









原文著者:David、深潮 TechFlow
1月20日の午後、Xは新バージョンのレコメンドアルゴリズムをオープンソース化しました。
マスクが添えた返信はなかなか興味深いものだった。「我々自身、このアルゴリズムが馬鹿げていることは承知しており、大幅な改良が必要だが、少なくともリアルタイムで改善に取り組んでいる様子が見えるだろう。他のソーシャルメディアはこんなことはできない。」
この言葉は二つの意味があります。一つはアルゴリズムに問題があることを認め、もう一つは「透明性」をアピールポイントにしている。
これはXのアルゴリズムが2度目のオープンソース化です。2023年のバージョンのコードは3年間更新されておらず、すでに実際のシステムとずれがありました。今回のリリースでは完全に書き直されており、コアモデルは従来の機械学習からGrok Transformerへと切り替わっています。公式の説明では「手作業での特徴量エンジニアリングを完全に排除した」とのことです。
以前のアルゴリズムはエンジニアが手動でパラメータを調整していたが、今はAIが直接あなたの履歴を見て、あなたのコンテンツをおすすめするかどうかを判断する。
コンテンツクリエイターにとって、これはもはや「どの時間帯に投稿するのが最も効果的か」「どのタグをつけるとフォロワーが増えやすいか」といった、いわゆる「勘」に頼る方法が通用しなくなることを意味します。
私たちはオープンソースのGitHubリポジトリも確認してみましたが、AIの補助により、コードの中に確かにいくつかのハードロジックが隠されていることがわかりました。それらを掘り下げてみる価値があります。
アルゴリズムの論理の変化:手作業での定義からAIによる自動判断へ
まず新旧のバージョンの違いをはっきりさせておいた方が、後の議論が混乱しにくくなります。
2023年、Twitterがオープンソース化したバージョンは「Heavy Ranker」と呼ばれ、本質的には従来の機械学習です。エンジニアは手動で数百の「特徴量」を定義する必要がありました。たとえば、投稿に画像が含まれているかどうか、投稿者のフォロワー数、投稿時刻から現在までの経過時間、投稿にリンクが含まれているかどうかなどです…
その後、各特徴に重みを設定し、あれこれ調整して、どの組み合わせが最も良い結果を生むか確認する。
今回オープンソース化された新しいバージョンは「Phoenix」と名付けられ、アーキテクチャがまったく異なります。これは、AIの大規模モデルにさらに強く依存したアルゴリズムと考えていただけます。そのコアにはGrokのトランスフォーマー(Transformer)モデルを採用しており、ChatGPTやClaudeと同じ技術体系に属しています。
公式READMEドキュメントには率直に書かれています。「我々はすべての手作業で設計された特徴量を排除しました。」
伝統的な手作業でコンテンツの特徴を抽出するルールは、一つも残さずすべて廃止しました。
では、現在、このアルゴリズムはコンテンツが本当に良いかどうかをどのように判断しているのでしょうか?
