









Article by Sleepy.txt
Eight years ago, ZTE suffered a cardiac arrest.
On April 16, 2018, a ban issued by the U.S. Department of Commerce’s Bureau of Industry and Security brought ZTE, a global fourth-largest telecommunications equipment provider with 80,000 employees and annual revenue exceeding $10 billion, to a sudden halt. The ban simply prohibited any U.S. company from selling components, goods, software, or technology to ZTE for the next seven years.
Without Qualcomm's chips, the base stations ceased production. Without Google's Android license, the phones had no usable operating system. Twenty-three days later, ZTE issued a statement saying its core business operations could no longer continue.
However, ZTE ultimately survived, at the cost of $1.4 billion.
A $1 billion fine to be paid in full; a $400 million deposit into a custodial account at a U.S. bank. Additionally, all senior executives were replaced, and a U.S. compliance oversight team was installed. In 2018, ZTE reported a net loss of RMB 7 billion, with revenue plunging 21.4% year-over-year.
At the time, Yin Yimin, then Chairman of ZTE, wrote in an internal letter: “We are in an industry that is complex and highly dependent on global supply chains.” This statement, heard then, was both a reflection and a sign of helplessness.
Eight years later, on February 26, 2026, China’s AI unicorn DeepSeek announced that its upcoming V4 multimodal large model will prioritize deep collaboration with domestic chip manufacturers, marking the first end-to-end non-NVIDIA solution from pre-training to fine-tuning.
We are no longer using NVIDIA.
Upon the announcement, the market's first reaction was skepticism. NVIDIA holds over 90% of the global AI training chip market—would it be commercially sensible to abandon it?
But behind DeepSeek’s choice lies a question bigger than business logic: What kind of computing independence does Chinese AI really need?
What exactly is being choked?
Many people think the chip ban targets hardware. But what's truly suffocating Chinese AI companies is something called CUDA.
CUDA, which stands for Compute Unified Device Architecture, is a parallel computing platform and programming model introduced by NVIDIA in 2006. It enables developers to directly harness the computational power of NVIDIA GPUs to accelerate a wide range of complex computing tasks.
Before the AI era, this was merely a tool for a small group of enthusiasts. But when the wave of deep learning arrived, CUDA became the foundation of the entire AI industry.
Training large AI models is essentially massive matrix operations—and this is precisely what GPUs are best at.
NVIDIA, through its strategic planning over a decade ago, built a comprehensive toolchain for global AI developers, spanning from underlying hardware to upper-layer applications using CUDA. Today, all major AI frameworks—from Google’s TensorFlow to Meta’s PyTorch—are deeply integrated with CUDA at their core.
A PhD student in AI has been learning, programming, and conducting experiments in a CUDA environment since the first day of enrollment. Every line of code they write strengthens NVIDIA's moat.

By 2025, the CUDA ecosystem has grown to include over 4.5 million developers, supporting more than 3,000 GPU-accelerated applications, and is used by over 40,000 companies worldwide. This means that over 90% of AI developers globally are locked into NVIDIA’s ecosystem.
The terrifying thing about CUDA is that it’s a flywheel: the more developers use it, the more tools, libraries, and code are created, leading to a more vibrant ecosystem; the more vibrant the ecosystem, the more developers it attracts. Once this flywheel starts spinning, it becomes nearly impossible to dislodge.
As a result, NVIDIA sells you the most expensive shovel and defines the only mining posture. Want to switch shovels? Sure—but you’d have to rewrite all the experience, tools, and code accumulated over the past decade by hundreds of thousands of the world’s brightest minds using that posture.
Who pays this cost?
So, when the BIS's first round of export controls took effect on October 7, 2022, restricting the export of NVIDIA's A100 and H100 chips to China, Chinese AI companies first collectively felt the suffocating pressure reminiscent of ZTE. In response, NVIDIA subsequently launched the "China-specific" A800 and H800 chips, reducing inter-chip connectivity bandwidth to barely sustain supply.
