









著者:ティナ、ドンメイInfoQ
1. 3年近くの時を経て、マスク氏が再びXのレコメンデーションアルゴリズムをオープンソース化
さきほど、XのエンジニアリングチームはX上で投稿し、Xのレコメンデーションアルゴリズムを正式にオープンソース化することを発表しました。このオープンソースライブラリには、「あなたにおすすめ」のフィードをサポートするコアのレコメンデーションシステムが含まれており、ネットワーク内コンテンツ(ユーザーがフォローしているアカウントからのコンテンツ)とネットワーク外コンテンツ(機械学習に基づく検索を通じて発見されるコンテンツ)を組み合わせ、すべてのコンテンツをGrokベースのTransformerモデルを用いてランク付けします。つまり、このアルゴリズムはGrokと同じTransformerアーキテクチャを採用しています。
オープンソースのアドレス: https://x.com/XEng/status/2013471689087086804
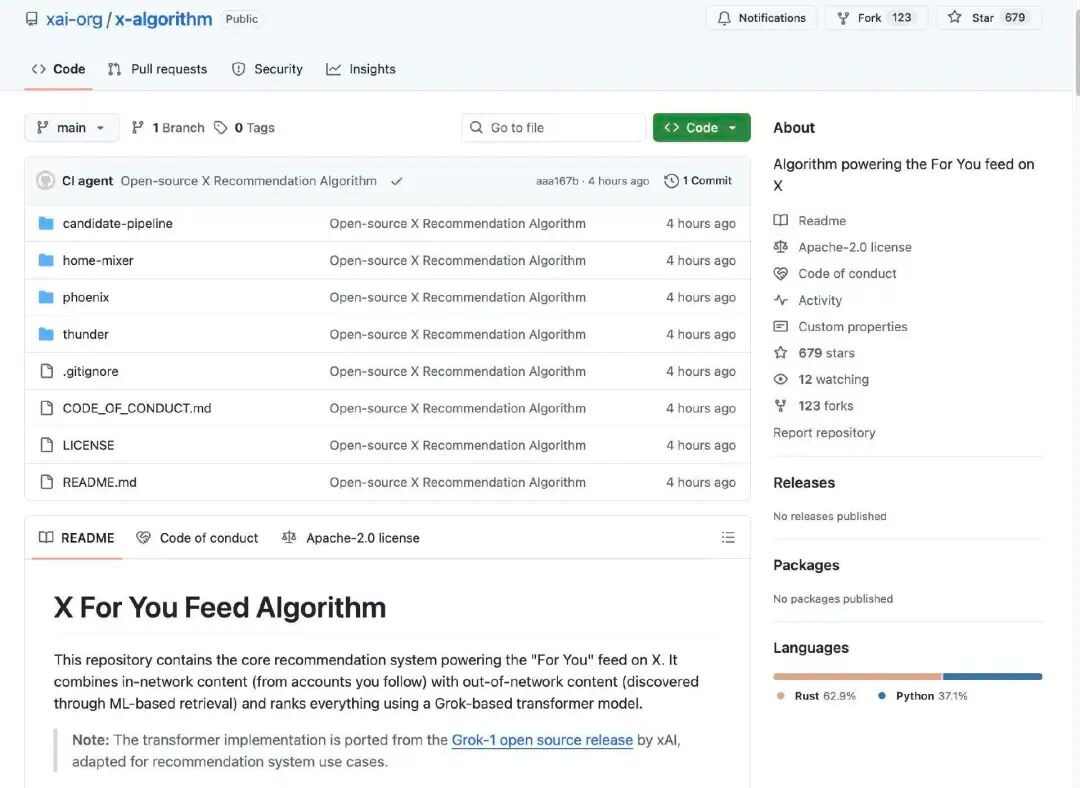
Xのレコメンデーションアルゴリズムは、ユーザーがホーム画面で見るコンテンツを生成する責任を担っています。「あなたにおすすめ」(For Youフィード)コンテンツそれは主に2つのソースから候補投稿を取得します:
フォローしているアカウント(In-Network / Thunder)
プラットフォームで発見された他の投稿(ネットワーク外 / Phoenix)
これらの候補コンテンツはその後、統一的に処理され、フィルタリングされ、関連性順に並べ替えられます。
では、アルゴリズムのコアアーキテクチャと動作ロジックはどのようなものでしょうか?
