










原文:KarenZ、Foresight News
2026年3月20日、All-In ベンチャーキャピタルのポッドキャストで、異例の会話が繰り広げられた。
ベンチャーキャピタリストのチャマス・パリハピティヤは、エヌビディアのCEOであるジェンセン・ホアンに話題を渡し、Bittensor上にあるプロジェクトが、分散型コンピューティングを用いてインターネット上で大規模言語モデルを訓練し、完全にデセントラライズドなプロセスで、いかなる中心化されたデータセンターも関与せずに「非常に狂気的な技術的成果」を達成したと語った。
黄仁勲は回避しなかった。彼はこれを、2000年代に一般ユーザーが余剰コンピューティングリソースを提供してタンパク質の折りたたみの課題に立ち向かうために行われた分散型プロジェクト「Folding@home」の現代版に例えた。
4日前の3月16日、Anthropicの共同創設者であるJack Clarkは、AI研究進展レポートの中で、この画期的な成果を大幅に紹介・引用した。BittensorエコシステムのサブネットTemplar(SN3)が、720億パラメータの大型モデル(Covenant 72B)の分散学習を完了し、そのモデル性能はMetaが2023年に発表したLLaMA-2と同等である。
ジャック・クラークはこの章を「分散トレーニングを通じたAI政治経済への挑戦」と名付け、分析の中で、これは継続的に注目すべき技術であると強調した。彼は、エッジデバイスで分散トレーニングによって生成されたモデルが広く採用され、クラウド上のAIは引き続き独占的な大規模モデルを実行する未来を想像できる。
市場の反応は若干遅れたが、非常に劇的だった:SN3は過去1か月で440%以上上昇し、過去2週間で340%以上上昇し、時価総額は1億3千万ドルに達した。サブネットのナラティブの爆発は、直接TAOの購入圧力として伝わる。そのため、TAOは急騰し、一時377ドルに達し、過去1か月で2倍になり、FDVは約75億ドルに達した。
問題が浮上:SN3は具体的に何をしたのか?なぜ注目の的となったのか?分散型トレーニングとデセントラライズドAIの価値ナラティブは今後どのように進化するのか?
その72Bのモデル
この質問に答えるには、SN3が提出した成績表をよく見なければなりません。
2026年3月10日、Covenant AIチームはarXiv上で技術レポートを公開し、Covenant-72Bのトレーニングを完了したことを正式に発表しました。これは720億パラメータを有する大規模言語モデルで、約1.1兆トークンのコーパス上で、70以上の独立したノードピア(1ラウンドあたり約20ノードが同期、各ノードにはB200が8枚搭載)を用いて事前学習が実施されました。
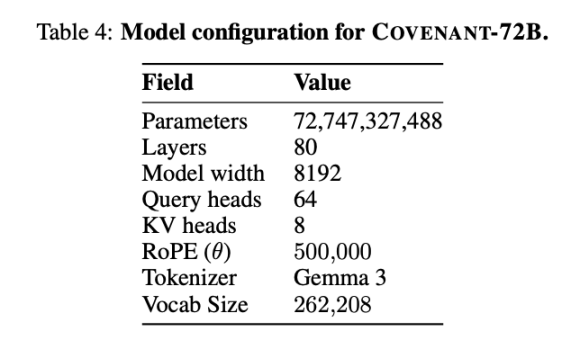
Templarはベンチマークに関するいくつかのデータを提示しました。ただし、比較対象のLLaMA-2-70BはMetaが2023年にリリースした大規模モデルです。Anthropicの共同創業者であるJack Clarkが述べたように、Covenant-72Bは2026年にはやや古くなっている可能性があります。Covenant-72BのMMLUスコア67.1は、Metaが2023年にリリースしたLLaMA-2-70B(65.6点)とおおむね同等です。
一方、2026年の最先端モデル——GPTシリーズ、Claude、Geminiのいずれも——はすでに数十万枚のGPUを用いて、パラメータ数が1000億をはるかに超える学習を完了しており、推論、コード、数学の能力の差はパーセンテージではなく、桁違いの問題である。この現実の差は、市場の感情に埋もれてはならない。
しかし、「オープンインターネット上の分散型コンピューティングパワーでトレーニングされた」という前提に換算すると、意味はまったく異なります。
比較してみましょう:同じく分散学習されたINTELLECT-1(Prime Intellectチーム開発、100億パラメータ)のMMLUスコアは32.7です。一方、ホワイトリスト参加者を対象とした分散学習プロジェクトPsyche Consilience(400億パラメータ)のスコアは24.2です。Covenant-72Bは72BのスケールでMMLUスコア67.1を記録し、分散学習分野で目立つ数値を達成しています。
