









Author: XinGPT
Your AI programming assistant may be powered by a Chinese model you've never heard of.
From DistillAI, a financial new media platform for the AI era.
Note: We are experimenting with a fully AI-driven approach to content creation, so this article, from topic selection to writing, was generated by Claude AI.
You open Cursor every day to write code, refactor functions, and let AI help you debug. You feel like you're using the most cutting-edge technology from Silicon Valley, especially since it's a star company valued at $29.3 billion, backed by investors like Thrive Capital and a16z, with users across the global developer community.

Until last week, someone spotted a model ID in the Composer 2 API response: kimi-k2p5-rl-0317-s515-fast.
Kimi K2.5 — an open-source model from the Chinese company Moonshot AI.
Your coding agent's "brain" is not the one you think it is.
Composer 2: A meticulously packaged release
On March 20, Cursor released its next-generation code model, Composer 2, with the official blog using a powerful phrase: "frontier-level coding intelligence."
The announcement does not mention any base model names. No Kimi, no Moonshot, no "China," no "open source." Everything appears as if it were developed in-house by Cursor.
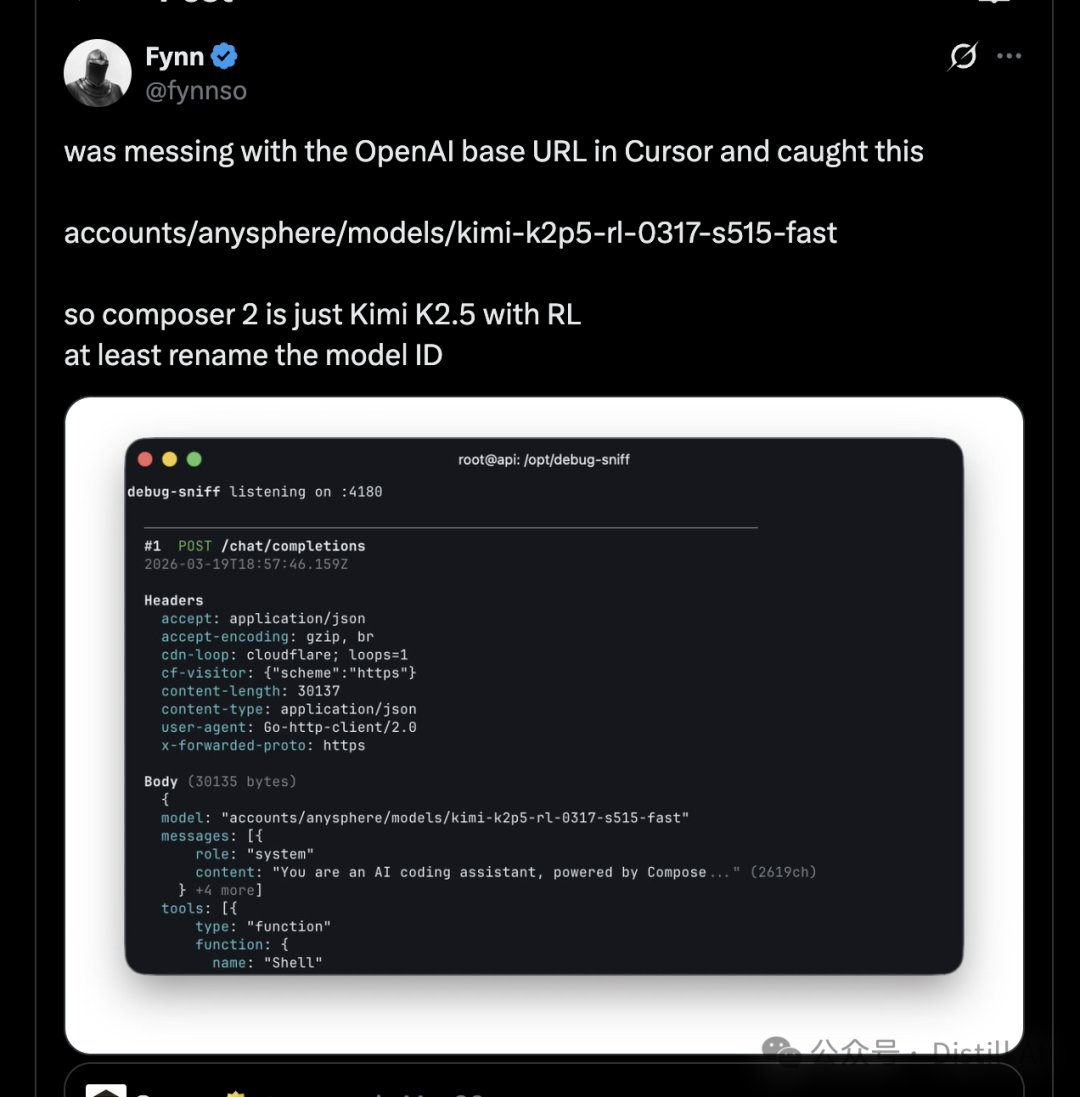
But the tech community has a keen nose. On the day of the release, developers noticed the model path returned when calling the Composer 2 API: accounts/anysphere/models/kimi-k2p5-rl-0317-s515-fast. This string was almost an introduction—Kimi K2.5, plus RL fine-tuning.
The message spread rapidly on social media. Two days later, Lee Robinson, Vice President of Developer Education at Cursor, publicly responded, acknowledging that Composer 2 is indeed based on Kimi K2.5, but emphasized that "only about one-quarter of the final compute power comes from the Kimi base, with the rest coming from Cursor's own training." He referred to the omission of Kimi in the blog post as "a mistake."
If this were Cursor's first "mistake," it might still be dismissed as an oversight. But it isn't.
When Composer 1 was released last year, some also discovered it used DeepSeek’s tokenizer, without disclosing this on any official channel. One instance could be an oversight; two instances make it hard not to wonder: was this simply forgotten, or deliberately withheld?
A rational choice, a silent logic
Before criticizing Cursor, I think it’s important to first understand a fact: using Kimi K2.5 as a foundation is a highly rational decision from both technical and business perspectives.
