
OpenClawのリアルワールドエージェントタスクで、どの大規模モデルが本当に最強なのか知りたいですか?
MyTokenは、評価サイトに基づいて、AIコーディングエージェントの実際の能力に焦点を当てた透明なベンチマークを構築しました。これは成功率という1つの核心的指標のみを評価対象としています(速度とコストは他の独立した指標であり、後ほど別途分析します)。完全に公開され、再現可能で、厳密な評価基準と最新の成功率Top 10ランキングのみを掲載しています。
一、評価項目:成功率
具体的基準:AIエージェントが与えられたタスクを完全かつ正確に完了した割合。各タスクは高度に標準化されたプロセスを採用しています:
正確なユーザー・プロンプト
スマートエージェントに送信して、リアルなユーザー要求シナリオをシミュレートする
期待される動作
受け入れ可能な実装方法と重要な意思決定ポイントを説明します
評価基準(チェックリスト)
個別に検証可能な原子化された成功判定リストを表示する
二、三种の評価方法
今回の評価は主に3つの評価方法を採用しています。
自動チェック:Pythonスクリプトがファイルコンテンツ、実行ログ、ツール呼び出しなどの客観的結果を直接検証
LLM大モデル裁判:Claude Opusが詳細なスケールに基づいて評点(コンテンツ品質、適切性、完全性など)を付与
ハイブリッドモード:自動化された客観的チェック + LLMによる定性的評価の組み合わせ
すべてのタスク定義、Prompt、スコアリングロジックを公開し、再テストと検証を可能にします。
三、評価用タスク
今回のベンチマークは、23の異なるカテゴリのタスクをカバーしています。基本的なインタラクション、ファイル/コード操作、コンテンツ作成、研究分析、システムツールの呼び出し、メモリの永続化など、複数の観点を網羅し、開発者がOpenClawを日常的に使用するシナリオに非常に近い形で構成されています。
セーニティチェック(自動化)——簡単な指示を処理し、挨拶に正しく返信する
カレンダーイベント作成(自動化)——自然言語から標準ICSカレンダーファイルを生成
株価リサーチ(自動化)——リアルタイムで株価を照会し、フォーマットされたレポートを出力
Blog Post Writing(LLM裁判)——約500字の構造化されたMarkdownブログ記事
天気スクリプト作成(自動化)——エラーハンドリング付きPython天気APIスクリプトの作成
ドキュメント要約(LLM裁判)——3段階の精緻な要約で核心テーマを抽出
Tech Conference Research(LLM裁判)——5つの実際のテクノロジー会議の情報(名称、日付、場所、リンク)を調査・整理
プロフェッショナルなメール作成(LLM裁判)——丁寧に会議を断り、代替案を提案する
コンテキストからのメモリ検索(自動化)—— プロジェクトノートから日付、メンバー、技術スタックなどを正確に抽出
ファイル構造の作成(自動化)——標準的なプロジェクトディレクトリ、README、.gitignoreを自動生成
マルチステップAPIワークフロー(ハイブリッド)——設定の読み取り → 呼び出しスクリプトの作成 → 完全なドキュメンテーション
ClawdHubスキル(自動化)をインストール——スキルリポジトリからインストールして有効性を確認
