










Original author: KarenZ, Foresight News
On March 20, 2026, an unusual conversation took place on the All-In podcast.
Venture capital heavyweight Chamath Palihapitiya passed the floor to NVIDIA CEO Jensen Huang, saying that a project on Bittensor had achieved a "remarkably crazy technical feat"—training a large language model on the internet using distributed computing, entirely decentralized with no centralized data centers involved.
Jensen Huang did not avoid the issue. He compared it to a modern version of Folding@home, the distributed project from the 2000s that enabled ordinary users to contribute their idle computing power to collectively tackle the challenge of protein folding.
Four days prior, on March 16, Jack Clark, co-founder of Anthropic, also devoted significant attention to this breakthrough in a report on AI research progress, highlighting and citing the achievement: the Bittensor ecosystem subnet Templar (SN3) completed distributed training of a 72-billion-parameter model (Covenant 72B), achieving performance comparable to Meta’s LLaMA-2, released in 2023.
Jack Clark titled this chapter "Challenging the Political Economy of AI Through Distributed Training," and in his analysis, he emphasized that this is a technology worth ongoing monitoring—he can envision a future in which edge AI widely adopts models trained through decentralized methods, while cloud AI continues to run proprietary large models.
Market reaction was slightly delayed but extremely sharp: SN3 rose over 440% in the past month and over 340% in the past two weeks, reaching a market cap of $130 million. The narrative surrounding subnets is driving direct buying pressure on TAO, causing TAO to surge rapidly—peaking at $377, doubling in value over the past month, with a fully diluted valuation of approximately $7.5 billion.
Here comes the question: What exactly did SN3 do? Why has it been thrust into the spotlight? And how will the value narrative around distributed training and decentralized AI evolve?
That 72B model
To answer this question, first take a close look at SN3's performance.
On March 10, 2026, the Covenant AI team published a technical report on arXiv, officially announcing the completion of training for Covenant-72B. This is a 72-billion-parameter large language model that underwent pre-training on approximately 1.1 trillion tokens, utilizing over 70 independent peer nodes (with around 20 nodes synchronized per round, each equipped with eight B200 GPUs).
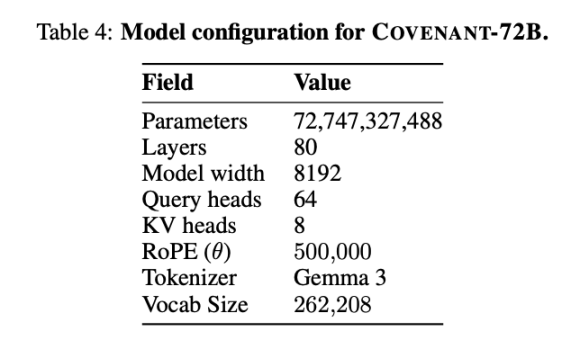
Templar provided some benchmarking data, with the comparison model being LLaMA-2-70B, a large model released by Meta in 2023. As Anthropic co-founder Jack Clark noted, Covenant-72B may already be outdated by 2026. Covenant-72B’s score of 67.1 on MMLU is roughly comparable to Meta’s LLaMA-2-70B, which scored 65.6.
Meanwhile, the cutting-edge models of 2026—whether from the GPT series, Claude, or Gemini—have already been trained on hundreds of thousands of GPUs with parameter counts far exceeding 100 billion; the gaps in reasoning, coding, and mathematical capabilities are orders of magnitude, not mere percentages. This real-world disparity should not be drowned out by market sentiment.
But when considered under the premise of "trained using distributed computing power on the open internet," the meaning is entirely different.
Here’s a comparison: INTELLECT-1 (developed by the Prime Intellect team, 10 billion parameters), trained in a decentralized manner, achieved an MMLU score of 32.7; another distributed training project, Psyche Consilience (40 billion parameters), trained among whitelisted participants, scored 24.2. Covenant-72B stands out in the decentralized training space with its 72B scale and an MMLU score of 67.1.
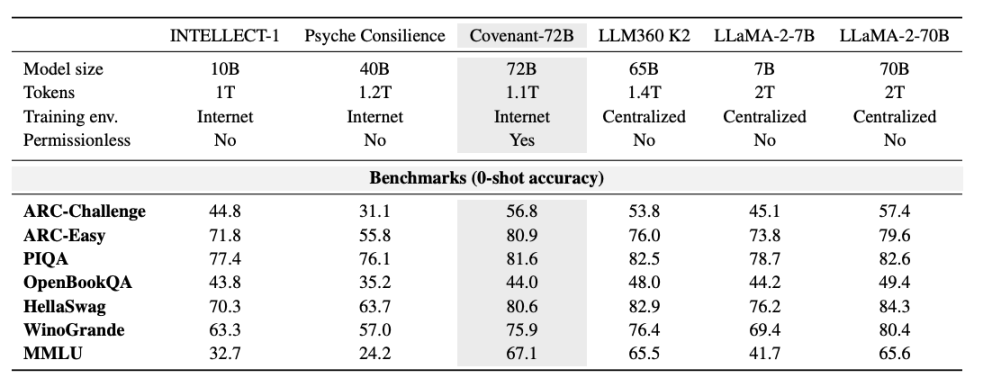
More importantly, this training is “permissionless.” Anyone can join as a participating node without prior approval or whitelisting. Over 70 independent nodes from around the world connected and contributed computing power to the model update.
