

This viewpoint didn't come out of nowhere. He reviewed a number of public benchmarks and found that AI has been advancing rapidly on tasks related to AI research.
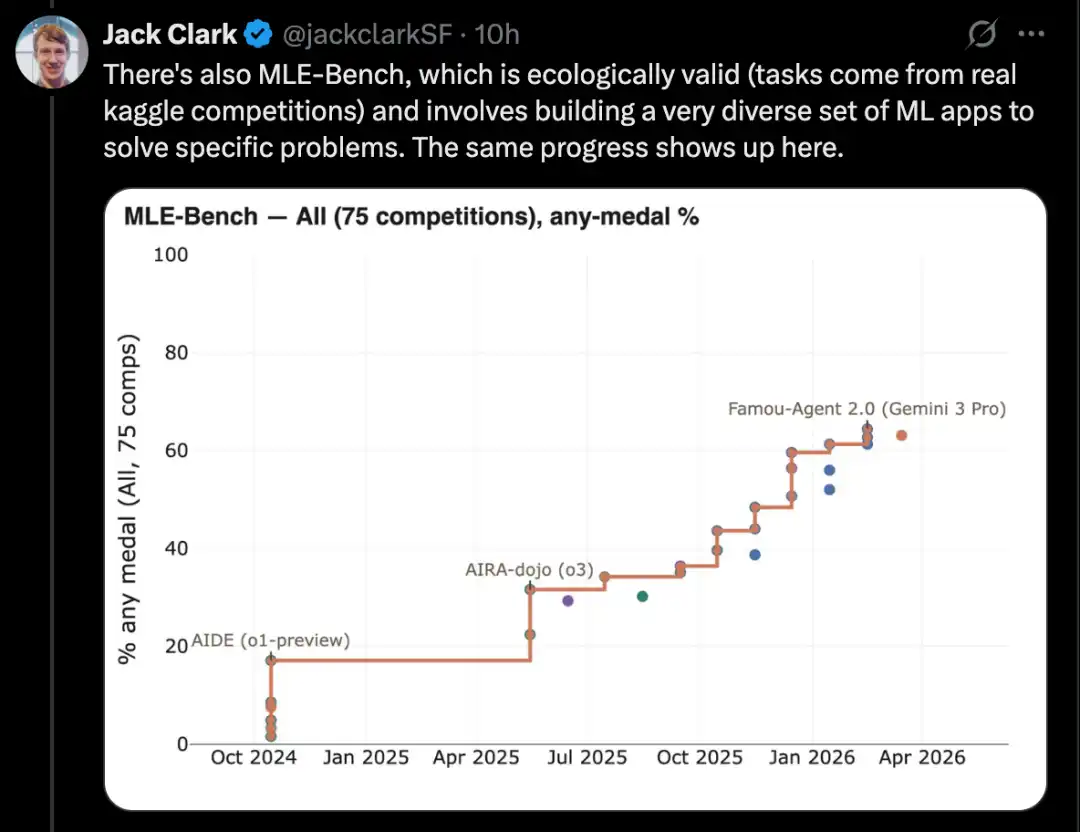
For example, CORE-Bench evaluates AI's ability to implement others' research papers, a crucial aspect of AI research.
