
How Do Self-Learning AI Agents Differ from Traditional Machine Learning Models and Current LLM-Based Agents?
2026/05/02 15:21:02
Introduction
The artificial intelligence landscape is undergoing a profound transformation. While traditional machine learning models dominated the past decade and large language models captured the world's attention since 2022, a new paradigm is emerging that fundamentally changes how AI systems operate. Self-learning AI agents represent the next evolutionary leap, combining autonomy, adaptive reasoning, and continuous improvement in ways that distinguish them sharply from both their predecessors and current LLM-based systems. Understanding these differences is essential for anyone seeking to navigate the rapidly evolving AI ecosystem.
What Are Self-Learning AI Agents?
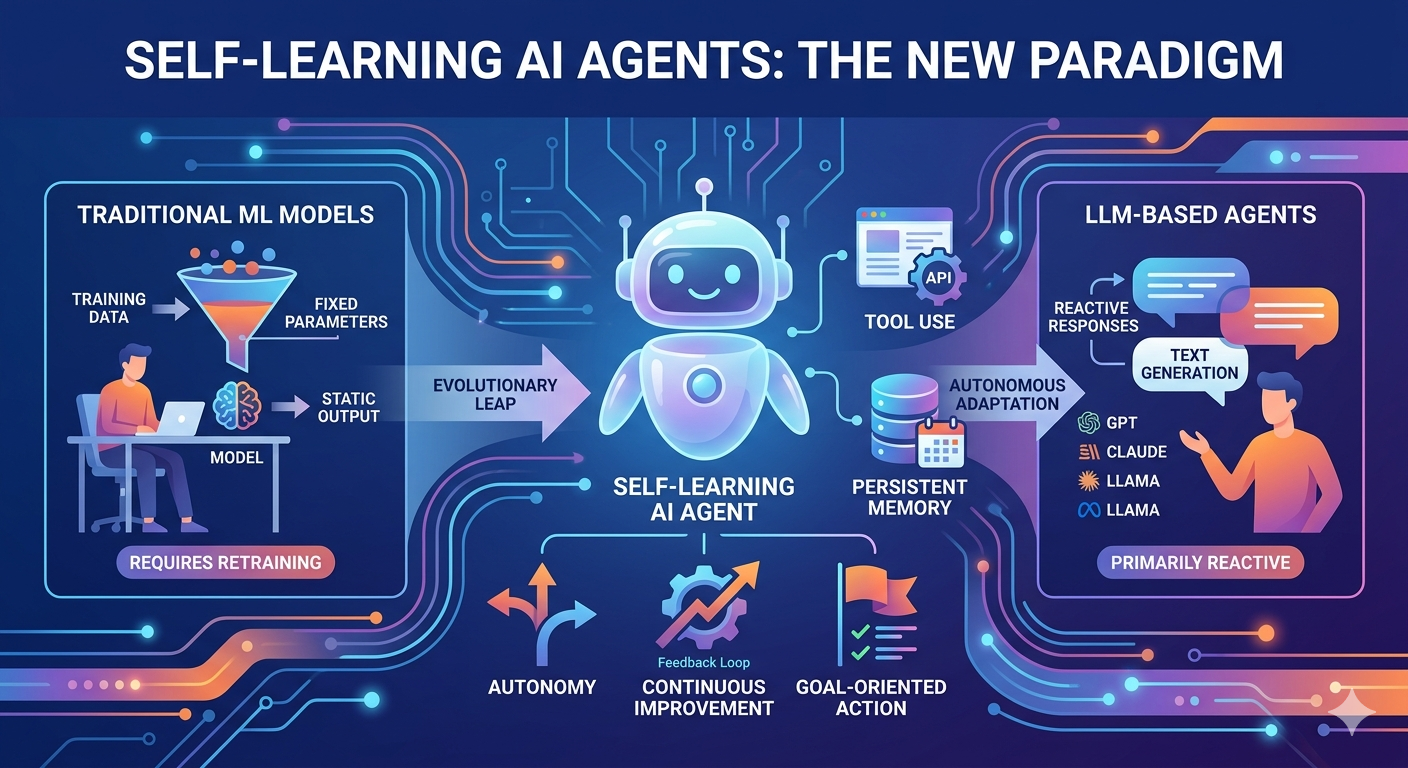
Self-learning AI agents are autonomous computational entities capable of perceiving their environment, analyzing information, formulating decisions, and executing actions to achieve specific goals. Unlike conventional AI systems that require human prompting at every step, self-learning agents can be given a high-level objective and will independently determine how to accomplish it. These agents combine perception, reasoning, learning, and action capabilities to simulate intelligent behavior previously seen only in biological systems.