答えはあなた次第です。行動シーケンスあなたが以前にいいねした内容、誰に返信したか、どの投稿で2分以上滞在したか、どの種類のアカウントをブロックしたかなどを含め、Phoenix はこれらの行動を Transformer に学習させ、モデル自身がパターンを見つけ出して要約するようにしています。
たとえるなら、古いアルゴリズムは、人間が手作業で作成した点数表のようなもので、各項目にチェックを入れて点数を付ける仕組みです。
新しいアルゴリズムは、あなたのすべての閲覧履歴を見たAIのように感じられます。直接に推測する次に何を見たいですか。
クリエイターにとって、これは二つの意味があります。
第一に、以前のような「ベストな投稿時刻」や「ゴールデンハッシュタグ」などのテクニックの参考価値は低下しています。モデルはもはやこれらの固定された特徴を見ることはなく、各ユーザーの個人的な好みを見て判断しています。
第二に、あなたのコンテンツが広く認知されるかどうかは、ますます「あなたのコンテンツを見て人々がどう反応するか」に依存してきます。この反応は15種類の行動予測として定量化され、次章で詳しく説明します。
アルゴリズムがあなたの15の反応を予測している
Phoenix は、おすすめする投稿を 1 件取得すると、現在のユーザーがそのコンテンツを閲覧した際に起こり得る 15 種類の行動を予測します:
- 前向きな行動いいね、返信、転載、引用転載、投稿をクリック、著者プロフィールページをクリック、動画を半分以上視聴、画像を拡大、共有、一定時間以上閲覧、著者をフォロー
- ネガティブな行動「関心なし」をクリックする、著者をブロックする、著者をミュートする、通報する
各行動にはそれぞれ予測確率が対応しています。たとえば、モデルがこの投稿に60%の確率で「いいね!」をクリックし、5%の確率でこの著者をブロックするなどと判断します。
その後、アルゴリズムは単純な作業を行います。つまり、それぞれの確率を対応する重みで掛けて合計し、総合的なスコアを得るのです。
公式はこうなっています:
最終スコア = Σ(重み × P(行動))
正の行動の重みは正の数であり、負の行動の重みは負の数です。