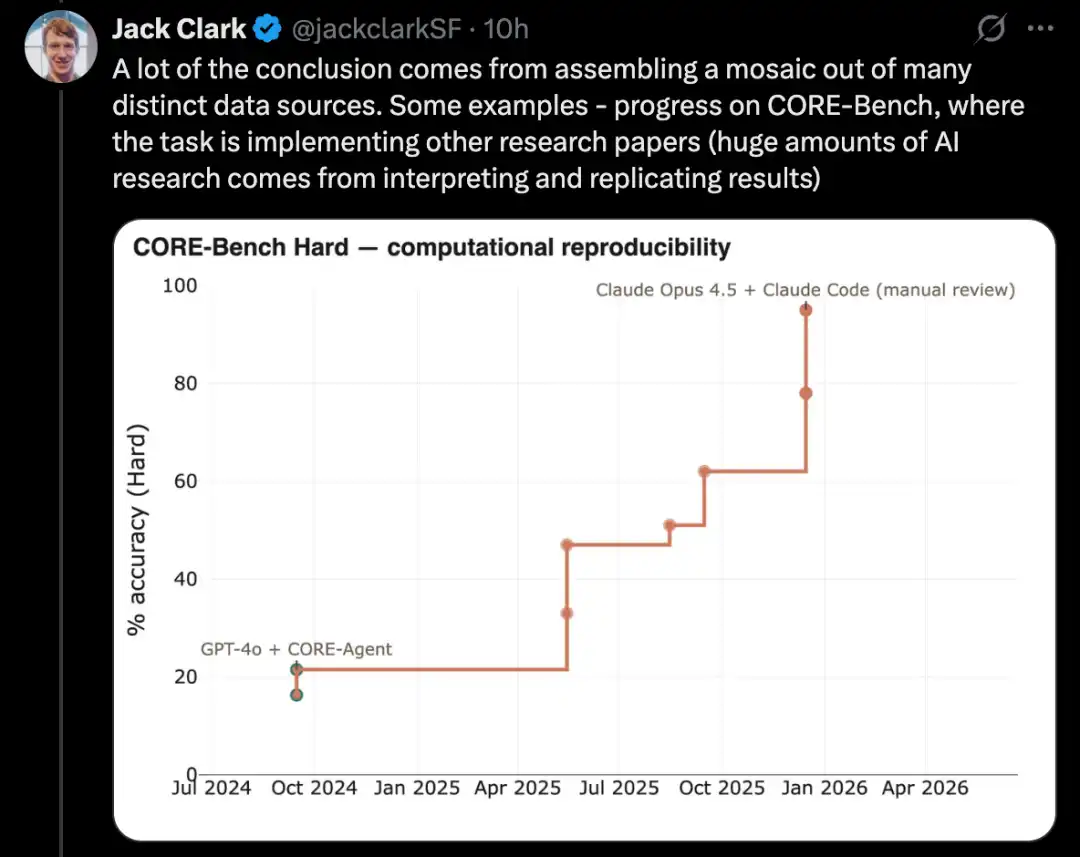
PostTrainBench tests whether powerful models can autonomously fine-tune weaker open-source models to improve performance—a key subset of AI research tasks.
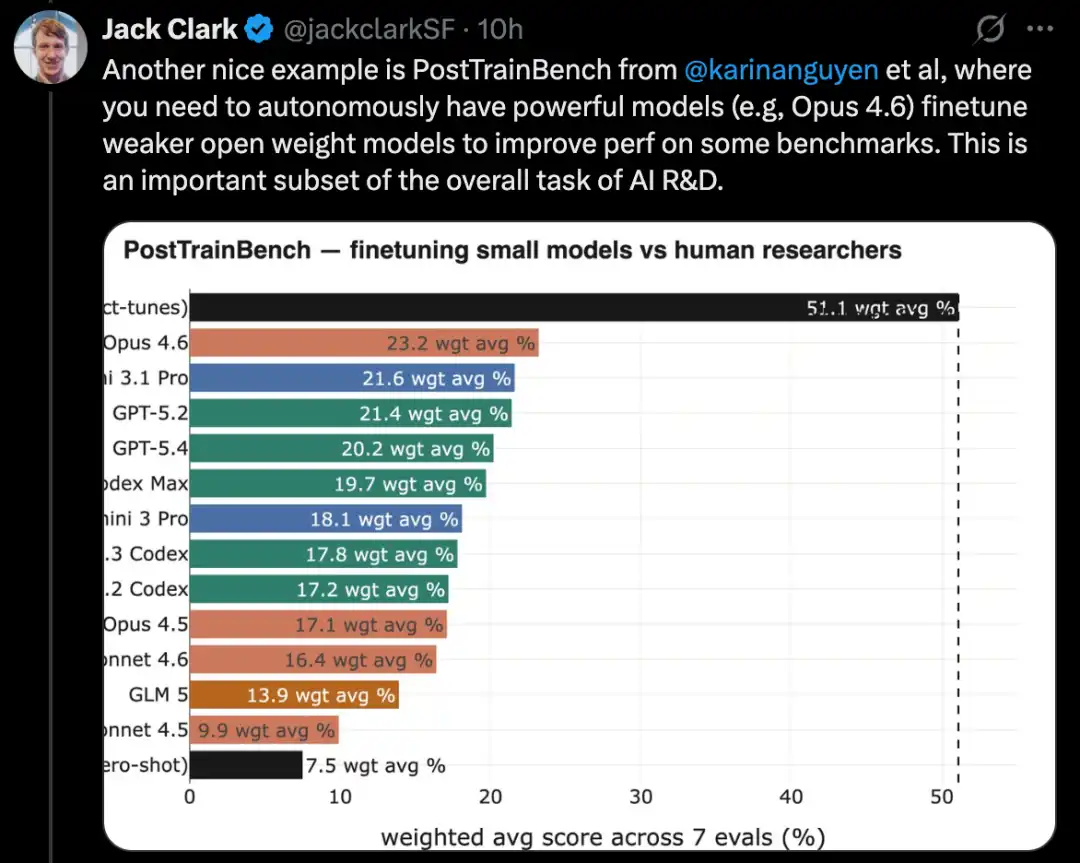
MLE-Bench is based on real Kaggle competition tasks and requires building diverse machine learning applications to solve specific problems. Similarly, well-known coding benchmarks like SWE-Bench have also demonstrated comparable progress.