The defining characteristics of self-learning AI agents include autonomy, reactivity, pro-activeness, and social ability. Autonomy allows agents to operate independently without continuous human intervention. Reactivity enables them to perceive environmental changes and respond appropriately. Pro-activeness means they do not merely react to stimuli but actively pursue goals through planning. Social ability permits collaboration with other agents in multi-agent systems to complete complex tasks.
According to Microsoft's 2025 AI predictions, AI-driven agents are gaining higher autonomy to execute more tasks, thereby improving quality of life across multiple domains. The key distinction lies in how these agents handle objectives: while a large language model requires a detailed, well-crafted prompt to produce quality output, an AI agent needs only a goal, and it will independently think through and execute the necessary actions.
Traditional Machine Learning Models: Structure and Limitations
Traditional machine learning models represent a fundamentally different approach to artificial intelligence. These models are typically trained on specific datasets to perform narrow, well-defined tasks such as classification, regression, or clustering. Once deployed, they operate within fixed parameters and cannot modify their behavior based on new experiences without explicit retraining.
The architecture of traditional ML models centers on statistical learning from historical data. A model learns patterns during training and applies these learned patterns to new inputs at inference time. This approach works exceptionally well for tasks with clear patterns and consistent inputs, such as spam detection, image classification, or recommendation systems. However, the static nature of these models creates significant limitations in dynamic, unpredictable environments.
Traditional ML models require human engineers to define features, select algorithms, and tune hyperparameters. When the data distribution shifts or the task requirements change, the models may degrade in performance and demand retraining. The learning process is essentially frozen after deployment, meaning these systems cannot improve from experience or adapt to novel situations without explicit intervention.
Security and compliance teams commonly use traditional ML for pattern recognition in structured data, but these systems struggle when confronted with tasks requiring contextual understanding or multi-step reasoning. They lack the ability to plan, reason about causality, or decompose complex problems into smaller, manageable sub-tasks.
LLM-Based Agents: Current Capabilities and Constraints
Current LLM-based agents represent a significant advancement over traditional machine learning. Built on large language models with billions of parameters, these systems can understand natural language, generate human-like text, and perform reasoning tasks that were previously impossible for AI. Companies like OpenAI, Anthropic, and Google have developed increasingly capable models that serve as the foundation for many AI applications today.
LLM-based agents excel at natural language understanding and generation. They can engage in meaningful conversations, summarize documents, write code, and explain complex concepts. OpenAI's o1 model, for instance, demonstrates advanced reasoning capabilities that enable it to solve complex problems using logical steps similar to human analysis before answering difficult questions.
However, most current LLM-based agents are fundamentally reactive systems. They respond to user prompts but do not proactively pursue goals or execute actions in the world. When you interact with a chatbot, the system generates a response based on your input and its training data, but it does not independently take steps to accomplish a broader objective without continuous human guidance.
The limitations of LLM-based agents become apparent when tasks require sustained effort across multiple steps, integration with external tools, or adaptation based on feedback. While these models can reason through problems in a single exchange, they often lack the ability to maintain state across interactions, execute actions in external systems, or learn from the outcomes of their decisions.
Key Differences: Self-Learning AI Agents vs Traditional ML
The differences between self-learning AI agents and traditional machine learning models span architecture, capability, and operational philosophy. Understanding these distinctions clarifies why many experts view agents as the next frontier in AI development.