But just one year later, on October 17, 2023, a second round of restrictions tightened further, banning the A800 and H800, and adding 13 Chinese companies to the Entity List. NVIDIA was once again forced to release a further crippled version, the H20. By December 2024, the final round of restrictions under the Biden administration took effect, strictly limiting exports of the H20 as well.
Three rounds of regulation, each one tightening the controls.
But this time, the story took a completely different path from ZTE back then.
An asymmetric breakthrough
Under the ban, everyone assumed China’s dream of large AI models would come to an end.
They were all wrong. Faced with restrictions, Chinese companies did not choose to confront the blockade head-on; instead, they began a breakthrough. The first battlefield of this breakthrough was not in chips, but in algorithms.
From late 2024 to 2025, China's AI companies collectively shifted toward a technical direction: Mixture of Experts models.
In simple terms, it means breaking a large model into many smaller experts, and only activating the most relevant ones when handling a task, rather than activating the entire model.
DeepSeek's V3 is a prime example of this approach. It has 671 billion parameters, but only activates 37 billion during each inference, accounting for just 5.5% of the total. In terms of training cost, it used 2,048 NVIDIA H800 GPUs over 58 days, totaling $5.576 million. For comparison, external estimates for GPT-4's training cost are around $78 million—a magnitude difference.
The extreme optimization on the algorithm is directly reflected in the pricing. DeepSeek’s API pricing is just $0.028 to $0.28 per million tokens for input and $0.42 for output. In comparison, GPT-4o charges $5 for input and $15 for output, while Claude Opus is even more expensive at $15 for input and $75 for output. This means DeepSeek is 25 to 75 times cheaper than Claude.
This price differential has generated tremendous反响 in the global developer market. In February 2026, on OpenRouter, the world’s largest AI model API aggregation platform, weekly usage of Chinese AI models surged by 127% over three weeks, surpassing the United States for the first time. A year earlier, Chinese models accounted for less than 2% of usage on OpenRouter; one year later, they grew by 421%, nearing 60%.
