









著者:深潮 TechFlow
先週、AIのメモリ使用量を1/6に圧縮すると称する論文が発表され、マイクロンやサンディスクを含む世界のストレージチップ株の時価総額が900億ドル以上減少した。
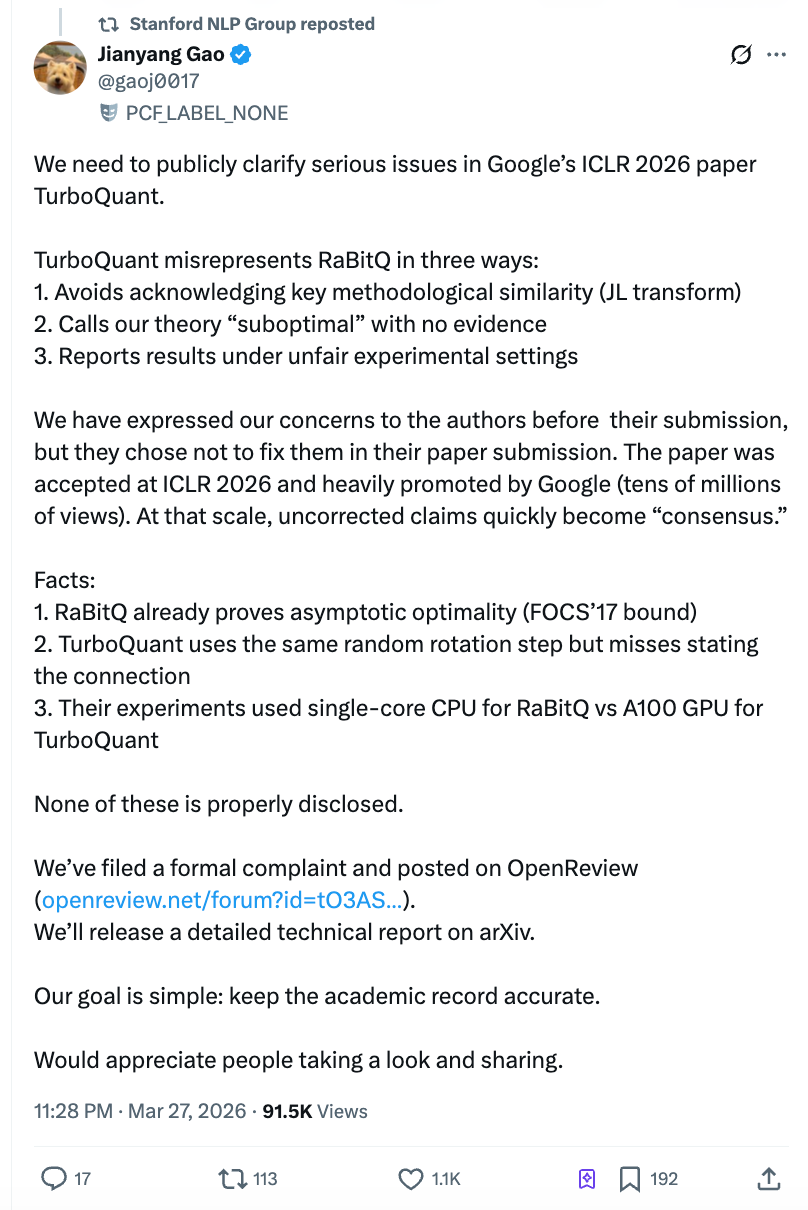
しかし論文が公開されてからたった2日後、アルゴリズムが「圧倒」とした対照グループであるチューリッヒ工科大学のポスドク、高健揚が1万字の公開書簡を発表し、グーグルチームが実験で相手側にはシングルコアCPUのPythonスクリプトを使用し、自らはA100 GPUを使用していたことを非難し、投稿前に問題を指摘されたにもかかわらず修正を拒否したと主張した。知乎での閲覧数は直ちに400万を突破し、Stanford NLPの公式アカウントが転載したことで、学術界と市場が同時に衝撃を受けた。
(参照: 一篇论文,把存储股打了下去)
この論争の核心はそれほど複雑ではない:グーグル公式が大規模に推奨し、全球のチップ株式市場にパニック売却を引き起こしたAIトップ会議の論文は、既に発表された先行研究を体系的に歪め、意図的に不公平な実験を設けて虚偽の性能優位性の物語を構築したのか?
