









DeepSeek's recent price adjustment forced the industry into a new cost era through a nonlinear, cliff-like decline.
Article author and source: 0x9999in1, ME News
TL;DR
- Price breaks the floor: By the end of April 2026, DeepSeek reduced the output price of its V4-Pro model to $0.878 per million tokens by combining limited-time discounts with caching reductions, and cached input prices dropped further to $0.0037 (approximately ¥0.025), completely shattering the pricing benchmark in the large model industry.
- A pricing gap has emerged between China and the U.S.: Compared with leading global vendors, the combined API cost of DeepSeek-V4-Pro is approximately one-thirtieth that of OpenAI’s GPT-5.5 and Anthropic’s Claude Opus, creating a highly significant cost advantage gap.
- Domestic competitive pressure is mounting: Under DeepSeek’s aggressive pricing, leading domestic models such as Zhipu’s GLM 5.1 and Moonshot’s Kimi K2.6 are facing significant commercial pressure and may be forced to follow suit with price cuts, accelerating industry consolidation.
- Cache hits become central to economics: DeepSeek has reduced cache hit pricing to one-tenth of the original rate, a strategy that fundamentally benefits long-text processing, RAG (Retrieval-Augmented Generation), and continuous multi-turn interaction scenarios for Agents.
- Think tank analysis conclusion: Foundation large models are rapidly becoming "infrastructure-like," similar to water and electricity; the future competitive focus will shift comprehensively from competition over single model parameter scale to optimization of inference costs and market share of developer ecosystems.
Introduction: The Inflection Point of Large Model Computing Costs
The advancement of technology is often accompanied by an exponential reduction in costs, a necessary path for any disruptive technology to achieve widespread adoption. On April 25–26, 2026, the AI industry witnessed a landmark moment: leading large model provider DeepSeek launched two “deep-water bombs” in succession. First, it announced a limited-time 75% discount on the API for the DeepSeek-V4-Pro model; shortly after, it revealed that for its entire API suite, the cost for input cache hits would be reduced to just one-tenth of the original price.
After two rounds of stacked pricing adjustments, the input cache hit price for DeepSeek-V4-Flash has dropped to an astonishing $0.0029 per million tokens (approximately ¥0.02) before May 5, 2026, while the input cache hit price for DeepSeek-V4-Pro, benchmarked against the world’s top tier, is only $0.0037 per million tokens (approximately ¥0.025).
Previously, the industry broadly predicted that large model inference costs would decrease at an annual rate of around 50%. However, DeepSeek’s recent price adjustment has triggered a nonlinear, cliff-like drop, forcibly ushering the industry into a new cost era. We believe this is far more than a simple marketing campaign or short-term “price war”—it is an inevitable outcome driven by fundamental algorithmic architecture optimizations (such as sparse attention mechanisms and advanced MoE architectures) and enhanced engineering capabilities of compute clusters. This report, based on the latest industry-wide pricing data, provides an in-depth analysis of the market disruption caused by DeepSeek’s price cut and offers a comparative assessment of the commercial competitiveness of leading global large models, aiming to deliver a clear roadmap of industry evolution for decision-makers.
Core phenomenon: Extreme breakdown of the DeepSeek-V4 series pricing structure
To understand the magnitude of this price reduction, we must examine the three core dimensions of large model API pricing: input price (cache miss), input price (cache hit), and output price. Past pricing models typically distinguished only between input and output, but as long-context technology matures, “cache hit rate” is becoming a pivotal variable reshaping API economics.
Pricing Strategy Breakdown: Discount Stacking and Cached Leverage
According to the latest published data, DeepSeek has implemented a three-pronged strategy of baseline price reduction, time-limited discounts, and cached leverage.