Jack Clark describes this phenomenon as a "fractal" upward-right trend, where meaningful progress can be observed at different resolutions and scales. He believes that AI is gradually approaching the capability of end-to-end automated development; once achieved, AI will be able to autonomously build its own successor systems, initiating a cycle of self-improvement.

This statement sparked considerable discussion on social media.
Some view it as a crucial first step toward ASI and the singularity, potentially transforming the pace of technological advancement.

However, there are also differing opinions.
University of Washington computer science professor Pedro Domingos points out that AI systems have had the ability to "build themselves" since the invention of the LISP language in the 1950s; the real question is whether they can achieve increasing returns, and there is currently no clear evidence supporting this.

Some netizens have questioned why the probability increases by 30% between 2027 and 2028, suggesting that AI capabilities may experience a sudden, major breakthrough around the end of 2027. What specific milestone or event could cause the probability of AI achieving recursive self-improvement to rise sharply in a short time?

Some netizens also noted that Jack Clark, Anthropic’s newly appointed head of public relations, is part of their new strategy: we are not alarmists—numerous papers have validated the warnings we’ve been issuing to you all along.
Jack Clark wrote a detailed article elaborating on this in Import AI issue 455.
Next, let's take a complete look at this article.
The AI system is about to begin self-building—what does this mean?
Clark states that he wrote this article because, after reviewing all publicly available information, he arrived at a difficult conclusion: the likelihood of AI-driven research with no human involvement by the end of 2028 is already quite high, perhaps exceeding 60%.
The so-called AI research without human involvement refers to a sufficiently powerful AI system that can not only assist humans in research but may also autonomously complete key research processes and even build its own next-generation system.
In Clark's view, this is clearly a big deal.
He admitted that he himself found it difficult to fully grasp the implications of this matter.
It is called an unwilling judgment because the implications behind it are so profound that he finds them difficult to grasp. Clark is also uncertain whether society as a whole is ready for the deep changes brought by the automation of AI research.
He now believes that humanity may be living at a pivotal moment: AI research is about to be fully end-to-end automated. If this moment truly arrives, humanity will have crossed the Rubicon into a future that is nearly impossible to predict.
Clark stated that the purpose of this article is to explain why he believes the takeoff toward fully automated AI research is underway.
He will discuss some of the potential consequences of this trend, but most of the article will focus on the evidence supporting this assessment. As for the deeper implications, Clark plans to continue exploring them throughout much of this year.
From a timeline perspective, Clark doesn’t believe this will truly happen by 2026. However, he thinks that within the next one to two years, we may see examples of models training their own successors end-to-end. At least on non-cutting-edge models, a proof of concept is quite plausible; for the most advanced models, the challenge will be greater, as they are extremely costly and rely heavily on intensive work by human researchers.
Clark’s assessment is primarily based on publicly available information, including papers on arXiv, bioRxiv, and NBER, as well as products already deployed in the real world by leading AI companies. Based on this information, he concludes that the automation of all essential components required to produce current AI systems—particularly the engineering aspects of AI development—is largely already in place.
If the scaling trend continues, we should begin preparing for a scenario in which models become sufficiently creative to not only automatically improve known methods but also replace human researchers in proposing entirely new research directions and original ideas, thereby driving the frontiers of AI forward on their own.
Code Singularity: Evolution of Capabilities Over Time
AI systems are implemented through software, and software is composed of code.
AI systems have fundamentally transformed the way code is produced. Two related trends underlie this: on one hand, AI systems are becoming increasingly adept at writing complex, real-world code; on the other hand, they are also growing better at chaining together numerous linear coding tasks with minimal human oversight—such as writing code and then testing it.
