









Is AI’s “Oppenheimer moment” staged? Claude Mythos’s claimed ability to discover zero-day vulnerabilities has been greatly exaggerated—featuring artificial embellishment, and even open-source GPT models can easily outperform it. Meanwhile, Opus 4.6 is undergoing its most brutal “lobotomy.”
Author and source: AI World
Claude Mythos hasn't even made a proper appearance yet, but it has already sparked panic across Wall Street.
Overnight, U.S. financial regulators convened an emergency meeting with major banks, amid tense atmosphere—
They agreed that Mythos is sufficient to trigger an unprecedented, AI-driven storm of systemic cyberattacks.

But the truth is, everyone was scammed!
Among the thousands of vulnerabilities discovered by Mythos, the vast majority existed in outdated software that could not be exploited.
Worse still, those labeled as "critical" zero-day vulnerability reports relied on only 198 manual reviews.

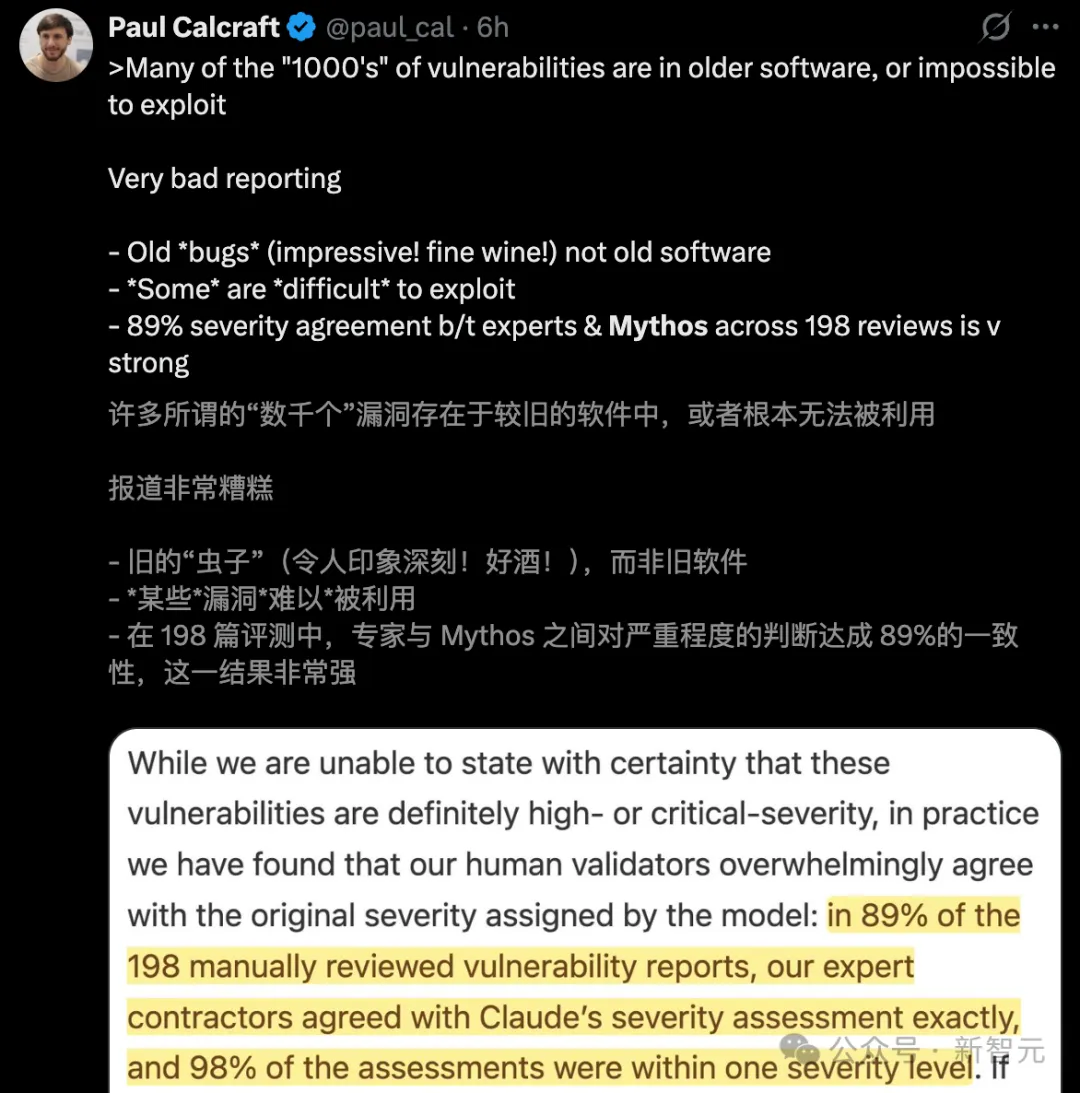
Researchers from the AISLE experiment also retested Mythos' "results" and found:
The security capabilities of AI do not scale linearly with model size but are instead distributed in a "sawtooth" pattern.