アルゴリズムは、最初に候補コンテンツを2種類のソースから収集します:
フォロー内のコンテンツ:あなたが積極的にフォローしているアカウントから投稿された記事。
非注目コンテンツ:システムがコンテンツライブラリ全体から検索して、あなたが関心を持つかもしれない投稿。
この段階の目的は「関連性のある可能性のある投稿を特定すること」です。
システムは自動的に低品質、重複、違反、または不適切なコンテンツを削除します。たとえば:
ブロックされたアカウントのコンテンツ
ユーザーが明確に興味を示していないトピック
違法、古くなった、または無効な投稿
これにより、最終的な並べ替えの際に価値のある候補コンテンツのみが処理されるよう保証されます。
この度オープンソース化されたアルゴリズムの核心は、システムがGrokベースのTransformerモデル(大規模言語モデル/深層学習ネットワークに類似)を用いて、各候補投稿に対してスコアを付ける点にあります。このTransformerモデルは、ユーザーの過去の行動(いいね、返信、リツイート、クリックなど)に基づき、それぞれの行動が起こる確率を予測します。最後に、これらの行動確率を重み付きで組み合わせ、包括的なスコアを算出します。スコアが高い投稿ほど、ユーザーに推薦される可能性が高くなります。
この設計は、従来の手作業による特徴量抽出というアプローチをほぼ廃止し、代わりにエンドツーエンドの学習方式を用いてユーザーの関心を予測するものである。
これは、マスク氏がXの推薦アルゴリズムをオープンソース化した初めての試みではありません。
2023年3月31日、マスク氏はTwitterの買収時に約束したとおり、ユーザーのタイムラインにツイートを推薦するアルゴリズムを含むTwitterの一部ソースコードを正式にオープンソース化しました。オープンソース化された当日、このプロジェクトはGitHubで10,000以上のスターを獲得しました。
当時、マスク氏はTwitterで、今回の発表について次のように述べました。「多くのレコメンデーションアルゴリズムは」他のアルゴリズムについても順次公開していく予定です。彼はまた、「独立した第三者が、Twitterがユーザーに表示する可能性のあるコンテンツを合理的な精度で特定できるようになることを望んでいる」と述べました。
スペースのアルゴリズム公開に関する議論の中で、彼は今回のオープンソース計画について、「ツイッターをインターネット上でもっとも透明性の高いシステムにすること」を目的とし、最も有名で成功したオープンソースプロジェクトの1つであるLinuxのように頑健なシステムにすることを目指していると語りました。「最終的な目標は、ツイッターを引き続き利用し続けるユーザーが、ここでの体験を最大限に楽しむことができることです。」
マスク氏がXアルゴリズムを最初にオープンソース化してから、もう3年近くが経過しました。テクノロジー界隈のスーパーキーパーソンであるマスク氏は、今回のオープンソース化について、十分な宣伝活動を事前に済ませていました。
1月11日、マスク氏はX(旧Twitter)で投稿し、7日以内に新しいXアルゴリズム(ユーザーにどの自然検索コンテンツや広告をおすすめするかを決定するすべてのコードを含む)をオープンソース化すると発表しました。
このプロセスは4週間に1度繰り返され、ユーザーが変更内容を把握しやすくするために、詳細な開発者向けの説明書が添付されます。
今日はまた、彼の約束が果たされた。
2. マスク氏はなぜオープンソースにしたのか?
イーロン・マスクが再び「オープンソース」を言及すると、外部の第一反応は技術的理想主義ではなく、現実的なプレッシャーである。
昨年を通じて、Xはコンテンツ配信メカニズムに関する議論を繰り返し巻き起こしました。このプラットフォームは、アルゴリズムの面で右翼的な見解を偏愛し、それを助長していると広く批判されており、この傾向は単発的な事例ではなく、システム的に根付いていると見なされています。昨年に発表された調査報告書では、Xのレコメンデーションシステムが政治的内容の拡散において、明らかに新たなバイアスを示していることが指摘されています。
同時に、いくつかの極端な事例がさらに外部の疑問を強めている。昨年、米国の右翼活動家チャールズ・コーケが襲撃されたという未検証の動画がXプラットフォームで急速に拡散され、世論を揺るがす事態となった。批判者は、これはプラットフォームの審査メカニズムの失敗を明らかにしただけでなく、「何を拡散させ、何を拡散させないか」にかかわるアルゴリズムの問題を再び浮き彫りにしたと指摘している。 潜在的権力。
このような背景のもとで、マスク氏が突然アルゴリズムの透明性を強調したことは、単なる技術的決定として単純に解釈することは難しい。

3. ネットユーザーの意見は?