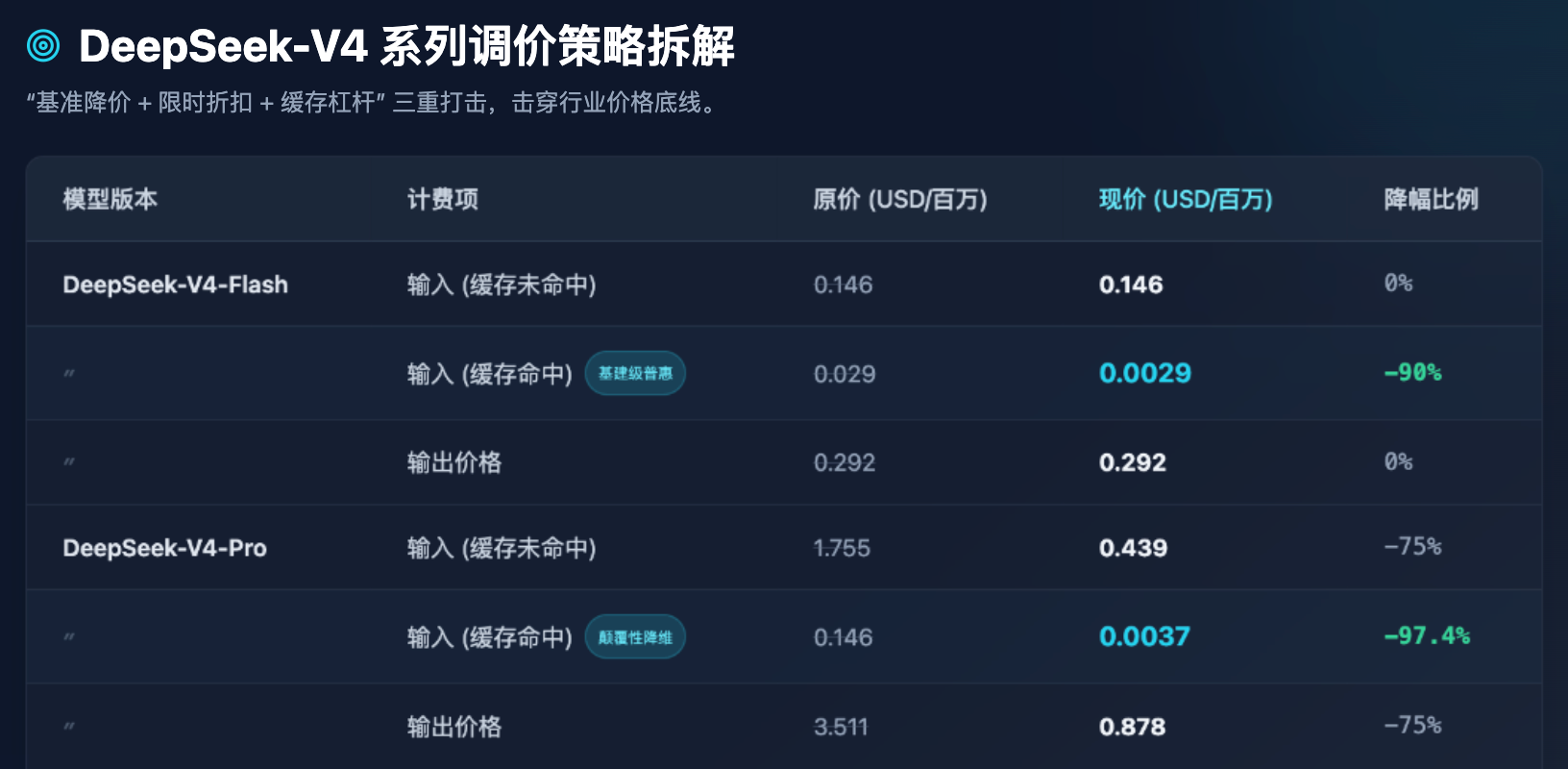
Table 1: Comparison of DeepSeek-V4 Series API Pricing Before and After Adjustment (USD per Million Tokens)
From Table 1, we can draw several highly clear industry observations:
First, the democratization of Flash models has reached its floor. For Flash models optimized for high concurrency and low latency, the output price remains at $0.292 per million tokens, which is already extremely close to the hard cost of server compute power. DeepSeek has not further reduced the base price of Flash models; instead, it has cleverly lowered the "cache hit" price by 90%. This means that when handling large volumes of repetitive system prompts or fixed-document Q&A, the cost of using Flash models becomes nearly negligible.
Second, the dimensional reduction strike of the Pro model. As a flagship model benchmarked against the world’s top tier (such as GPT-5 level), the output price of V4-Pro has plummeted from $3.511 to $0.878. Even more astonishingly, the cached input price, originally $0.146, has been slashed by an additional 75% discount and a further 90% reduction, dropping directly to $0.0037. This is an extraordinarily staggering figure—it means the cost of accessing the world’s top-tier intelligence has been compressed to a level where even small and medium-sized enterprises and individual developers can invoke it frequently without hesitation.
Third, it pushes developers to optimize prompt engineering. By setting the cached price at a fraction—such as 0.0037 USD versus 0.439 USD in the Pro model, a difference of about 118 times—this is not merely a pricing strategy, but a commercial mechanism to guide the technical ecosystem. DeepSeek is clearly telling developers: if your architecture is well-designed (for example, placing fixed long context first and variable short questions afterward), you can enjoy nearly free input compute power.