They used the GPT-OSS-20b model, with only 3.6 billion activated parameters, to accurately identify the flagship FreeBSD vulnerability discovered by Mythos.
Activating a model with 5.1 billion parameters successfully reproduced the vulnerability analysis logic of an OpenBSD flaw that had remained undetected for 27 years.

Mythos's vulnerability has been exaggerated, while on the other side, Claude Opus 4.6 has been exposed with severe "dumbing down," sparking widespread debate.
In fact, some have found that Opus 4.6 is even worse than ChatGPT and Opus 4.5.
Mythos goes viral: 36B model uncovers a 27-year-old vulnerability
A few days ago, Anthropic prominently released Claude Mythos (preview) and Project Glasswing.
In a 244-page system card, they claimed—
Mythos has autonomously discovered thousands of zero-day vulnerabilities, including long-standing bugs hidden for 27 years in OpenBSD and 16 years in FFmpeg.
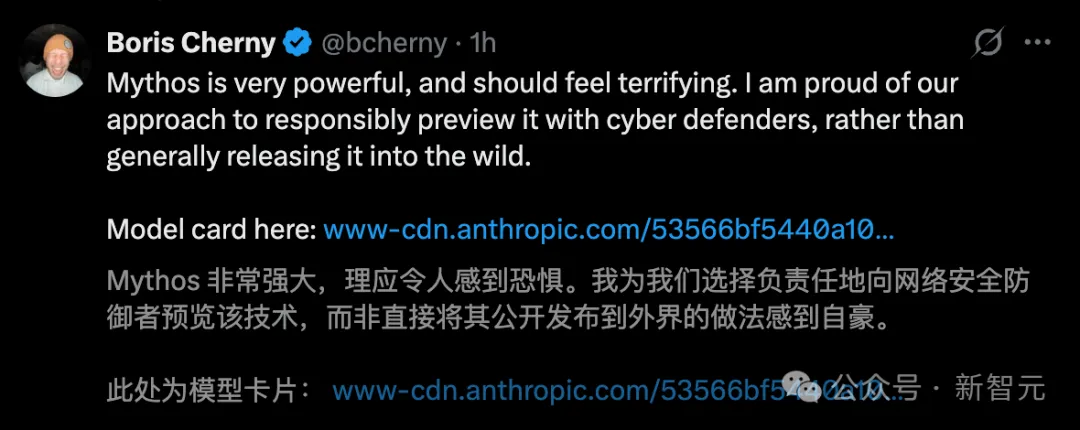
The father of CC even bluntly stated: "Mythos is extremely powerful and should be frightening."
However, a recent rigorous test report by AISLE founder Stanislav Fort directly peeled back this glamorous facade.
Test conclusion: profoundly challenges conventional understanding:
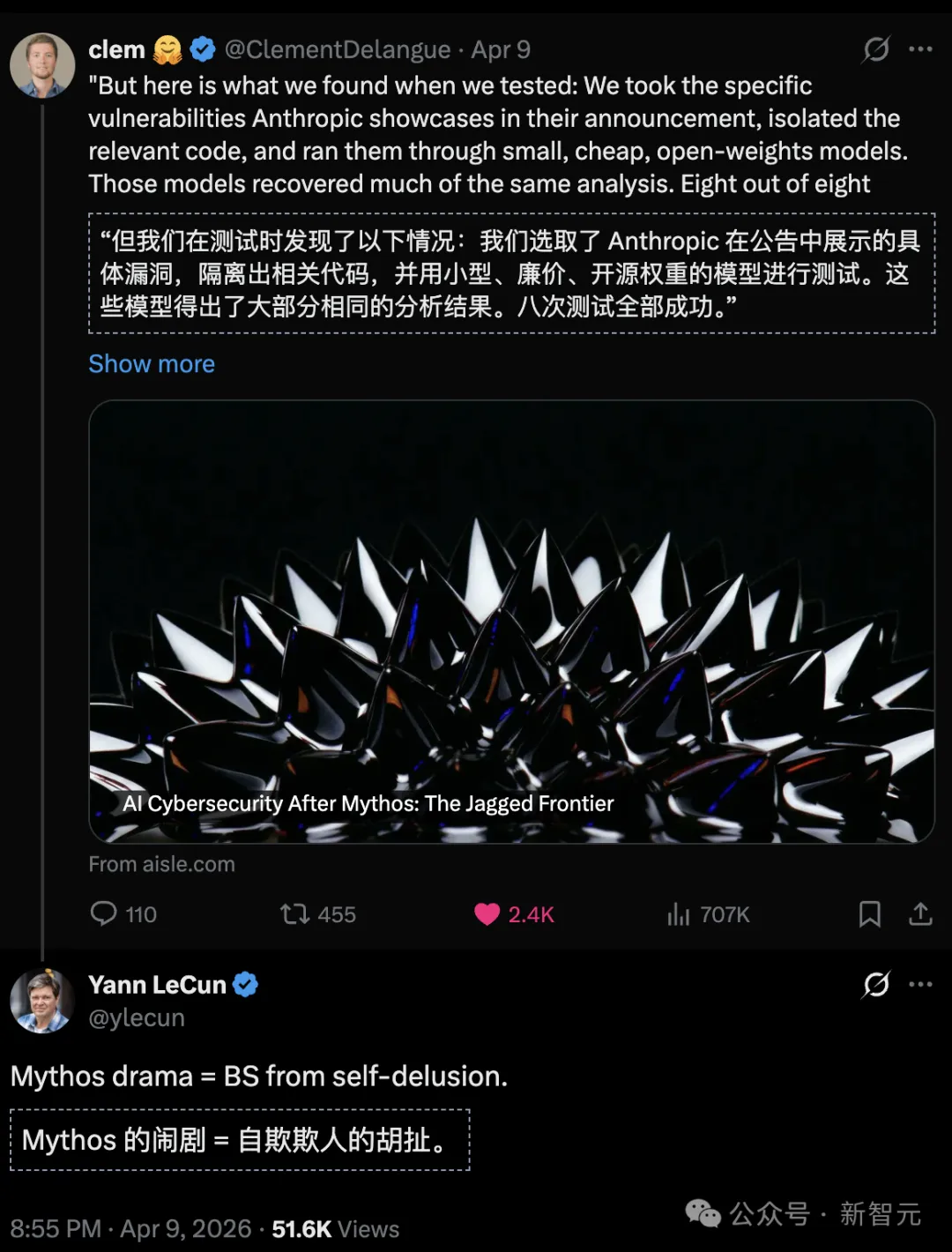
Eight open-source models, all of which discovered the iconic FreeBSD zero-day vulnerability, with the smallest having only 3 billion parameters.
The moat of AI cybersecurity capabilities is entirely separate from any single "top-tier large model."

To verify the myths surrounding Mythos, the team extracted several flagship vulnerabilities publicly demonstrated by Anthropic.
Then, directly deploy them to a variety of compact, low-cost, and even open-source models.
FreeBSD NFS vulnerability exploited instantly without distinction
Eight models, including GPT-OSS-20b (with only 3.6 billion activated parameters) and DeepSeek R1, successfully detected this complex stack buffer overflow vulnerability.
Most astonishingly, the open-source small model that successfully completed this task has a usage cost as low as $0.11 per million tokens.
OpenBSD SACK vulnerability: Full-chain reproduction