Xのレコメンドアルゴリズムがオープンソース化された後、Xプラットフォームではユーザーがレコメンドアルゴリズムのメカニズムについて以下の5つのポイントをまとめました。
- あなたのコメントに返信します。アルゴリズムでは、「返信+著者による返信」の重み付けはいいねの75倍です。コメントに返信しないと、露出率に大きな影響を及ぼします。
- リンクは露出率を低下させますリンクはプロフィールまたはピン留められた投稿に掲載してください。絶対に投稿本文内に載せないでください。
- 視聴時間は非常に重要です。彼らがスワイプして見過ごしてしまえば、彼らの注意は引けません。動画や投稿が多くの注目を集めるのは、ユーザーのスクロールを止める効果があるからです。
- 自分の専門分野をしっかり守れ「シミュレーションクラスター」は現実に存在しています。もしもあなたの専門分野(暗号通貨、テクノロジーなど)から外れてしまうと、一切の流通チャネルを得ることができなくなります。
- スクリーン / 黙秘はあなたのスコアを大幅に下げる論争を巻き起こすが、不快感を与えることはない。
要するに:ターゲット層とコミュニケーションを取り、関係を築き、ユーザーがアプリ内に留まるようにする。実はとても簡単です。
また、ネット上では、アーキテクチャはオープンソースであるにもかかわらず、まだ一部の内容がオープンソースになっていないことに気づいたユーザーもいます。そのユーザーは、今回のリリースは本質的にフレームワークであり、エンジンは含まれていないと指摘しました。具体的には、何が欠けているのでしょうか?
重みパラメータが不足しています - コード確認では「ポジティブな行動に対する加点」および「ネガティブな行動に対する減点」が確認されているが、2023年版とは異なり、具体的な数値は削除されている。
モデルの重みを隠す - モデルそのものの内部パラメータや計算は含まれていません。
非公開のトレーニングデータ - トレーニングモデルに使用されるデータや、ユーザー行動のサンプリング方法、また「良い」サンプルと「悪い」サンプルの構築方法について、私たちは何も知りません。
一般的Xユーザーにとって、Xのアルゴリズムがオープンソース化されても大きな影響は感じられないかもしれない。しかし、より高い透明性により、なぜある投稿が注目されるのか、また他の投稿は無視されるのかを説明する助けとなり、研究者たちがプラットフォームがコンテンツをどのように順位付けているのかを研究できるようになる。
4. なぜレコメンデーションシステムは必争の地なのでしょうか?
ほとんどの技術的な議論において、レコメンデーションシステム多くの場合、バックエンドエンジニアリングの一部として、控えめで複雑でありながらも、スポットライトの当たる存在とは見なされにくいものです。しかし、本当にインターネット大手企業のビジネス運営を分解してみれば、レコメンデーションシステムが周辺的なモジュールではなく、ビジネスモデル全体を支える「インフラストラクチャレベルの存在」であることに気づくでしょう。このようにして、インターネット業界における「沈黙の巨獣」と呼ばれるにふさわしい存在なのです。
公開されたデータは繰り返し、この点を裏付けています。アマゾンは、自社プラットフォームにおける約35%の購入がレコメンデーションシステムから直接生じていることを明らかにしていました。ネットフリックスはさらに極端で、視聴時間の約80%がレコメンデーションアルゴリズムによって駆動しているとされています。ユーチューブの状況も同様で、視聴時間の約70%がレコメンデーションシステム、特にフィード(情報流)から来ているとされています。メタ(Meta)については明確な割合は発表されていませんが、内部技術チームは、社内でのコンピューティングクラスタの約80%の計算リソースがレコメンデーション関連のタスクに使われていると述べています。
これらの数字は何を意味していますか?これらの製品からレコメンデーションシステムを取り除くことは、ほぼ基礎を抜き去ることと同じである。たとえばMetaの場合、広告配信、ユーザーの滞在時間、商業的な変換(コンバージョン)などは、ほぼすべてレコメンデーションシステムに依存しています。レコメンデーションシステムは、ユーザーが「何を見せるか」だけでなく、プラットフォームが「どのように収益を得るか」を直接的に決定するのです。
しかし、こうした生死を分けるシステムこそが、長期間にわたり非常に高い工学的複雑さに直面し続けてきた。
