










このシーンを想像してみてください:
AIエージェントにコードのバグを直してもらいました。エージェントはプロジェクトを開き、20のファイルを読み込み、修正してテストを実行しましたが、失敗。再度修正し、テストを実行しましたが、まだ失敗……十数回繰り返しても、結局直せませんでした。
あなたはコンピューターを電源オフにし、安心した。そしてAPIの請求書が届いた。
上の数字を見て、息をのむかもしれない——AIエージェントが海外公式API上でバグを自力で修正する際、1回の未修正タスクで百万トークン以上が消費され、費用は数十ドルから100ドル以上に達することもある。
2026年4月、スタンフォード大学、MIT、ミシガン大学などが共同で発表した研究論文が、AIエージェントのコードタスクにおける「消費のブラックボックス」を初めて体系的に解明した——資金はどこに使われ、その価値はあったのか、事前に予測できるのか。その答えは驚異的だった。
発見1:エージェントがコードを書く際のコストは、通常のAI会話の1000倍である
皆さんは、AIにコードを書かせるのと、AIとコードについて話すのでは、かかる費用はほぼ同じだと感じるかもしれません。
論文による比較表示:
Agentic タスクのトークン消費量は、通常のコード質問およびコード推論タスクの約1000倍です。
整整三个数量级の差があります。
なぜこうなるのでしょうか?論文は、お金が「コードを書く」ことに使われるのではなく、「コードを読む」ことに使われるという事実を指摘しています。
ここで言う「読む」は、人がコードを読むことを意味するのではなく、Agentが作業中にプロジェクト全体のコンテキスト、履歴操作記録、エラーメッセージ、ファイル内容などを一括してモデルに「与える」ことを指します。対話が1回増えるたびに、このコンテキストも1回分長くなります。そしてモデルはトークン数に基づいて課金されるため、与える量が増えれば増えるほど、支払う額も増えます。
たとえば、修理工を呼んで、レンチを一つ動かすたびに、その建物全体の図面を最初から読み上げなければならないようなものだ——図面を読む費用は、ネジを締める費用よりもはるかに高い。
論文はこの現象を次の一文で要約している:エージェントのコストを駆動しているのは、出力トークンではなく、入力トークンの指数的増加である。
発見2:同じバグを2回実行すると、コストが2倍になることがある——そして、価格が高いバグほど不安定である
さらに厄介なのはランダム性です。
研究者は同じエージェントを同じタスクで4回実行し、結果は以下の通りでした:
- 異なるタスク間で、最もコストの高いタスクは最も安価なタスクよりも約700万トークンを多く消費します(図2a)
- 同じモデル、同じタスクの複数回の実行において、最も高価な回は最も安価な回の約2倍です(図2b)
- また、異なるモデル間で同じタスクを比較すると、最大消費量と最小消費量の差は最大で30倍になります。
特に注目すべきは最後の数字です。これは、正しいモデルを選んだ場合と間違ったモデルを選んだ場合のコスト差が「少し高い」だけでなく、「1桁異なる」ことを意味します。
より心を刺すのは——多く使うことが、必ずしも良く行っていることを意味しないということだ。
論文は「逆U字型」の曲線を発見しました:
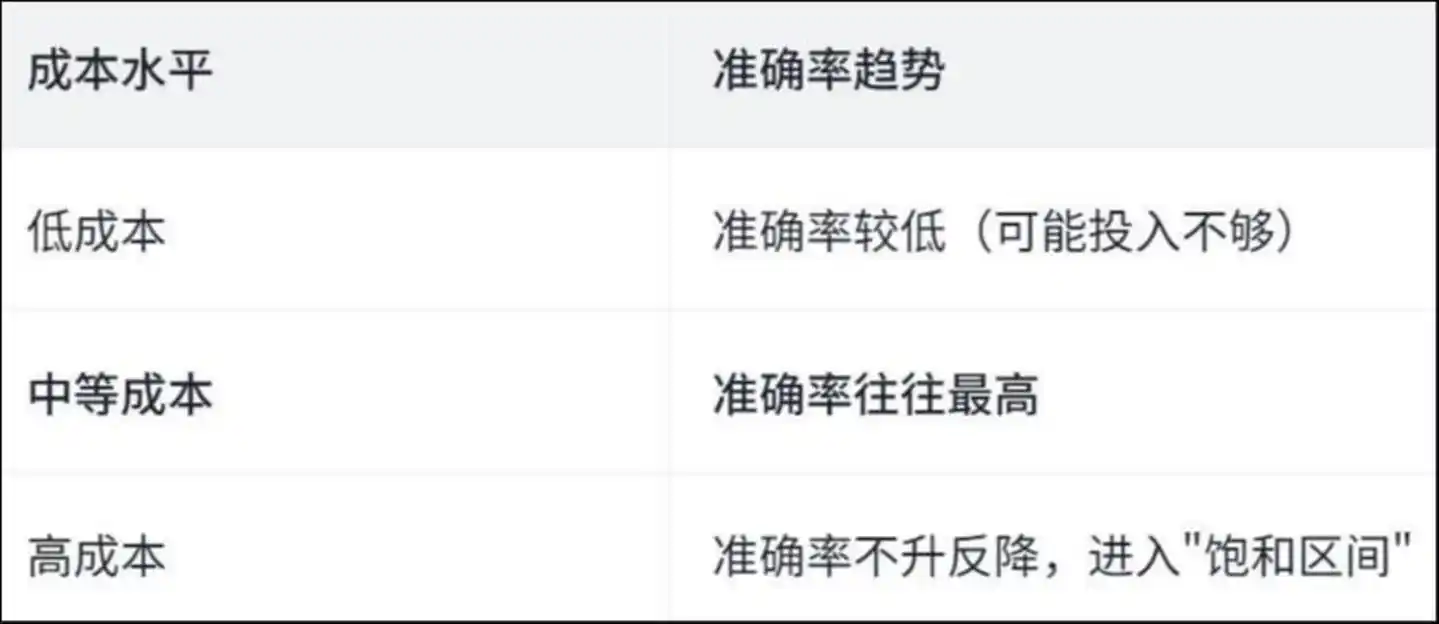
コストレベルの精度トレンド:低コストでは精度が低い(投入が不足している可能性)中コストでは通常最も高い精度を達成高コストでは精度が逆に低下し、「飽和領域」に入る
なぜこのようなことが起こるのでしょうか?論文は、エージェントの具体的な操作を分析することで答えを示しています——