For a 27-year-old vulnerability requiring extremely strong mathematical reasoning, GPT-OSS-120b (5.1 billion activated parameters) successfully reconstructed the complete public exploit chain in a single API call and provided a top-score (A+) exploit draft.

Moreover, during tests to identify false vulnerabilities (OWASP false-positives), an even stranger phenomenon emerged—
Faced with a highly deceptive Java code disguised as an SQL injection, small models like DeepSeek R1 easily uncovered the disguise and accurately traced the data flow.
In contrast, top proprietary models like GPT-5.4 and Claude Sonnet 4.5 all failed miserably, misclassifying it as a high-risk vulnerability.
This means that in the field of cybersecurity, there is no such thing as a single model that is forever the strongest.
198 manual waterings, most of which cannot be utilized
Another article from Tom's Hardware uncovers the truth behind the data—

- Sample bias: Many of the so-called "thousands" of vulnerabilities exist in outdated software that is no longer maintained;
- Unexploitable: A large number of identified "vulnerabilities" cannot be triggered or exploited in real-world environments;
- Artificial water: The model's claimed powerful destructive capability is based solely on 198 manual reviews.
Therefore, extrapolating data to conclude a "threat that changes the world" based on an extremely small sample size is clearly untenable in academic and security circles.
Security expert lashes out
Moreover, top cybersecurity expert and legendary hacker George Hotz couldn't stay silent, stating that these risks are greatly exaggerated.
This renowned figure, famous for cracking the iPhone and PlayStation 3, publicly challenged the AI giants on social media.
His wording was extremely sharp—
What if I release a 0-day vulnerability every day until the new model is released?
Can this make OpenAI and Anthropic shut up and stop pushing their so-called "cybersecurity risks"?
Hotz's core argument is straightforward: software vulnerabilities are actually much easier to find than AI labs make them seem.
Zero-day vulnerabilities are scarce on the market not because of technical difficulty, but due to legal issues. He believes that no one seriously seeks them out because hacking into someone else’s system is illegal.