総合スコアが高い投稿は上位に表示され、低いものは下へ移動する。
要約すると、それはこうである:
今や、コンテンツの質の良し悪しは、コンテンツそのものの完成度(もちろん読みやすさや他者への有用性は広がりの基盤にはなる)によってではなく、むしろ「そのコンテンツにあなたがどのような反応をするか」によって決まるようになりました。アルゴリズムは投稿そのものの質を気にするわけではなく、あなたの行動だけを気にしています。
この考え方によれば、極端な例として、低俗ではあるが誰もが我慢できずに返信やツッコミを入れたくなる投稿は、高品質だが誰も反応しない投稿よりもスコアが高くなる可能性があります。このシステムの基本的なロジックはおそらくこのような仕組みに基づいているのかもしれません。
ただし、新たにオープンソース化されたバージョンのアルゴリズムでは具体的な行動重みの数値は公開されていないが、2023年のバージョンでは公開されていた。
参考(旧バージョン):1回の通報=738回のいいね
次に、2023年のデータを見てみましょう。古いデータではありますが、アルゴリズムがさまざまな行動にどれほどの「価値」を付けるかを理解するのに役立ちます。
2023年4月5日に、XはGitHubで一連の重みデータを公開したことは事実です。
直接に数字を出しましょう:
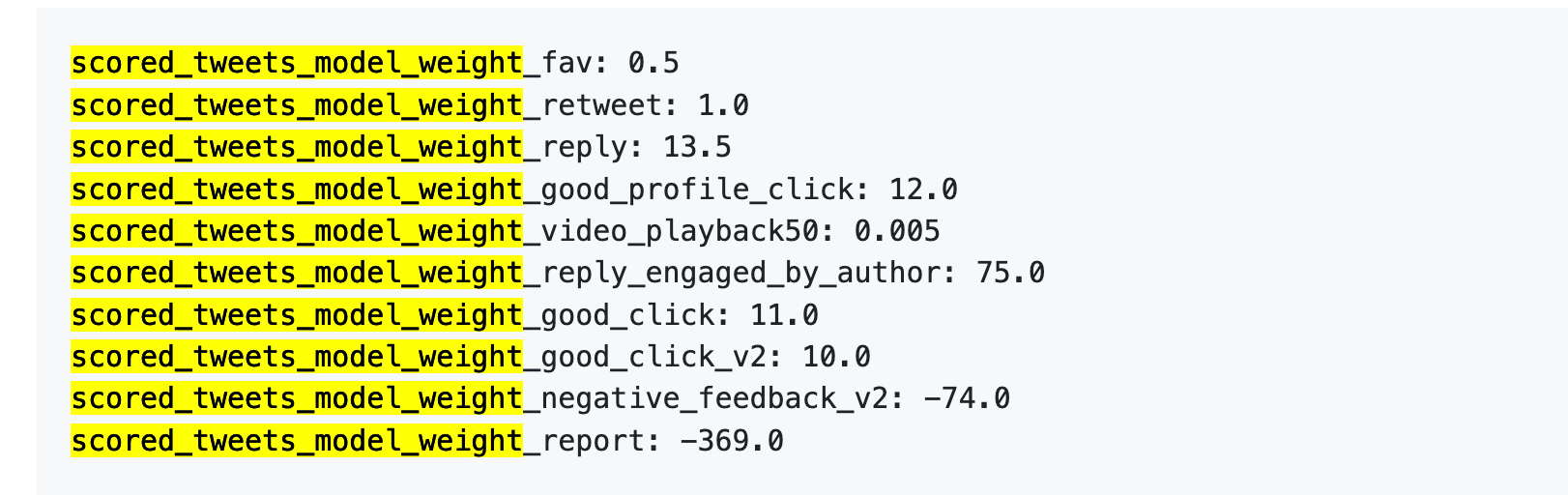
もう少し直訳的に翻訳してください:
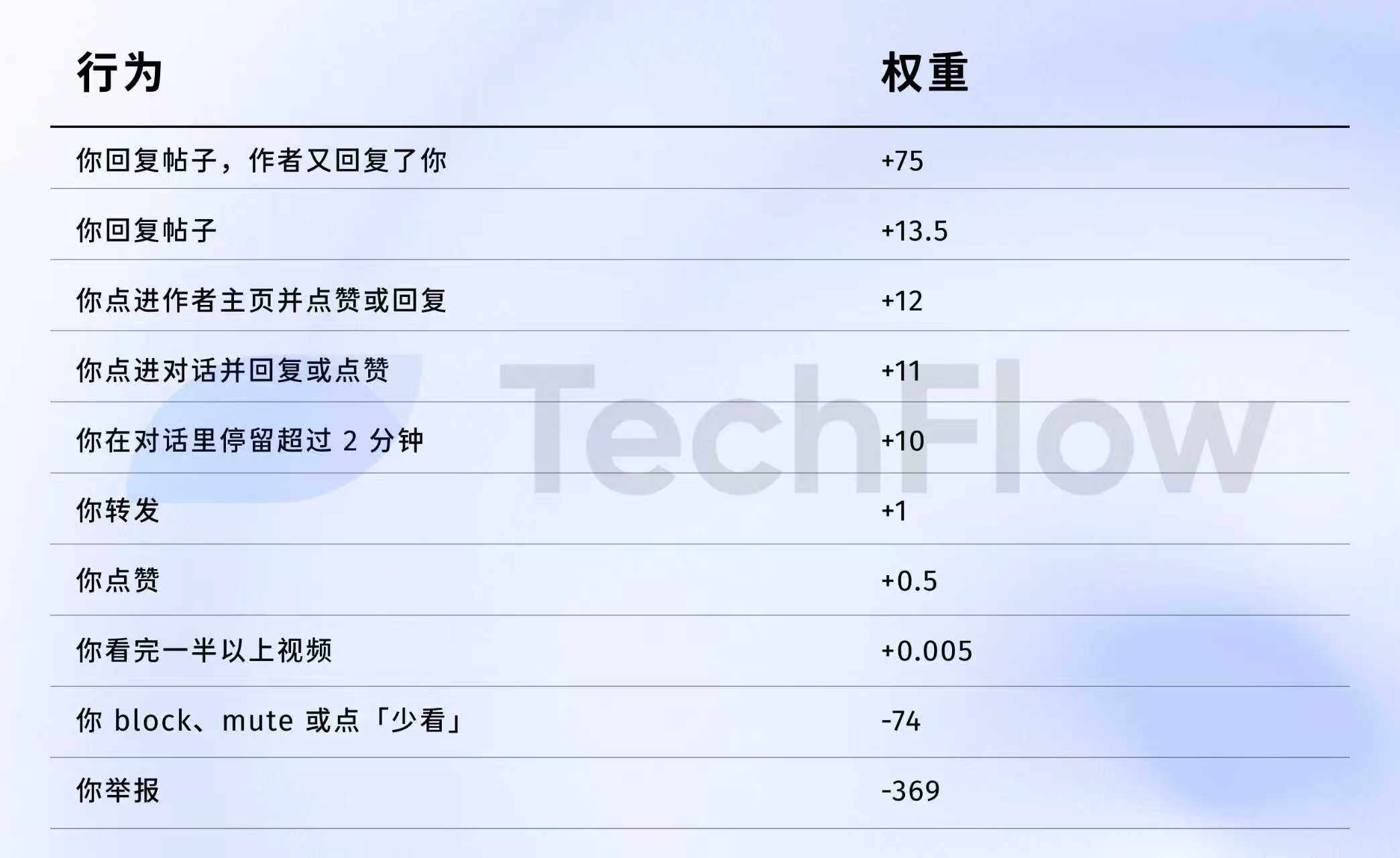
データソース: 旧版 GitHub twitter/the-algorithm-ml リポジトリをクリックして元のアルゴリズムを確認できます。
いくつかの数字に注目する価値があります。
第一に、いいねはほぼ価値がない。 重みは0.5しかないため、すべてのポジティブな行動の中で最も低い値です。アルゴリズムにとっては、いいねの価値はほぼゼロに等しいのです。
第二に、対話と相互作用こそが本物の価値を持つものです。 「あなたが返信し、著者があなたに返信する」ことは重みが75で、いいねの150倍に相当します。アルゴリズムが最も望んでいるのは片方向のいいねではなく、往復の会話です。