高コストの運用において、エージェントは「繰り返し作業」に多くの時間を費やしています。
研究によると、高コストの実行では、約50%のファイル参照およびファイル変更操作が重複している——つまり、エージェントが同じファイルを繰り返し読み、同じ行のコードを繰り返し変更しており、まるで部屋の中でぐるぐる回る人のように、回れば回るほど混乱し、混乱すればするほどさらに回る状態である。
お金は問題解決に使われず、迷子になることに使われた。
発見3:モデル間の「効率比」に大きな差が——GPT-5が最も省エネ、一部のモデルは150万トークンも余分に消費
論文は、業界標準のSWE-bench Verified(500の実際のGitHub Issue)を用いて、8つの最先端の大規模モデルのエージェント性能を評価しました。ドルに換算すると、トークン効率の高いモデルは1タスクあたり数十ドルの差が出ます。企業レベルのアプリケーションでは、1日に数百タスクを実行するため、この差は実際の資金となります。
より興味深い発見は、トークン効率がタスクによるものではなく、モデルの「本質的な特性」であるということです。
研究者は、すべてのモデルが成功したタスク(230個)とすべてのモデルが失敗したタスク(100個)をそれぞれ抽出して比較したところ、モデルの相対的なランキングはほとんど変化しなかった。
これは、一部のモデルが元々「話が多い」ことを示しており、タスクの難易度とはそれほど関係がないことを意味します。
さらに深く考えさせられる発見として、モデルには「損切意識」が欠けていることです。
すべてのモデルが解決できない困難なタスクに直面した際、理想的なエージェントは、無駄なコストを削減するために早期に諦めるべきである。しかし現実には、モデルは失敗したタスクに対してより多くのトークンを消費してしまう——それらは「敗北を認める」ことなく、継続的に探索し、再試行し、コンテキストを再読み込みする。まるで燃料警告灯のない車が、故障するまで走り続けるように。
発見4:人間にとって難しいことは、エージェントにとって必ずしも高価ではない——難易度の認識が完全にずれている
あなたはおそらく考えるだろう:では、少なくともタスクの難易度に応じてコストを予測できるはずだよね?
論文では、人間の専門家に500のタスクの難易度を評価させ、その後、エージェントの実際のトークン消費量と比較した——
結果:両者には弱い相関しかありません。
人間にとってはとても難しいタスクでも、エージェントは簡単に低コストでこなせることがある。一方、人間にとっては簡単なタスクでも、エージェントにとっては途方もないコストがかかることがある。
これは、人間とAIが「見る」難易度が根本的に異なるからです:
- 人が見るもの:論理的複雑さ、アルゴリズムの難易度、ビジネス理解のハードル
- エージェントが見ているのは:プロジェクトの規模、読み込むファイルの数、探索パスの長さ、同じファイルを繰り返し修正するかどうか
人間の専門家が「1行変更すれば済む」と考えるバグに対して、エージェントはその1行を特定するため、まずコードベース全体の構造を理解しなければならない——その「読み取り」だけで大量のトークンを消費する。一方、人間が「ロジックが複雑だ」と感じるアルゴリズムの問題に対して、エージェントはむしろ標準的な解法を知っているため、あっという間に解決してしまう。
その結果、開発者は直感的にエージェントの実行コストを予測することがほぼ不可能になります。
発見5:モデル自身でさえ、自分がどれだけの費用をかけるのかを正確に計算できない
人間が予測できないなら、AIに自分で予測させればいいのか?