What Jensen Huang said, and what he didn't say
Revisiting the details of that podcast conversation can help correct external interpretations of this "endorsement."
Chamath Palihapitiya presented Bittensor’s technical achievement in the conversation to Jensen Huang, describing it as training a Llama model using distributed compute power in a way that was “completely distributed while maintaining state.” Huang responded by comparing it to a “modern-day Folding@home” and went on to discuss the necessity of open-source and proprietary models coexisting in parallel.
Notably, Huang did not directly mention Bittensor’s token or any investment implications, nor did he further discuss decentralized AI training.
Understand Bittensor subnets and SN3
To understand the breakthrough of SN3, it’s essential to first grasp how Bittensor and its subnets operate. In simple terms, Bittensor can be viewed as an AI-focused public blockchain and platform, where each subnet functions as an independent “AI production line,” each with its own defined core mission and incentive structure, collectively forming a decentralized AI ecosystem.
Its operation is clear and decentralized: subnet owners define subnet objectives and design incentive models; miners provide computational power and complete AI-related tasks (such as inference, training, and storage) within the subnet; validators score miners' contributions and upload these scores to the Bittensor consensus layer; finally, Bittensor’s Yuma consensus algorithm distributes rewards to subnet participants based on the accumulated incentives across subnets.
There are currently 128 subnets on Bittensor, covering various AI tasks such as inference, serverless AI cloud services, image processing, data labeling, reinforcement learning, storage, and computation.
SN3 is one such subnet. It does not wrap applications or rent existing large model APIs; instead, it directly targets one of the most expensive and closed-off core segments of the entire AI industry: large model pre-training itself.
SN3 aims to leverage the Bittensor network to coordinate distributed training across heterogeneous computing resources, demonstrating that powerful foundational models can be trained without expensive centralized supercomputing clusters through incentive-driven, decentralized large model training. The core appeal lies in "equalization"—breaking the resource monopoly of centralized training and enabling individuals or small-to-medium organizations to participate in large model training, while reducing training costs through distributed computing power.
The core force driving SN3's development is Templar, backed by the research team at Covenant Labs. This team also operates two other subnets: Basilica (SN39), focused on compute services, and Grail (SN81), focused on RL post-training and model evaluation. Together, the three subnets form a vertically integrated ecosystem that comprehensively covers the entire lifecycle of large models—from pre-training to alignment optimization—building a complete decentralized ecosystem for large model training.
Specifically, miners contribute computing resources to upload gradient updates (the direction and magnitude of model parameter adjustments) to the network; verifiers assess the quality of each miner’s contribution and assign on-chain scores based on the degree of error improvement. The results determine reward weights, which are automatically distributed without requiring trust in any third party.
The key to designing the incentive mechanism is to tie rewards directly to "how much your contribution improved the model," rather than merely to computational power attendance. This fundamentally solves the most challenging problem in decentralized scenarios: how to prevent miners from slacking off.
How does Covenant-72B address communication efficiency and incentive compatibility?
Coordinating dozens of nodes that do not trust each other, have varying hardware, and differ in network quality to jointly train the same model presents two challenges: first, communication efficiency—standard distributed training schemes require high-bandwidth, low-latency connectivity between nodes; second, incentive compatibility—how to prevent malicious nodes from submitting faulty gradients, and how to ensure that each participant is genuinely training rather than copying others’ results?
SN3 addresses these two issues with two core components: SparseLoCo and Gauntlet.
SparseLoCo addresses communication efficiency issues. Traditional distributed training requires synchronizing full gradients at every step, resulting in massive data transfer. SparseLoCo’s approach is for each node to perform 30 local optimization steps (using AdamW) before compressing and uploading the resulting "pseudo-gradients" to other nodes. Compression techniques include top-k sparsification (retaining only the most critical gradient components), error feedback (accumulating discarded gradients for the next round), and 2-bit quantization. The final compression ratio exceeds 146x.
In other words, what previously required transmitting 100 MB now needs less than 1 MB.
This enables the system to maintain a computational utilization of approximately 94.5% under the bandwidth constraints of a standard internet connection (110 Mbps upload, 500 Mbps download)—with 20 nodes, each equipped with 8 B200 accelerators, and each communication round taking only 70 seconds.
Gauntlet addresses incentive compatibility. It operates on the Bittensor blockchain (Subnet 3) and is responsible for validating the quality of pseudo-gradients submitted by each node. Specifically, it tests how much the model's loss decreases when incorporating a node’s gradient using a small batch of data; this result is called the LossScore. The system also verifies whether the node is training on its assigned data—if a node shows greater loss improvement on random data than on its assigned data, it receives a negative score.
