









今夜、ChatGPT Images 2.0が衝撃的にリリースされ、初の「思考する」画像AIとなりました。オーレンは、これがGPT-3からGPT-5への飛躍だと称賛しました。このAIは中国語の指示を正確に理解し、複雑なUIをレンダリングするだけでなく、米粒に文字を刻むことさえ可能です。
記事執筆者、出典:新智元
あの親しみやすいOpenAIが戻ってきました!
深夜、ウルトラマンが自らチームを率い、20分間のオンラインライブを実施し、数日間の沈黙を破った。
OpenAIがようやく噂されていたChatGPT Images 2.0をリリースし、画像生成の新たな時代を本格的に開幕しました。

Images 2.0は質的な飛躍であり、長文の指示を正確に理解し、物体間の関係を正確に配置・整理し、密集したテキストをレンダリングする点で大きな進歩を遂げました。
最も重要なのは、これが初めて「思考能力」を備えた画像モデルであり、インターネットに接続してリアルタイム情報を検索し、再確認が可能であることです。
また、一括で8枚のスタイルが統一された画像を生成でき、最高2K超解像度をサポートします。
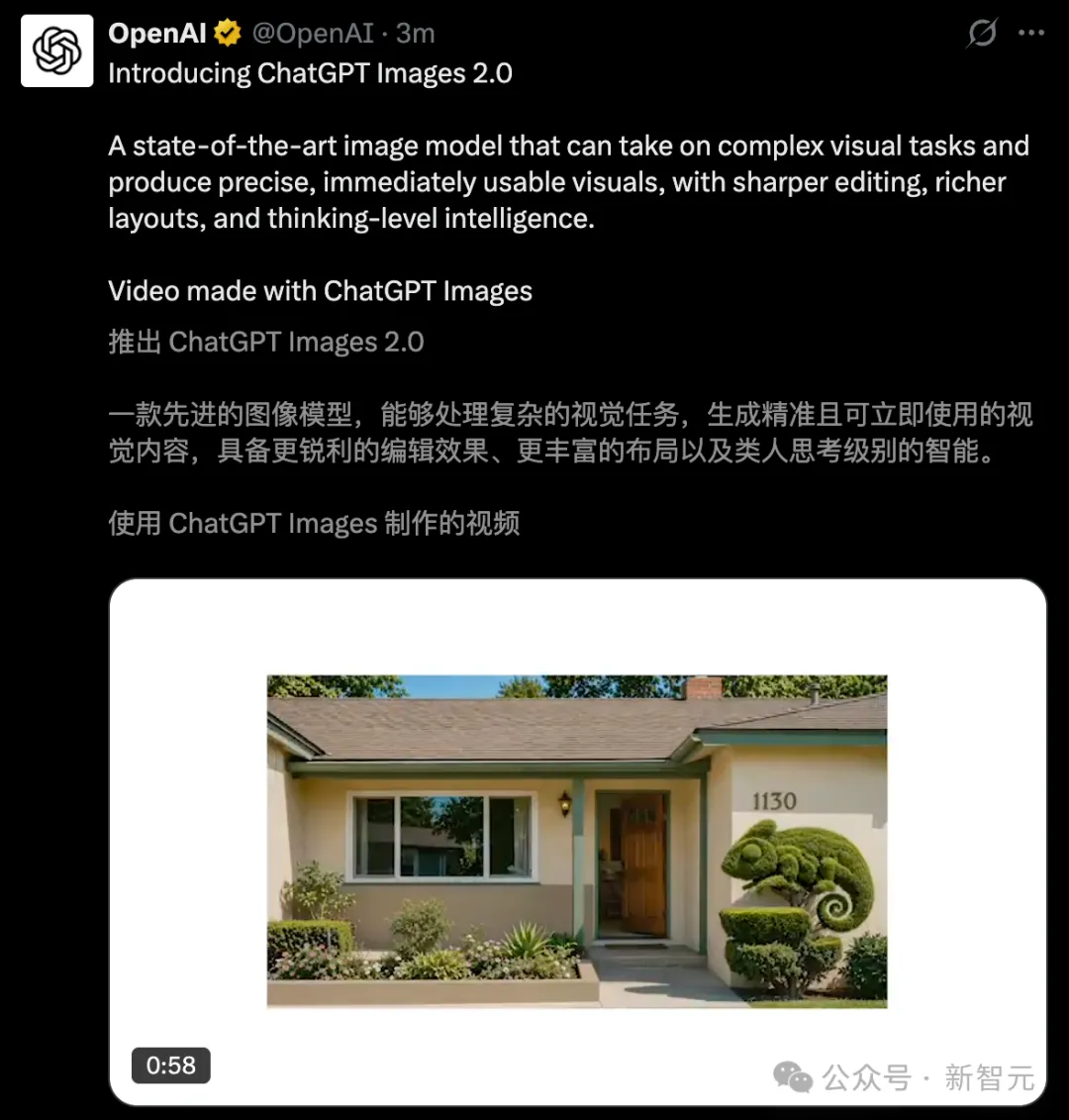
言い換えれば、Images 2.0の登場が、視覚生成の支配力を再定義した——
- ピクセル単位の精度:小文字のテキスト、アイコン、UI要素などの複雑な詳細をワンクリックで生成し、3:1から1:3までの全サイズ出力をサポートします;
- 多言語の質的変化:中国語、日本語、韓国語など非ラテン文字の正確なレンダリングにより、文字の綴りだけでなく、文も滑らかで自然になります;
- 成熟なスタイル:写真級のリアリズム、映画のワンシーン、ピクセルアート、漫画などのビジュアル言語をすべて巧みに取り入れる;
- 思考する:最初の推論機能を備えた画像モデルで、インターネット検索や出力の自己チェックが可能。知識は2025年12月まで更新されています。
Arena最新ランキングで、Images 2.0が圧倒的な差をつけて、世界のAI画像生成トップに登頂。Google Nano Banana 2/Proを242点差で上回りました。
それは7つのすべてのテキストから画像生成カテゴリで、すべて1位でした。