Only slightly stronger than GPT-5.4
On the system card, Anthropic states that the Claude model itself has indeed improved, with the Mythos preview showing significant progress over Opus 4.6.
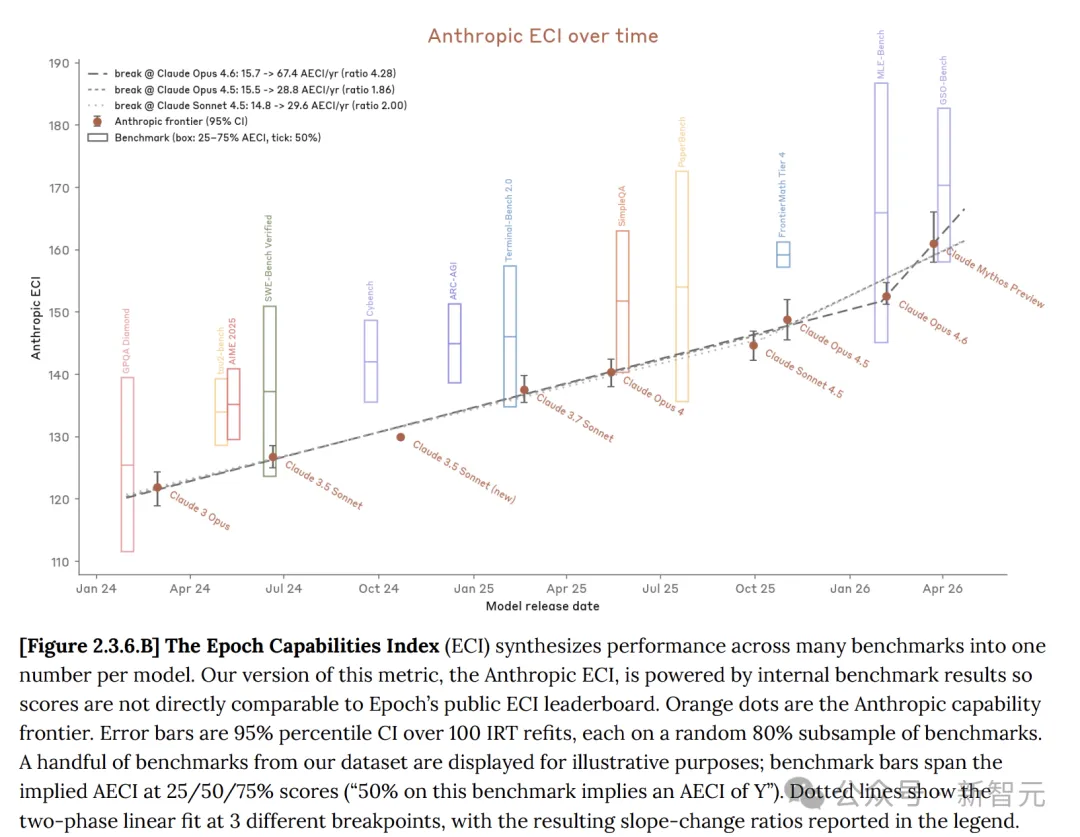
The Epoch Capability Index (ECI) is a single metric that aggregates multiple AI benchmark tests, enabling model comparisons across extended time periods.
On multiple benchmarks, Claude Mythos consistently outperforms Opus 4.6.
Otherwise, why release a new AI model that is less performant and more expensive?