Horizontal comparison: The stark pricing disparity between global and local large models
Simply comparing DeepSeek’s price cuts vertically is not enough to see the full picture; when placed within the context of the global large model market in 2026, the stark contrast created by this pricing strategy is truly chilling.
Based on OpenRouter and publicly available information from various sources, we have compiled the latest API pricing data for the nine most representative large models in the domestic and international markets.

Table 2: Comparison of Global Leading Large Model API Pricing in 2026 (USD per million tokens)
Take on global giants: Shatter the myth of "high intelligence, high premium"
Over the past two years of AI narratives, OpenAI and Anthropic have maintained an unspoken agreement: the most intelligent models deserve the highest gross margins. Currently, the output prices for GPT-5.5 and Claude Opus 4.7 stand at $30 and $25 per million tokens, respectively. These two Silicon Valley giants are attempting to maintain their high compute taxes by monopolizing the most advanced reasoning capabilities.
However, the emergence of DeepSeek-V4-Pro and its $0.878 output pricing has directly pierced through this veil. If V4-Pro can achieve or come close to GPT-5.5’s performance across all major benchmarks and real-world use cases, the 34-fold price difference between the two would completely dismantle the premium pricing logic that major overseas players rely on in the B2B market.
According to ME News Think Tank, for an overseas-focused enterprise heavily reliant on AI-generated content, if it consumes 1 billion tokens per month in output, the hard cost using GPT-5.5 would be $30,000; switching to DeepSeek-V4-Pro would reduce this cost dramatically to just $878. Such a massive cost difference could determine the survival or failure of a startup. This demonstrates that Chinese AI companies have forged a distinct path—balancing “brute-force aesthetics” with “extreme engineering”—in foundational model training efficiency and inference cluster optimization, diverging entirely from Silicon Valley’s approach.
Cracking down on domestic peers: accelerating industry consolidation
If DeepSeek represents a dimensional advantage over overseas giants, it is a brutal zero-sum game for domestic competitors.
As shown in Table 2, leading domestic providers such as Zhipu (GLM 5.1, $4.40 output) and Moonshot (Kimi K2.6, $4.00 output) find themselves in an awkward pricing position. These rates were recently considered “reasonable and cost-effective,” but they instantly lose all price competitiveness against DeepSeek-V4-Pro ($0.878 output). Even Alibaba Cloud, long known for its open-source model and low pricing (Qwen3.6 Plus, $1.96 output), no longer appears “cheap.”
In the arena of lightweight Flash models, the competition is equally fierce. Step 3.5 Flash by Step AI offers input as low as $0.028 and output at just $0.299, closely competing with DeepSeek-V4-Flash (output at $0.292). This shows that in the lightweight model space, computational costs have been squeezed to the nanometer level, with every player flying right along the cost line.
Overall, DeepSeek is using Pro-level capabilities to compete against domestic competitors' Plus or even standard editions at lower prices, while employing Flash-level pricing to capture massive volumes of low-value-density long-tail traffic. This “dual-pronged strategy” significantly compresses the survival space for other large model companies, accelerating the elimination race among domestic AI large models following this round of price cuts.
Deep Dive: The Technology and Business Logic Behind the Ultra-Low Prices
Prices detached from fundamentals are unsustainable. DeepSeek dares to implement such an aggressive pricing strategy for 2026 due to strong technical backing and ambitious business goals.
Technical Logic: From Brute Force to Architecture Wins
The sharp decline in price is essentially the release of benefits from technological architecture evolution.
- The deep advantage of MoE (Mixture of Experts) architecture: Unlike OpenAI’s early large dense models, current state-of-the-art models commonly employ highly optimized MoE architectures. DeepSeek is very likely to further reduce the proportion of activated parameters in its V4 architecture. This means that even with a massive total parameter count, only a tiny fraction of “experts” are activated during each inference, significantly lowering the computational cost (FLOPs) and memory bandwidth pressure per call.
- A revolutionary breakthrough in KV Cache management: The biggest highlight of this price adjustment is “input cache hit rate reduced to 1/10.” In Transformer architectures, the primary bottleneck for long-text inference is not computation, but the large amount of VRAM consumed by KV Cache storing contextual information. DeepSeek has evidently implemented a system-level, cross-request, globally shared KV Cache pooling technology (e.g., an enhanced version of RadixAttention). When countless concurrent user requests contain identical system configurations or background knowledge bases, the model no longer needs to recompute these tokens—it can directly retrieve them from memory or even a distributed VRAM pool. This brings the marginal cost of “long-text input” close to zero.