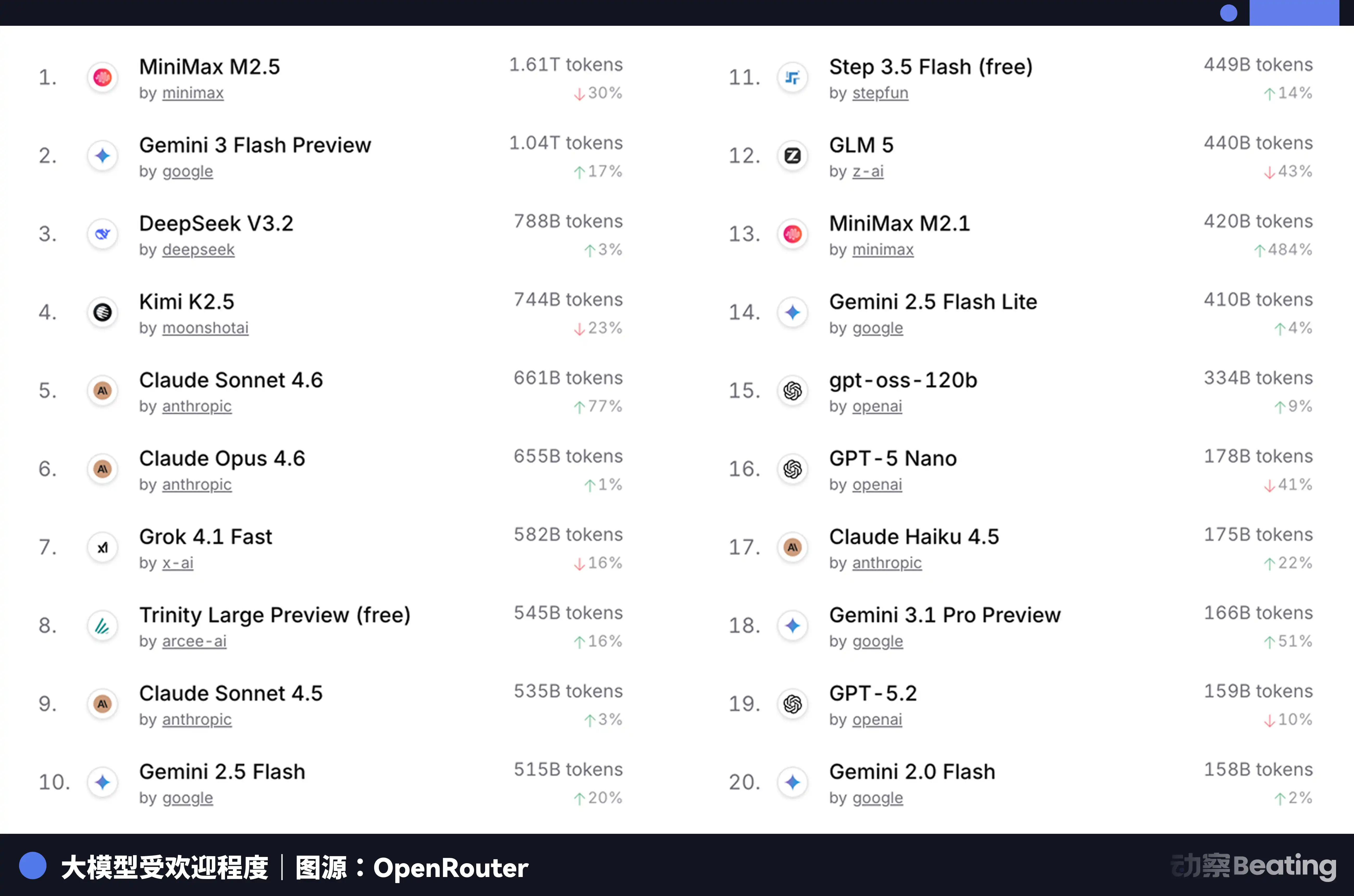
Behind this data lies a structural shift that is often overlooked. Starting in the second half of 2025, the mainstream use case for AI applications is shifting from chat to agents. In agent scenarios, token consumption per task is 10 to 100 times higher than in simple chat. As token consumption grows exponentially, price becomes the decisive factor—and China’s models, with their extreme cost-effectiveness, have perfectly timed this window.
But the problem is that reducing inference costs does not solve the fundamental issue of training. If a large model cannot be continuously trained and iterated on the latest data, its capabilities will rapidly degrade. And training remains the inescapable black hole of computational power.
So, where do the trained "shovels" come from?
Promotion from backup
Xinghua, Jiangsu, a small city in northern Jiangsu, is known for its stainless steel and health foods, and had no prior connection to AI. But in 2025, a 148-meter-long domestic AI computing server production line was built and launched here, from signing to operation in just 180 days.
The core of this production line consists of two entirely domestically developed chips: the Loongson 3C6000 processor and the TaiChu Yuanqi T100 AI accelerator card. The Loongson 3C6000 features fully independent research and development of both its instruction set and microarchitecture. The TaiChu Yuanqi was developed by a team from the National Supercomputing Center in Wuxi and Tsinghua University, utilizing a heterogeneous many-core architecture.
When operating at full capacity, this production line outputs one server every five minutes. The total investment in this production line is 1.1 billion yuan, with an expected annual output of 100,000 units.
More importantly, clusters composed of these domestic chips have already begun handling real large model training tasks.
In January 2026, Zhipu AI, in collaboration with Huawei, released GLM-Image, the first state-of-the-art image generation model trained entirely on domestic chips. In February, China Telecom’s trillion-parameter “Star” large model completed full-process training on a domestic ten-thousand-GPU computing pool in Shanghai’s Lingang area.

