










出典:CoinW 研究院
要約
Gradientsは、Bittensor上に構築された分散型AIトレーニングサブネット(SN56)であり、その核心は「タスクの公開、マイナーの競争、検証による選別」などのメカニズムを通じて、モデルトレーニングを複雑な技術プロセスから市場駆動型のネットワーク協力プロセスへと転換することです。アーキテクチャ面では、AutoMLと分散型コンピューティングリソースを統合し、インセンティブメカニズムを核とするトレーニングマーケットを形成することで、AIの利用障壁を低減し、コンピューティングリソースの利用効率を向上させています。エコシステムおよびデータのパフォーマンス面では、Gradientsは基本的なネットワーク構築を完了していますが、現在のインセンティブ重みや資金流入は依然として限定的です。GradientsはTAOエコシステムにおけるトレーニングインフラを補完し、「市場駆動型AI最適化」という新たなパラダイムを模索しており、長期的には分散型AIトレーニングの重要なエントリーレイヤーとなる可能性を秘めています。
1. Web2 AutoML から始める:AI 訓練の現状と限界
1.1 AutoMLとは何か
従来の認識では、AIモデルを訓練することは非常に高いハードルがあり、エンジニアがデータを処理し、モデルを選択し、パラメータを繰り返し調整し、効果を評価する必要があり、プロセスは複雑で時間のかかるものでした。一方、AutoML(自動機械学習)の登場は、これらの煩雑な手順を「一括して自動化」することを本質的に意味します。これは「モデルを自動で作成するツール」と考えることができます。ユーザーはデータを提供し、分類、予測、認識などの目標をシステムに伝えるだけで、モデルの選択、パラメータ調整、訓練と最適化といった残りのプロセスはすべてシステムが自動で完了します。これにより、AIは少数の専門エンジニアのためのツールから、一般の開発者や企業にも利用可能な能力へと進化し、AIの普及に向けた重要な一歩となりました。
1.2 伝統的なAutoMLの核心的な制限
現在、AutoMLの主流実装は、Google Vertex AIやAWS SageMakerなどのクラウドプロバイダーのプラットフォームに集中しており、これらのプラットフォームは「AIトレーニングをサービスとして提供」しています。Web2 AutoMLはAIの利用门槛を大幅に低下させましたが、その基盤モデルには依然として明確な限界があります。まず、中心化の問題があり、計算リソース、価格設定、ルールはすべてプラットフォームが支配しており、ユーザーは単一のサービスプロバイダーに強く依存し、交渉力が欠けています。次に、コストが高く、透明性に欠けています。AIトレーニングに必要なGPUリソースは主にクラウドプロバイダーが保有しており、価格メカニズムには市場競争が反映されていません。さらに重要なのは、最適化効率に上限があることです。従来のAutoMLは本質的に「1つのシステムがあなたの代わりに最適解を探している」に過ぎず、そのシステムがいかに複雑であっても、単一の技術的アプローチの最適化にすぎません。その探索空間は限定的であり、まったく異なる複数のアプローチを同時に試すことは困難です。したがって、現在のWeb2 AIトレーニングは「閉鎖的なシステム」であり、モデルのトレーニング、最適化、リソーススケジューリングはすべて単一のプラットフォームが支配する環境で行われています。このモデルは効率的ですが、需要の増加に伴い、その限界が徐々に明らかになってきています。
2. Gradients:「ネットワーク」でAIトレーニングを再構築
2.1 Gradientsとは:分散型AutoMLプラットフォーム
前の章で述べたように、従来のWeb2 AutoMLの核心的な課題は「閉鎖的なシステム」であり、モデルの訓練はプラットフォームに依存し、最適化のパスが限られ、リソースの流れが制限されていました。Gradientsは、このモデルに対する再構築です。Gradientsは、WanderingWeightsが立ち上げた分散型エンジニアコミュニティに由来し、Bittensorネットワーク上に構築され、Subnet 56で動作するAI訓練サブネットです。従来のプラットフォームとは異なり、Gradientsは中央集権的なサービスを提供せず、訓練プロセスを分解してオープンなネットワークに委ねます。ユーザーはモデルの種類やデータなどのタスク目標を定義するだけで、訓練の実行、パラメータ最適化、結果の選別といったその他のプロセスはすべてネットワークが自動的に処理します。このモデルでは、AI訓練は複雑なエンジニアリングプロセスから、「要件を提出して結果を得る」というシンプルなプロセスへと抽象化され、非常に専門的な技術作業ではなく、汎用的な能力に近づいています。