第三に、ネガティブなフィードバックは非常に高いコストを伴います。 1 回のブロックまたはミュート(-74)を相殺するには、148 回のいいねが必要です。1 回の通報(-369)を相殺するには、738 回のいいねが必要です。また、これらのマイナス点数はアカウントの信頼度に累積され、その後のすべての投稿の配信に影響を与えます。
第四に、動画の視聴完了率の重みが異常に低すぎる。 たったの 0.005 で、ほぼ無視できるほどです。これは抖音や TikTok と鮮明な対比をなし、後者は視聴完了率を主要な指標としています。
公式ドキュメントで同じファイルについて次のようにも記載されています。「ファイル内の正確な重みはいつでも調整可能です…それ以来、私たちは定期的に重みを調整し、プラットフォームの指標の最適化を図ってきました。」
重みはいつでも調整される可能性があり、実際に調整されたこともある。
新しいバージョンでは具体的な数値は公開されていないが、READMEに書かれた論理フレームワークは同じである:正の点数を加点し、負の点数を減点し、重み付きで合計する。
具体的な数字は変わっていても、オーダーの関係は大概の確率で残っています。他人への返信は、100いいねをもらったよりも有益です。相手にブロックされたくらいなら、反応がまったくないよりもましです。
これらのことを知った上で、私たちクリエイターはどのような行動が取れるでしょうか。
ツイッターの新旧アルゴリズムコードを分析し、それらを総合的に見ることで、いくつか実行可能な結論を導き出しました。
1. コメントを投稿した人への返信を行います。 重み付け表において、「著者がコメントに返信する」は最も高得点(+75)であり、ユーザーによる単方向のいいねの150倍の価値があります。コメントを求めるのではなく、誰かがコメントしたときに返信するだけです。たとえ「ありがとう」とだけ返信しても、アルゴリズムはその点を記録します。