研究者は洗練された実験を設計した:エージェントが実際にバグを修正する前に、コードベースを「検査」し、どのくらいのトークンを消費するかを予測するが、実際の修正は行わない。
結果はいかがですか?
すべてのモデルが敗北した。
最高の成績は、Claude Sonnet-4.5 の出力トークン予測相関性で、0.39(満点1.0)。多くのモデルの予測相関性は0.05~0.34の範囲にとどまり、Gemini-3-Proは最低の0.04で、ほぼランダムな推測と同程度である。
さらに驚異的なのは、すべてのモデルが自らのトークン消費量を系統的に過小評価していることである。図11の散布図では、ほぼすべてのデータポイントが「完璧な予測線」の下方に位置しており、モデルは「これほど消費しない」と考えているが、実際にはより多くのトークンを消費している。また、例を提供しない場合、この過小評価のバイアスはさらに顕著になる。
さらに皮肉なことに——予測自体にもお金がかかる。
Claude Sonnet-3.7 および Sonnet-4 の予測コストは、タスク自体のコストの2倍以上にもなる。つまり、それらにまず「見積もりを立ててもらう」ほうが、直接作業させるよりも高い。
論文の結論は明確である:
現在、最先端のモデルは自らのトークン使用量を正確に予測できません。「Agentを実行」をクリックすることは、盲盒を開けるようなもの——請求書が出てきて初めていくら使ったかわかります。
この「あいまいな帳簿」の背後には、より大きな業界の問題が隠されている
ここまで読んだあなたは、これらの発見が企業に何を意味するのかと疑問に思うかもしれません。
「月額サブスクリプション」の価格モデルは、エージェントによって亀裂が生じている
論文は、ChatGPT Plusのようなサブスクリプションモデルが成り立つのは、通常の会話におけるトークン消費が比較的制御可能で予測可能だからであると指摘している。しかし、エージェントタスクはこの前提を完全に覆す——エージェントがループに陥ると、1つのタスクで膨大なトークンを消費する可能性がある。
これは、エージェントシナリオにおいて単なるサブスクリプション価格設定が持続可能ではない可能性を意味し、今後も長期間にわたり、使用量に応じた課金(ペイアズユーゴー)が最も現実的な選択肢であるということです。しかし、使用量に応じた課金の課題は——使用量そのものが予測不可能であることです。
2. トークン効率はモデル選択の「第3の指標」になるべきである
従来、企業はモデルを選択する際に、能力(実行できるか)と速度(実行が速いか)の2つの観点を重視してきた。この論文は、第3の同等に重要な観点、すなわち効率(どれだけのコストで実行できるか)を提示している。
能力はやや劣るが、効率が3倍高いモデルは、スケーリングシナリオにおいて「最も強力だが最もコストが高い」モデルよりも経済的価値が高い可能性がある。
3. アジェントは「ガソリンメーター」と「ブレーキ」が必要です
論文では、注目すべき将来の方向性として、予算認識型ツール使用ポリシー(Budget-aware tool-use policies)が挙げられている。簡単に言えば、エージェントに「ガソリンメーター」を装備し、トークン消費が予算に近づいた時点で無駄な探索を強制的に停止させ、予算を全消費するまで続けるのを防ぐことである。
現在、ほとんどの主要なAgentフレームワークにはこのメカニズムが欠けています。
エージェントの「資金消費問題」はバグではなく、業界が経験する避けられない苦痛である
この論文が明らかにしたのは、あるモデルの欠陥ではなく、AIが「一問一答」から「自律的計画、複数ステップ実行、繰り返しデバッグ」へ進化する際に、トークン消費の予測不可能性がほぼ必然であるという、エージェントパラダイム全体の構造的課題である。
良いニュースは、これが初めて誰かがこの混乱した帳簿を体系的に整理して計算したということです。このデータにより、開発者はモデルの選択、予算設定、損切メカニズムの設計をより賢明に行えるようになります。また、モデル提供企業にとっても、より強力にするだけでなく、より効率的にするという新たな最適化の方向性が生まれました。
結局のところ、AIエージェントがあらゆる産業の本番環境に本格的に導入される前には、きれいなコードを書くことよりも、1円ずつお金をどのように使うかがより重要である。(本記事は钛媒体APPで初公開、著者 | サンフランシスコTech news、編集 | 趙虹宇)
注:本記事は、2026年4月24日にarXivに掲載された予印本論文『How Do AI Agents Spend Your Money? Analyzing and Predicting Token Consumption in Agentic Coding Tasks』(Bai、Huang、Wang、Sun、Mihalcea、Brynjolfsson、Pentland、Pei)に基づいて作成されています。著者はバージニア大学、スタンフォード大学、MIT、ミシガン大学など所属しています。この研究はまだ査読を経ていません。