Business logic: Trade profit for space, rebuild the ecological moat
The ME News Think Tank believes that DeepSeek's limited-time discount and bottom-price strategy has a clear and decisive business objective:
First, completely dismantle the "wrapper fine-tuning" ecosystem to force the explosion of native AI applications. When the cost of invoking the most powerful foundational models approaches zero, it will become economically nonsensical for entrepreneurs to spend vast sums training or fine-tuning their own industry-specific small models. DeepSeek, through low pricing, aims to attract all AI developers nationwide into its API ecosystem, positioning itself as the foundational "water, electricity, and gas" of the AI era—like Amazon AWS or Microsoft Azure.
Second, the dawn of Agent (intelligent agent) proliferation. True agentic applications require models to perform extensive self-reflection, planning, and multi-round loop calls. During this process, massive amounts of implicit token consumption occur. Expensive APIs are the biggest barrier to Agent adoption. By reducing cache hit pricing to $0.0037, DeepSeek is making it economically feasible for AI to run ten thousand loops on its own. Whoever provides the lowest cost of trial and error will nurture the greatest AI-native super-applications.
Industry Impact and Trend Analysis: From the "Model War" to the "Ecosystem War"
To more intuitively demonstrate the impact of these price changes on business decisions, we conducted a cost simulation for enterprise-level applications.
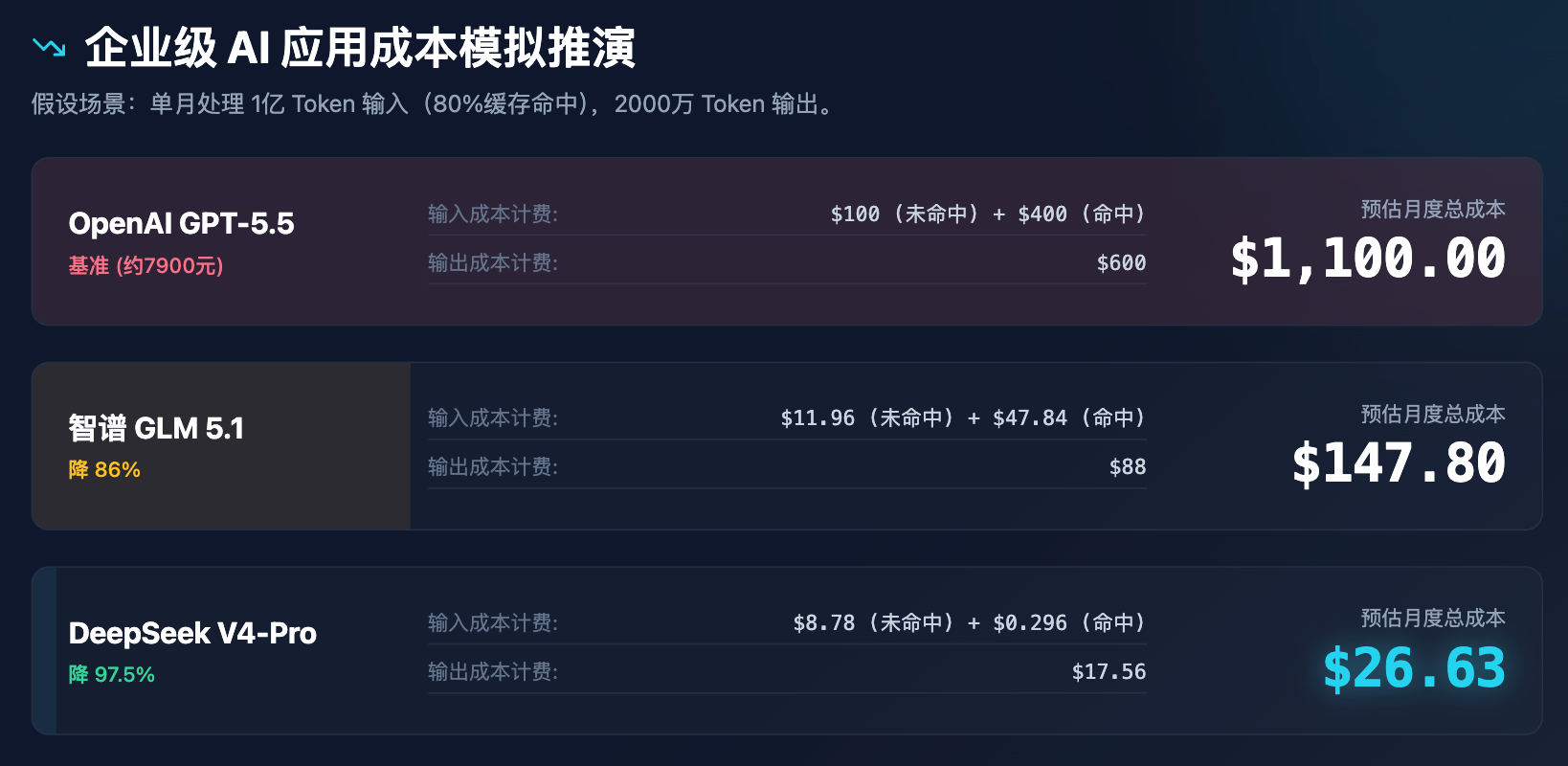
Table 3: Cost Simulation Analysis for Enterprise AI Applications (Assuming 100 million input tokens and 20 million output tokens processed per month)
The above simulation clearly shows that DeepSeek’s pricing is not just a discount—it’s a restructuring of the cost model. With a monthly cost of less than $30, it can power all customer support assistance, document parsing, and code review needs for a mid-sized enterprise, inevitably triggering a cascade of consequences:
- The fundamental shift in AI investment logic: capital will completely lose interest in "rebuilding a general-purpose large model." The door to general-purpose foundational models is now welded shut, except for a very few state-backed entities or internet giants. Future investments will flow comprehensively toward the application layer (Application Layer) and infrastructure middleware (such as AI routers and AI gateways).
- Multi-model routing (LLM Routing) has become standard: enterprises no longer rely on a single model. The system automatically distributes tasks based on complexity. For example, 90% of routine data cleaning and simple classification tasks are handled by DeepSeek-V4-Flash or Step 3.5 Flash at extremely low cost; the remaining 10% involving complex logical reasoning or executive report generation invoke DeepSeek-V4-Pro or GPT-5.5 on demand.
