are not central arguments, but they sufficiently illustrate how failures in credit assessment, state interpretation, and execution strategies can directly lead to fund losses.
The issue is not that contracts are hard to find, but that blockchains typically lack a native concept of “this is the official contract for this application.” This absence is, to some extent, a feature of permissionless systems rather than a design flaw, yet it still creates coordination challenges for autonomous systems. This problem stems partly from the open system architecture’s weak standard identity mechanisms and partly from immature registries, standards, and trust distribution mechanisms. An agent attempting to interact with Aave v3 must determine which addresses are the canonical ones, and whether those addresses are immutable, upgradeable via proxies, or currently subject to pending governance changes.
Humans address this issue through documents, front-end interfaces, and social media. Agents must determine this by verifying the following:
- Agency Model and Implementation Key Points
- Access Control and Time Lock
- Parameter update module for governance control
- Bytecode / Application Binary Interface match known between deployments
In the absence of a standardized registry, "officialness" becomes a matter of inference. This means agents cannot treat contract addresses as static configurations. Instead, they must either maintain a continuously verified allowlist, dynamically rediscover standardness at runtime via proxy checks and governance monitoring, or accept the risk of interacting with abandoned, compromised, or imitated contracts. In traditional software and market infrastructure, service identity is typically anchored by namespaces, credentials, and access controls maintained by institutions. In contrast, on-chain, a contract may be callable and function properly, yet from the caller’s perspective, it lacks economic or business standardness.
Token authenticity and metadata are the same issue. Tokens appear to self-describe, but token metadata is not authoritative—it is merely byte data returned by the code. A classic example is Wrapped Ether (WETH). The widely used WETH contract code explicitly defines the name, symbol, and decimals.
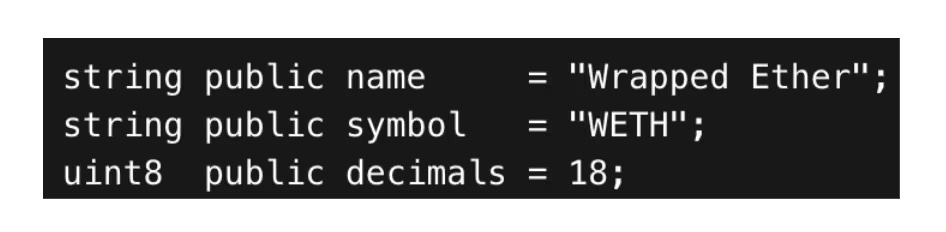
This appears to be an identity identifier, but it is not. Any contract can set:
- symbol() = WETH
- decimals() = 18
- name() = Wrapped Ether
And implement the same ERC-20 token standard interface. The functions name(), symbol(), and decimals() are merely public read-only functions that return arbitrary values set by the deployer. In fact, there are nearly 200 tokens on Ethereum with the name "Wrapped Ether," symbol "WETH," and precision of 18 decimals. Without checking CoinGecko or Etherscan, could you tell which "WETH" is the standard version?
Agents face this exact situation. Blockchain does not verify uniqueness, cross-check against any registry, or impose any restrictions. Today, you could deploy 500 contracts, all returning identical metadata. On-chain, there are some heuristic methods for detection—for example, checking whether Ethereum balances match total supply, querying liquidity depth on major decentralized exchanges, or verifying whether the asset is accepted as collateral in lending protocols—but none provide absolute proof. Each method either relies on threshold assumptions or recursively depends on the standardization verification of other contracts.

Just as finding the "true" path in a maze requires external guidance, there is no native standard signal on-chain.
This is why token lists and registries exist as off-chain filtering layers—they provide a way to map concepts like "WETH" to specific addresses, which is why wallets and front-end interfaces maintain whitelists or rely on trusted aggregation platforms. For agents, the core issue is not just low metadata reliability, but that standard identities are typically established at social or institutional levels, not natively by the protocol. While reliable on-chain identifiers are contract addresses, mapping human intentions like "swap for USDC" to the correct address still heavily depends on non-native protocol filtering, registries, whitelists, or other trust layers.
Data friction
An agent optimizing allocations across DeFi protocols must standardize each opportunity as an economic object: yield, liquidity depth, risk parameters, fee structures, oracle sources, and more. In some ways, this is a common systems integration problem. However, on-chain, protocol heterogeneity, direct capital exposure, multi-call state stitching, and the absence of a unified economic model at the underlying layer exacerbate this challenge—yet these are precisely the essential elements required to compare opportunities, simulate allocations, and monitor risk.