2.2 閉鎖システムからオープンな協力へ:Gradients が解決した問題
Gradientsの核心的な変更は、従来単一プラットフォーム内に閉じていたトレーニングプロセスを、オープンな協力型ネットワークプロセスに変えることです。トレーニングタスクは単一のシステムによって完了するのではなく、複数の参加者に分散され、並列に試行され、その後統一された評価メカニズムによって最適な結果が選択されます。この構造はまず、中央集権的なサービスプロバイダーへの依存を低減し、トレーニングを分散型コンピューティングパワーに基づいて構築します。同時に、分散したGPUリソースが同一ネットワークに統合され、競争を通じてより市場に近いリソース配分方式を実現します。さらに重要なのは、モデルの最適化が単一のパスに限定されず、複数の手法を並列に探求することで、より優れた解に次第に近づき、全体の最適化上限を高めることです。
2.3 本質的な変化:ツールから「トレーニングマーケット」へ
従来のAutoMLでは、プラットフォームは内部アルゴリズムを通じてユーザーが最適解を見つけるためのツールに過ぎませんでした。一方、Gradientsでは、このプロセスは持続的に動作する「市場」に近いものです:ユーザーが要求を掲示し、異なる参加者が同じタスクをめぐって競い合い、評価メカニズムによって結果が選別されます。これにより、モデルの性能は単一システムの能力に依存するのではなく、複数の参加者による持続的な競争と反復から生み出されます。AutoMLは、比較的閉鎖的な技術的最適化の問題から、インセンティブによって駆動される動的なプロセスへと変化し、参加者が増えるにつれて最適化能力が拡張可能になります。この変化により、AIのトレーニングは市場に似た自己進化の特性を備え始めています。
2.4 TAOエコシステムにおける役割:AIトレーニングインフラ層
Bittensorのサブネット体系において、異なるサブネットは推論、データ処理、トレーニングなどの異なる機能を担っており、Gradientsはトレーニング層に位置しています。Gradientsは分散された計算能力を実際のモデル出力に変換し、タスク配信と評価メカニズムを通じてこれらのリソースを継続的にスケジューリングおよび最適化します。同時に、Gradientsは計算能力の供給とモデルの需要を結びつけ、トレーニングを単なるリソース消費プロセスから、組織化され最適化可能なネットワーク協働プロセスへと変革します。この体系において、Gradientsは分散リソースを利用可能なAI能力に変換する中枢的な役割を果たし、上位アプリケーションの発展を支えています。
3. コアアーキテクチャ:AIのトレーニングはネットワーク内でどのように実行されるか
前の章で、Gradients は AI のトレーニングを「プラットフォーム内で完了」から「ネットワークによる協力で完了」へと変革したと述べました。では、このネットワークは具体的にどのように機能しているのでしょうか?この章の核心は、このプロセスをより直感的に分解して明確にすることです。
3.1 分散学習:1つのタスクはどのように「複数人で完了」されるのか
Gradients を、継続的に動作する「トレーニング協力ネットワーク」と考えることができます。ユーザーがトレーニングタスクを送信すると、そのタスクは特定のシステムに割り当てられるのではなく、ネットワーク内の複数の参加者に同時に配信されます。これらの参加者は、同じデータと目標に基づき、それぞれ異なるトレーニング手法を試行し、規定時間内に結果を提出します。その後、システムはこれらの結果を一括で評価し、最も優れたソリューションを選び出します。最終的に、優れた結果には報酬が与えられ、他のソリューションは除外されます。ユーザーの視点では、このプロセスは一度タスクを発信するだけで、複数の異なる最適化アプローチを同時に「呼び出し」、最適解を自動的に選択したことに相当します。この方式の鍵は、個々のノードの性能ではなく、多数の参加者が並行して試行し、自動的に選別することで、結果を最適に近づけていく点にあります。
