










著者: 一直在路上的Max 、01Founder
OpenAIの2025年を段階的にまとめると、多くの人が退屈で、あるいはやや受動的だと評価するだろう。
過去1年以上にわたり、彼らは論理的推論のパスを着実に実現し、o3proからo4miniまでの推論モデルを次々とリリースし、GPT-4.5やGPT-5といった新しいベースモデルも導入しました。
しかし、一般ユーザーが最も感じ取りやすく、自発的な拡散が起きやすい視覚生成分野では、彼らの存在感が次第に薄れていっている。
Soraの登場当初の衝撃の後、OpenAIはこの分野で長い沈黙期に入ったようだ。
一方、テーブルの他のプレイヤーたちは何もしていなかった。
オープンソースエコシステムでは、Fluxのようなモデルが高品質なローカル画像生成の障壁を完全に取り除いた。
ビジネス側では、古い競合が極限の審美基準を築いており、さらに Nano-banana のようなネット検索機能を備えた新興勢力も登場しています。
一方で、OpenAIの過去の主力画像生成モデルGPT-Image-1.5はすでに古びて見えます:
画質が悪く、レイアウトが硬直しており、複雑なテキストには頻繁にクラッシュします。
次第に、業界内に一種のコンセンサスが形成された。
OpenAIは視覚生成分野で技術的ボトルネックに直面し、さまざまな競合に囲まれ、もはや対応が困難になっています。
数週間前まで、転換点は非常に隠された形で現れた。
有名な大規模モデルのブラインドテストプラットフォームLM Arenaに、コード名「Duct Tape」の謎の画像モデルが静かに混入しました。
盲検に参加したユーザーはすぐに異常なことに気づいた:
このモデルは極端なアスペクト比の制御が非常に正確であり、多数の多言語テキストを含むレイアウトポスターを完璧に生成できます。画像出力の前には、まるで隠された論理的計画プロセスが存在するかのようです。
一時、さまざまな技術コミュニティで、これはどの企業がこっそりとリリースした強力な手なのかと推測が広がったが、OpenAI側は一貫して沈黙を守った。
今日の夜明け、やっと靴が落ちた。
長々とした発表会や広範なマーケティングキャンペーンはなく、OpenAIはこのコード名「テープ」のモデルを正式にChatGPT GPT-Image-2と名付け、市場に全面的に投入した。
同時に発表されたのは、やや息苦しい印象を与えるText-to-Image競技場ランキングです。
GPT-Image-2は1512の非常に高いスコアで即座に1位にランクインし、2位(ネット検索機能付きのNano-banana-2)を242ポイント上回りました。
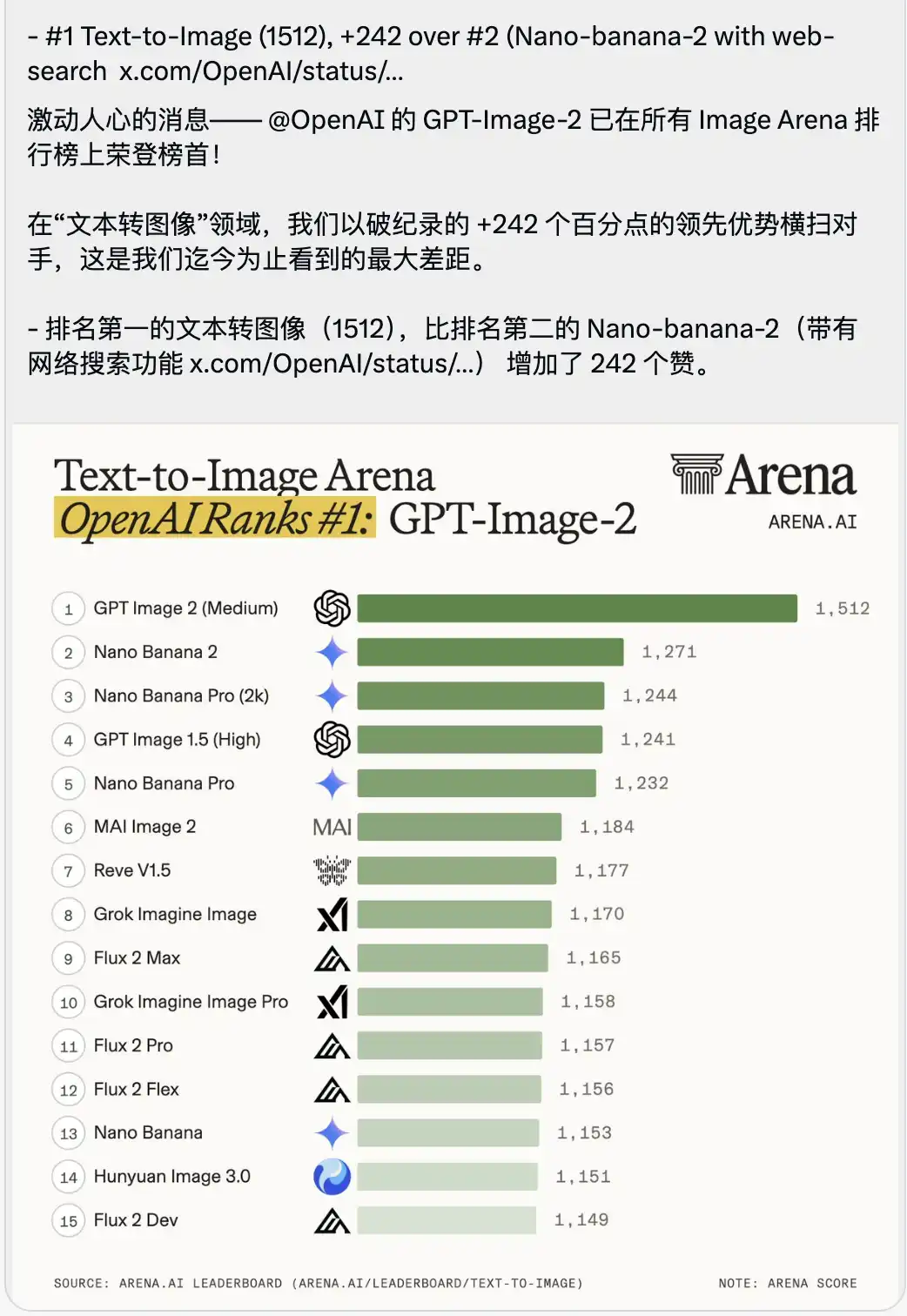