従来のレコメンデーションシステムアーキテクチャでは、すべてのシーンを統一されたモデルでカバーすることは困難です。現実世界のプロダクションシステムは、多くの場合非常にフラグメント化されています。例えば、Meta、LinkedIn、Netflixなどの企業では、完全なレコメンデーションパイプラインの裏には、通常30個以上に及ぶ専用モデルが同時に稼働しています。これは、リコメンデーションモデル、粗フィルタリングモデル、精緻フィルタリングモデル、再並べ替えモデルなど、それぞれが異なる目的関数やビジネス指標を最適化するために設計されたものです。各モデルの裏には、多くの場合1つまたは複数のチームが特徴量エンジニアリング、トレーニング、ハイパーパラメータ調整、本番環境への導入、および継続的なイテレーションを担当しています。
このアプローチのコストは明らかです。それは、エンジニアリングが複雑で、メンテナンスコストが高く、タスク間の連携が困難になります。もし誰かが「1つのモデルで複数のレコメンデーション問題を解決できないか」と提案したとすれば、それはシステム全体の複雑さを桁違いに低減することを意味します。これは業界が長年求めてきたが実現が難しかった目標です。
大規模言語モデルの登場により、レコメンデーションシステムに新たな可能性が開かれた。
LLM(大規模言語モデル)はすでに実践で、極めて強力な汎用モデルであることを証明しています。それは、異なるタスク間での転移学習能力が高く、データ量や計算リソースが拡大するにつれて性能が継続的に向上するからです。一方で、従来のレコメンデーションモデルは多くの場合「タスク専用型」であり、複数のシーン間で能力を共有することが困難です。
さらに重要なのは、単一の大規模モデルがもたらすのは、エンジニアリングの簡略化にとどまらず、「クロス学習(交差学習)」の可能性も含まれているということです。同じモデルが複数のレコメンデーションタスクを同時に処理する際、異なるタスク間のシグナルがお互いに補完し合うため、データ規模が拡大するにつれてモデル全体の進化がより容易になります。これはレコメンデーションシステムが長年求めていたが、従来の手法では実現が難しかった特性です。
LLM(大規模言語モデル)は何かを変えましたか? 実際には、特徴量エンジニアリングから理解能力へのプロセスを変化させました。
方法論の観点から見ると、LLM がレコメンデーションシステムに最も大きな変化をもたらしたのは、「特徴量エンジニアリング」という中心的な段階です。
従来のレコメンデーションシステムでは、エンジニアはまず、多くのシグナルを人工的に構築する必要があります。たとえば、ユーザーのクリック履歴や滞在時間、類似ユーザーの嗜好、コンテンツのタグなどです。その後、明確にモデルに「これらの特徴をもとに判断してください」と指示します。モデル自体はこれらのシグナルの意味を理解せず、単に数値空間でのマッピング関係を学習しているだけです。
言語モデルが導入されたことで、このプロセスは高度に抽象化されました。もはや、「このシグナルは見るが、あのシグナルは無視する」といったルールを1つ1つ指定する必要はなくなりました。代わりに、モデルに対して直接問題そのものを説明するだけで済みます。たとえば、「これはユーザーであり、これはコンテンツです。このユーザーは過去に類似のコンテンツを好んでいますし、他のユーザーたちもこのコンテンツに対してポジティブなフィードバックをしています。では、今このコンテンツをこのユーザーに推薦すべきかどうかを判断してください」といった具合です。
言語モデル自体はすでに理解能力を持っており、どの情報が重要なシグナルであるかを自ら判断し、それらのシグナルをどのように統合して意思決定を行うかを判断できます。ある意味で、それは単に推奨のルールを実行するだけでなく、「推薦することそのものを理解」しているのです。
この能力の源泉は、LLMがトレーニング段階で膨大で多様なデータに触れており、微細だが重要なパターンをより容易に捉えられることにあります。これに対して、従来のレコメンデーションシステムは、エンジニアがこれらのパターンを明示的に列挙する必要があり、見落とされたパターンについてはモデルが認識することができません。
バックエンドの視点から見れば、このような変化は決して新鮮なものではありません。あなたがGPTに質問を投げかけると、文脈に基づいて回答を生成するのと同じように、「このコンテンツに私は関心を持つだろうか」と尋ねられても、既存の情報に基づいて判断を行うことができます。ある意味で、言語モデル自体はもともと「おすすめ」する能力を備えているのです。