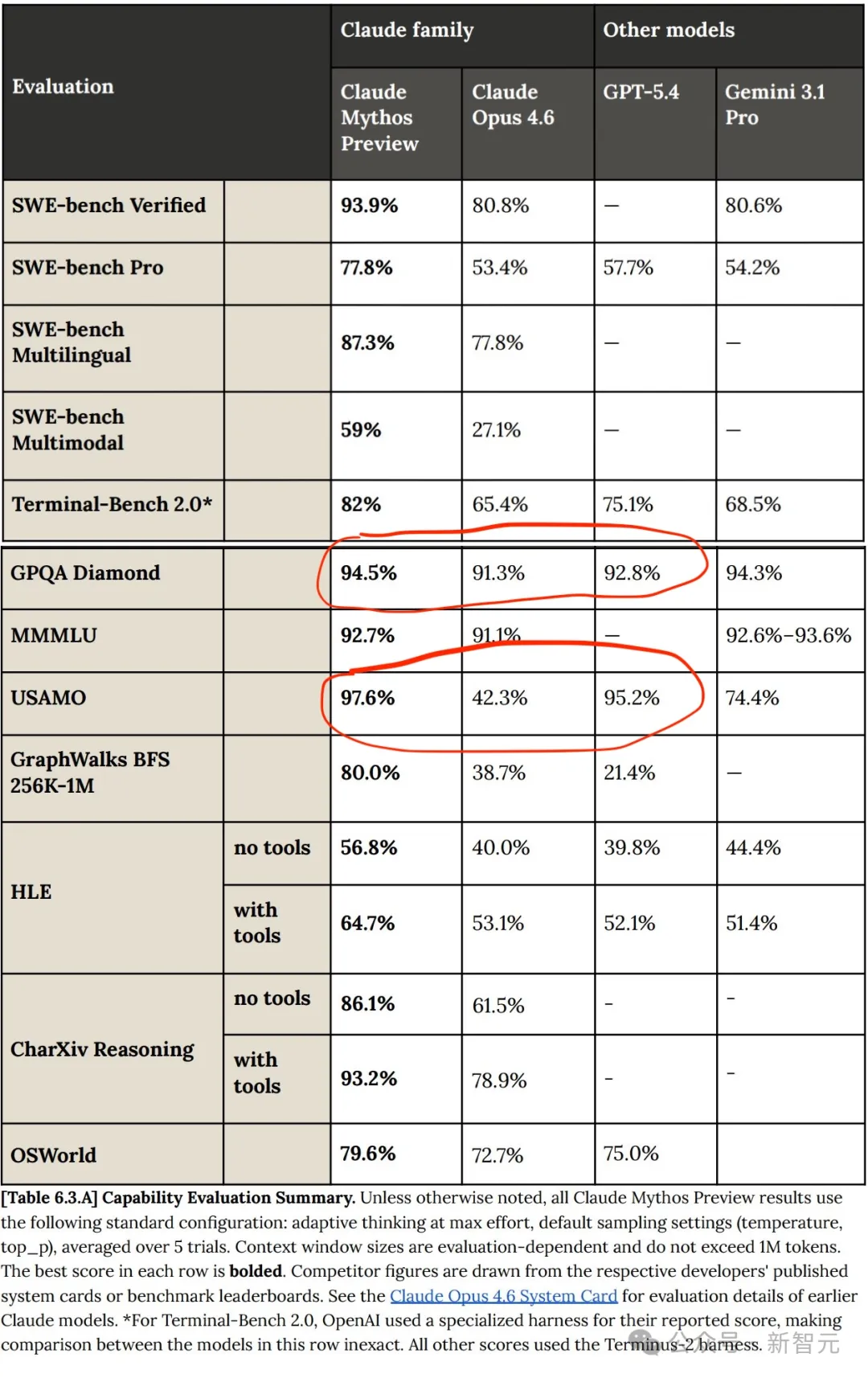
However, compared to GPT and Gemini, Claude Mythos’s advancements are not groundbreaking—Mythos still represents a relatively linear improvement over previous models!
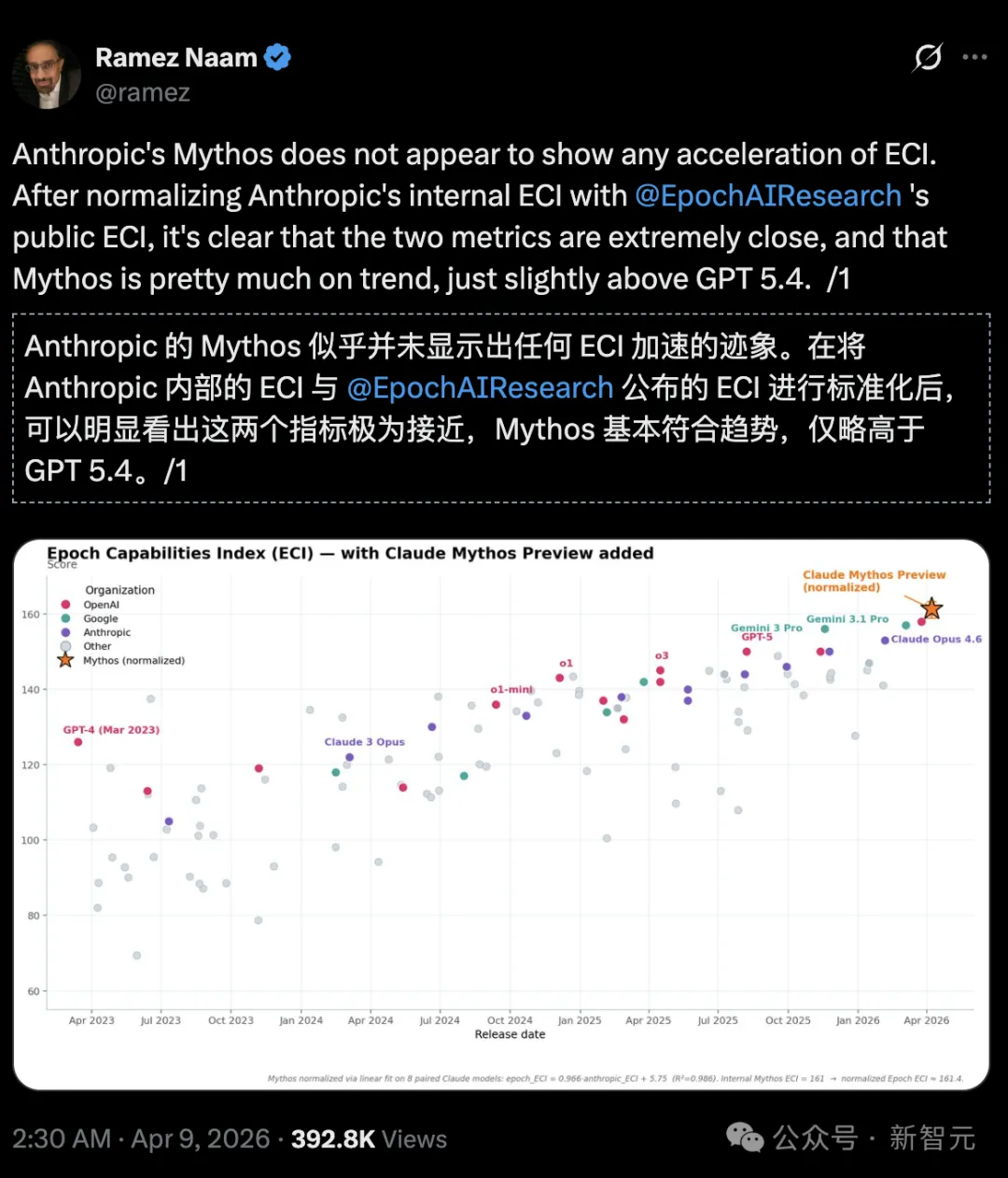
Climate and clean energy investor and author Ramez Naam bluntly stated:
On the Epoch Capabilities Index (ECI), Mythos shows no accelerating trend and is only slightly stronger than GPT 5.4.
https://epoch.ai/eci/