大規模モデルのベンチマークの文脈では、人々は通常、0.1や一桁の差を大きく取り上げ、トップモデル間のスコアは非常に僅差で競い合っています。
242点のリード差は、アリーナの歴史上かつてないことです。
これは微小なバージョンアップではなく、圧倒的な世代差による圧倒です。
私は半日以上を費やして、その各種限界機能と最新のAPIドキュメントを丁寧に確認しました。
最も大きな感想は一つだけです:
OpenAIはそのままのOpenAIです。
それが失地を回復すると決断したとき、その方法は古い牌桌をひっくり返すことだった。
このモデルの前で、私たちがまだ2〜3年はかかると思っていた視覚デザインの仕事は、今日ほぼ終わりを告げたと言える。
PART.01 画像生成:モデルから視覚エージェントへ
GPT-Image-2 がこれほど大きなスコア差を生み出せる理由を理解するには、従来のテキスト生成画像モデルに対する固定観念を捨て去る必要があります。
以前、AIで絵を描くことは、本質的にブラインドボックスを引くようなもので、いくつかのプロンプトを入力して、ピクセルが思い通りに並ぶのを待つだけでした。
しかし、GPT-Image-2はビジュアルエンジンを内蔵したエージェントのようなものです。
最も顕著な変化は、そのメカニズムが二つの完全に異なるモードを直接分離したことです。
一つはすべてのユーザーに開放されているインスタントモード(Instant Mode)です。
このモードは、極速の応答とライフワークフローとのシームレスな統合を特徴としています。
たとえば、携帯電話で指示を送ると、数秒以内に構造が整った図を提供します。
その基盤となる視覚理解能力は非常に優れていますが、主に高頻度で単発の視覚変換要件を解決します。
有料ユーザー向けの思考モード(Thinking Mode)。
それが実際に1ピクセルもレンダリングする前に、十数秒にわたる論理的推論とオンライン検索を経ます。
正是このパターンが、極めて核心的かつ極めて困難な課題を解決しました:
モデルは初めて、自分が何を描くべきかを理解した。
最も直観的な例を挙げましょう。
チャットボックスに入力してください:
ダクトテープという神秘的なモデルについて、オンラインで人々の評価を調べて、チャットGPTのQRコードを添えてポスターを作成してください。

以前のモデルでは、ネットユーザーが何を言っているのか全く理解できず、乱码の偽文字が書かれたポスターを描くだけで、QRコードもスキャンできない偽の画像でした。
しかし、思考モードでは、そのワークフローは次のようになります:
まず描画を一時停止し、オンライン検索ツールを起動して、Reddit、Threads、またはLinkedIn上でユーザーの本物の評価を収集します。
その後、ポスターのレイアウト、余白、フォントの階層を設計し始めました;