最も驚異的なのは、ピクセルレベルで生成できることです。
ライブ配信中に生成された米山図の一つの米粒に、「GPT image 2」というフォントが刻まれていた。
オルトマンは、4o画像担当のガブリエル・ゴーと一緒におよそGPUの漫画画像をさらに公開した。
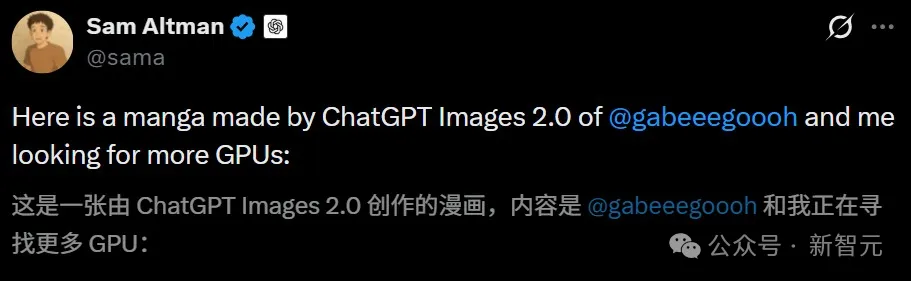

ネットユーザーたちが次々と体験し、Images 2.0の実力に再び驚かされました。
中には、「OpenAIが再び画像生成分野をリードした」と語る人もいます!

