









DeepSeek V4がついにリリースされました。これは約5か月間待ち望まれた瞬間です。1TパラメータのMoEメインモデルと285BパラメータのFlash版に加え、合計1.6TパラメータのPro版が続いた後、GitHub上で完全にオープンソース化され、Apache 2.0ライセンスのもとで重みとデプロイコードが同時に公開されました。
モデルが完成すると、資本市場は三つの独立しながらも互いに連動する方法で回答を示した。
資本市場の異なる反応
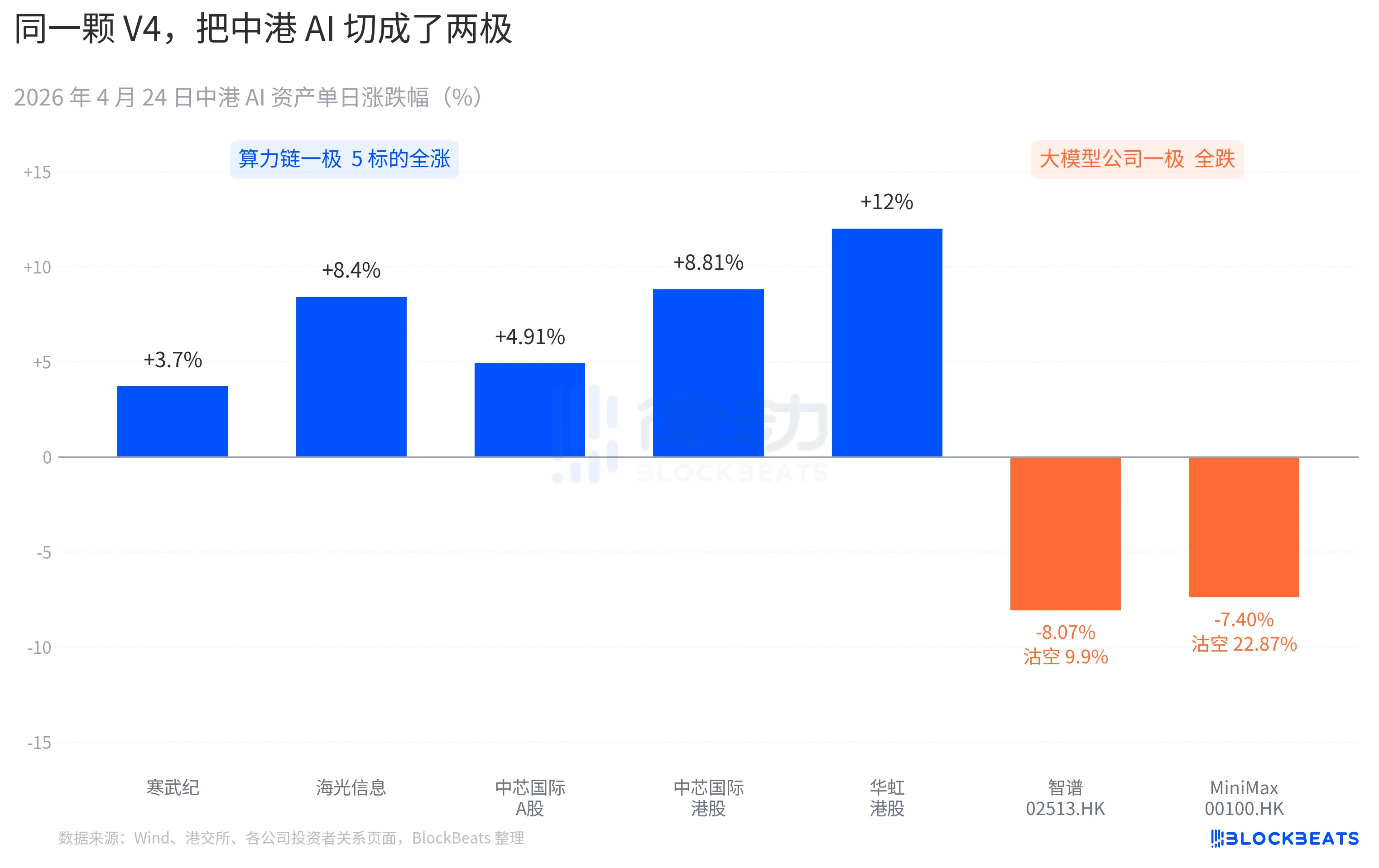
A株の計算力チェーンはほぼ全線で急騰しました。寒武紀は11日連続の陽線を記録し、1日当たり3.7%上昇、今月の累計上昇率は60%を超えました。海光情報は取引中に10%のストップ高に達し、終値は+8.4%でした。中芯国際のA株は+4.91%、香港株は+8.81%上昇しました。華虹の香港株は最高で+18%まで上昇し、終値は+12%でした。科学技術チャイナ半導体国泰ETFは1日で24億元を吸収し、規模は過去最高水準に達しました。
香港市場の大規模モデル企業は別の色合いを見せている。智谱(02513.HK)は8.07%下落し、空売り比率は9.9%。MiniMax(00100.HK)は7.40%下落し、空売り比率は22.87%まで急騰した。後者は過去3か月で香港市場のAIセクターで最も高い単日空売りデータである。这两家公司都是2025年下半年香港AI上市潮的代表,IPO招股书中写的核心竞争力是同一句话,「自研基座大模型」。
太平洋の反対側でも反応は同様に明確だった。ナビダは4月24日に1.8%安で始まり、取引中には最大で-2.6%まで下落したが、終値は横ばいとなった。ブルームバーグの市場速評は、この調整を1月27日のV3「DeepSeekの瞬間」と比較した。