最後に、実際に使用可能で、スキャンして直接移動できるQRコードを生成し、全体の画像をレンダリングします。

これはもはや絵を描くことではなく、調査から企画、文案抽出、レイアウト設計までを自ら一貫して行う作業です。
ここで並行比較を行う必要があります。
大規模モデルのコミュニティでは、インターネット接続と検索機能を備えた画像生成モデルはOpenAIが最初ではないことが知られています。
ランキング2位のNano-bananaはすでにこのメカニズムを備えていました。
しかし、Nano-bananaを実際に使用すると、多くの場所でやや不器用であることに気づくでしょう。
Nano-bananaの思考はしばしば機械的な組み合わせ論理である。
たとえば、業界のトレンドを調べてポスターを作るように指示しても、実際に検索はするものの、通常はウィキペディアの文をそのまま無理やり切り取って、画面上に無理に貼り付けてしまう。
抽象的なビジネス要件を解釈する必要が生じた場合、すぐに混乱してしまう。

それは、言葉は理解できるが、全くの経験のないインターンのように、実行はできるが戦略をまったく理解していない感じだ。
しかし、GPT-Image-2 はこの点でのパフォーマンスは、比喩的に言えば極めて優れています。
その思考は形だけのものではなく、背後にある文化的情報と商業的意図を真正に理解したものである。
テスト中に極めて簡潔な中国語の指示を入力しました:マスクが抖音で豆包を販売するライブ配信のスクリーンショットを描いてください。
以前の画像生成モデルを使えば、おそらく白人の人物でマスクに似た外見をした人が、包子を手に持ち、背景はぼやけており、抖音がどのようなものかさえ知らない姿を描くでしょう。
思考モードでは、GPT-Image-2 が生成する結果が少し驚かされます。
それは単に要素を単純に組み合わせるのではなく、中国のインターネットに対する理解を自ら活用して、ピクセルレベルで再現された抖音ライブストリームUIのスクリーンショットを生成した。
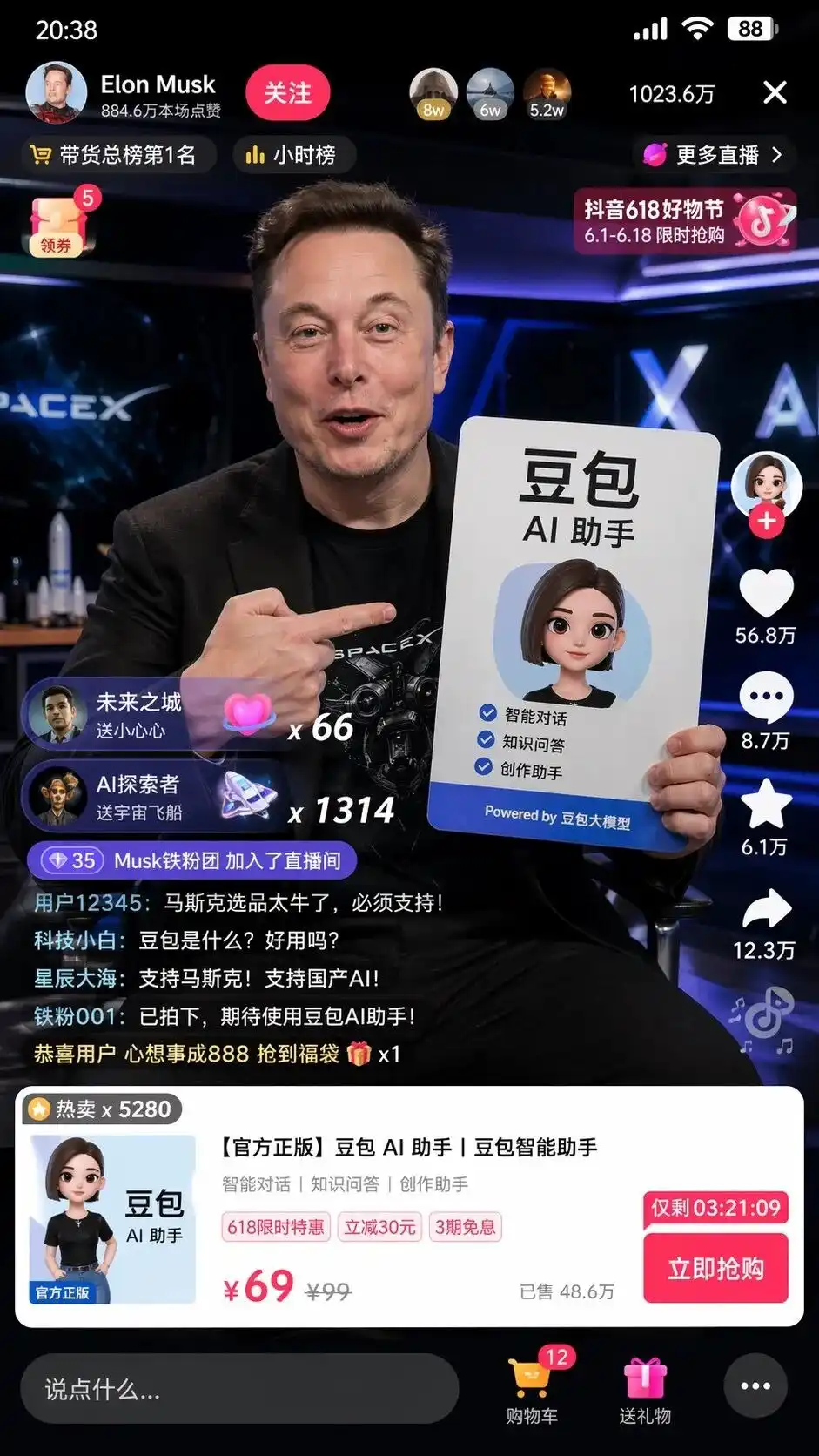
画面には、完璧にレイアウトされた豆包AIアシスタントの広告ボードを掲げるリアルなマスクが描かれているだけでなく、プロンプトに含まれていなかったより恐ろしい細部まで存在している:
左上角のフォローボタンと時間別ランキング、右上角のオンライン人数1023.6万、底部にポップアップされる標準商品カード、そして横線価格99、特別価格69、カウントダウン付きの即購入ボタンが示されています。
左下角に流れる、非常にリアルなユーザーのコメントが最も恐ろしい。
テクノロジー初心者:豆包とは何ですか?使いやすいですか?
星の海:マスクを支持!国産AIを支持!