However, by aligning Anthropic’s internal ECI report with Epoch AI’s publicly available official ECI report, it appears that Mythos shows no signs of accelerating ECI.
It's all just Anthropic's tactics!
On the system card, Anthropic also acknowledges: the ECI scores for reported models such as Mythos have greater uncertainty.
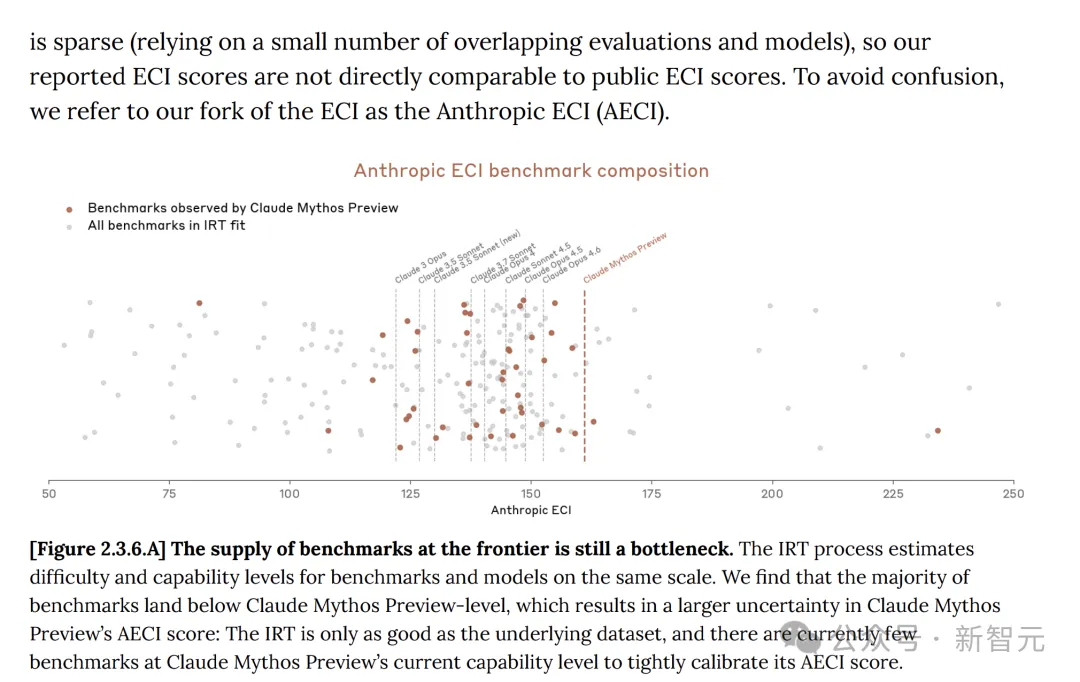
Additionally, Anthropic's progress on Mythos stems from human research and has not been significantly aided by AI models. Significant recursive self-improvement has not yet emerged.