このネットワークには主に三つの参加者があります:ユーザー、マイナー、バリデーターです。ユーザーはトレーニング要件を提案し、マイナーは計算リソースを提供してさまざまなトレーニング手法を試行します。バリデーターは結果を評価し、最適なモデルを選定します。この役割分担により、トレーニングプロセスが継続的に実行され、より優れた解が次々と選ばれます。全体として、これは「需要、供給、評価」によって駆動される協力ネットワークを構成しています。
3.2 マーケット駆動のAutoML
前の文のメカニズム解説からわかるように、Gradients は AutoML を単純にチェーン上に移すのではなく、複数の参加者とインセンティブメカニズムを導入することで、モデル最適化の基本的なロジックを変革しています。従来の AutoML は、限られたパスの中で単一のシステムが最適解を探索しますが、Gradients ではこのプロセスがネットワーク全体に拡張されます。異なる参加者が同じタスクに対して継続的に異なるアプローチを試行し、統一された評価を通じて継続的に選別と反復を繰り返します。これにより、モデル最適化は一度きりの計算プロセスではなく、繰り返し進化可能なダイナミックなプロセスとなります。このようなメカニズムのもと、より優れた性能を発揮する結果はより高い報酬を得るため、参加者が継続的に戦略を最適化し、全体の効果が常に向上し続けます。
4. インセンティブと競争メカニズム:AIのトレーニングが「ポジティブサイクル」をどのように形成するか
4.1 インセンティブメカニズム(TAO駆動):トレーニング行動から収益還元へ
Gradientsが長期的に運用できる鍵は、その背後にあるインセンティブメカニズムにあります。これは、Bittensorが提供するネイティブインセンティブ体制に依存しています。その中で、TAOはBittensorネットワークのネイティブトークンであり、ネットワーク全体における「価値の担い手」として機能します。一方では、計算リソースやモデルへの貢献を行った参加者に報酬を支払うために使用され、他方では、ステーキングなどの方法を通じてサブネットのウェイト配分に参加し、リソースが異なるサブネット間でどのように流れるかに影響を与えます。
Bittensor メインネットは、継続的に新しいインセンティブエミッション(TAO)を生成し(現在の適切な日量は約3600TAO)、一定のルールに基づいてさまざまなサブネットに配分します。各サブネットがどれだけのTAOを受け取るかは、ネットワーク全体における「パフォーマンス」、たとえば活性度、貢献の質、資金支援状況などによって決まります。Gradientsが所属するサブネットでは、このように配分されたTAOが内部で参加者間に再配分されます。配分の核心的な基準は、どのモデルの貢献が優れているかであり、優れたモデルを提供した参加者がより多くのリワードを得られます。
具体的には、マイナーが訓練結果を提出し、バリデーターがそれらをテストして評価します。システムは評価結果に基づいて、各参加者の「貢献ウェイト」を計算し、このウェイトに従って報酬を分配します。汎化能力が高く、安定した性能を示すような優れたモデルはより高い収益を得られ、また、実際の品質を正確に反映する評価を行うバリデーターもより多くのインセンティブを受け取ります。この設計により、「より良く行う」ことが直接「より多く稼ぐ」ことにつながり、参加者がモデルの最適化を継続的に推進するよう促されます。
4.2 サブネット間の競争:内部競争だけでなく、外部ランキングでも
サブネット内部の競争に加えて、GradientsはBittensorネットワーク全体における「横断的競争」にも直面している。TAOの配分は動的であるため、異なるサブネット間でより高い重みを巡って競争が発生する。継続的に高品質な結果を生み出し、より多くの参加者を引きつけるサブネットのみが、より大きな報酬シェアを得られる。したがって、Gradientsのインセンティブは内部のモデルパフォーマンスだけでなく、エコシステム全体における相対的競争力にも依存する。このシステム全体は、複数層の循環を形成している:サブネット内ではモデル同士が競い合い、サブネット間では全体的なパフォーマンスが競われる。最終的に、計算リソースの投入、モデルの効果、経済的報酬が結びつき、持続的に機能する正のフィードバックメカニズムが構築される。