Blockchains typically do not expose standardized economic objects at the protocol level. Instead, they expose storage slots, event logs, and function outputs, from which economic objects must be inferred or reconstructed. The protocol only guarantees that contract calls return correct state values; it does not guarantee that these values can be clearly mapped to readable economic concepts, nor that the same economic concepts can be retrieved through a consistent interface across protocols.
Therefore, abstract concepts such as markets, positions, and health factors are not protocol primitives. They are reconstructed off-chain by indexers, data analytics platforms, frontend interfaces, and APIs, transforming heterogeneous protocol states into usable abstractions. Human users typically see only this standardized layer. Agents can also use this layer, but in doing so, they inherit third-party patterns, latency, and trust assumptions; otherwise, they must reconstruct these abstractions themselves.
This issue is becoming increasingly prominent across various protocols. The share price of treasuries, collateralization ratios in lending markets, liquidity depth of decentralized exchange pools, and staking contract reward rates are all economically significant foundational components, yet none have standardized interfaces for access. Each protocol type has its own methods of retrieval, structural layout, and unit conventions. Even within the same category, implementations vary.
Lending Market: Retrieve fragmented case studies
The lending market clearly illustrates this issue. While the economic concepts—such as supply and borrowing liquidity, interest rates, loan-to-value ratios, credit limits, and liquidation thresholds—are universal and largely consistent, the ways to access them vary significantly.
In Aave v3, market enumeration and reserve state retrieval are two separate steps. The typical process is as follows:
List reserve assets and return an array of token addresses.

For each asset, retrieve liquidity and interest rate baseline data using another code snippet.

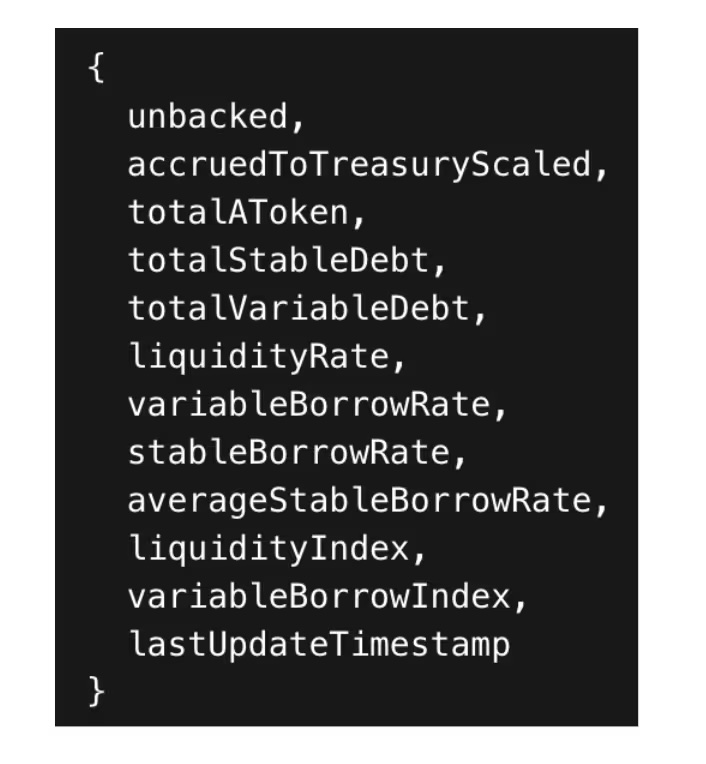
This method returns a structure containing the total liquidity, interest rate index, and configuration flags with a single call, for example:
In contrast, each deployment in Compound v3 corresponds to a single market (USDC, USDT, ETH, etc.), with no unified reserve structure. Instead, market snapshots must be assembled through multiple function calls:
- Base utilization
- Total supply
- Interest rate
- Collateral asset allocation
- Global Configuration Parameters
Each call returns only a different subset of the economic state. "Market" is not a top-level object, but rather an inferred structure constructed by the caller.
From an agent’s perspective, both protocols are lending markets; however, from an integration standpoint, they are systems with entirely different structures. There is no unified, shared model. Instead, agents must employ distinct asset enumeration methods for each protocol and stitch together state through multiple calls.
Fragmentation introduces latency and consistency risks.