-
Learning and Adaptation
Traditional ML models learn during a fixed training phase and then operate statically. A fraud detection model trained on historical transaction data will apply the same patterns indefinitely unless retrained. Self-learning agents, by contrast, can learn continuously from their interactions with the environment. They observe the outcomes of their actions, analyze what worked and what did not, and modify their strategies accordingly.
-
Autonomy and Goal-Directed Behavior
Traditional ML models are tools that humans use to accomplish specific tasks. They do not pursue goals independently; they simply process inputs and produce outputs according to learned patterns. Self-learning agents are goal-oriented systems that can receive high-level objectives and determine the best course of action to achieve them. They decompose complex goals into sub-tasks, execute those sub-tasks, and adjust their approach based on progress.
-
Tool Use and Environmental Interaction
Self-learning agents can interface with external tools, APIs, and software systems. They can browse the internet, manipulate files, execute code, and interact with databases. Traditional ML models typically cannot do this; they are limited to the inputs they receive and the outputs they generate within their own computation graph.
-
Contextual Understanding and Planning
While traditional ML excels at pattern recognition in structured data, self-learning agents demonstrate superior capabilities in understanding context and planning multi-step solutions. An agent given the objective of planning a trip will research destinations, compare prices, check availability, and book arrangements—behaviors impossible for a static classification model.
Key Differences: Self-Learning AI Agents vs LLM-Based Agents
The distinction between self-learning AI agents and current LLM-based agents is subtle but consequential. Both may use large language models as core components, but their architectures and operational modes differ significantly.
-
Reactive vs Proactive Operation
Most current LLM-based agents are reactive systems that generate responses to prompts. A user asks a question, and the model provides an answer. Self-learning agents, however, can operate proactively. Given an objective, they will take initiative to gather information, make plans, and execute actions without waiting for human input at each step.
-
State Management and Memory
Traditional LLMs treat each conversation as stateless, though some implementations add context windows. Self-learning agents incorporate sophisticated memory systems that maintain information across sessions, track progress toward goals, and enable learning from past experiences. This persistent memory allows agents to build on previous work rather than starting fresh with every interaction.
-
Tool Integration and Action Execution
LLM-based agents primarily generate text, even when that text represents code or commands. Self-learning agents are designed to actually execute those commands and interact with external systems. OpenAI's Operator and Claude's Computer Use represent early steps in this direction, enabling AI to control browsers, command-line interfaces, and software applications.
-
Dynamic Workflow Adaptation
When an LLM-based agent encounters an obstacle, it typically fails or produces an error message. A self-learning agent can recognize when its initial approach is not working, analyze why, and dynamically adjust its strategy. This ability to iterate and adapt is crucial for handling complex, real-world tasks that rarely proceed exactly as planned.
The Architecture of Self-Learning Agents
Understanding what makes self-learning agents different requires examining their underlying architecture. These systems combine multiple components that work together to enable autonomous, adaptive behavior.
-
Planning and Reasoning Engine
At the core of a self-learning agent is a reasoning engine, typically powered by a large language model, that can decompose complex goals into actionable steps. This engine enables the agent to plan, reason about causality, and evaluate the outcomes of potential actions. Microsoft's research indicates that training methods and agent capabilities may create synergistic effects, with improved models enabling more effective agents.
-
Memory Systems
Self-learning agents maintain multiple types of memory: short-term working memory for current tasks, long-term memory for persistent knowledge, and episodic memory for past experiences. These memory systems allow agents to learn from feedback, remember successful strategies, and avoid repeating mistakes. The sophistication of these memory systems distinguishes truly self-learning agents from simpler reactive systems.
-
Tool Use and API Integration
Agents are equipped with the ability to call external tools, access databases, browse the web, and interact with software applications. This tool use capability extends the agent's reach beyond pure text generation into real-world actions. The agent can select appropriate tools based on the task, execute tool calls, and incorporate the results into its reasoning.