4.3 グラデーション 5.0:競争から「トーナメントメカニズム」へ
初期の継続的な競争を基盤に、Gradientsはより構造化されたメカニズムである「トーナメント型トレーニング」へと進化しました。これは周期的なコンペティションと捉えられます:各トレーニングラウンドでは時間枠が設定され、複数の参加者が同じタスクをめぐって競い合い、複数の選抜段階を経て最適なソリューションが選出されます。この形式は段階的な比較と集中評価を重視します。重要な変更点の一つは、マイナーがトレーニング結果を直接提出するのではなく、「トレーニング方法」(コード)を提出し、検証ノードが一括して実行するようになったことです。これにより、計算環境の違いによる干渉を回避し、公平性が向上するとともに、データとトレーニングプロセスのプライバシーもより適切に保護されます。さらに、優勝したソリューションは通常、再利用可能な方法として蓄積され、継続的に進化する「ベストプラクティス」となります。長期的には、このメカニズムは最適なモデルを選出するだけでなく、進化し続けるトレーニング方法のライブラリを構築することでもあります。
5. エコシステムの現状
5.1 参加者構造:需要、供給、評価からなる協力ネットワーク
Gradientsエコシステムは、ユーザー(需要側)、マイナー(供給側)、およびバリデーター(評価側)の3つのコアロールで構成されています。ユーザーには主にAI開発者、中小企業、Web3ビルダーが含まれ、これらのグループは一般的に一定の技術的基盤を持ちますが、計算リソースや完全なモデルトレーニング能力を欠いているため、Gradientsを通じて低コストでモデルを構築することを好みます。マイナーはGPU計算リソースを提供し、トレーニングタスクの競争に参加します。彼らの主な動機はTAO報酬を得ることです。バリデーターはトレーニング結果を評価・ランキングする役割を担い、モデルの品質とメカニズムの円滑な運用を保証する鍵となる存在です。
より細分化されたユーザー層を見ると、Gradientsの実際の利用者は明確な「半開発者化」の特徴を示しています。トップレベルのAI研究所とは異なり、技術的背景のない一般ユーザーとも異なり、ある程度のエンジニアリング能力を持つ開発者とWeb3技術ユーザーが中心です。これはコミュニティ構造にも反映されており、現在のエコシステムは英語が主導し、核心的なユーザーは北米とヨーロッパの開発者層に集中しており、一部の東南アジアのマイナーとグローバルなGPUリソース提供者もカバーしています。全体として、技術主導の開発者コミュニティに近い状態です。
5.2 エコシステムの現在の運用状況
5月12日現在、Gradientsのalphaトークン価格は約0.0255 TAO、保有アドレスは約4,890件、マイナーは243人、バリデーターは12人で、Emission比率は1.61%です。また、流動性プールにおけるTAOの比率は2.19%、Alphaの比率は97.81%です。価格と保有アドレス数の観点から、Gradientsは一定のユーザー基盤と注目度を有していますが、全体としてはまだ初期拡散段階にあります。TAOエコシステムのトッププロジェクトChutesと比較すると、当日のalphaトークン価格は0.0877 TAO、保有アドレスは13,409件です。
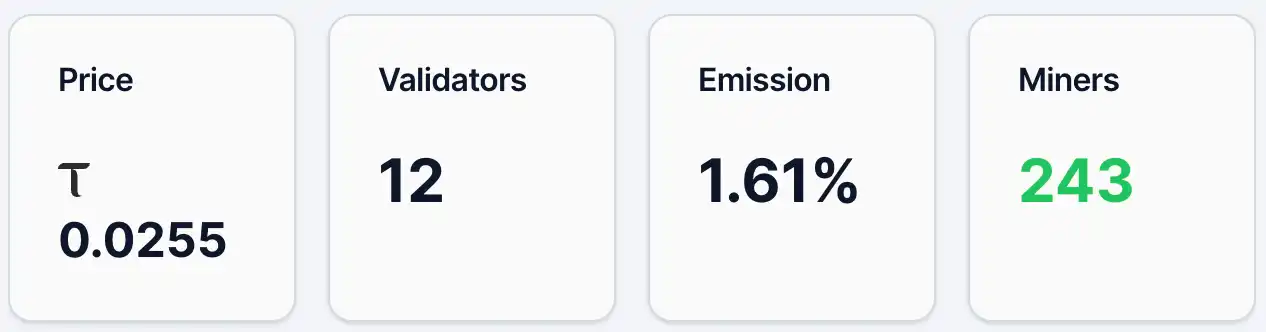
図1. グラデーションデータ。
出典:https://bittensormarketcap.com/subnets/56