In addition to structural inconsistency, this fragmentation introduces latency and consistency risks. Since the economic state is not exposed as a single atomic market object, agents must reconstruct snapshots across multiple contracts through multiple remote procedure calls. Each additional call increases latency, throttling risks, and the probability of block inconsistency. In volatile environments, by the time the supply rate is calculated, the rate may already have changed; without explicitly locking a block, configuration parameters may correspond to a different block height than the total liquidity. Users rely on UI caching layers and aggregated backends to indirectly mitigate these issues. Agents directly interacting with raw RPC interfaces must explicitly manage synchronization, batching, and temporal consistency. Therefore, non-standardized retrieval not only creates integration challenges but also limits performance, synchronization, and correctness.
Due to the lack of a standardized economic data retrieval system, even protocols that implement nearly identical financial primitives exhibit state exposure that depends on the specific implementation and composition of their contracts. These structural differences are a core component of data friction.
Potential data stream mismatch
Access to the economic state on the blockchain is inherently a pull model, even though execution signals can be streamed. External systems query nodes for the required state rather than receiving continuous, structured updates. This model reflects the blockchain’s core function of on-demand verification rather than maintaining a persistent, application-level view of state.
Push primitives exist. WebSocket subscriptions can stream new blocks and event logs in real time, but these do not include the storage state that carries most of the economic significance, unless the protocol explicitly chooses to redundantly publish them. Agents cannot directly subscribe on-chain to borrow market utilization, pool reserves, or position health factors. These values are stored in contract storage, and most protocols do not provide native mechanisms to push this information to downstream consumers. The current optimal pattern is to subscribe to new block headers and re-query all data on each block. Logs can only indicate that a state may have changed, but they do not encode the final economic state; reconstructing that state still requires explicit reads and historical state access.
Agent systems may benefit from a push-based approach. Instead of polling hundreds of contracts for state changes, agents can receive structured, precomputed state updates directly pushed to their execution environment. A push-based architecture reduces redundant queries, lowers latency between state changes and agent perception, and allows intermediate layers to bundle state into semantically meaningful updates, rather than requiring agents to interpret meaning from raw storage data.
This reverse shift is not easy. It requires subscription-based infrastructure, logic to filter relevance, and patterns to transform stored changes into economically actionable events for agents. But as agents become persistent participants rather than intermittent queryers, the inefficiency costs of the pull model grow increasingly high. Infrastructure that treats agents as continuous consumers rather than intermittent clients may better align with how autonomous systems operate.
Whether push-based infrastructure is truly superior remains an open question. Massive state changes create filtering challenges, and agents still need to determine which changes are relevant, reintroducing pull-based semantics at another level. The issue is not with pull-based architecture itself, but rather that current architectural designs do not account for persistent machine consumers. As agent usage scales, it may be worth exploring alternative models.
Execution friction
Friction arises because many current interaction layers bundle intention translation, transaction review, and outcome verification into workflows designed around frontend interfaces, wallets, and operator oversight. In retail and subjective decision-making scenarios, this oversight is typically performed by humans. For autonomous systems, these functions must be formalized and directly encoded. While blockchains guarantee deterministic execution based on contract logic, they do not ensure that transactions align with user intent, comply with risk constraints, or achieve desired economic outcomes. In current workflows, user interfaces and humans fill this gap.
User interface sequence of combined actions (exchange, approve, deposit, borrow), with the wallet providing the final "Review and Send" node, where users or operators typically make informal strategic judgments at the last step. They often assess whether a transaction is secure and whether the quoted outcome is acceptable, even with incomplete information. If a transaction fails or yields unexpected results, users may retry, adjust slippage, change the route, or abandon the operation entirely. The agent system removes humans from this execution loop, meaning the system must replace these three human functions with machine-native alternatives:
- Intent integration. Human goals such as “Transfer my stablecoin to the risk-adjusted optimal yield venue” must be integrated into specific action plans: selecting which protocol, which market, which token pathway, what scale, which authorizations, and the execution sequence. For humans, this process is implicitly handled through the user interface; for agents, it must be formally implemented.
- Strategy enforcement. Clicking "Send Transaction" is not just a signature—it also implicitly checks whether the transaction complies with constraints: slippage tolerance, leverage limits, minimum health factor, whitelist contracts, or "prohibit upgradeable contracts." The agent must encode explicit strategy constraints as machine-verifiable rules:
- The execution system must verify that the proposed call graph satisfies these rules before broadcasting.