誰もそのコメント欄に何を書くべきか、商品UIをどのようにするべきか、価格をどう定めるべきかを教えたことはない。
これは、抖音の商品販売とDouBao大モデルという二つのタグを分析した後、人間の代わりに補完され実行された完全なビジネスUI設計および運営プランです。
大規模モデルによる画像生成の評価基準は、今や単に美しく描けるかどうかから、戦略やレイアウトの論理を理解しているかへと移行した。
PART.02 実測コア能力
その限界を試すため、私はビジネスデザインの基準に従い、いくつかの高頻度で複雑なシナリオを試しました。
結果、それが問題を解決する粒度は、恐ろしいほど細かかった。
最初のシナリオ:視覚理解とビジネスのサイクル(モデルに服を着せる)
従来のeコマースのビジュアルやファッションプランニングでは、アイデアから実際に着用した効果を見るまでにかかる実行コストは非常に高いです。
モデルを探し、衣装を借り、スタジオを設営し、後期処理で精緻に仕上げる。
その後、AIが登場し、人々は人物の顔の形状を固定するためにLoRAモデルを訓練し始めたが、それでも数十枚の画像素材と高い学習コストが必要だった。
GPT-Image-2では、このプロセスが極限まで圧縮されています。
私は自分の日常のセルフィーをアップロードし、来月海岛のバケーションに行くことを伝えて、いくつかの服装を提案してもらいました。
それはまず、8セットの全く異なるスタイルの夏服図鑑を私に提示し、レイアウトはプロフェッショナルなEC Lookbookのようであり、各アイテムの横には正しいテキストラベルが付いていた。
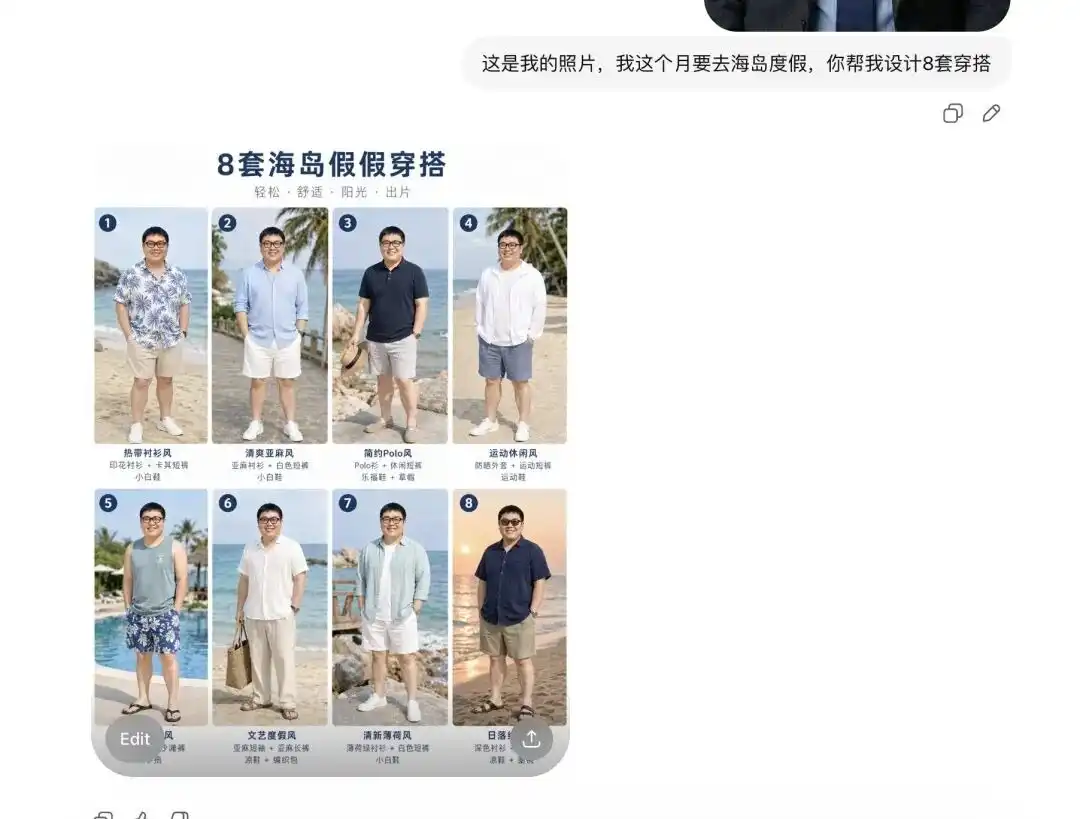
より重要なのは、その瞬間にすでに私の顔の特徴と体の比率を正確に解析していたことです。
私が「最初のセットを着たときの効果を見せてください。複数の角度からの詳細画像もお願いします」と言うと、それは私のセルフィーから人物を抽出して夏服に着替えさせ、側面や半身など異なる視点の画像を生成しました。

この転換は非常にスムーズです。これは、初心者向けの服装コーディネートのレンダリングや、モデルによる試着を外部委託する作業の競争優位性が完全に失われたことを意味します。
二番目のシナリオ:一貫性と連続的な物語の解決(1文で漫画を生成)
AI画像を作成したことがある人は皆知っているが、AIに美しい画像を1枚描かせることは難しくない。難しいのは、同じ人物を10枚描かせ、その動作と視点を連続させることだ。
これがいわゆる一貫性(Consistency)の課題です。
しかし今回の実測では、過去の経験に大きく反する事例を見ました。
昨日友達との写真を一枚アップロードし、非常にシンプルなプロンプトを入力してください。
私たち二人を主人公にして、三ページの日本風漫画を三枚描いて、ストーリーはあなたが決めてください
数秒後、それは標準的なセリフ付きの白黒漫画を3ページ出力した。
最も恐ろしいのは、この二人の実在人物から生成された漫画キャラクターが、三ページの異なるカットに登場している点である。

近景のクローズアップ、遠景での走行、背中姿、さらには顔の特徴、髪型の細部、衣装のしわまで、すべて完璧に一貫性を保っています。
さらに驚くべきことに、漫画のストーリーは完全に一貫しており、会話ボックス内のテキストさえも完全な物語の論理を構成している。