- Long-form applications are reaching a true commercial inflection point: Previously, while the idea of “uploading a million-word financial report for AI summarization” sounded appealing, the API cost of several dollars per use deterred B2B enterprises. With input cache hit prices now dropping to the level of 0.02 RMB per million tokens, “reading entire document libraries and interacting in real time” will become a standard feature in all enterprise OA and ERP systems.
Conclusion and Strategic Recommendations
The price cut storm in April 2026 marked the formal end of the classical romantic era in the large model industry—where competition revolved around parameter counts and benchmark scores—and ushered in a harsh, industrial age defined by cost competition, compute acquisition, and ecosystem dominance. Through its aggressively pricing strategy, DeepSeek has not only demonstrated the profound expertise of Chinese AI companies in model engineering but has also actively burst the high premium bubble surrounding AI compute.
In response, "ME News Think Tank" offers three recommendations:
- For application-layer developers: Let go of your fear of large model invocation costs. Immediately stop building or fine-tuning foundational models with fewer than ten billion parameters, and redirect all R&D resources toward enhancing product experience, edge-side adaptation, building proprietary data moats, and refining Agent workflows. Leverage the current “affordable, high-intelligence computing power”红利 to quickly capture use cases.
- For traditional enterprise CIOs/CTOs: Reevaluate your company’s AI strategy. Knowledge base Q&A, automated customer service, and code Copilot projects previously put on hold due to cost considerations now offer significantly higher ROI under current API pricing. We recommend adopting a mature LLMOps platform and establishing an enterprise-grade AI gateway to flexibly integrate the most cost-effective models available today.
- For competitors with foundational models: the follow-the-leader strategy must be abandoned. In the face of price wars, either achieve even lower costs through extreme chip-framework co-optimization, or build irreplaceable technological advantages in differentiated areas such as embodied intelligence, native multimodal (video/3D generation), and strong logical reasoning for vertical industries. Purely language-based large models have become commoditized and offer no viable path forward.
Large models are no longer deities confined to laboratories; they are rapidly descending from their pedestals, becoming a powerful force driving intelligence in everything. And this is only the beginning.
Source:
- OpenRouter. (2026). API Pricing Comparison Database.
- DeepSeek Official Announcement. (2026, April 25).DeepSeek-V4-Pro API Limited-Time Offer.
- DeepSeek Official Announcement. (2026, April 26).Democratizing Compute Power in the Large Model Era: API Global Cache Hit Price Adjustment Plan.