The significance of these cases lies in proving one thing: domestic chips have progressed from being "capable of inference" to being "capable of training." This is a qualitative leap. Inference only requires running pre-trained models, imposing relatively low demands on chips; training, however, involves processing massive amounts of data and performing complex gradient calculations and parameter updates, demanding an order of magnitude higher computational power, interconnect bandwidth, and software ecosystem.
The core force behind these tasks is Huawei's Ascend series chips. By the end of 2025, the Ascend ecosystem had surpassed 4 million developers and over 3,000 partners, with 43 leading industry large models pre-trained on Ascend and more than 200 open-source models adapted. On March 2, 2026, at MWC, Huawei launched its next-generation computing infrastructure, SuperPoD, for overseas markets.
The FP16 computing power of the Ascend 910B has reached parity with NVIDIA's A100. Although a gap still exists, it has shifted from unusable to usable, and is now moving toward being highly practical. Ecosystem development cannot wait until the chip is perfect—it must be scaled up aggressively during the "sufficiently capable" phase, using real-world business demands to drive iterative improvements in both hardware and software. ByteDance, Tencent, and Baidu have all set targets to double their adoption of domestic AI computing servers by 2026 compared to the previous year. According to data from the Ministry of Industry and Information Technology, China’s AI computing scale has reached 1,590 EFLOPS. 2026 is poised to become the pivotal year for large-scale deployment of domestic AI computing power.
Power shortages in the United States and Chinese companies going global
In early 2026, Virginia, which carries a large portion of the world’s data center traffic, paused approval of new data center projects. Georgia followed suit, extending its approval pause through 2027. Illinois and Michigan subsequently implemented similar restrictions.
According to the International Energy Agency, U.S. data centers consumed 183 terawatt-hours of electricity in 2024, accounting for approximately 4% of the nation’s total electricity use. By 2030, this figure is projected to double to 426 TWh, potentially exceeding 12% of total consumption. Arm’s CEO has further predicted that by 2030, AI data centers could consume 20% to 25% of all electricity in the United States.
The U.S. power grid is already overstretched. The PJM grid, which serves 13 states in the eastern U.S., faces a 6GW capacity shortfall. By 2033, the U.S. as a whole is projected to have a 175GW power capacity gap—equivalent to the electricity needs of 130 million households. Wholesale electricity costs in areas with high concentrations of data centers have risen by 267% compared to five years ago.
The limit of computing power is energy. And in terms of energy, the gap between China and the U.S. is even larger than that in chips—except the direction is reversed.
China's annual electricity generation is 10.4 trillion kilowatt-hours, while the United States produces 4.2 trillion kilowatt-hours—China generates 2.5 times more than the U.S. More importantly, residential electricity consumption in China accounts for only 15% of total usage, compared to 36% in the U.S. This means China has significantly greater industrial electricity capacity available to devote to computing power infrastructure.