TurboQuantが行ったこと:AIの「下書き用紙」を元の6分の1に薄くした
大規模言語モデルは回答を生成する際、これまでに計算した内容を都度確認しながら書き進めます。これらの途中結果は一時的にVRAMに保存され、業界では「KV Cache」(キー・バリュー・キャッシュ)と呼ばれています。対話が長くなるほど、この「下書き用紙」は厚くなり、VRAMの消費量とコストも増加します。
Google研究チームが開発したTurboQuantアルゴリズムの主な特徴は、このスケッチを元の1/6に圧縮し、精度の損失なしに推論速度を最大8倍まで向上させることです。この論文は2025年4月に学術プレプリントプラットフォームarXivで初めて公開され、2026年1月にAI分野のトップ会議ICLR 2026に採択され、3月24日にGoogle公式ブログによって再パッケージされて広く紹介されました。
技術的に見ると、TurboQuantの考え方を簡単に説明すると、まず数学的変換を用いて乱雑なデータを統一された形式に「洗い」、次に事前に計算された最適な圧縮テーブルを用いて個々に圧縮し、最後に1ビットの誤り訂正メカニズムで圧縮に伴う計算偏差を修正するというものです。コミュニティによる独立実装により、その圧縮効果はほぼ事実であることが検証されており、アルゴリズムレベルでの数学的貢献は実在します。
問題はTurboQuantが使えるかどうかではなく、Googleがそれを「競合他社をはるかに上回る」と証明するために何をしたかにある。
高健揚の公開書簡:3つの指摘、すべてが核心を突いている
3月27日22時、高健揚は知乎に長文を投稿し、同時にICLR公式査読プラットフォームOpenReviewに正式なコメントを提出しました。高健揚はRaBitQアルゴリズムの第一著者であり、このアルゴリズムは2024年にデータベース分野のトップ会議SIGMODで発表され、高次元ベクトルの効率的な圧縮という同一の課題を解決しています。
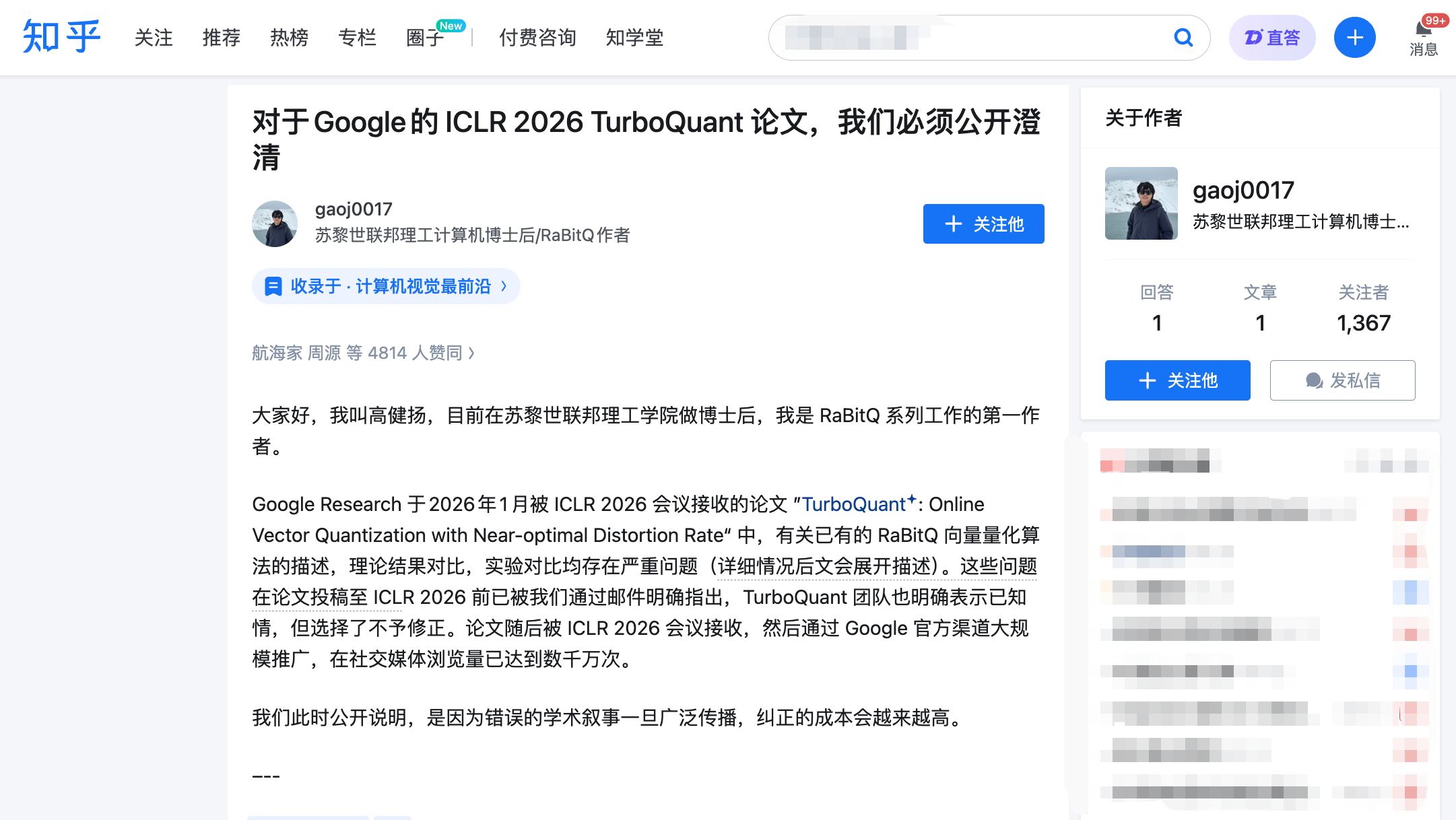
彼の主張は3つに分かれ、それぞれにメール記録とタイムラインが裏付けられています。
主張1:他人のコア手法を使用し、全文で一切言及していない。
TurboQuantとRaBitQの技術的コアには、データを圧縮する前に「ランダム回転」を施すという重要な共通ステップがあります。この操作は、不規則に分布したデータを予測可能な均一分布に変換し、圧縮の難易度を大幅に低下させます。これは、両方のアルゴリズムで最も核心的で最も近い部分です。
TurboQuantの著者自身は査読返信でこの点を認めているが、論文全文ではこの手法とRaBitQとの関連を明確に述べていない。さらに重要な背景として、TurboQuantの第二著者Majid Daliriは2025年1月、RaBitQのソースコードを基に改変したPython版のデバッグを高健揚チームに依頼した。メールには再現手順とエラー情報が詳細に記載されていた——つまり、TurboQuantチームはRaBitQの技術的詳細を深く理解していた。