違いは、1月の場合はパニック売却で1日で6,000億ドルの時価総額が吹き飛んだのに対し、今回は再評価に近いもので、規模は控えめだが方向性は明確だった。買い手機関の研究メモには、「中国のAI推論需要が北米のAI推論需要から分離し始めた」という新たな表現が登場した。
この3つのチャートを重ねると、V4がリリースされてから24時間以内に市場が書き下した最初の判決書となる。オープンソースが勝利した後、資金は再び陣営を選び始め、モデルそのものではなく、そのモデルがどのGPU上で動作し、どの産業チェーンに組み込まれているかが価格を決定するようになった。
30日間で11の新モデル、V4がオープンソース陣営に火をつける
V4のリリースタイムウィンドウ自体が、この反応が拡大された理由の一部である。
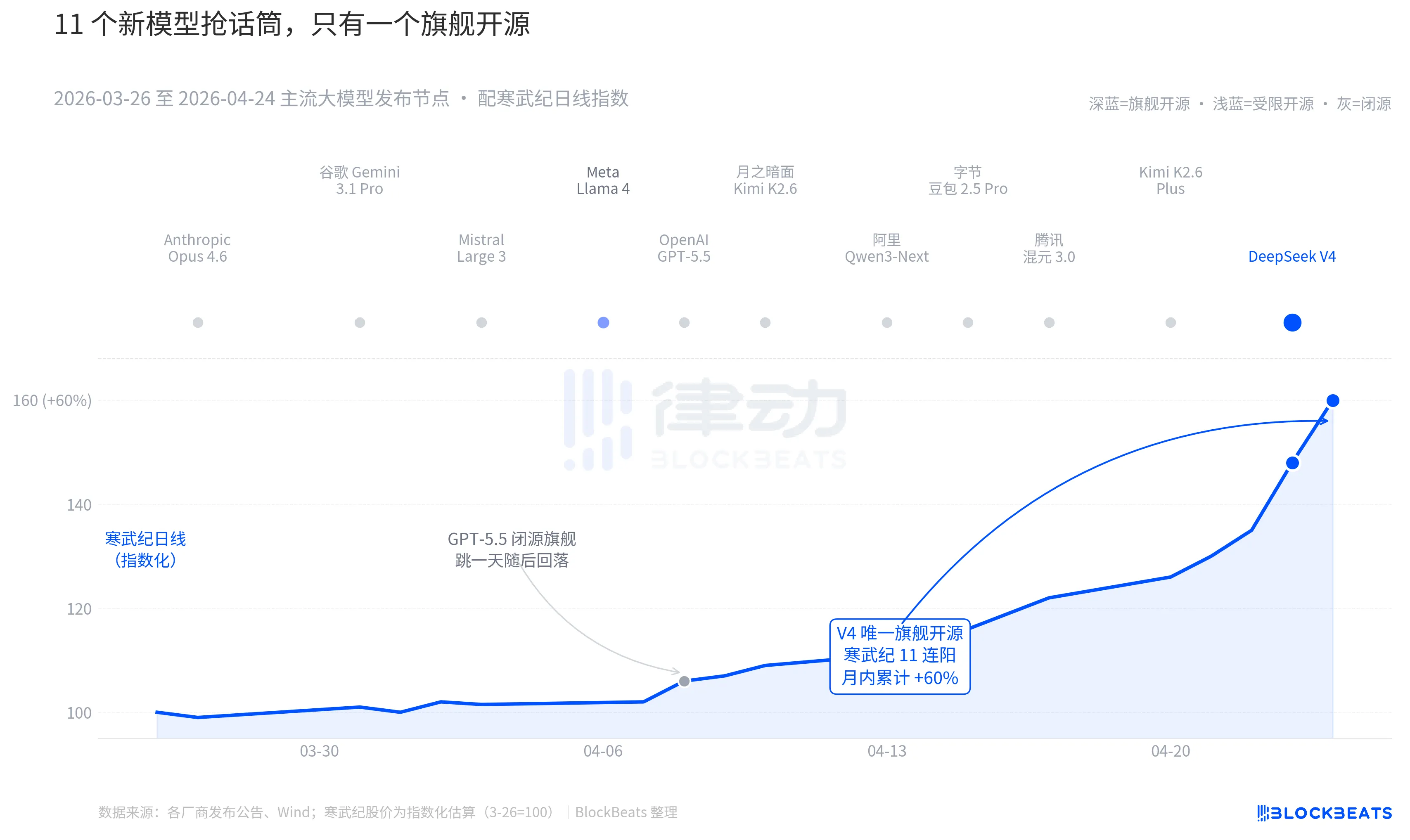
過去30日間、3月26日から4月24日までの間に、世界で少なくとも11の注目すべき大規模モデルがリリースまたは大幅に更新され、そのリストには主要なプレイヤーがほぼすべて含まれています。Anthropic Opus 4.6、Google Gemini 3.1 Pro、OpenAI GPT-5.5、Mistral Large 3、Meta Llama 4、月之暗面 Kimi K2.6、阿里 Qwen3-Next、字節豆包 2.5 Pro、騰訊混元 3.0、Kimi K2.6 Plus、そして4月23日未明にリリースされたDeepSeek V4。
平均して2.7日ごとに新しいモデルが登場している。これはファンドマネージャーですらリリース文を読み切れない速さだ。しかし、この30日間の中国・香港AI資産のK線を振り返ると、価格チャートに持続的な痕跡を残したのはたった一つの名前だけだ。4月8日のGPT-5.5はナスダックのNVIDIAを単日4.2%上昇させ、その日で高値を付けた。その後、4月23〜24日のDeepSeek V4が中国・香港の計算能力チェーンを連続的なジャンプ上昇へと導いた。