次にEmissionインセンティブメカニズムです。Bittensorシステムにおいて、Emissionとは、そのサブネットがネットワーク全体の新規報酬配分において占めるリアルタイムの割合を指します。Bittensorネットワークは継続的にTAOを新規発行し、その割合を各サブネットに配分します。Gradientsの現在の1.61%は、ネットワーク全体の新規インセンティブのうち、ごく一部しか獲得していないことを意味します。この指標は本質的に、市場が資金流(例:ステーキングなど)を通じて異なるサブネットに投じた「投票結果」を反映しています。したがって、1.61%という水準は、現在の市場認知度と資金流入が比較的限定的であることを示しており、一方で、今後も割合を向上させる余地があることを意味します。資金構造(流動性プール)を見ると、TAOの割合はわずか2.19%で、Alphaは97.81%と非常に高いため、外部からの資金流入は依然として限られています。現在は主にサブネット内部の供給が主導しています。価格は新規資金の流入に対して敏感であり、より多くのTAOが流入すれば、より顕著な拡大効果が生じる可能性があります。
6. 競合状況と強み・弱み
6.1 業界ポジショニング:デセントラライズドAutoMLのトレーニングインフラストラクチャー
Gradientsは「AIトレーニングインフラ + デセントラライズドAutoML」というニッチな分野に位置づけられています。同社は、モデルトレーニングを中央集権的なプラットフォームから解放し、ネットワーク化メカニズムを通じてリソースの効率的利用とモデル最適化を実現しようとしています。Web2の枠組みでは、この分野はすでに比較的成熟しており、代表的な例としてGoogle Vertex AIやAWS SageMakerがあります。これらのプラットフォームはクラウドコンピューティングを通じて開発者にワンストップのモデルトレーニングおよびデプロイサービスを提供していますが、本質的には依然として中央集権的なアーキテクチャです。これに対して、Gradientsの差別化は「機能がより多い」ことではなく、基盤となるロジックの違いにあります。つまり、トレーニングを「プラットフォームサービス」から「ネットワーク協働」へと転換し、競争メカニズムを通じて最適な結果を抽出することで、市場メカニズムに基づくトレーニングシステムに近づけています。
6.2 横断比較:Web2 と Web3 の AutoML の違い
より広い視点から見ると、Web2とWeb3のAutoMLにおける違いは、本質的に二つの異なるパラダイムの比較である。Web2モデルは効率性と安定性を重視し、リソースを集中させ、エンジニアリングの最適化を通じて、制御可能で成熟したサービス体験を提供する。一方、Web3モデルはオープン性とインセンティブメカニズムを重視し、複数の参加者を導入することで、モデルの最適化を競争の中で継続的に進化させる。具体的には、Web2 AutoMLは「強力なツール」に似ており、ユーザーがタスクをプラットフォームに委ね、システム内部で最適解を探索する。一方、GradientsのようなWeb3 AutoMLは「オープンなマーケット」に似ており、ユーザーがニーズを公開し、さまざまな参加者が解決策を提供し、評価メカニズムを通じて結果が選別される。この違いがもたらす直接的な影響は、前者はより安定し制御可能だが、最適化の道筋が限られているのに対し、後者は探索の幅が広く、潜在的な上限が高いが、安定性と成熟度においてまだ改善の余地があることである。
6.3 Web3におけるGradientsの差別化
現在のWeb3 AI分野では、ほとんどのプロジェクトが推論層またはAIエージェントに集中しており、「トレーニングインフラストラクチャ」に焦点を当てたプロジェクトは比較的少ない。一部のプロジェクトは、計算リソースネットワークやデータネットワークを組み合わせてトレーニング機能を提供しようとしているが、全体として、多くのプロジェクトはリソーススケジューリングや計算リソースマーケットのレベルにとどまっている。Gradientsの差別化ポイントは、単に計算リソースのマッチングを提供するだけでなく、さらに上位の「モデル最適化メカニズム」そのものにまで拡張している点である。評価と競争システムを導入することで、トレーニングプロセスに継続的な進化能力をもたらしている。つまり、Gradientsは「計算リソースはどこから来るか」という問題を解決するだけでなく、「これらの計算リソースをより効率的にどう使うか」という問題にも取り組んでいる。位置づけとして、Gradientsは単なる計算リソースマーケットやツールプラットフォームではなく、「トレーニング結果志向」のネットワークに近い。これが、Gradientsと他の多くのWeb3 AIプロジェクトの核心的な違いである。