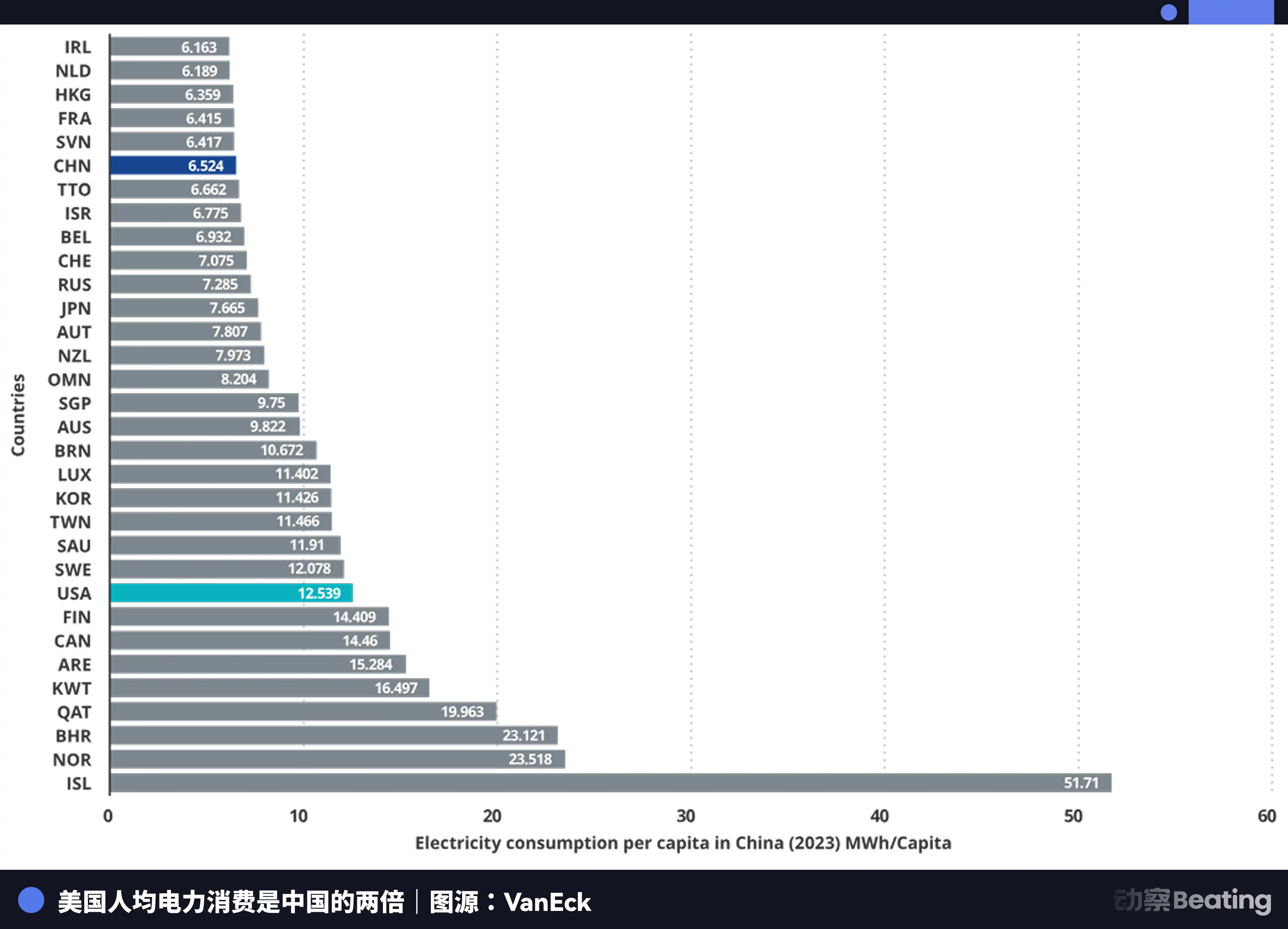
In terms of electricity prices, the areas in the United States where AI companies are concentrated have electricity rates of $0.12 to $0.15 per kilowatt-hour, while industrial electricity rates in western China are approximately $0.03, only one-fourth to one-fifth of those in the United States.
China's increase in power generation has reached seven times that of the United States.
While the United States is grappling with electricity issues, China’s AI is quietly expanding overseas—but this time, what’s being exported isn’t a product or a factory, it’s a token.
Tokens, the smallest units of information processed by AI models, are emerging as a new digital commodity. They are produced in China’s computing factories and transmitted globally via undersea fiber-optic cables.
The user distribution data for DeepSeek is highly revealing: 30.7% from mainland China, 13.6% from India, 6.9% from Indonesia, 4.3% from the United States, and 3.2% from France. It supports 37 languages and is widely popular in emerging markets such as Brazil. Over 26,000 businesses worldwide have registered accounts, and 3,200 organizations have deployed the enterprise version.