差異はモデルの能力そのものにはない。この11のモデルはLMArenaランキングで、ほとんどの場合50点以内の差であり、「同じ階級」の狭い範囲に位置している。差異は二つの要因の重なりにある。
最初の一件はオープンソースです。上位10モデルのうち、Llama 4 のみがオープンソースでしたが、Llama 4 の重みプロトコルには長大な商用制限条項が付随し、欧米の開発者コミュニティからの評価は冷ややかで、OpenRouter では3日目には上位10から外れました。V4のプロトコルはApache 2.0で、重みに制限はなく、商用利用に制限がなく、推論コードも同時に公開されています。これは過去半年で、閉源陣営が性能、価格、オープン性の3つの側面で同時に圧力を受ける最初のフラッグシップオープンソースモデルです。
二つ目はタイミングだ。閉源陣営が次々と強力な手を打つ中、オープンソースのナラティブは繰り返し圧力を受けている。Opus 4.6はコードタスクのSWE-Benchを新記録に引き上げ、GPT-5.5は100万トークンあたり1.25ドルという下限のアンカーを設定した。オープンソースが閉源に追いつけるかどうかという議論は、シリコンバレーですでに2年間続いてきた。V4は1か月のアクティブユーザー予測で9000万人に達し、この議論に一時停止ボタンを押した。
ある国内大手ファンドマネージャーのルーピングでの発言によると、「V4以前、我々はオープンソースの大規模モデルに割引を適用していたが、V4以降、この割引が逆に適用され始めた。」
DeepSeekが計算能力サプライチェーンの価格表を変更しました
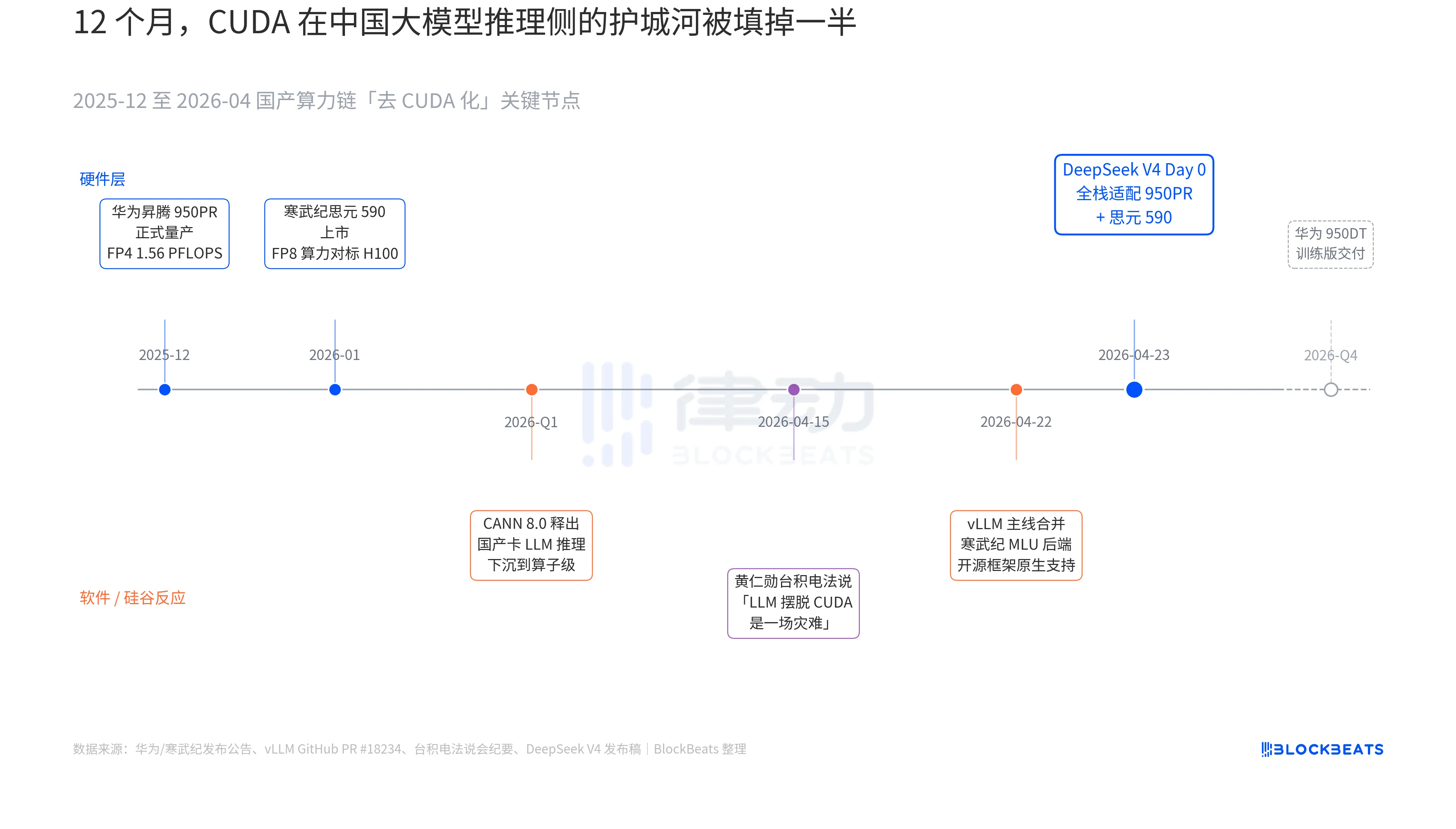