検索してインストールするスキル(自動化)——天気関連のスキルを検索し、正しくインストールする
AI画像生成(混合)——説明に基づいて画像を生成して保存
AI生成ブログを人間らしく修正(LLM裁判)——機械的な文章を自然な口語に変える
每日研究摘要(LLM裁判)——複数のドキュメントを統合した一貫した日次要約
メールインボックスのトリアージ(混合)——複数のメールを分析し、緊急度に基づいて報告を整理
メール検索と要約(混合)——アーカイブされたメールを検索し、重要な情報を抽出
競合市場調査(ハイブリッド)——企業APM分野の競合分析
CSVおよびExcelの要約(混合)——テーブルファイルを分析してインサイトを出力
ELI5 PDF要約(LLM裁判)——5歳の子でもわかる言葉で技術PDFを説明
OpenClawレポート理解(自動化)——研究レポートPDFから特定の質問に正確に回答
Second Brain Knowledge Persistence(混合)——セッションをまたいで情報を保存し、正確に想起
四、核心結論:成功率上位10の大モデルランキング(最高%/平均%)
データは2026年4月7日まで更新されています
最高%は単回の最高成功率、平均%は複数回の平均成功率であり、安定性をよりよく反映します。
以下が成功率が最も高い上位10のモデルです
anthropic/claude-opus-4.6(Anthropic)——93.3% / 82.0%
arcee-ai/trinity-large-thinking(Arcee AI)——91.9% / 91.9%
openai/gpt-5.4(OpenAI)——90.5% / 81.7%
qwen/qwen3.5-27b(Qwen)——90.0% / 78.5%
minimax/minimax-m2.7(MiniMax)——89.8% / 83.2%
anthropic/claude-haiku-4.5(Anthropic)——89.5% / 78.1%
qwen/qwen3.5-397b-a17b(Qwen)——89.1% / 80.4%
xiaomi/mimo-v2-flash(Xiaomi)——88.8% / 70.2%
qwen/qwen3.6-plus-preview(Qwen)——88.6% / 84.0%
nvidia/nemotron-3-super-120b-a12b(NVIDIA)——88.6% / 75.5%
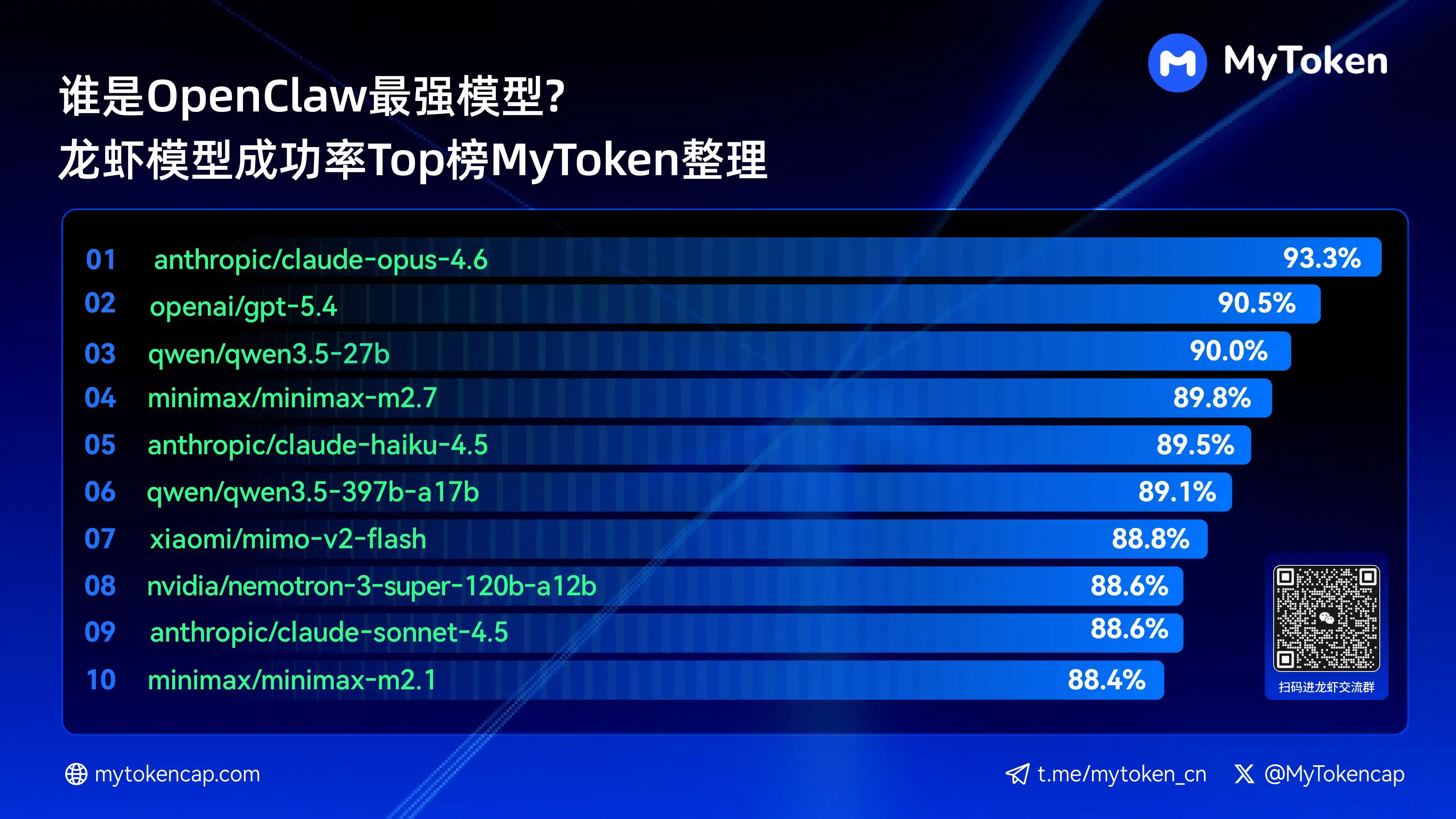
Claude Opus 4.6は現在93.3%の最高成功率でリードしていますが、ArceeのTrinityは平均安定性で目立っており、Qwenシリーズも複数モデルがトップ10にランクインし、非常に高いコストパフォーマンスの可能性を示しています。成功率は基本的な基準ですが、今後は速度とコストの観点が実際の体験にさらに影響を与えることになります。
この23タスクベンチマークは完全に透明であり、各自のシナリオに合わせて実際にテストすることを強く推奨します。その他のモデルランキングについては、MyTokenが間もなくリリースするエージェントランキング機能をお楽しみにお待ちください。
(データはPinchBenchが公開したOpenClawエージェントベンチマークに基づいており、継続的に更新中です。)