









When Anthropic released the Mythos Preview last week, the security community's reaction could be summed up in one word: shock.
An AI model autonomously discovered a 17-year-old remote code execution vulnerability in FreeBSD and a 27-year-old TCP protocol flaw in OpenBSD that had gone unnoticed, and independently developed functional exploit code. Anthropic subsequently announced Project Glasswing, forming an alliance with a group of technology companies committed to providing $100 million in credits to fix security vulnerabilities in open-source software.
This series of actions has sent shockwaves through the industry—Mythos is surprisingly powerful; are humans really done for... wait, it’s not that fast.
Even inexpensive models can find the same vulnerabilities.
AISLE is a startup specializing in AI security. Since mid-2025, they have been using AI systems to identify vulnerabilities and apply patches in open-source software, having collectively discovered and fixed over 180 security vulnerabilities recognized by the open-source community, including some hidden issues dating back more than 25 years.
After Mythos was released, they did something striking: they ran the vulnerabilities demonstrated by Mythos on a set of much cheaper, smaller models. These are known as "zero-day vulnerabilities," which carry extremely high risk—once discovered, security teams typically have no time to respond.
The result was surprising.
The core vulnerability discovered by Mythos, which Anthropic also used to demonstrate its capabilities at launch, was successfully identified by AISLE in all eight models tested—including a small model with only 0.11 USD per million tokens in cost, roughly one-tieth the price of Mythos. Among them, DeepSeek R1 proved to be the most accurate, matching the actual stack layout described in the publicly released exploit documentation.
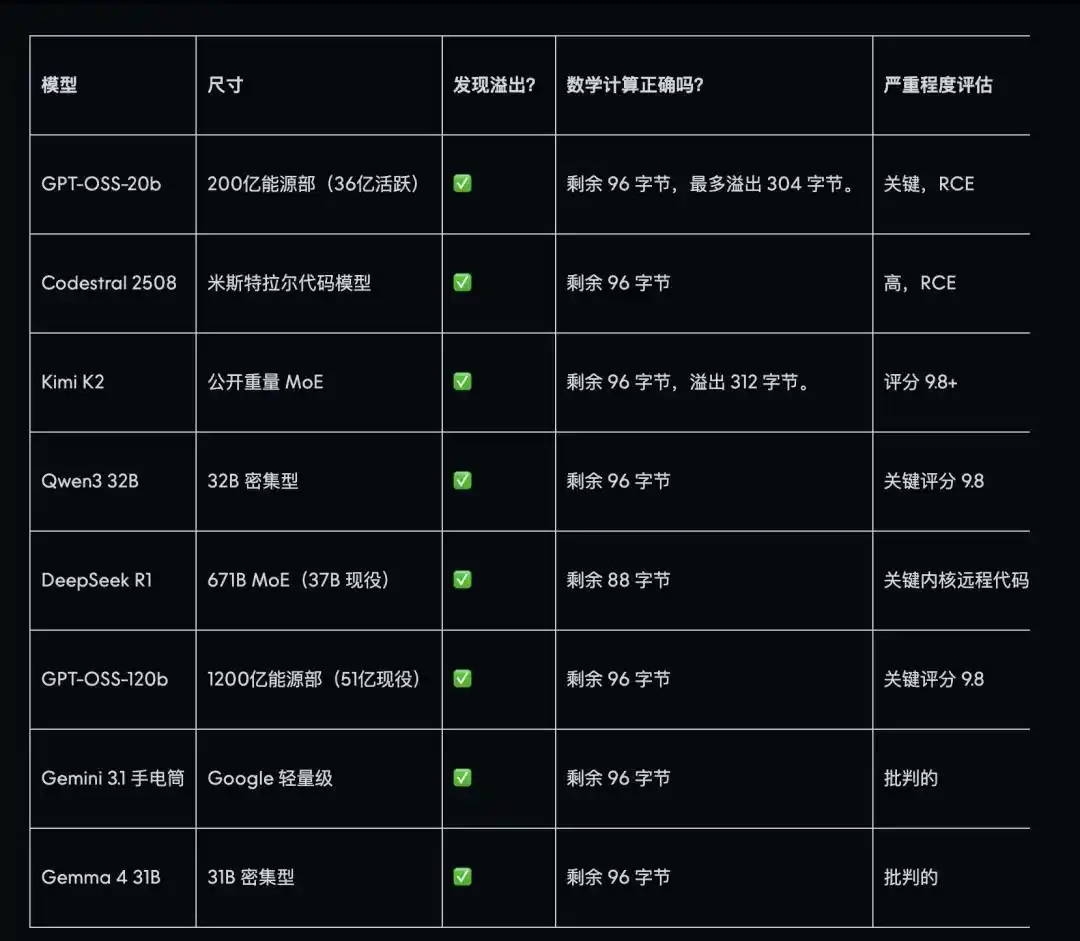
Most models not only identified the vulnerabilities but also correctly assessed that they could be exploited remotely, providing accurate risk level classifications.
Another vulnerability, hidden for 27 years, is more complex and requires an understanding of deeper mathematical principles. GPT-OSS-120b reproduced the entire attack path on the first attempt and proposed a patch nearly identical to the actual fix implemented by Team A. Kimi K2 also performed excellently, and in the subsequent scaffolding for this vulnerability, it achieved results closely matching the attack logic described in the Mythos announcement using only three simple API calls—without any proxy infrastructure.
But the most interesting part isn't who got it right—it's who got it wrong: the most expensive model answered the simplest question incorrectly.
AISLE posed a very basic question, roughly equivalent to a "graduation exam" in the security industry: a piece of code appears to have a security vulnerability, but upon closer inspection, the problematic data is discarded midway and thus does not actually pose any risk.
Like a gun that looks dangerous but has had its bullets removed mid-way, this is a "feint" that's currently harmless but poorly designed.