In 2025, 58% of new AI startups incorporated DeepSeek into their tech stack. In China, DeepSeek captured 89% of the market share, while in other sanctioned countries, market share ranged between 40% and 60%.
This scene resembles the other war over industrial autonomy forty years ago.
In 1986 in Tokyo, under strong pressure from the United States, the Japanese government signed the U.S.-Japan Semiconductor Agreement. The core provisions of the agreement included three points: requiring Japan to open its semiconductor market, ensuring that U.S. chips capture more than 20% of the Japanese market; prohibiting Japanese semiconductors from being exported below cost; and imposing a 100% punitive tariff on $300 million worth of Japanese exports. At the same time, the United States blocked Fujitsu’s acquisition of Fairchild Semiconductor.
That year, Japan's semiconductor industry was at its peak. In 1988, Japan controlled 51% of the global semiconductor market, while the United States held only 36.8%. Six of the world's top ten semiconductor companies were Japanese: NEC ranked second, Toshiba third, Hitachi fifth, Fujitsu seventh, Mitsubishi eighth, and Panasonic ninth. In 1985, Intel suffered a loss of $1.73 billion in the U.S.-Japan semiconductor rivalry and came close to bankruptcy.
But everything changed after the agreement was signed.
The United States launched comprehensive pressure against Japanese semiconductor companies through measures such as the Section 301 investigation, while simultaneously supporting South Korea’s Samsung and SK Hynix to flood the Japanese market with lower-priced products. Japan’s DRAM market share plummeted from 80% to 10%. By 2017, Japan’s share of the IC market had dwindled to just 7%. The once-dominant giants either were split up, acquired, or faded away amid endless losses.
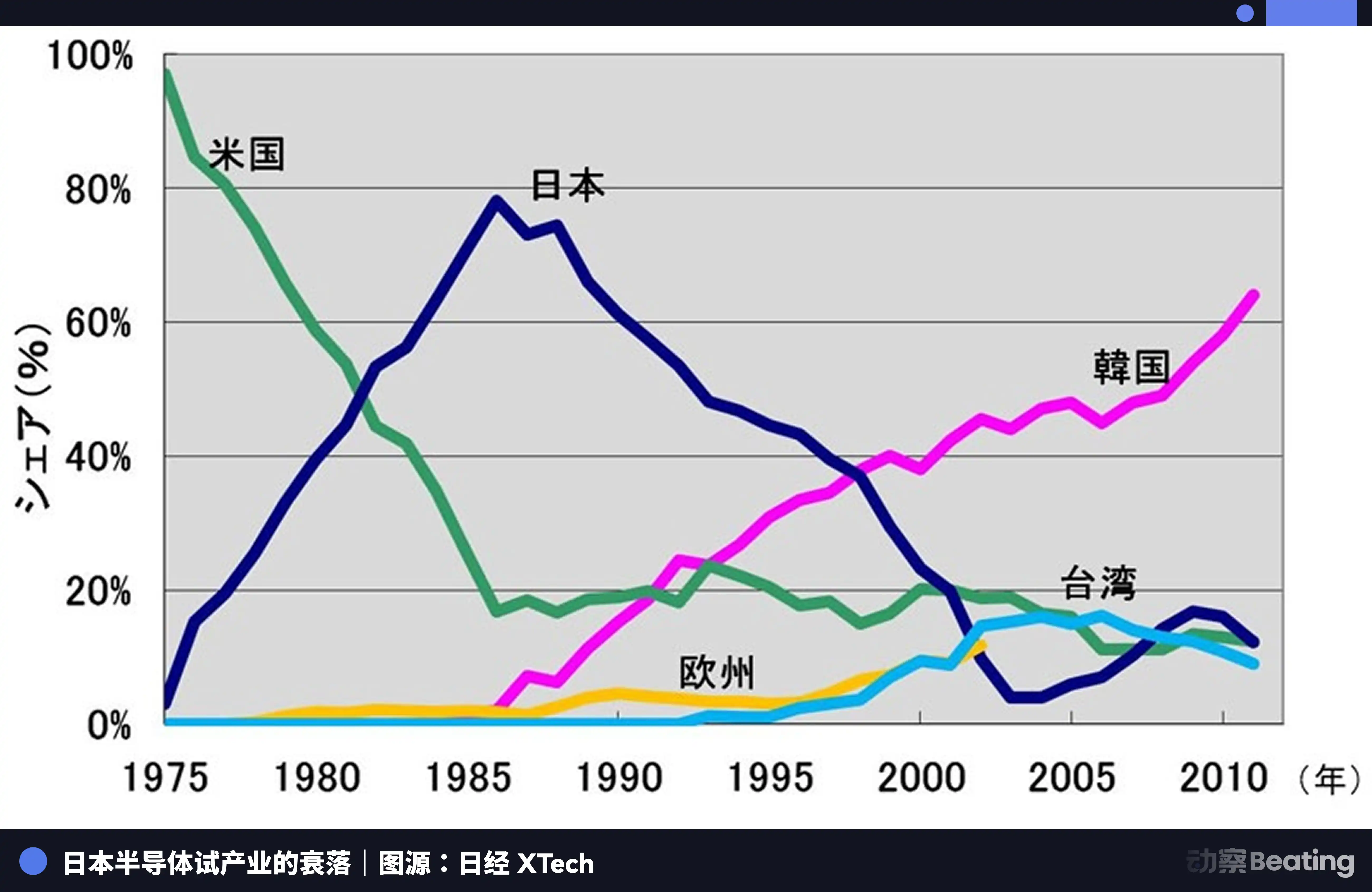
The tragedy of Japan’s semiconductor industry lies in its contentment with being the best producer within a global division of labor dominated by a single external force, never seeking to build its own independent ecosystem. When the tide receded, it realized it had nothing but production itself.
Today, China's AI industry stands at a crossroads that is similar yet entirely different.