時間と空間の一貫性を実現できることは、これが単一画像生成の範疇を越え、連続的な物語を演出する能力を備えていることを示している。
サードシナリオ:文字レンダリングの最後の障壁を越える(多言語レイアウト)
一貫性がナラティブの問題を解決するのであれば、多言語テキストの正確なレンダリングが、真正面からグラフィックデザイナーを追い詰める。
以前、画像に少しでも文字が含まれると、大規模モデルは意味のない筆跡を書き始めました。
モデルが理解する文字はトークン(意味の塊)であり、生成される画像はピクセル点であるため、これまでこれらは分離されていました。
GPT-Image-2 はこの問題を完全に解決しました。
フランス語のファッション雑誌の表紙を生成し、満載のひらがなと漢字を含む日本のレストランのメニューを作成し、さらにロシア語の注釈を極めて高密度にレイアウトしてみた。

結果は一発成型で、スペルミスゼロです。
最も絶望的なのは、それが文字を正しく書くだけでなく、言語に応じて現地の文化美意識やフォントデザインに合わせられるということです。
例えば、日本語のチラシにある漢字は、非常に地道な日本のレトロな美術字体を使用しており、ひらがなの配置も日本語の縦書き読書習慣に合っています。
レイアウト設計はかつてグラフィックデザイナーの専売特許だった。
字間隔の調整、主従の分け方、文字と背景の視覚的バランスの取り方には、多くの練習が必要です。
しかし、AIがこれほど多くの言語をゼロエラーで処理でき、高度なレイアウトの美的感覚を備えているなら、日常的なポスター、パンフレット、フィード広告を手動でガイドラインを合わせる必要はもはやない。
第4のシーン:歪んだアスペクト比と極端なマイクロコントロール(米粒への刻印)
最後に、その従順さがどれほど恐ろしいかを確認するために、私はいくつか非常に難解な指示を与えました。
私はまずその極端なアスペクト比をテストしました。
従来の拡散モデルは、非標準のアスペクト比を非常に苦手としています。
以前、画像を少し縦に伸ばすと、画面に二つの頭が現れていました。
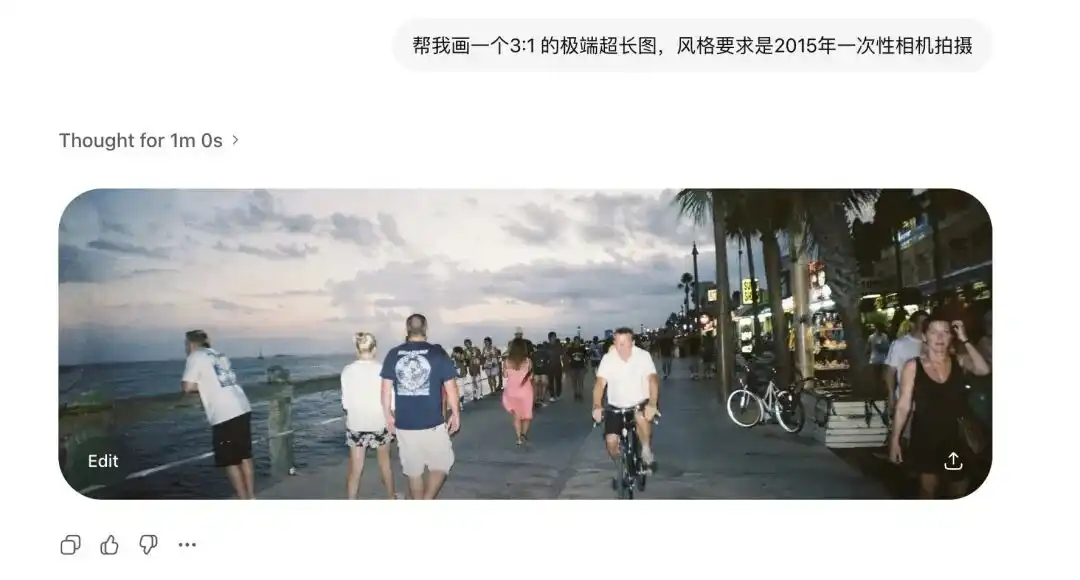
しかし、私はImages 2.0に3:1の超広角画像と1:3の縦長画像を生成するよう要求しました。それだけでなく、画像は崩れることなく、首尾繋がり論理的に閉じた360度パノラマ画像を生成しました。
2015年のワンタイムカメラで撮影されたエントリを追加することで、古くなったレンズの歪みやフラッシュが壁に当たって生じる粗い反射まで鮮明に再現されています。
そして、その微細な制御力をよりよく示しているのは、公式が発表会で提示したやや異常な米粒テストです。
研究者は現在ベータテスト中の実験的な4K APIを呼び出し、マクロ撮影や8K超高精細などの修飾語を一切使用せず、ただ一つの非常に抽象的なシンプルな指示を出しました:
一山の米。その一粒の米に「GPT Image 2」と書かれている。
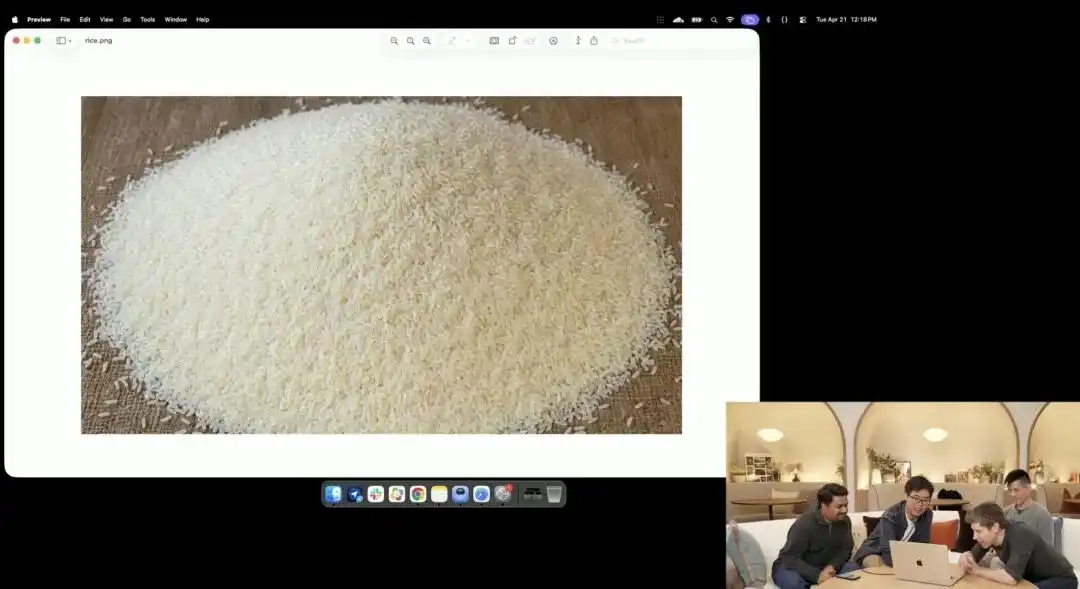
画面がスクリーン上で数十倍に拡大され、ピクセルの粒が見えるようになったとき、あなたは本当に米の山から刻まれた微細な粒を見つけることができるでしょうか。
この米の質感は依然として物理法則に従っており、文字は米粒の微細な弧に正確に沿って表面に埋め込まれている。