6.4 核心優位性:メカニズムによる効率向上
全体として、Gradientsの利点は主にそのメカニズム設計に現れている。まず、タスクの抽象化により使用のハードルが下がり、ユーザーは複雑なトレーニングプロセスに深く関与することなくモデルの結果を得られるため、潜在的なユーザー層が拡大する。次に、リソース面では、分散型コンピューティングの導入により、トレーニングが単一のクラウドプロバイダーに依存しなくなり、理論的には競争を通じてより弾力的なコスト構造を実現できる。さらに重要なのは、最適化手法の変化である。複数の参加者が並行して探索し、選別メカニズムと組み合わせることで、Gradientsは従来の単一パス最適化とは異なるアプローチを提供し、モデルがより短時間でより優れた性能に達する可能性を生み出している。この「競争駆動型最適化」のモデルが、その最も核心的な利点である。
6.5 潜在的な課題
モデルの品質には安定性の問題が存在する可能性があります。分散型トレーニングは複数の参加者に依存しており、上限を高める一方で、結果の変動を引き起こす可能性があり、中央集権的なシステムと比較して、制御性に一定の不確実性を伴います。次に、企業向けの信頼性の問題があります。企業ユーザーにとって、データセキュリティとトレーニングプロセスの検証可能性は極めて重要ですが、分散型環境においてデータの悪用を防ぎ、結果を監査可能にする方法は依然として重要な課題です。最後に、トークン経済への依存です。Gradientsの運用はインセンティブメカニズムに大きく依存しており、TAOの収益性が低下すれば、マイナーの参加意欲やネットワーク全体の活性度に影響を与える可能性があります。したがって、その長期的な持続可能性は、経済モデルが安定した正の循環を形成できるかどうかに一定程度依存しています。
7. 未来の展望:分散型AutoMLは実現可能か?
現在の段階では、Gradients はまだ初期段階にあり、その将来が実際に成功するかどうかは、いくつかの重要なポイントにかかっています。最も核心的なのは、インセンティブに頼った参加ではなく、真のトレーニング需要を継続的に引きつけることができるかどうかです。次に、モデルの品質であり、分散化方式が安定して使用可能な、あるいはより優れた結果を生み出せるかどうかです。そして、経済メカニズムが正のサイクルを形成し、計算リソースの供給と収益の間に長期的なバランスを保てるかどうかです。
より広い業界の文脈において、AIのトレーニングは二つの道に分かれています。一つは、大手テクノロジー企業が主導するWeb2モデルで、集中したリソースとエンジニアリング能力を通じてモデルのパフォーマンスを継続的に強化するものであり、その利点は安定性と成熟度にあります。もう一つは、GradientsのようなWeb3の道で、オープンなネットワークとインセンティブメカニズムを通じて、より多くの参加者がモデルの最適化に共同で関与し、競争の中で上限を継続的に引き上げます。前者は「より強力なシステムを構築する」ことですが、後者は「自己進化するネットワークを構築する」ようなものです。
この観点から見ると、Gradientsの探求は、AIトレーニングが単なる技術的課題ではなく、「計算リソース+データ+市場メカニズム」の統合であるという新たな可能性を示している。このモデルが成立すれば、分散型AIのトレーニング入口となり、Bittensorエコシステムにおいて重要なインフラとしての役割を果たす可能性がある。もちろん、この方向性はまだ検証に時間を要するが、既にAutoMLに従来とは異なる進化の道筋を提供している。
参照
1. Bittensor ドキュメント:https://docs.learnbittensor.org
2. Gradientsウェブサイト:https://www.gradients.io/
3. グラデーション:https://bittensormarketcap.com/subnets/56
4. Gradients X: https://x.com/gradients_ai
5.Taostats:https://taostats.io/subnets/56/chart