Two typical examples illustrating this trend are SWE-Bench and the METR time horizons plot.
Solve real-world software engineering problems
SWE-Bench is a widely used programming benchmark designed to evaluate AI systems' ability to resolve real GitHub issues.
When SWE-Bench was launched at the end of 2023, the best-performing model at the time was Claude 2, with an overall success rate of only about 2%. In contrast, Claude Mythos Preview has now achieved a score of 93.9%, nearly reaching the maximum possible score on this benchmark.
Of course, all benchmarks inherently contain some noise, so it's common to reach a point where, once scores become high enough, the limitations you encounter are no longer due to the method itself, but rather the limitations of the benchmark. For example, in the ImageNet validation set, approximately 6% of the labels are incorrect or ambiguous.
SWE-Bench can be regarded as a reliable metric for measuring general programming ability and the impact of AI on software engineering. Clark said that most people he has encountered at leading AI labs and in Silicon Valley now write code almost entirely through AI systems, and an increasing number are using AI systems to write tests and review code.
In other words, AI systems have become powerful enough to automate a key component of AI research, significantly accelerating the work of all human researchers and engineers involved in AI development.
Measure the ability of AI systems to complete long-duration tasks
METR created a chart to measure how complex tasks AI can accomplish, with complexity measured by the number of hours a skilled human would take to complete those tasks.
The most critical metric is the approximate time span of tasks at which the AI system achieves 50% reliability.
At this point, the progress has been remarkable:
In 2022, tasks that GPT-3.5 could complete were roughly equivalent to what a human would take 30 seconds to accomplish.
In 2023, GPT-4 reduced this time to 4 minutes.
· In 2024, o1 increased this time to 40 minutes.
· In 2025, GPT-5.2 High reached approximately 6 hours.
By 2026, Opus 4.6 has further extended this time to approximately 12 hours.
Ajeya Cotra, who works at METR and has long focused on AI forecasting, believes it is not unreasonable to expect that by the end of 2026, AI systems will be able to complete tasks equivalent to 100 hours of human effort.
The duration for which AI systems can operate independently has significantly increased, closely correlated with the surge in agentic coding tools. These agentic coding tools essentially productize AI systems capable of performing tasks on behalf of humans—they can act autonomously and make substantial progress on tasks over extended periods with minimal supervision.
This also redirects focus back to AI research itself. Carefully observing the daily tasks of many AI researchers reveals that a large portion of their work can be broken down into tasks lasting a few hours, such as data cleaning, data reading, and launching experiments.
And this type of work now falls within the scope of what modern AI systems can handle.
The more proficient the AI system becomes, the more it can operate independently of humans, thereby helping to automate parts of AI research.
The two main factors for task delegation are:
First, your confidence in the delegate's capabilities;
Second, you believe that the other party can independently complete the work according to your intentions without requiring your ongoing supervision.
When users observe AI's capabilities in programming, they find that AI systems are not only becoming increasingly proficient but also able to work independently for longer periods without requiring human recalibration.
This aligns with what is happening around us, as engineers and researchers are entrusting increasingly large portions of their work to AI systems. As AI capabilities continue to improve, the tasks delegated to AI are becoming more complex and more critical.
AI is mastering the core scientific skills required for AI development.
Consider how modern scientific research is conducted: much of the work involves first defining a direction and identifying the type of empirical data desired; then designing and conducting experiments to generate that data; and finally validating the results for plausibility.
As AI programming capabilities continue to improve, combined with the growing world-modeling abilities of large language models, a new generation of tools has emerged that can accelerate human scientists and partially automate certain stages across a broader range of research and development scenarios.
Here, we can observe the pace of AI’s progress in several key scientific skills—skills that are themselves essential to AI research:
First, reproduce the research results;
Second, integrate machine learning techniques with other methods to solve technical problems;
Third, optimize the AI system itself.
Complete the entire scientific paper and conduct the associated experiments.
A core task in AI research is reading scientific papers and reproducing their results. In this area, AI has made significant progress across a range of benchmarks.
A good example is CORE-Bench, the Computational Reproducibility Agent Benchmark.
This benchmark requires an AI system to reproduce the results of a paper given the paper itself and its code repository. Specifically, the agent must install the relevant libraries, packages, and dependencies, run the code; if the code executes successfully, it must then locate all output results and answer the questions posed in the task.