-
Feedback and Learning Mechanisms
Perhaps the most distinctive feature of self-learning agents is their ability to learn from experience. When an agent attempts a task, it can evaluate the outcome, identify what went wrong, and modify its approach for future attempts. This learning can occur through various mechanisms, including reinforcement learning, self-reflection, and iterative refinement.
Real-World Applications and Implications
The unique capabilities of self-learning AI agents are enabling new applications across industries. Microsoft reports that nearly 70% of Fortune 500 employees already use Microsoft 365 Copilot agents to handle repetitive daily tasks such as email filtering and meeting note-taking during Teams conferences.
In supply chain management, agents can predict inventory demand changes based on historical data and real-time information, adjusting procurement and production plans to avoid stockouts or overstock situations. In healthcare, agents can analyze patient cases, provide diagnostic suggestions, and assist with treatment planning by processing vast amounts of medical literature and patient records.
The implications extend beyond efficiency gains. Self-learning agents are transforming how knowledge work is performed. Rather than humans learning to use AI tools, the paradigm is shifting toward AI agents that learn to assist humans more effectively. This represents a fundamental change in the human-AI relationship, moving from humans operating tools to humans supervising and collaborating with autonomous agents.
How Can Organizations Prepare for the Agent Era?
Organizations seeking to leverage self-learning AI agents should begin by identifying high-value use cases where agent capabilities can provide significant advantages over traditional approaches. Tasks involving multi-step processes, external system integration, or dynamic environments are prime candidates for agent deployment.
Technical infrastructure must evolve to support agent operation. This includes robust API integrations, secure tool access, and monitoring systems that can track agent performance and detect issues. Organizations should also establish governance frameworks that define appropriate boundaries for agent autonomy while ensuring compliance with relevant regulations.
Investing in agent literacy across the organization becomes essential as these systems become more prevalent. Employees need to understand how agents operate, how to provide effective guidance, and how to evaluate and refine agent outputs. The shift requires not just technical investment but also cultural adaptation.
Conclusion
Self-learning AI agents represent a fundamental advancement in artificial intelligence capabilities. Unlike traditional machine learning models, which are static and task-specific, agents can adapt, plan, and execute complex workflows autonomously. Compared to current LLM-based systems, agents add proactive operation, persistent memory, and the ability to take real-world actions through tool integration.
The transition from reactive AI to autonomous agents marks a paradigm shift comparable to the move from narrow AI to general language understanding. Organizations that understand these differences and prepare accordingly will be best positioned to harness the transformative potential of self-learning agents. The agent era is not approaching—it is already here, reshaping how work gets done and what AI can accomplish.
FAQs
What is the main difference between AI agents and traditional machine learning models?
Traditional ML models learn patterns during training and apply them statically to new inputs, requiring retraining to adapt. Self-learning AI agents can learn continuously from experience, adapt to new situations, and operate autonomously without constant human intervention or retraining.
Can self-learning AI agents replace current LLM-based chatbots?
AI agents and LLMs serve different purposes and are often complementary rather than competitive. LLMs excel at language understanding and generation, while agents add autonomy, action capabilities, and adaptive learning. Many agents actually use LLMs as their reasoning engine while adding layers for planning, memory, and tool use.
Do self-learning AI agents require more computational resources than traditional ML models?
Self-learning agents typically require more computational resources due to their complexity, persistent state management, and often larger underlying models. However, the efficiency gains from autonomous operation and reduced need for human supervision can offset these costs in many applications.
How do self-learning agents handle errors and failures?
Self-learning agents can recognize when their approach is not working, analyze the reasons for failure, and dynamically adjust their strategy. This iterative refinement capability allows them to handle unpredictable situations better than static systems, though robust error handling and human oversight remain important.
Are self-learning AI agents safe for business use?
When properly designed with appropriate guardrails, self-learning agents can be safely deployed in business environments. Organizations should implement clear boundaries for agent autonomy, establish monitoring systems, and maintain human oversight for critical decisions. The key is balancing agent capabilities with appropriate governance frameworks.