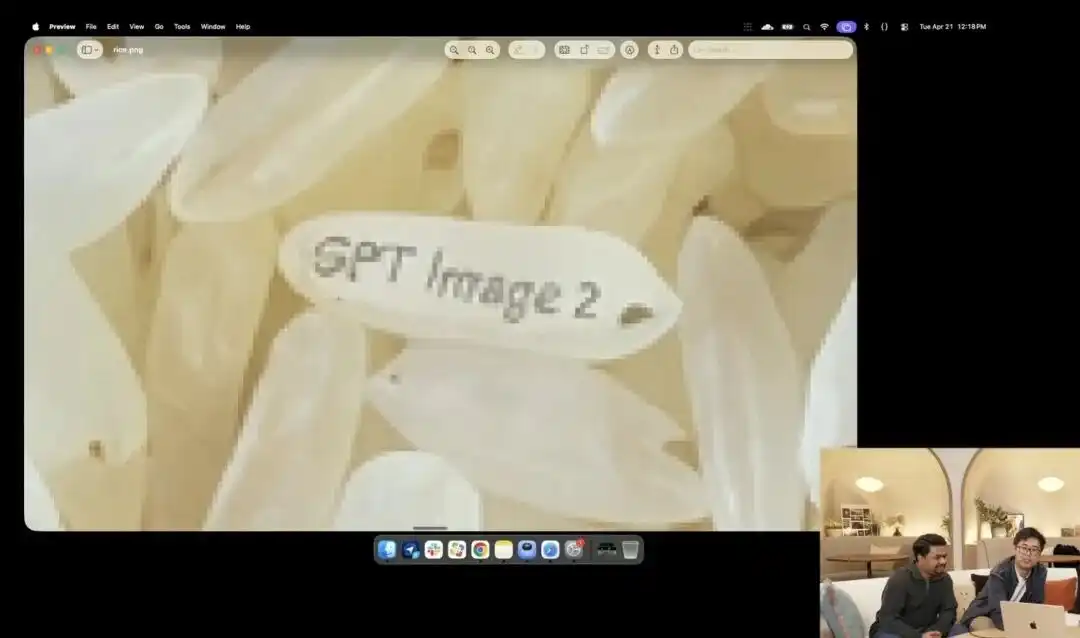
残りのすべての作業——マクロ視点の呼び出し、被写界深度の計算、潜在空間内でその一粒の米の物理的座標を探し出し、文字を印刷する——は、大規模モデルが思考モードで自動的に補完して完了しました。
この事例は、モデルが空間位置をピクセルレベルの手術刀のような精度で理解していることを直観的に示しています。
これは、今後、実際の作業でデザイン案の小さな部分を正確に修正でき、どこを指してもその部分だけを変更できるということを意味します。以前のように、襟を変更しようとした際に、画像全体が変わってしまうようなことはなくなります。
PART.03 いくつかの技術的詳細
このような極端な制御力と戦略的インテリジェンスは、単に計算力を無差別に積み上げただけでは実現できません。
GPT-Image-2の本質を理解するために、いくつかのプロービングテストを実施しました。
非常に興味深い点が見つかりました。
公式ドキュメントではGPT-Image-2の全体的な知識ベースの最終更新日が2025年12月とされていますが、私の実際のテストでは。
インスタントモードのトレーニングデータの最終日は、2024年5月末のままです;

そして、長考が必要な思考モード(Thinking Mode)のネイティブ知識ベースは、おおむね2024年6月までにとどまっています(ただし、リアルタイムでのインターネット接続により現在の正確な日付を取得できます)。

この二つの時間点から推測すると、GPT-Image-2の基盤には何かしらの手がかりが見られるようだ。
まず、高頻度で画像を出力するリアルタイムモードをご案内します。
2024年5月の期限は、それがo4-miniを直接適用したか、GPT-5ファミリーの軽量バージョン(GPT-5 miniや、さらに小さなGPT-5 nano)であることを示唆している。
正是因为这批轻量化基座已经具备了极强的空间规划和听懂复杂指令的能力,上层的图像生成才能稳住阵脚不乱套。
そして、その極めて賢く、ビジネス戦略を理解する思考パターンの基盤は、GPT-5メインモデルではあり得ない。
GPT-5の基礎知識ベースの最終更新日は2024年9月です。
思考モードは、バックグラウンドで継続的に更新されるOシリーズ推論モデル(例:o4、または更新版のo3)にほぼ確実に接続されています。
大規模モデルはまず、Oシリーズ特有の長考メカニズムを用いて、潜空間内でビジネスロジック、ターゲット心理、レイアウト座標をすべて明確に計算した後、ビジュアルモジュールに最終的なピクセルレンダリングを委ねます。
もちろん、別の可能性のある道もあります:
OpenAIの内部で極めて精緻な計算リソースの割り当てメカニズムにより、高速モードでは最低限の性能を保証するためにGPT-5 nanoが直接使用され、思考モードではやや大型のGPT-5 miniと外部ツールが組み合わされます。
しかし、どのベースコンビネーションであっても、OpenAIのAPIエコシステムを継続的に注視していると、その基本的な生成ロジックはもはやMidjourneyとは完全に次元が異なることがわかります。
パート04 ユーザーが最も関心を持つ価格設定