V4リリースノートには、これまで中国のどの大規模モデルの公式ドキュメントにも記載されていなかった一行がある:「Day 0 で全スタックを寒武紀思元590および华为昇騰950PRに最適化し、デプロイコードをオープンソースとして公開。」この一行の重みを理解するには、過去12ヶ月間に並行して展開された3つの暗黙の線を結びつける必要がある。これらの3つの線は、ハードウェア、ソフトウェア、そしてシリコンバレーの反応にそれぞれ属している。
最初の裏技はチップ側にある。華為昇騰950PRは2025年12月に本格量産を開始し、FP4演算能力は1.56 PFLOPS、HBM容量は112GBで、中国製AIチップとして初めてハードウェア指標でNVIDIA Bシリーズと対等に競合する。V4のような1TパラメータのMoE推論タスクにおいて、1枚のカードのスループットはH20と比較して2.87倍向上した。対応するCANN 8.0ソフトウェアスタックは、LLM推論フレームワークの最適化をオペレータレベルまで深くまで押し下げており、DeepSeekが公開したベンチマークによると、V4は昇騰スーパーノード(8枚の950PR)上で同等規模のH100クラスタと比較してエンドツーエンド推論遅延が35%低減している。寒武紀思元590のデータはさらに大胆で、単一チップのFP8演算能力はH100と対等であり、価格はその半分以下である。
第二の暗黙の道はソフトウェア側にある。vLLMのメインラインは4月22日に寒武紀MLUバックエンドのPRをマージし、オープンソース推論フレームワークとして初めてNVIDIA以外の国内GPUをネイティブにサポートした。海光情報のDCUはROCmエコシステムを通じて別の道を歩んでいるが、V4のMoEルーティングレイヤーを完全に実行可能である。これはV4のデプロイが「特定の国内GPUでのみ実行可能」という制約から、「複数の国内GPUから選択可能」という状態へと移行したことを意味する。エコシステムが単一ベンダーへの依存から脱却したことは、本番環境における重要な転換点である。