中国語で直接封神。OpenAI自らネタを振り「しっかり受け止める」
過去の画像モデルは、英語やラテン文字言語ではそれなりに機能したが、中国語、日本語、韓国語の文字になると「鬼画符」になってしまった。
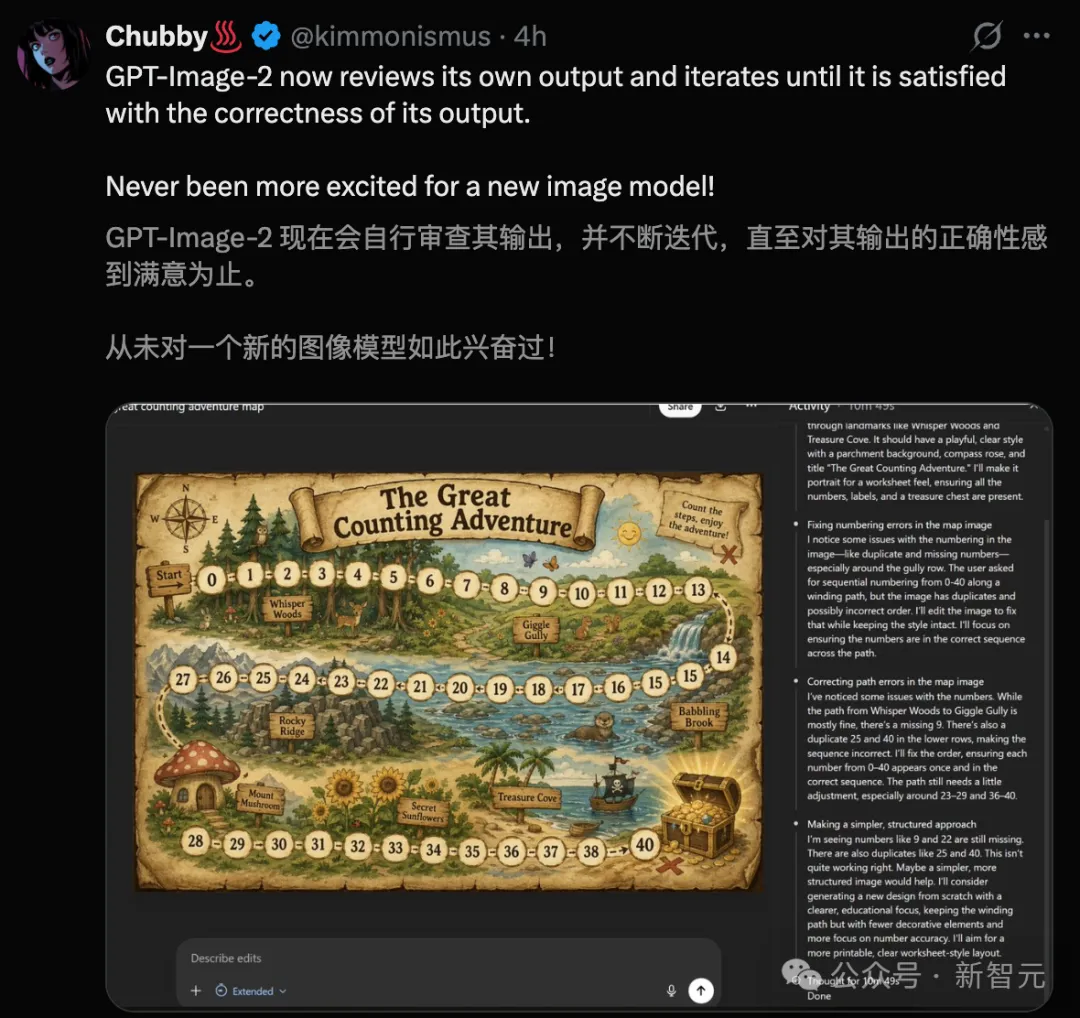
今回、公式ブログで公開された中国語デモが大反響を呼んだ。
OpenAI研究科学者チェン・ボーユアンが自ら出演(おそらく自分で作成したプロンプトだろう)、中国語のカラフルな漫画1ページを生成し、OpenAIでChatGPT Image 2の中国語テキストレンダリング最適化について語っている。

この図は、中国語テキストのレンダリング能力の飛躍的向上、極小フォントサイズの精度制御、および複雑なマルチパネル漫画の一度の生成能力を同時に示しています。
漫画は5段に分かれ、第一段は陳博遠がパソコンの前に向かって懸命に作業している様子で、背景にはパールミルクティーがあり、壁にはテープでバナナが貼り付けられている(アート界の有名なシーンへのオマージュ)。
第二列は、彼が故郷の無錫のために生成した多言語手書き風情報図ポスターで、ぎっしりと書かれた中国語の小さな文字がすべて正しくレンダリングされている。
三列目は、チームが効果を確認した後の盛り上がる様子です。
第四列のシーンが変わり、陳博遠は携帯電話を手に休憩中であり、オーレンからチームの中国語レンダリング成果を祝う翻訳メッセージを受け取った。
そして、メインイベントがやってきます。
第五列で、陳博遠はオーレマンが生成したお祝いの画像を見て、中央に「しっかり受け止める」と書かれていた。
わかる人はわかる。

GPTは中国語の会話で頻繁に「あなたをしっかり受け止めます」「あなたの感情は正当です」と言い、その脂ぎったようで誠実なアメリカ式カウンセリングの匂いが、中国語ユーザーに半年以上も酷評されてきた。
漫画の陳博遠は即座に崩れ、漫画風に怒りながら叫ぶ「えっ!またキャッチを覚えた!?」。隣のチームメイトたちは頭から冷や汗をかき、弱々しく「今、修理中です!」と答える。
この自虐は満点です。(手動で犬頭)