しかし、ベースを推測するよりも、それをワークフローに実際に統合しようとする開発者や企業にとって、より注目すべきは、非常に現実的で直感に反するAPIの価格表である。
以前のDALL-E 3は1枚あたり料金が設定されていました(例:1枚0.04ドル)。
しかし、最初の GPT-Image-1 から、OpenAI はそれをトークン単位の課金フレームワークに完全に変更しました。
今回のGPT-Image-2は、この基準を引き続き継承するとともに、さらに内容を充実させて価格を引き下げました。
公式が剛剛発表した価格表によると、100万トークンあたりの価格は以下の通りです。
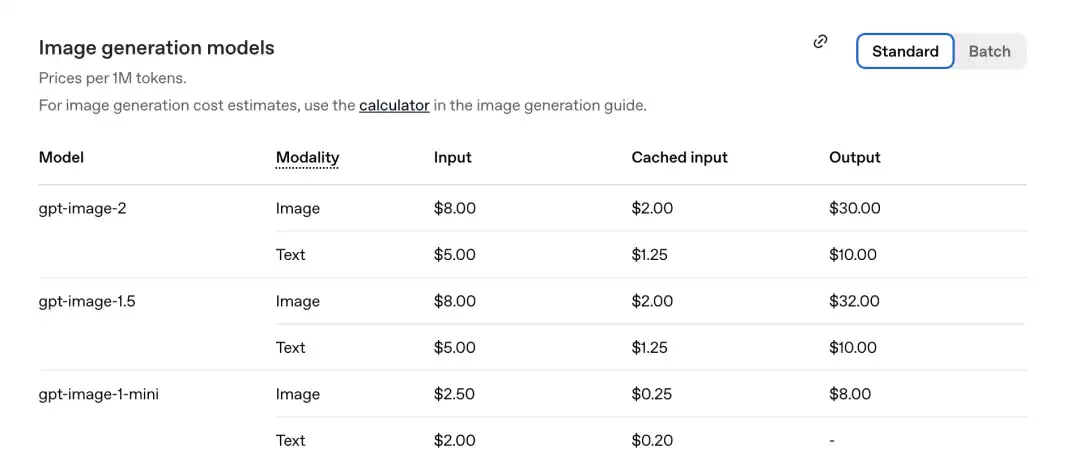
GPT-Image-2 イメージ部分:入力 8.00、キャッシュ入力(Cachedinputs)2.00、出力 $30.00。
前世代のgpt-image-1.5と比較:出力は$32.00です。
新しいモデルの方がむしろ安くなりました。
では、計算してみましょう。
過去のモデルでは、高品質な画像を生成するのに約1000〜1500の出力トークンを消費しました。
百万トークンあたり30ドルの料金で計算すると、1枚の画像を生成する実際のコストは約0.03~0.045ドル(約人民元2~3毛)です。
秒返が必要ない場合、公式が提供するBatch(バッチ)APIモードを使用すると、この価格はさらに半額になります(出力が$15.00に直接低下します)。
計算すると、1枚の画像を生成するのに最低でも1毛以上かかります。
このシングルペイスの価格はすでに十分にコストパフォーマンスが高いですが、本当の強みは価格表にあるキャッシュされた入力(Cached inputs)です。
以前、マンガを描いたり、同じシリーズのポスター設計を行ったりする際、毎回再生成するたびに多数のキャラクター参考図、前情説明、長いプロンプトを再アップロードしなければならず、入力コストが非常に高かった。
しかし、現在のトークン課金モデルでは、8枚の連続した漫画を一度に生成させると、最初の画像の視覚的要素が直接コンテキストキャッシュとして保存されます。
2枚目の画像から、画像の入力コストは$8.00から$2.00に急落しました(つまり、25%のみを徴収)。
したがって、大規模な商業用バッチ画像生成や、高いキャラクター一貫性が求められる連続生成を行う場合、その限界コストは急激に低下します。
モデルがより賢く、より多くの画像を生成するほど、1枚あたりの平均コストは低くなります。
この工業化された課金ロジックが、本当にラインアートの画家たちを追い詰めるものだ。
PART.05 バックステージチームの正体揭秘
最後に、このライブ発表会で登壇したOpenAIの内部ビジュアルチームを改めて振り返ると、以前は信じられなかった多くの機能が、完全に理解できるようになった。
例えば、それはどのようにして多言語の複雑なレイアウトと難解な文字の課題を解決しているのでしょうか。
これは、チームのシニアサイエンティストであるGabriel Gohのおかげです。

この学術界では、彼は革新的なマルチモーダルモデル CLIP の主要著者として最も有名です。
CLIPは、現代のAIが人間の言語と画像のピクセルがどのように対応しているかを理解するための基盤を築きました。
このマルチモーダル意味マッピングの専門家が率いることで、GPT-Image-2は文字の形状を推測するのではなく、ピクセルレベルで実際に文字を書くことができるようになりました。