さらに重要なのは、このトレーニングが「許可不要」であることです。誰でも事前の審査やホワイトリストなしで参加ノードとして接続できます。70以上もの独立したノードが、世界中から接続して計算リソースを提供しました。
黄仁勋が言ったこと、言わなかったこと
そのポッドキャストの対話の詳細を再現することで、この「推奨」に対する外部の解釈を修正するのに役立ちます。
チャマス・パリハピティヤは対話の中で、Bittensorの技術的成果を黄仁勲に提示し、分散された計算リソースを用いてLlamaモデルをトレーニングしたことを、「完全に分散され、状態を維持しながら」行われたと説明した。黄仁勲の返答は、これを「現代版のFolding@home」と比較し、オープンソースモデルとプロプライエタリモデルが並存する必要性について議論を展開した。
注目すべきは、黄仁勲がBittensorのトークンや任何の投資的含意に直接言及せず、分散型AIトレーニングについてもさらに議論しなかったことです。
Bittensor サブネットと SN3 を理解する
SN3のブレイクスルーを理解するには、まずBittensorとそのサブネットの動作ロジックを明確に理解する必要があります。簡単に言えば、BittensorはAIパブリックチェーンおよびプラットフォームであり、各サブネットは独立した「AI生産ライン」として、それぞれ明確な核心タスクとインセンティブメカニズムを備え、分散型AIエコシステムを構成しています。
その運用プロセスは明確でデセントラライズされています:サブネット所有者がサブネットの目標を定義し、インセンティブモデルを構築します。マイナーはサブネット内で計算リソースを提供し、推論、トレーニング、ストレージなどのAI関連タスクを完了します。バリデーターはマイナーの貢献度を評価し、そのスコアをBittensorコンセンサス層にアップロードします。最終的に、BittensorのYumaコンセンサスアルゴリズムは、各サブネットに累積された報酬に基づいて、サブネット参加者に適切な収益を分配します。
現在、Bittensorには128のサブネットがあり、推論、サーバーレスAIクラウドサービス、画像、データアノテーション、強化学習、ストレージ、計算など、さまざまなAIタスクをカバーしています。
そしてSN3はそのサブネットの一つです。アプリケーション層のラッピングを行わず、既存の大規模モデルAPIをレンタルすることもなく、AI産業チェーンで最も高価で閉鎖的な核心部分の一つである、大規模モデルの事前学習そのものに焦点を当てています。
SN3は、Bittensorネットワークを活用して非同質な計算リソースを分散型で調整し、インセンティブに基づく分散型大規模モデル訓練を通じて、高額な中央集権型スーパーコンピュータクラスタがなくても、強力な基礎モデルを訓練できることを実証します。その核心的な魅力は「平等化」にあります——中央集権的な訓練によるリソースの独占を打破し、一般個人や中小機関も大規模モデルの訓練に参加できるようにし、分散型計算力によって訓練コストを削減します。
SN3の発展を推進する中心的な力はTemplarであり、その背後にはCovenant Labsという研究チームがいます。同チームは、別々のサブネットであるBasilica(SN39、計算サービスに特化)とGrail(SN81、RL後トレーニングとモデル評価に特化)も運営しています。この3つのサブネットは垂直統合を実現し、大規模モデルの事前学習からアライメント最適化までの全プロセスをカバーすることで、分散型大規模モデルトレーニングの完全なエコシステムを構築しています。
具体的には、マイナーが計算リソースを提供し、勾配更新(モデルパラメータの調整方向と強度)をネットワークにアップロードします。バリデーターは各マイナーの貢献の質を評価し、誤差の改善度に応じてチェーン上のスコアを付与します。その結果が報酬の重みを決定し、第三者を信頼することなく自動的に配分されます。
インセンティブ設計の鍵は、単なる計算力の出勤ではなく、「あなたの貢献がモデルをどれだけ改善したか」に報酬を直接連動させることです。これにより、分散型環境で最も難しい課題、つまりマイナーの手抜きを防ぐ問題が本質的に解決されます。
Covenant-72Bは、通信効率とインセンティブ適合性の問題をどのように解決しますか?