ICLRの匿名査読者の一人は、両者が同じ技術を使用していることを独立して指摘し、十分な議論を求めていた。しかし、最終版の論文において、TurboQuantチームは議論を追加せず、もともと本文中にあったRaBitQに関する(すでに不完全な)記述を付録に移動させた。
主張2:根拠なく相手の理論を「次善」と称する。
TurboQuantの論文は、RaBitQの数学的分析が「粗雑」であるとして、RaBitQに「理論的に次最適」(suboptimal)というラベルを貼った。しかし、高健揚は、RaBitQの拡張版論文が、圧縮誤差が数学的最適限界に達することを厳密に証明しており、この結論は理論計算機科学のトップ会議で発表されたと指摘した。
2025年5月、高健揚チームは複数回のメールでRaBitQ理論の最適性を詳細に説明した。TurboQuantの第二著者Daliriは、全著者に通知したことを確認した。しかし、論文は最終的に「準最適」という表現をそのまま残し、反論の根拠を一切示さなかった。
主張三:実験比較において「左手で人を拘束、右手で刃物を保持」。
これは全文で最も致命的な点です。高健揚は、TurboQuantの論文が速度比較実験で二重の不公平な条件を重ねていたと指摘しました。
第一に、RaBitQの公式チームは最適化されたC++コード(デフォルトでマルチスレッド並列処理をサポート)を提供していますが、TurboQuantチームはそれを使用せず、自ら翻訳したPython版を使用してRaBitQをテストしました。第二に、RaBitQのテストはシングルコアCPUでマルチスレッドを無効にして実施されましたが、TurboQuantはNVIDIA A100 GPUを使用しました。
これらの条件が重なる結果として、読者は「RaBitQはTurboQuantより数桁遅い」という結論を読み取るが、その結論の前提が、Googleチームが相手を手足を縛った状態で走らせた競争であることを知る由もない。論文では、これらの実験条件の差異が十分に開示されていない。
Googleの返答:「ランダム回転は汎用技術であり、すべての論文に引用することは不可能です」
高健揚によると、TurboQuantチームは2026年3月のメールの返信で、「ランダムローテーションとJohnson-Lindenstrauss変換の使用は、この分野での標準的な技術であり、これらの手法を使用したすべての論文を引用することは不可能です。」と述べました。
高健揚チームは、これは概念のすり替えであると考えている:問題は、すべてのランダム回転を用いた論文を引用するかどうかではなく、RaBitQ が完全に同じ問題設定において、この手法をベクトル圧縮と初めて組み合わせ、その最適性を証明した作品であるという点であり、TurboQuant 論文は両者の関係を正確に記述すべきである。