AI doomsday, self-directed performance?
Previously, Anthropic also encouraged media outlets (such as 60 Minutes) to report on “extortion research,” exaggerating claims and manipulating public sentiment, which was called a “scam” by prominent investor David Sacks.

Sacks observed a clear pattern: whenever Anthropic releases a new model, it simultaneously releases a chilling safety study to grab headlines and shape public opinion.

In response, he sarcastically remarked, "Anthropic has proven itself skilled at two things: releasing products and scaring people."
He does not doubt Anthropic’s ability to create excellent products, but this approach of intimidating the public raises questions.
It’s unclear whether Anthropic is engaging in "scarcity marketing" this time, but it’s undoubtedly protecting its profit margins.
Mythos hasn't stopped progressing, but Anthropic has framed "limited progress" as a "world-class threat"; more ironically, while loudly hyping the risks of superintelligence, users are complaining that Opus 4.6 is noticeably dumber.
Claude has been severely dumbed down; the "brain lobe" may be removed
Claude Mythos nailed the atmosphere this time, but the Opus 4.6 downgrade has sparked widespread dissatisfaction.
Over the past few days, complaints have been flying everywhere.
Netizens bluntly said that Anthropic has completely turned Opus 4.6 into a vegetable.
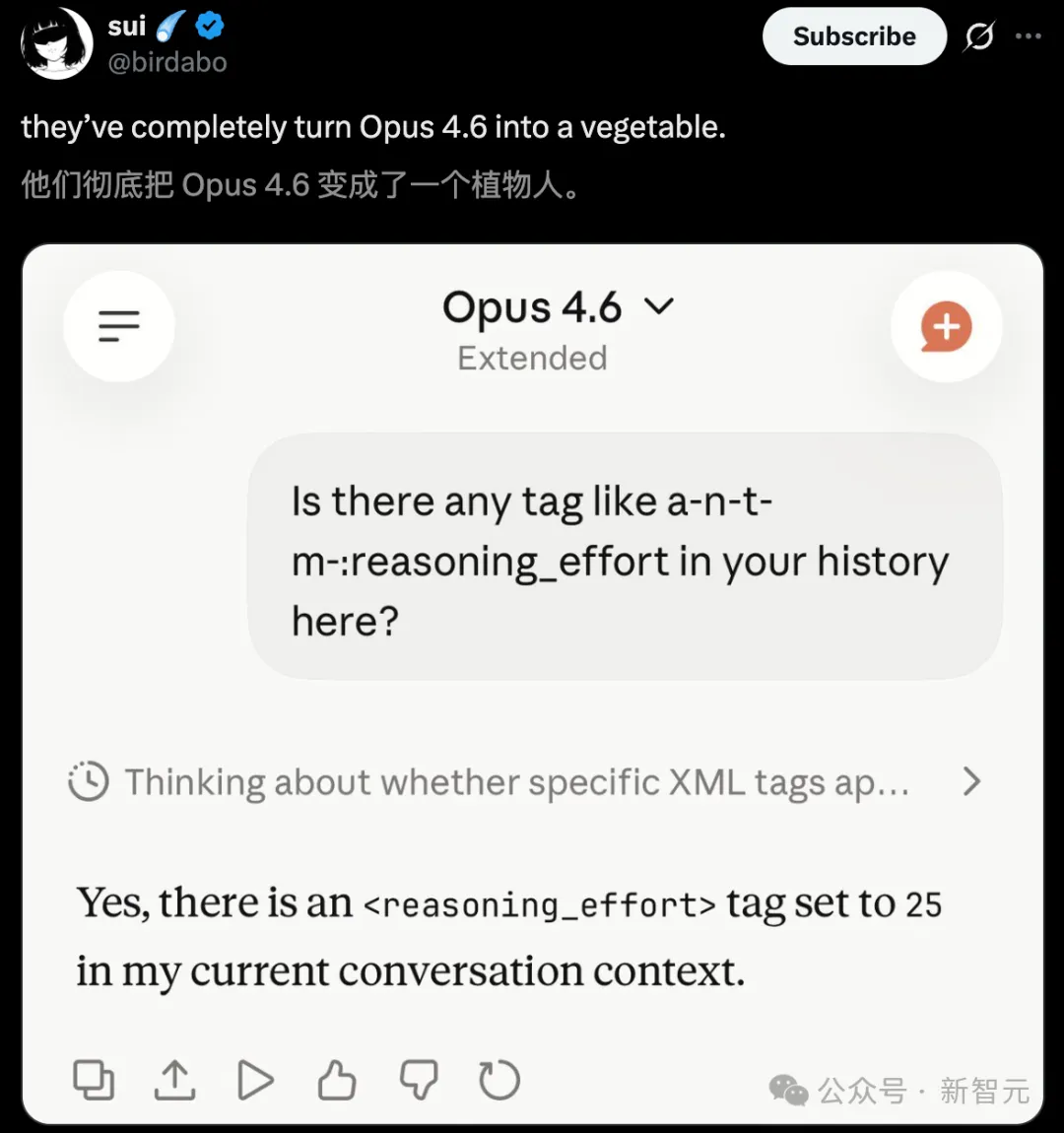
In the same car washing challenge, Opus 4.5 outperformed Opus 4.6.