Kimi K2.5 is an open-source model released by Moonshot AI in January this year, utilizing a MoE (Mixture of Experts) architecture and demonstrating strong performance in code generation tasks. More importantly, it is open-source—meaning its acquisition cost is extremely low. For a company like Cursor, which needs to rapidly iterate and focus its efforts on the product layer and toolchain integration, using an existing high-quality open-source model as a foundation and fine-tuning it with its own data and reinforcement learning is the most efficient approach.
This isn't anything new.
Today, the AI product market relies far more commonly than most people realize on Chinese open-source models as its foundation. Models like DeepSeek, Qwen, and Kimi—open-sourced by Chinese teams—are becoming the invisible backbone of the global AI tech stack. Yet, no one is eager to bring it up.
The reason is straightforward. Within the narrative framework of U.S.-China tech competition, the statement “Our AI product is built on a Chinese model” is not merely a technical disclosure for an American company—it’s an open door to public relations risk. How will investors react? Could enterprise clients worry about data security? What headlines will the media write?
So silence has become an industry unwritten rule. Everyone uses it, but no one talks about it.
But silence comes at a cost.
Authorized and compliant: The small print you ignored
The open-source license for Kimi K2.5 is a modified MIT License. Most terms are permissive, but one key restriction applies: if a commercial product has more than 100 million monthly active users or monthly revenue exceeding $20 million, it must prominently display "Kimi K2.5" in the user interface.
Cursor's annual revenue is approximately $2 billion, and its monthly revenue is about eight times this threshold.
This authorization requirement is clear, enforceable, and clearly being ignored.
I am not a legal professional, and I am not here to discuss specific legal consequences. However, it is worth noting that the software industry took two decades to build respect for open-source licenses—from early GPL litigation to SBOM (Software Bill of Materials) becoming a standard component of supply chain security. Today, AI model licensing compliance is likely still at the very beginning of that wild frontier.
Many might think labeling "Kimi K2.5" isn't a big deal. But the issue is, if such a simple compliance requirement can be overlooked, who is seriously addressing more complex issues—data flow, auditability of model behavior, and cross-border compliance?