スタンフォードNLPグループの公式Xアカウントが、高健揚の声明を転載しました。高健揚チームはICLR OpenReviewプラットフォームに公開コメントを掲載し、ICLR大会の議長および倫理委員会に正式な抗議を提出しました。今後、arXivに詳細な技術レポートを公開する予定です。
独立技術ブロガーのDario Salvatiは、分析の中で比較的中立的な評価を示しました:TurboQuantは数学的アプローチにおいて確かに実質的な貢献をしているが、RaBitQとの関係は論文で述べられているよりもはるかに密接である。
時価総額900億ドルが消滅:論文論争と市場のパニックが重なる
この学術的論争が発生した時期は非常に繊細である。Googleが3月24日に公式ブログでTurboQuantを発表した後、世界中のストレージチップセクターは激しい売却に見舞われた。CNBCなどの複数のメディアによると、マイクロンテクノロジーは連続6取引日下げ、累計で20%以上下落した。SanDiskは1日で11%下落し、韓国のSKハイニックスは約6%、サムスン電子は近い5%下落、日本のキオクシアは約6%下落した。市場のパニックのロジックは単純明快である:ソフトウェア圧縮によりAI推論のメモリ需要が6倍削減され、ストレージチップの需要見通しが構造的に下方修正されると考えられた。
モルガン・スタンレーのアナリスト、ジョセフ・ムーアは3月26日のレポートでこの論理に反論し、マイクロンおよびサンディスクの「買い」評価を維持した。ムーアは、TurboQuantが圧縮するのはKVキャッシュという特定のキャッシュタイプに限定され、全体のメモリ使用量ではないと指摘し、これを「通常の生産性向上」と評価した。ウェルズ・ファーゴのアナリスト、アンドリュー・ロチャもジェブンズのパラドックスを引用し、効率の向上によりコストが低下すると、逆にAIの導入規模が拡大し、結果としてメモリ需要が増加する可能性があると述べた。
古い論文、新しいパッケージ:AI研究から市場ナラティブへの伝導チェーンリスク
技術ブロガーのBen Pouladianの分析によると、TurboQuantの論文は2025年4月にすでに公開されており、新規の研究ではない。3月24日、Googleは公式ブログを通じて再パッケージしてプロモーションを行ったが、市場はこれを新たなブレイクスルーとみなして価格を付けた。この「旧論文、新発表」のプロモーション戦略と、論文に含まれる可能性のある実験バイアスは、AI研究が学術論文から市場のナラティブへと伝達される過程におけるシステムリスクを浮き彫りにしている。
AIインフラ投資家にとって、論文が「数桁の性能向上」を達成したと主張する際、まず最初に問うべきは、ベンチマーク比較の条件が公平であるかどうかである。
高健揚チームは、問題の正式な解決を引き続き推進すると明言しています。グーグル側は公開書簡の具体的な指摘に対してまだ正式な返答をしていません。