第三の暗線はシリコンバレーから。4月15日、黄仁勲は台積電の法説会でアナリストから中国国内の計算能力の進展について問われ、その回答は冷たく具体的だった。「もし彼らが本当にLLMをCUDAから解放できれば、それは私たちにとって災難(a disaster)だ。」そして9日後、DeepSeekはDay 0の公告でその答えを提示した。
「国産代替」という言葉は、過去3年間で使いすぎられ、意味を失ってしまった。しかし、4月24日午前以降、この出来事は初めて資本市場で評価可能な具体的なデータを手にした。単一GPUのスループット、エンドツーエンドの推論遅延、推論コスト、商用展開可能なコードが、静かにこの長きにわたる言説戦を本格的な実用段階へと押し込んだ。
寒武紀の株価が11日連続で上昇している背景には、ここに隠されている。それはもはや「国内GPU概念株」ではなく、「DeepSeek V4 推論インフラサプライヤー」である。同じロジックで、華虹の香港株式が12%上昇した理由も説明できる。彼女が製造するのは950PRの7nm相当プロセスだ。中国製昇騰上で動作するV4トークン1つにつき、原本としてNVIDIAおよびTSMCに流向していた生産能力の一部が、珠江デルタ地域に留まることを意味する。
次のステップはすでに準備されている。華為のロードマップでは、950DT(トレーニング版)は2026年第四四半期に提供される予定であり、目標は「1万枚のGPUクラスタでのV5または同等規模モデルのフルスタックトレーニング」である。この道が成功すれば、CUDAは中国の大規模モデルトレーニング分野における競争優位性を「必須」から「選択肢の一つ」に引き下げるだろう。
出典:律動 BlockBeats