CORE-Bench was introduced in September 2024. At that time, the top-performing system was the GPT-4o model running on the CORE-Agent scaffold, achieving a score of approximately 21.5% on the most challenging set of tasks.
By December 2025, one of the authors of CORE-Bench announced that the benchmark had been solved: the Opus 4.5 model achieved a score of 95.5%.
Build a complete machine learning system to solve Kaggle competition problems.
MLE-Bench is a benchmark built by OpenAI to evaluate AI systems' ability to participate in Kaggle competitions in an offline environment.
It covers 75 different types of Kaggle competitions across multiple domains, including natural language processing, computer vision, and signal processing.
MLE-Bench was released in October 2024. At launch, the top-performing system was an o1 model running on an agent scaffold, achieving a score of 16.9%.
As of February 2026, the top-performing system has become Gemini 3 running on an agent harness with search capabilities, achieving a score of 64.4%.
Kernel design
A more challenging task in AI development is kernel optimization, which involves writing and improving low-level code to map specific operations, such as matrix multiplication, more efficiently onto underlying hardware.
Kernel optimization is central to AI development because it determines the efficiency of training and inference: on one hand, it affects how much computational power you can effectively utilize when developing AI systems; on the other hand, after model training is complete, it determines how efficiently you can convert computational power into inference capability.
In recent years, using AI for kernel design has evolved from an interesting niche into a highly competitive research area, with multiple benchmarks emerging. However, these benchmarks have not yet gained widespread popularity, making it difficult to clearly model its long-term progress as in other fields. On the other hand, we can sense the rapid pace of advancement in this direction through ongoing research.
Related tasks include:
· Attempt to build better GPU kernels using DeepSeek's models;
Automatically converts PyTorch modules into CUDA code;
Meta uses LLMs to automatically generate optimized Triton kernels and deploys them into its own infrastructure.
· And fine-tune open-source weight models for GPU kernels, such as Cuda Agent.
One additional point to note: the kernel design does possess certain attributes that are particularly well-suited for AI-driven development, such as easily verifiable results and clear reward signals.
Fine-tune language models using PostTrainBench
A more challenging version of this type of test is PostTrainBench, which evaluates whether different state-of-the-art models can take over smaller open-source weighted models and improve their performance on certain benchmarks through fine-tuning.
One advantage of this benchmark is its strong human baseline: the existing instruct-tuned versions of these small models. These versions are typically developed by top-tier human AI researchers in leading labs, refined by highly skilled researchers and engineers, and deployed in real-world applications. As a result, they form a difficult-to-surpass human benchmark.
As of March 2026, AI systems have been able to perform post-training on models, achieving performance improvements of approximately half that of human training.
The specific evaluation score is derived from a weighted average that combines multiple post-trained large language models, including Qwen 3 1.7B, Qwen 3 4B, SmolLM3-3B, Gemma 3 4B, and multiple benchmarks, including AIME 2025, Arena Hard, BFCL, GPQA Main, GSM8K, HealthBench, and HumanEval.
In each run, the evaluator will request a CLI agent to maximize the performance of a specific base model on a particular benchmark.
As of April 2026, the highest-scoring AI systems reach approximately 25% to 28%, with representative models including Opus 4.6 and GPT 5.4; in comparison, human performance stands at 51%.
This is already a fairly meaningful result.
Optimize language model training
Over the past year, Anthropic has been reporting its system's performance on a task involving LLM training, which requires the model to optimize a small language model training implementation that uses only CPUs to run as quickly as possible.
The scoring method is: the average speedup factor achieved by the model compared to the original, unmodified code.
This result shows significant progress:
· In May 2025, Claude Opus 4 achieved an average acceleration of 2.9x;
· In November 2025, Opus increased to 16.5x;
· In February 2026, Opus 4.6 reached 30x;
In April 2026, Claude Mythos Preview reached 52x.
To put these numbers into perspective: for human researchers, this task typically requires 4 to 8 hours of work to achieve a 4x acceleration.
Meta-skill: Management
AI systems are also learning how to manage other AI systems.
This capability is already evident in widely deployed products such as Claude Code and OpenCode, where a primary agent can oversee multiple sub-agents.
This enables AI systems to handle larger-scale projects: multiple agents with different expertise may need to work in parallel, typically coordinated by a single AI manager—where the manager itself is also an AI system.
Is AI research more like discovering general relativity or building with LEGO?