- Result verification. A transaction being on-chain does not equate to task completion. Even if a transaction executes successfully, the intended goal may still not be achieved: slippage may exceed tolerance thresholds, the target position size may not be reached due to capacity limits, or interest rates may have changed between simulation and on-chain execution. Humans informally verify outcomes by reviewing the user interface afterward. Agents, however, must programmatically evaluate post-conditions.
This introduces the need for completion checks, not just simple transaction inclusion. Intent-centric architectures can partially address this by shifting more of the "how" execution burden from agents to specialized solvers. By broadcasting signed intents rather than raw call data, agents can specify outcome-based constraints that solvers or protocol-level mechanisms must satisfy for execution to be acceptable.
Multi-step workflow and failure modes
Most DeFi execution workflows are inherently multi-step. A yield configuration may require completing authorization → swap → deposit → borrow → stake. Some steps may be individual transactions, while others can be bundled via multicall or routing contracts. Humans can tolerate partially completed workflows and return to the UI to continue the process. Agents, however, require deterministic workflow orchestration: if any step fails, the agent must decide whether to retry, reroute, rollback, or pause.
This has given rise to new failure modes that are largely hidden in human processes:
- State drift between decision and on-chain execution. Between simulation and execution, interest rates, utilization, or liquidity may change. Humans accept this variability; agents must define acceptable ranges and enforce them.
- Non-atomic execution with partial fills. Some operations may span multiple transactions or produce partial results. The agent must track intermediate states and verify that the final state aligns with the target.
- Authorization limits and approval risks. Humans inadvertently sign authorizations through the user interface; agents must reason about the scope of authorization (limit, user, duration) as part of their security policy, not merely as a UI step.
- Path selection and implicit execution costs. Humans rely on routing contracts and default user interface settings. Agents must incorporate slippage, maximum extractable value risk, gas costs, and price impact into their objective function.
Execute: Native machine control issue
The core argument of execution friction is that the interaction layer of decentralized finance relies on human wallet signatures as the final control plane. This step carries current intent verification, risk tolerance, and informal "is this reasonable?" judgments. Removing humans turns execution into a control problem: agents must translate goals into behavioral patterns, autonomously enforce strategy constraints, and verify outcomes under uncertainty. This challenge exists in many autonomous systems, but the blockchain environment is especially harsh: execution directly involves capital, composes with unfamiliar contracts, and is exposed to adversarial state changes. Humans make decisions using heuristics and correct errors through trial and error. Agents must perform the same tasks programmatically at machine speed, often within dynamically changing behavioral spaces. Therefore, the claim that "agents simply need to submit transactions" underestimates the difficulty—submitting transactions is the easiest part.
Conclusion
The original design of blockchain was not intended to natively provide the semantic and coordination layers required by agents. Its goal is to ensure deterministic execution and consensus on state transitions in adversarial environments. The interaction layer built upon this foundation has evolved around human users interpreting state through interfaces, selecting actions via front-end interfaces, and verifying outcomes through manual review.
Agent systems disrupt this architecture by removing human interpreters, approvers, and verifiers from the loop, requiring these functions to be natively implemented by machines. This shift reveals structural friction across four dimensions: discovery, credit assessment, data acquisition, and execution workflows. These frictions arise not because execution is infeasible, but because the infrastructure surrounding blockchain still generally assumes human involvement between state interpretation and transaction submission.
Bridging these gaps will likely require building new infrastructure across multiple layers of the technology stack: normalizing cross-protocol economic states into machine-readable middleware; indexing services or remote procedure call extensions for semantic primitives such as positions, health factors, and opportunity sets; a registry providing standardized contract mappings and token authenticity verification; and an execution framework that encodes strategy constraints, handles multi-step workflows, and programmatically verifies goal completion. Some gaps arise from the structural characteristics of permissionless systems: open deployment, weak standard identities, and heterogeneous interfaces. Others depend on current tools, standards, and incentive designs; as agent adoption scales and protocols compete to optimize for seamless integration with autonomous systems, these gaps are expected to narrow.
As autonomous systems begin to manage capital, execute strategies, and interact directly with on-chain applications, the architectural assumptions of the current interaction layer will become increasingly apparent. Most of the friction described in this paper stems from the fact that blockchain tools and interaction patterns have evolved around human-mediated workflows; some friction arises from the openness, heterogeneity, and adversarial nature of permissionless systems; and another portion reflects challenges commonly faced by autonomous systems in complex environments.
The core challenge is not getting the agent to sign transactions, but providing it with a reliable means to perform the semantic interpretation, credit assessment, and strategy execution that are currently shared between software and human judgment between blockchain states and operational behaviors.