中国語以外にも、OpenAIは日本語の対話が全編使用された少年冒険漫画、ヒンディー語、ベンガル語、テルグ語など9か国語の書籍カバーを掲載したインドの書店、そして韓国語の高級韓屋宿泊広告を公開しました。
言語はもはや画像生成の「二等市民」ではない。

ピクセル単位の生成 GPT-3からGPT-5への大幅な進化
ChatGPT Images 2.0は、OpenAIの画像生成における次のマイルストーンと呼べる。
ライブ中、オルトマンはこれを「GPT-3から一気にGPT-5に昇進したような感覚だ」と呼んだ。
4人でのグループ写真をアップロードし、ChatGPTが雑誌の表紙を生成。ページデザインや文字のレイアウトが非常に丁寧である。
また、ポスターには膨大な細部が含まれており、小さな文字の処理や人物の顔の一貫性が、男性アイドルグループのような臨場感を生み出しています。

細部において、ChatGPTの出力は「写真級」の効果を完全に達成し、AIが生成したものであるとは見分けられないほどリアルです。
例えば、この画像は2015年、OpenAIが設立された当時に戻ったかのような、階段教室の照明環境とPPTの文案に驚かされます。
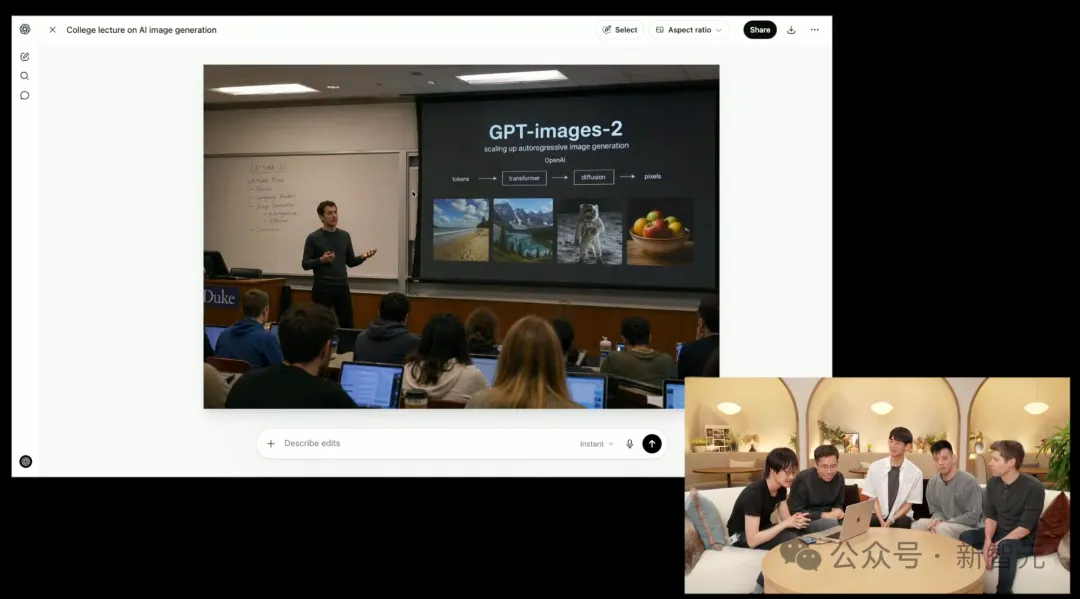
会場を驚かせたのは、人類が月に着陸した360°パノラマ写真だった。
ChatGPTで生成した画像をパノラマビューアに取り込むと、太陽の位置、影の方向、その他の細部がすべて明確に確認できます。
公式が公開したデモには、macOSのブラウザでのChatGPTウィンドウのスクリーンショットが含まれています。
ウィンドウが重なり、ターミナルがバックグラウンドで開き、デスクトップがごちゃごちゃしている。視覚的な細部が異常に多く、生成された結果はほぼ実際のスクリーンショットと同一である。
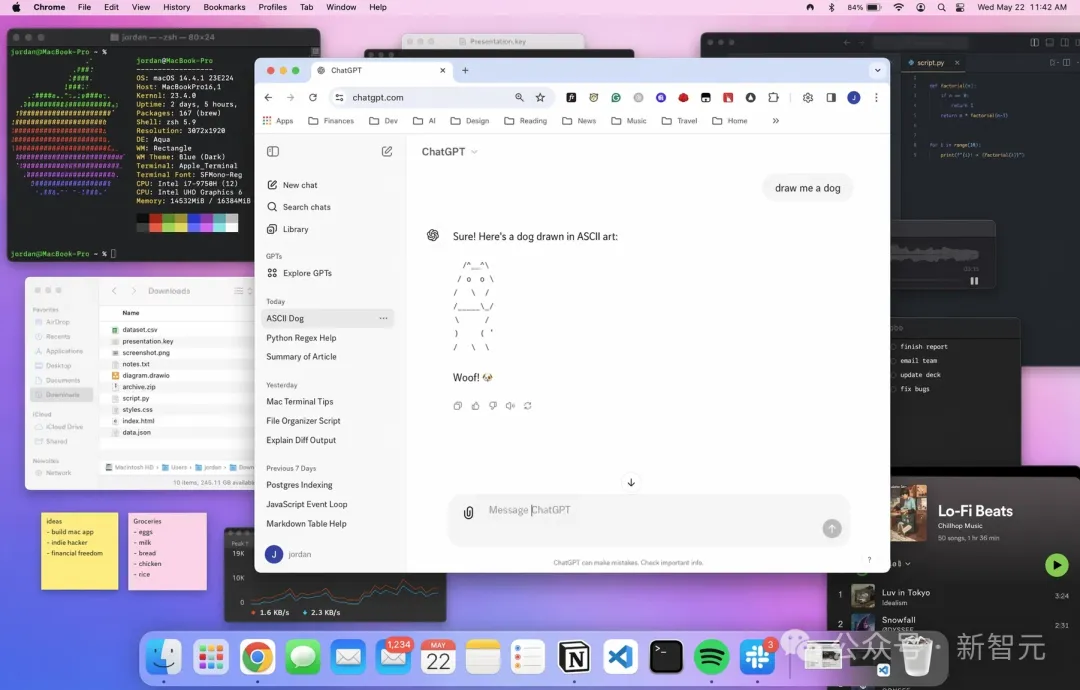
このレベルのレンダリング精度は、モデルが画像の各ピクセルに対する制御力が臨界点を超えたことを示しています。
写真級のリアリズムを備えたAI生成画像が、ついにAIらしくなくなった
スタイルのリアルさはまた一つの大きな進歩です。
過去のAI生成画像には、どこか言葉にできない「AI感」があり、肌があまりにも滑らかで、光が均一で、構図が完璧すぎて、一目で本物の写真ではないとわかる。
Images 2.0は逆の道を選び、「不完全さ」を学び始めました。
公式デモには、35mmフィルムの質感を持ち、粒状性が見えるスナップショットのセットが含まれており、構図はやや中心からずれており、服と髪が風で揺れている。
あなたにこれがAIで生成されたものだと教えなければ、誰かが道路脇でふとシャッターを切った結果だと思ってしまうでしょう。