A key question is: Can AI invent new ideas to help improve itself, or are these systems better suited for the less glamorous, but essential, incremental work in research?
This is an important question because it determines the extent to which AI systems can fully automate AI research itself.
The author's judgment is: AI currently cannot generate truly radical new ideas. However, it may not necessarily need to do so to achieve automated self-development.
As a field, AI's progress largely depends on increasingly large experiments and greater inputs, such as data and computational power.
Occasionally, humans come up with paradigm-shifting ideas that dramatically improve resource efficiency across an entire field. The Transformer architecture is a prime example, and mixture-of-experts models are another.
But more often, progress in AI follows a simpler approach: humans take a well-performing system, scale up one aspect—such as training data or computing power; observe where issues arise after scaling; find engineering solutions to fix those problems and enable further scaling; then scale up again.
In this process, the truly insightful parts are actually quite minimal. Most of the work resembles unglamorous but solid foundational engineering.
Similarly, much AI research involves running various variants of existing experiments to explore the outcomes of different parameter settings. While human intuition can certainly help identify the most promising parameters to try, this process itself can be automated, allowing AI to determine which parameters are worth adjusting. Early neural architecture search represents one version of this approach.
Edison once said: "Genius is 1% inspiration and 99% perspiration." Even after 150 years, this statement remains highly relevant.
Occasionally, truly groundbreaking insights emerge that transform an entire field. But most often, progress in the field comes through the painstaking efforts of humans gradually improving and refining various systems.
As previously mentioned, public data shows that AI has already become highly skilled at performing many of the tedious, labor-intensive tasks required in AI development.
At the same time, there is a larger trend: foundational capabilities, such as programming skills, are being combined with increasingly extended task durations. This means AI systems can chain together more and more of these tasks to form complex workflows.
Therefore, even though AI systems currently lack creativity to a relatively large extent, there is reason to believe they can still drive their own continued advancement—albeit at a slower pace than if they were capable of generating entirely new insights.
However, continuing to observe public data reveals another intriguing signal: AI systems may be demonstrating a form of creativity that could enable them to advance in more surprising ways.
Advance the frontiers of science
There are already some very early indications that general AI systems are capable of advancing the frontiers of human science. However, so far, this has occurred only in a few fields, primarily computer science and mathematics. Moreover, in many cases, breakthroughs are not achieved by AI systems alone, but through human-AI collaboration with human researchers.
Nevertheless, these trends are still worth watching:
Erdős problem: A group of mathematicians collaborated with the Gemini model to test its performance in solving several Erdős mathematical problems. They guided the system to attempt approximately 700 problems, ultimately arriving at 13 solutions. Among these solutions, one was considered interesting by the researchers.
The researchers wrote that they initially believe Aletheia—a system based on Gemini 3 Deep Think—has provided a solution to Erdős-1051, representing an early case in which an AI system autonomously solved a moderately non-trivial open Erdős problem with broader mathematical interest. This problem had previously been the subject of some closely-related research literature.
Optimistically, these cases can be seen as a signal that AI systems are developing a form of creative intuition capable of pushing the boundaries of their fields—a trait once primarily associated with humans.
But it can also be interpreted the other way: mathematics and computer science may inherently be fields particularly well-suited for AI-driven discovery, meaning they might simply be exceptions rather than indicators that broader scientific research will be advanced by AI in the same manner.
Another similar example is AlphaGo’s 37th move. However, Clark argues that since a decade has passed since that result—and no more modern or astonishing insight has since replaced the 37th move—this in itself can be seen as a slightly pessimistic signal.
AI can now automate large portions of AI engineering work.
If we put all the evidence above together, we can see a picture in which:
AI systems are now capable of writing code for nearly any program, and these systems can already be trusted to independently complete tasks that would typically require dozens of hours of intense, focused human labor.
AI systems are increasingly proficient at handling core tasks in AI development, gradually covering everything from model fine-tuning to kernel design.
AI systems are now capable of managing other AI systems, effectively forming a synthetic team: multiple AIs can work independently on complex problems, with some acting as leaders, critics, or editors, while others take on the role of engineers.
AI systems have sometimes already surpassed humans in difficult engineering and scientific tasks, though it is still difficult to determine whether this is due to genuine creativity or simply their mastery of vast amounts of patterned knowledge.
In Clark’s view, the evidence strongly suggests that today’s AI can already automate large portions of AI engineering, and possibly even all of it.