Similarly, we also face immense external pressure. Three rounds of chip restrictions, each one tightening further, have left the CUDA ecosystem's barriers still towering.
Unlike before, this time we have chosen a more difficult path—from extreme optimization at the algorithmic level, to the leap of domestic chips from inference to training, to the accumulation of 4 million developers in the Ascend ecosystem, to the global market penetration of Token outbound. Every step on this path is building an independent industrial ecosystem that Japan never had.
Epilogue
On February 27, 2026, three earnings previews from domestic AI chip companies were released on the same day.
Cambricon's revenue surged 453%, achieving its first annual profit. Moore Threads' revenue grew 243%, but posted a net loss of 1 billion. Moxi's revenue increased 121%, with a net loss of nearly 800 million.
Half flame, half sea.
Fire is the market's extreme hunger. The 95% gap left by Huang Renxun is being slowly filled by the revenue figures of these domestic companies. Regardless of performance or ecosystem, the market demands a second choice beyond NVIDIA. This is a once-in-a-lifetime structural opportunity opened up by geopolitics.
Seawater represents a massive cost in ecological development. Every dollar lost is real money spent to catch up with the CUDA ecosystem—investment in R&D, subsidies for software, and the human cost of engineers deployed to customer sites to individually resolve compilation issues. These losses are not due to poor management, but rather the war tax required to build an independent ecosystem.
These three earnings reports document the true nature of this hash rate war more honestly than any industry report ever could. It is not a triumphant march to victory, but a brutal, bloody, front-line battle.
But the nature of war has indeed changed. Eight years ago, we were discussing whether we could survive. Today, we are discussing how much it will cost to survive.
The cost itself is progress.
Click to learn about the open positions at BlockBeats
Welcome to the official BlockBeats community:
Telegram subscription group: https://t.me/theblockbeats
Telegram group: https://t.me/BlockBeats_App
Official Twitter account: https://twitter.com/BlockBeatsAsia