さらに、2000年代初頭のアメリカの高校コンピュータールームを模した、ワンタイムカメラ風の写真セットがあり、生徒たちがベージュのCRTモニターの前に詰めかけ、ChatGPTを使っている様子が描かれている。
フラッシュの過剰露出、軽いモーションブラー、隅に「02 18 04」と印されたオレンジ色の日付スタンプ。すべての「フィルム時代の不完全さ」が正確に再現されている。

スタイルの多様性において、Images 2.0も差を広げました。
アスペクト比は現在、最大3:1、最大1:3をサポートしています。これに合わせて、OpenAIは中国伝統的な横長の山水画を特意に掲載し、墨の濃淡と余白の表現が非常に優れています。
1960年代のフランス・ヌーベルバーグ映画のポスター、アールデコスタイルのブックマーク、アニメキャラクターの設定画。それぞれのビジュアル言語は、「ちょっと似ている」だけでなく、高いスタイルの一貫性を保っている。

思考する画像モデルが一度に8枚の連続した画像を生成
ライブ配信中、ChatGPT画像担当のGabriel Gohは、Images 2.0には合計で2つのモードが導入されたと述べました——
- インスタントモード
- 思考モード
その中で最も革新的なアップグレードは、すべて「思考モード」に隠されています。
ChatGPTで思考モデルを選択すると、Images 2.0はもはや「言うと描く」レンダラーではなく、視覚的な思考パートナーになります。
それは、あなたの意図を理解するのに時間がかかり、ネット上でリアルタイムの情報を検索し、画像の構造を推論した上で、ようやく書き始めるのです。
さらに重要なのは、思考モードでは、スタイルが一貫し、キャラクターが同じで、内容が段階的に進む最大8枚の画像を一度に生成できることです。
顔写真を1枚アップロードするだけで、ChatGPTがすぐに夏服の8つのコーディネートを提案します。その中から1つを選べば、さらにさまざまな角度からの衣類の詳細が生成されます。
このタスクでは、ChatGPTが2種類の異なる「ビジュアルインテリジェンス」を呼び出しました:
まず「視覚理解」の能力で、写真を実際に「見て」、人の容姿を理解し、適切な服装の組み合わせを計画します。
もう一つの次元は「視覚生成」能力です。これには、計画された衣装のレイアウトを一貫性があり、整理された画像に変換する必要があります。
以前はソーシャルメディア用の素材を一枚ずつ生成し、自分で組み合わせる必要がありました。今では、1つのプロンプトでTwitter、Instagram Stories、Instagram Feed、LinkedInの4つのサイズを一括で生成でき、色調と構図のスタイルが統一されます。
公式デモでは、ブルックリンの抹茶店「kizuki」の広告素材を紹介。日差しに輝くアイスストロベリーマッチャの映像に、ストリートファッションの美学と日本の極簡主義を組み合わせ、4つのソーシャルメディア向けサイズを一度に提供。

さらに、学術論文のポスター用デモも用意しており、PDFを直接アップロードすると、モデルが重要なチャート、データ、構造を自動で抽出し、横長のポスター形式にレイアウトします。

注目すべきは、Images 2.0が思考モードを有効にすると、直接インターネットで情報を検索できることです。
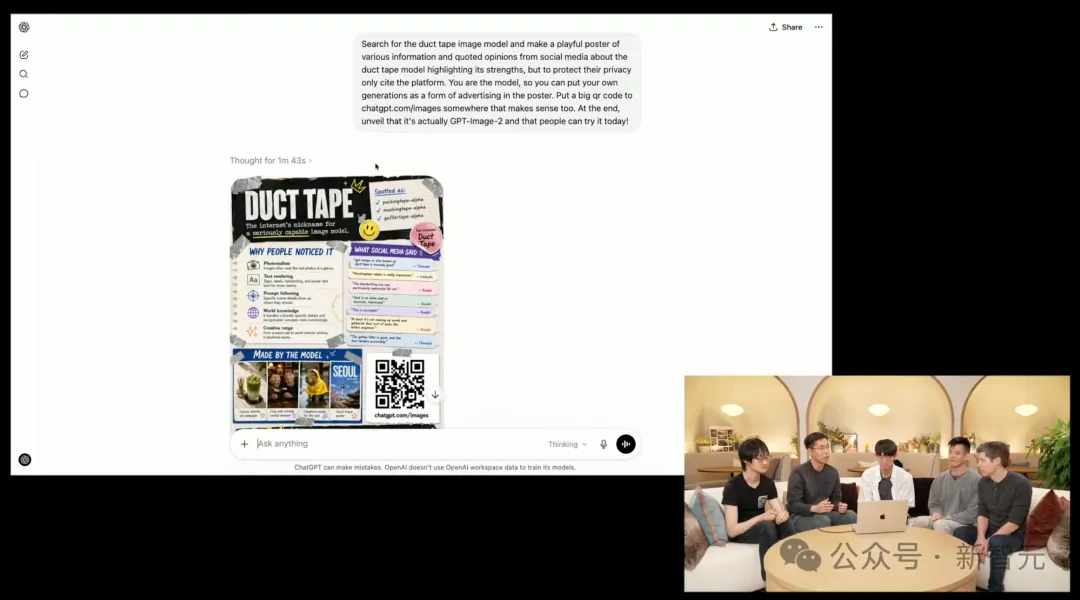
チームは、数日前にArenaでベータテストされた「DuckTape」が、本日のImages 2.0であることを明かした。
その後、彼らはImages 2.0にネットユーザーのフィードバックを収集し、1枚の画像にまとめさせました。意想不到にも、モデルはスキャン可能な「QRコード」を生成しました。
ChatGPT、Codexが全線開放
今日から、すべてのChatGPTおよびCodexでChatGPT Images 2.0を使用できるようになります。
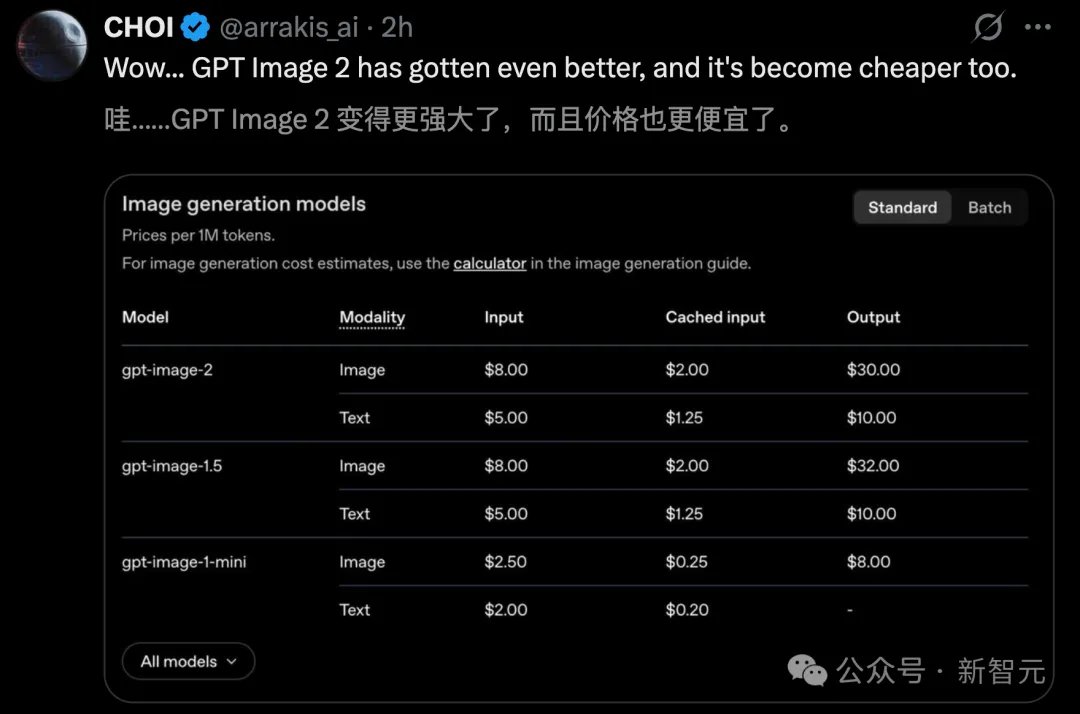
「思考」プロセスを備えた画像生成機能が、ChatGPT Plus、Pro、Businessユーザーに開放されました。基盤モデルgpt-image-2もAPIでリリースされました。