例えば、それが三次元の空間関係をどうやって理解し、極端なアスペクト比の360度パノラマ画像を作成でき、米粒ほどの微距における光と影を理解できるのでしょうか。
これはもう一人のコアメンバーであるAlex Yuのおかげです。

彼はOpenAIに参加する前は、3D生成分野の注目を集めるスタートアップ企業Luma AIの共同創設者かつ元CTOであり、3Dニューラルレンダリング(NeRFなど)に特化したトップレベルの研究者でした。
彼がいることで、GPT-Image-2 は既に従来の2Dピクセル塗りつぶしから脱却しています。
おそらく、脳内でまず三次元のシーンを構築し、照明を整えた上で、正確な2Dスライスをレンダリングしているのでしょう。
どのようにしてあの恐ろしく長い漫画の一貫性を実現したのでしょうか。
これは、マサチューセッツ工科大学(MIT CSAIL)から間もない若いチームのコンビに対応しています:
Boyuan Chen(左)と Kiwhan Song(右)。
彼らの学術界における核心的な方向性は、ワールドモデル(World Models)とエムボディードインテリジェンスです。
機械に物理世界の働き方を理解させ、異なる時間と空間のシーンにおいてキャラクターの特徴を完全に一致させ、変形させないということが、まさにこの二人の学者が取り組み続けてきた課題である。
最後に、推論大モデルと視覚の基盤ロジックの連携に長年取り組んできた Nithanth Kudige(左、Oシリーズ推論モデルの主要な著者)と Kenji Hata(右、元グーグル研究員、スタンフォード視覚ラボ出身)を加えます。

この人々が集まると、基本的な論理推論、3D空間レンダリング、画像とテキストの極限の整列、そして物理世界の法則が、自然に同じモデルに統合された。
PART.06 GPT-Image-2の境界
あらゆるモデルには限界があります。
公式も、特定の極端な状況に直面した際に依然として苦戦することを認めています。
例えば、厳密な物理的空間の反転を必要とする折紙のガイドや、ルービックキューブの解き方、あるいは極めて緻密な砂粒のような高頻度の詳細などは、依然としてその能力の限界に触れる。
しかし、商業アプリケーションの文脈では、これは極めて微細な欠陥です。
デザイン業界全体にとって、不安をあおる必要はありません。これは審美の終焉を意味するものではありません。
洗練され、ビジネスの洞察力を持ち、戦略を理解する人々は、依然としてこれを使って優れたものを生み出せる。
しかし、客観的な事実として、デザイナーという職業の競争優位性は実質的に崩壊しています。
以前,靠熟记设计软件的快捷键、懂得如何将字体横平竖直地对齐、懂得根据语种进行排版、懂得精细修图和抠图来谋生。
しかし、今後は難しくなるでしょう。なぜなら、かつて明確な価格で取引されていたこれらのスキルが、今や誰でも一言で無料で呼び出せる基本的なコマンドになってしまったからです。
しばらくの沈黙の後、OpenAIは非常に静かだが非常に強力な方法で、このトランプのテーブルで誰が本当のジョーカーを握っているかを再び示した。
従来の実行ツールチェーンが破綻しており、業界に残された課題はAIが私たちを置き換えるかどうかではなく、この全新的な生産ラインにどう適応するかです。