2. 人にスワイプされないようにする。 1回のブロックというネガティブな影響を相殺するには、148回のいいねが必要です。物議を醸すようなコンテンツは確かにインタラクションを引き起こしやすいですが、そのインタラクションが「この人うざい、ブロック」という形であれば、あなたのアカウントの信頼スコアは継続的に損なわれ、その後のすべての投稿の配信に影響を及ぼします。物議を醸す人気は双刃の剣です。他人を切る前に、まず自分自身を切ってみましょう。
3. 外部リンクはコメント欄に掲載してください。アルゴリズムはユーザーを外部に誘導することを好まない。本文中にリンクを含むと評価が下がる。これはMusk自身が公開して述べたことだ。読者を誘導したい場合は、本文に内容を書き、リンクは最初のコメントに貼れ。
4. スクリーンをスクロールさせないでください。 新しいバージョンのコードには「Author Diversity Scorer」という機能があり、同じ投稿者が連続して投稿した場合にその投稿の重みを下げる働きがあります。この機能の目的は、ユーザーのフィードに多様性を持たせることですが、副作用として10回連続で投稿するよりも、1回だけでも質の高い投稿をしたほうが効果的になることがあります。
6. 「最高の投稿時間」はもう存在しない。 以前のアルゴリズムには「投稿日時」という人為的な特徴があったが、新バージョンではいきなり廃止されてしまった。Phoenix はユーザーの行動履歴だけを見て判断し、投稿が何時何分に投稿されたかは一切見ない。そのため、「火曜日の午3時に投稿するのが効果的」といった攻略情報の参考価値は、ますます低下している。
上記はコードレベルで読み取れることです。
X(旧Twitter)の公開ドキュメントには、今回のオープンソース化されたリポジトリには含まれていない、加点・減点の要素もいくつかあります。例えば、青色のチェックマーク(ブルーチェック)があると加点され、すべて大文字で書かれたツイートは評価が下がり、センシティブな内容が含まれると80%の到達率が削減されるなどのルールがあります。これらのルールはオープンソース化されていないため、ここでは詳しくは説明しません。
総合的に見ると、今回のオープンソースはかなり実質的だった。