価格面で、ChatGPT Images 2.0は強化され、トークンの入力/出力価格は上昇していません。
一般のユーザーにとって、過去はPhotoshopを操作して長時間かけていたプレゼンテーション用画像、ソーシャルメディア用ポスター、製品プロモーションカードなどが、今では1つのプロンプトで簡単に作成できます。
開発者および企業にとって、ローカライズされた広告、多言語インフォグラフィック、教育コンテンツ、デザインツールなどの手作業が多かったビジュアルワークフローが、今やAPIを介して一括自動化可能になりました。
Codexでは、画像生成がワークスペースに統合され、デザインチームは同じ環境でUI案を立案し、オプションを比較して製品に移行でき、途中でツールを切り替える必要がありません。
画像生成のiPhoneの瞬間?
振り返ると、DALL·EからMidjourney、Stable Diffusionに至るまで、AI画像生成は「十分だがそれほど優れていない」状態だった。
文字のレンダリングが失敗し、多言語対応が不十分で、スタイルが一律であり、構図が一目でAI生成とわかる——これらの課題は、AI画像を本格的なシーンに活用したい人々をすべて却下してきた。
Images 2.0はこれらの短所を一気に補い、思考機能と複数画像の一度生成を追加しました。
それは「完璧」まではまだ遠いが、デザイナー、マーケター、コンテンツクリエイターが「これは実際に仕事で使える」と実感する最初のAI画像モデルかもしれない。
今や、デザイナーたちは自らの競争優位性がどこにあるのか、再考する必要があるかもしれない。
参考資料:
https://x.com/OpenAI/status/2046661795327459677
https://x.com/OpenAI/status/2046670977145372771
https://openai.com/index/introducing-chatgpt-images-2-0/
https://x.com/sama/status/2046672912833458597