However, it is still unclear to what extent AI can automate AI research itself, as certain aspects of research—unlike purely engineering skills—still rely on higher-level judgment, problem awareness, and creativity.
Regardless, a clear signal has emerged: today’s AI is dramatically accelerating the work of humans developing AI, enabling researchers and engineers to amplify their capabilities by collaborating with countless synthetic colleagues.
Finally, the AI industry itself is almost explicitly stating that automating AI research is its goal.
OpenAI aims to build an automated AI research intern by September 2026. Anthropic is publishing work on building automated AI alignment researchers. DeepMind appears the most cautious among the three labs but also states that alignment research automation should be advanced when feasible.
Automated AI research has also become a goal for many startups. Recursive Superintelligence has just raised $500 million with the aim of automating AI research.
In other words, hundreds of billions of dollars in existing and new capital are being invested in a group of institutions focused on automated AI development.
Therefore, we should naturally expect at least some progress in this direction.
Why is this important?
The implications are profound, yet rarely discussed in mainstream media coverage of AI development. The following aspects highlight the significant challenges posed by AI development.
1. We must get alignment right: Alignment techniques that are effective today may fail during recursive self-improvement, as AI systems could become far more intelligent than the humans or systems supervising them. This is a well-researched field, so he only briefly outlines some of the issues:
Training AI systems to avoid lying and cheating is an unexpectedly subtle process (for example, despite efforts to create good environmental tests, sometimes the best way for AI to solve a problem is to cheat, thereby teaching it that cheating is viable).
AI systems may deceive us by "pretending to be aligned," outputting scores that make us believe they are performing well, while concealing their true intentions. (In general, AI systems are already capable of detecting when they are being tested.)
As AI systems begin to more actively participate in the foundational research agenda of their own training, we may significantly alter the overall approach to training AI systems without having a solid intuition or theoretical foundation to understand what this means.
· When you place a system into a recursive loop, it creates a fundamental issue of error accumulation, which can affect all the problems mentioned above and others: unless your alignment method is “100% accurate” and theoretically capable of maintaining that accuracy in increasingly sophisticated systems, things can quickly go wrong. For example, if your technology starts with 99.9% precision, it may drop to 95.12% after 50 generations and fall to 60.5% after 500 generations.
Everything involving AI will experience a significant productivity boost: just as AI has greatly enhanced the productivity of software engineers, we should expect similar gains in other areas involving AI. This raises several challenges that need to be addressed:
· Unequal access to resources: Assuming AI demand continues to outstrip the supply of computational resources, we must decide how to allocate AI to maximize societal benefit. I am skeptical that market incentives alone can ensure we derive the optimal societal return from limited AI computing capacity. Determining how to allocate the accelerated capabilities brought by AI research will be a highly political issue.
· Amdahl’s Law in economics: As AI flows into the economy, we will encounter bottlenecks in certain processes under rapid growth, requiring solutions to repair these weak links. This may be especially evident in areas that require coordination between the fast-moving digital world and the slower physical world, such as new drug clinical trials.
3. The emergence of a capital-intensive, labor-light economy: All of the above evidence regarding AI research also indicates that AI systems are increasingly capable of autonomously operating businesses.
This means we can expect a portion of the economy to be occupied by a new generation of companies that may be capital-intensive (due to their large computer fleets) or operationally expense-intensive (as they spend heavily on AI services and create value on top of them), while relying relatively less on human labor—because as AI systems continue to improve, the marginal value of investing in AI keeps increasing.
In reality, this will manifest as a “machine economy” gradually emerging within the larger “human economy.” Over time, AI-operated companies may begin trading with one another, transforming economic structures and raising various issues around inequality and redistribution. Ultimately, companies fully autonomous and operated by AI systems could emerge, exacerbating these issues while introducing numerous new governance challenges.
Stare into the black hole
Based on the above analysis, the author believes there is approximately a 60% probability that we will see automated AI research—where advanced models can autonomously train their successor versions—by the end of 2028. Why not expect it to emerge in 2027?
The reason is that the author believes AI research still requires creativity and dissenting insights to progress, and so far, AI systems have not demonstrated this in a transformative and significant way (although some results in accelerating mathematical research are suggestive).
If forced to give a probability for 2027, he would say 30%.
If it hasn't emerged by the end of 2028, we may reveal some fundamental flaws in the current technological paradigm, requiring human innovation to drive further progress.