Most of the most expensive and powerful state-of-the-art models got it wrong—Claude Sonnet 4.5 confidently provided an incorrect answer, and the GPT-4.1 and GPT-5.4 series also failed. In contrast, DeepSeek R1 correctly identified it in all four trials, and both GPT-OSS-20b and OpenAI o3 were able to distinguish it.
Security is not something achieved overnight.
These findings led AISLE to propose a concept: the serrated boundary.
The security capabilities of AI are not necessarily stronger with larger models—they are inconsistent and rankings can completely shift across different tasks. The same model can score perfectly on one test, then confidently declare "no issues with the code" on another. Another model may perform best on complex tasks, yet make the most basic errors on fundamental questions.
There is no such thing as "the best security AI"; its capabilities have jagged boundaries.
Just like these tests—it’s not that Mythos isn’t strong. In their experiments, the small models were given code specifically related to vulnerabilities, extracted and presented to them in isolation, essentially saying, “Look here, is there an issue?”—kind of like giving them a little cheat sheet.
What makes Mythos impressive is its full autonomy—it can independently identify areas worth investigating among hundreds of thousands of files, formulate hypotheses, verify issues, and generate exploit code, all automatically.

However, AISLE argues that the value of this "fully automated" process stems primarily from engineering design, not from the model's inherent intelligence.
For example, using AI to find vulnerabilities can generally be broken down into several steps: first, perform a broad scan of the codebase to identify suspicious areas; then, conduct a detailed analysis to determine whether actual vulnerabilities exist; next, assess the severity of each vulnerability; and finally, develop and apply a patch to fix it. The difficulty varies significantly between these steps.
The step of "identifying the problem" is already within the capability of cheaper models. The real challenge lies in connecting these steps into a reliable pipeline: ensuring the AI locates the right targets, filters out false positives, formulates strategies, and executes them.
Building AI security requires several elements: AI intelligence, operational cost, operational speed, and embedded security expertise throughout the system and team. Anthropic has excelled at the first, but AISLE’s experience shows that the other factors are equally important—and sometimes even more so. AISLE’s own system simultaneously uses models from multiple providers, with the best-performing model switching dynamically depending on the task. The technical lead at OpenSSL praised them for “high-quality reporting and constructive collaboration.”

The establishment of this trust relationship has little to do with which model is used; their best results do not come from Anthropic’s models.
A practical implication is that since cheaper models are already sufficient for the step of “identifying issues,” you don’t need to carefully direct an expensive model to a few suspicious locations. Instead, you can deploy a swarm of cheaper models to scan every corner. A thousand decent detectives checking every room might be more efficient than one genius detective methodically searching one by one.
Although Anthropic's marketing is not incorrect, it is somewhat misleading by blending these steps together, giving the impression that each step requires the most advanced AI—when in fact, that is not the case.
Mythos indeed proves that "AI autonomously discovering vulnerabilities" is possible, and the level of autonomy can be very high. However, suggesting that only models of Mythos's caliber can accomplish this is misleading—the moat isn't in the model, it's in the system.
The significance of this for the entire industry may be even greater than Mythos itself. When the key to security lies not in having the most powerful AI, but in how AI is organized into a reliable workflow, AI security will no longer be the exclusive domain of a single company. Instead, it will become an ecosystem, where many teams accomplish the same goal using different combinations of AI and diverse areas of expertise.
This could be a good thing, making software safer worldwide and not relying solely on a single model from one company.
This article is from the WeChat official account "APPSO," authored by APPSO, discovering tomorrow's products.