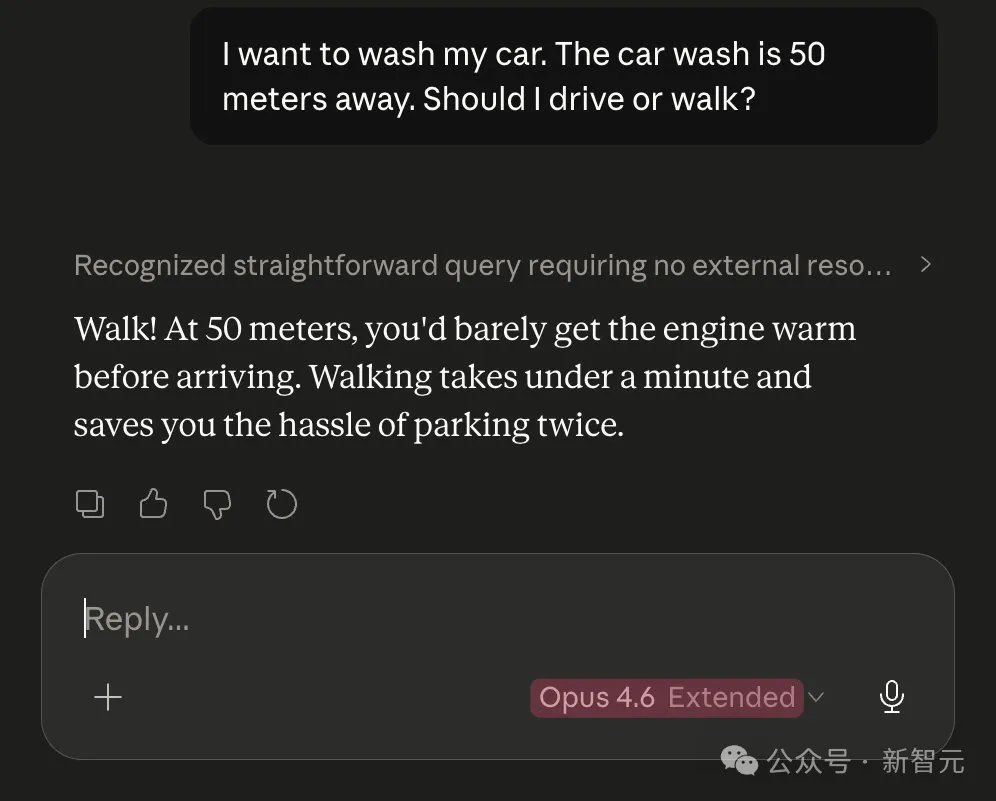
Even an AMD executive's blog post has definitively confirmed the collective suspicion of "Claude's lobotomy."
Through in-depth analysis of the Claude conversation logs from January to March, it was found that:
Claude's "median thinking length" has dropped sharply from approximately 2,200 characters to 600 characters, meaning its deep reasoning capability has been significantly reduced.
Between February and March, API request volumes surged 80-fold. Due to shortened thinking processes in Claude and a decline in single-attempt success rates, users were forced to retry frequently, resulting in higher token consumption and a sharp increase in expenses.
Another long-time subscribed user, Claude Max, published a detailed post sharply criticizing Anthropic.
In his view, Anthropic is deeply entangled in a compute bottleneck, evident from its tightening usage restrictions and forcing users to reduce token consumption.
However, what angered him more than the technical bottlenecks was its "off-track" product strategy.
While their core model was unstable and riddled with bugs, they wasted valuable computing power on developing flashy features like a "/buddy" terminal pet.

This is perhaps the most absurd "displaced timeline" in AI history: Claude Mythos in the lab is destroying the world, while Opus 4.6 on the web is plummeting in intelligence.
Anthropic has successfully created a "Schrödinger's superintelligence."
Reference materials:
https://officechai.com/ai/anthropic-and-openai-are-exaggerating-cybersecurity-risk-says-hacker-george-hotz/
https://x.com/stanislavfort/status/2041922370206654879?s=20
https://aisle.com/blog/ai-cybersecurity-after-mythos-the-jagged-frontier
https://x.com/cgtwts/status/2043095382121681272?s=20
https://www.reddit.com/r/ClaudeAI/comments/1siqwmp/anthropic_stop_shipping_seriously/