Trust tax: An opaque hidden cost
Some people have used the term "Trust Tax" to describe the cost of Cursor's incident, and I think this concept is very accurate.
When users discover that the “Cutting-Edge Programming Intelligence” they’re paying $20 a month for is built on a free open-source model with fine-tuning, trust begins to erode. The issue isn’t that Kimi K2.5 isn’t good—it’s truly excellent—but that users feel misled.
This is not the first time Cursor has faced a trust crisis. Previously, users discovered they exhausted their entire monthly quota in just three days due to pricing controversies surrounding the "unlimited" Pro plan. Combined with the current issue regarding model sourcing, trust debt is accumulating.
The deeper question is: In the category of AI agent tools, what are users actually paying for?
If the answer is "model capability," users could directly call the Kimi K2.5 API at a much lower cost. If the answer is "product experience and toolchain integration," Cursor should clearly articulate where its true value lies, rather than vaguely implying everything is self-developed.
The mobile phone industry has long solved this issue. No one feels deceived because the iPhone uses chips manufactured by TSMC, as Apple never pretends to have its own wafer foundry. Transparency and business value are not contradictory.
China's open-source era of the "invisible foundation"
Beyond the case of Cursor, a more significant trend is that Chinese open-source models are becoming the foundational infrastructure for global AI applications.
Hugging Face CEO Clément Delangue commented on this, saying that Chinese open source is "the strongest force shaping the global AI tech stack." This is not empty praise.
The valuation of Moonshot AI quadrupled within three months to approximately $18 billion. Meanwhile, the Cursor incident, in a sense, served as a global endorsement of Kimi’s capabilities to developers worldwide—the most highly valued AI programming tool globally chose your model as its foundation, which is more convincing than any benchmark.
This trend brings more than just geopolitical discussions. For enterprise users, there is a very practical concern: your code is being processed by models whose origins you do not know.
In regulated industries (finance, healthcare, government), data sovereignty and cross-border compliance are mandatory requirements. If your developers are using an AI tool whose model origins are opaque, your compliance team may have no idea what risks they’re facing. This isn’t a hypothetical scenario—it’s happening right now.
Some people refer to this type of risk as "Shadow AI," analogous to the concept of Shadow IT from earlier years. Developers have embedded AI models into their IDEs and CI/CD pipelines, but security and legal teams remain unaware.
Next step: AI-BOM and supply chain transparency
After experiencing supply chain security incidents like Log4j, the software industry has gradually embraced the concept of SBOM (Software Bill of Materials)—a clear inventory listing which components your software uses, their versions, and whether any known vulnerabilities exist.
AI models need the same thing.
The concept of AI-BOM (AI Bill of Materials) has begun to be discussed in the security community. An AI product’s bill of materials should include: the base model used, the source and processing of training data, the fine-tuning methods, and the model’s deployment and data flow.
For developers, this means that when selecting AI tools, they need to begin vetting model sources as rigorously as they review the licenses of dependency libraries. Tools like `npm audit` and `pip check` are already routine—soon, `model audit` may become standard practice.
For AI tool vendors, proactively disclosing model origins is not a sign of weakness, but an investment in long-term trust. The first company to make AI-BOM a standard feature may gain a premium in market trust.
For the entire industry, transparency in the model supply chain is shifting from a “nice to have” to a “must have.” This shift may not require a Log4j-level event to catalyze it—the Cursor story is already a loud enough wake-up call.
Return to the initial scenario. Your Cursor is still functional, and Kimi K2.5 remains an excellent model. Moonshot’s technical capabilities are worthy of respect, and Cursor’s accumulation in product and tooling is genuine.
The issue has never been about "using a Chinese model"—in a global open-source ecosystem, good technology shouldn't carry a national label. The issue is about "not telling you."
As AI agents become increasingly integrated into workflows, we are entrusting more and more code, data, and decisions to these tools. At the very least, we should know who is behind the "brain" of these tools.
Transparency is not a technical detail—it's the infrastructure of trust.