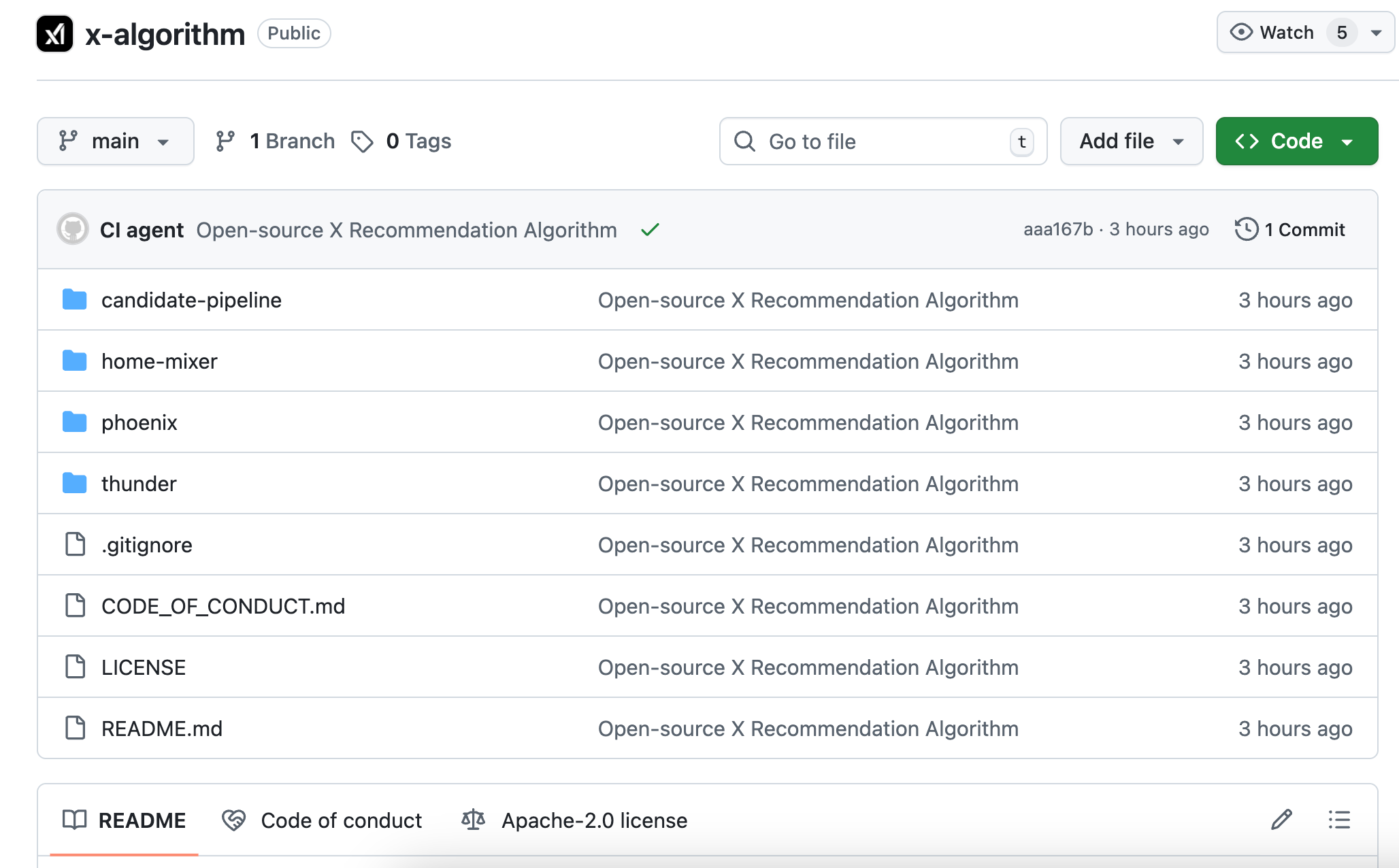
完全なシステムアーキテクチャ、候補コンテンツのリコールロジック、順位付けとスコアリングのプロセス、さまざまなフィルタの実装。コードは主に Rust と Python で構成されており、構造が明確で、README の詳細さは多くの商用プロジェクトよりも優れている。
しかし、いくつかの重要なものが公開されていません。
1. 重みパラメータが公開されていません。 コードには「ポジティブな行動には加点し、ネガティブな行動には減点する」とだけ書かれており、具体的にはいいねが何ポイント加算されるのか、ブロックが何ポイント減点されるのかについては記載されていません。2023年のバージョンでは少なくとも数値が明示されていたのですが、今回はただの式の枠組みだけが提示されています。
2. モデルの重みが公開されていません。 Phoenix は Grok transformer を使用していますが、モデル自体のパラメータは公開されていません。そのため、モデルがどのように呼び出されているかは確認できますが、モデル内部でどのように計算されているかは見えません。
3. トレーニングデータが公開されていない。 モデルがどのようなデータで訓練されたのか、ユーザーの行動データはどのようにサンプリングされたのか、ポジティブサンプルとネガティブサンプルはどのように構築されたのか、すべて記載されていません。
たとえるなら、今回のオープンソースは、「我々は加重平均で総合点を計算しています」とは教えてくれるが、重みの値は教えてくれないようなものだ。また、「我々はトランスフォーマーを使って行動確率を予測しています」とは教えてくれるが、そのトランスフォーマーの中身までは教えてくれない。
横並びで比較すると、TikTokやInstagramはこのような情報を公開したこともない。X社が今度オープンにした情報量は、確かに他の主要プラットフォームよりも多い。しかし、「完全な透明性」まではまだ距離がある。
オープンソースが価値がないわけではない。作曲家や研究者にとって、コードが見えることは見えないよりも常に有利である。