Ultimately, only the gradients from the highest-scoring nodes are selected for aggregation in each round, with all other nodes eliminated for that round. Additional participants are dynamically added as needed to maintain system stability. Throughout the training process, an average of 16.9 node gradients are included in each aggregation round, with more than 70 unique node IDs having participated cumulatively.
The value narrative of decentralized AI is undergoing a fundamental shift.
From a technical and industry perspective, the direction represented by Covenant-72B has several genuine implications.
First, it breaks the assumption that distributed training is only suitable for small models. Although it still lags behind state-of-the-art models, it demonstrates the scalability of this approach.
Second, permissionless participation is not only possible but practical—an aspect that has been underappreciated. Previous distributed training projects relied on whitelists, allowing only vetted participants to contribute computing power. In this SN3 training, anyone with sufficient computing power can join, while the verification system filters out malicious contributions. This represents a concrete step toward true decentralization.
Third, Bittensor’s dTAO mechanism enables market discovery of subnet value. dTAO allows each subnet to issue its own Alpha token, using an AMM mechanism to let the market determine which subnets receive greater TAO emissions. This provides a rough but effective value capture mechanism for subnets like SN3 that have delivered tangible results. However, this mechanism is also susceptible to narrative and sentiment-driven fluctuations, as the quality of LLM training outcomes is difficult for typical market participants to independently assess.
Fourth, the political and economic implications of decentralized AI training. Jack Clark, in Import AI, elevates this issue to the level of “Who owns the future of AI?” Currently, training state-of-the-art models is monopolized by a few institutions with large-scale data centers—a problem not merely commercial, but one of power structures. If distributed training continues to make technical progress, it could potentially foster a genuinely decentralized development ecosystem for certain types of models, such as small-scale frontier models in specific domains. Of course, this prospect remains distant for now.
Summary: A genuine milestone, along with a host of real issues
Huang Renxun said this is like a "modern-day Folding@home." Folding@home made real contributions in the field of molecular simulation, but it did not threaten the core R&D positions of large pharmaceutical companies. This analogy is very accurate.
SN3 has successfully implemented the protocol and validated a viable direction for distributed training. However, from both technical and industry perspectives, behind this performance report lie a host of issues that few are willing to seriously discuss:
MMLU itself is also a controversial metric in academia, with risks of leaked questions and answers entering training sets. More importantly, the choice of baseline models is concerning: the LLaMA-2-70B and LLM360 K2 models referenced in the paper are both outdated models from 2023 to 2024, while scores in the 65–70 range are considered mid-to-lower or beginner-level when compared to models like Grok and Doubao, and regarded as severely behind by Claude. If evaluated on dynamically updated leaderboards or next-generation benchmarks designed with anti-contamination measures, the conclusions might be far more honest.
More critically, the high-quality data that determines the upper limit of a model’s capabilities—conversational data, code, mathematical derivations, and scientific literature—is likely held by major corporations, publishing houses, and academic databases. While computing power has been democratized, the data landscape remains oligopolistic—a contradiction that has not been addressed.
Regarding security, permissionless participation means you don’t know who is behind those 70+ nodes or what data they are using for training. Gauntlet can filter out obviously anomalous gradients, but it cannot prevent subtle data poisoning—if a node systematically trains several additional rounds on harmful content types, the resulting gradient shifts may be subtle enough to pass loss-score screening while still causing cumulative behavioral drift in the model. The ultimate question is: what risks arise when using a model trained by a small number of anonymous nodes with incomplete traceability of data sources, in high-compliance, security-critical domains such as finance, healthcare, or legal?
There is also a structural issue worth stating directly: Covenant-72B is open-sourced under the Apache 2.0 license and does not use SN3 tokens. Holding SN3 tokens entitles you to a share of the emission rewards generated by the subnet’s ongoing production of new models, not to any direct revenue from model usage. This value chain depends on continuous training output and the healthy functioning of Bittensor’s overall network emission mechanism. If training stalls in the future, or if new training outputs fail to meet quality expectations, the valuation logic of the token will weaken.
Listing these issues is not meant to negate the significance of Covenant-72B. The fact that it proved something previously thought impossible can be achieved will not disappear. But achieving it and what it truly means are two different things.
The SN3 token has risen 440% over the past month. The gap between this surge and reality may not be mere speculation, but rather the fact that narratives often move faster than reality. Whether this gap will eventually be closed by reality or absorbed by market correction depends on what the Covenant AI team delivers next.
Notably, Grayscale submitted an application for a TAO ETF in January 2026, signaling institutional interest in this sector. Additionally, in December 2025, Bittensor halved its daily TAO emissions, further intensifying the structural supply reduction.
Reference link:
https://arxiv.org/pdf/2603.08163
https://importai.substack.com/p/importai-449-llms-training-other
https://docs.tplr.ai/
https://systems-analysis.ru/int/MMLU_Benchmark_%E2%80%94_MMLU_%E5%9F%BA%E5%87%86%E6%B5%8B%E8%AF%95