信頼できない数十のノードが、ハードウェアが異なり、ネットワーク品質もまちまちである中で、同じモデルを共同で学習させるには、二つの課題がある。一つ目は通信効率であり、標準的な分散学習手法では、ノード間で高帯域幅かつ低遅延の接続が求められる。二つ目はインセンティブの整合性であり、悪意のあるノードが誤った勾配を送信するのをどう防ぐか、また各参加者が他人の結果を模倣するのではなく、真面目に学習していることをどう保証するかである。
SN3は、SparseLoCoとGauntletの2つのコアコンポーネントにより、これらの課題を解決します。
SparseLoCoは通信効率の問題を解決します。従来の分散学習では、各ステップで完全な勾配を同期する必要があり、データ量が膨大です。SparseLoCoは、各ノードがローカルで30ステップの内部最適化(AdamW)を実行した後、生成された「疑似勾配」を圧縮して他のノードにアップロードする方式を採用しています。圧縮方法には、Top-kスパース化(最も重要な勾配成分のみを保持)、エラーフィードバック(削除された部分を保存し次回のステップに累積)、および2ビット量子化が含まれます。最終的な圧縮率は146倍以上です。
つまり、以前は100MBを送信する必要があったものが、今では1MB未満で十分です。
これにより、システムは通常のインターネット(アップロード 110Mbps、ダウンロード 500Mbps)の帯域幅制限下で、計算利用率を約94.5%に維持します——20ノード、各ノードにB200を8枚、1ラウンドの通信にかかる時間はわずか70秒。
Gauntletはインセンティブ適合性の問題を解決します。これはBittensorブロックチェーン(サブネット3)上で動作し、各ノードが提出する擬似勾配の品質を検証します。具体的には、小さなデータバッチを使って「そのノードの勾配を用いた場合、モデルの損失がどれだけ低下したか」をテストし、その結果をLossScoreと呼びます。また、システムはノードが自身に割り当てられたデータで学習しているかを確認します。もしあるノードがランダムデータでの損失改善が、自身に割り当てられたデータでの改善よりも優れている場合、負のスコアが与えられます。
最終的に、各ラウンドの訓練では、スコアが最も高いノードの勾配のみが集約に参加し、他のノードはそのラウンドから除外されます。追加の参加者は随時補充され、システムの安定性を維持します。訓練全体を通じて、平均して各ラウンドで16.9個のノードの勾配が集約に取り込まれ、累計で70個以上の固有ノードIDが参加しました。
デcentralized AIの価値ナラティブが根本的に変化しています
技術的および業界の観点から見ると、Covenant-72Bが示す方向性にはいくつかの実際的な意味があります。
まず、「分散トレーニングは小規模モデルにのみ適している」という前提を打破了した。最新モデルにはまだ及ばないが、この方向性の拡張可能性を実証した。
第二に、許可なしでの参加は現実的に可能である。この点は過小評価されている。これまでの分散学習プロジェクトはホワイトリストに依存しており、審査を通過した参加者のみが計算リソースを提供できた。しかし、SN3の今回の学習では、十分な計算リソースを保有する誰でも参加でき、検証メカニズムが悪意のある貢献をフィルタリングする。これは「真の分散化」への具体的な一歩である。
第三に、BittensorのdTAOメカニズムは、サブネットの価値に対する市場発見を可能にします。dTAOは各サブネットが独自のAlphaトークンを発行し、AMMメカニズムを通じて市場がどのサブネットにより多くのTAOを配分するかを決定できるようにします。これにより、SN3のような具体的な成果を生み出したサブネットには、粗削りながらも効果的な価値獲得メカニズムが提供されます。ただし、このメカニズムは物語や感情の影響を受けやすく、LLMの訓練成果の品質は一般の市場参加者にとって独立して評価することが困難です。
第四に、分散型AIトレーニングの政治経済的含意。Jack ClarkはImport AIでこの問題を「誰がAIの未来を所有するか」というレベルまで引き上げた。現在の最先端モデルのトレーニングは、大規模なデータセンターを保有する少数の機関によって独占されており、これは単なる商業的問題ではなく、権力構造の問題でもある。分散型トレーニングが技術的に継続的に進展すれば、特定の分野における小規模な最先端モデルなど、いくつかのモデルタイプにおいて、真に分散型の開発エコシステムが形成される可能性がある。ただし、この見通しは現在のところまだ遠い。
まとめ:真のマイルストーンと、多くの真の課題
黄仁勲は、これは「現代版のFolding@home」だと述べた。Folding@homeは分子シミュレーション分野で実際の貢献を果たしたが、大手製薬企業の核心的な研究開発の地位を脅かすことはなかった。この類推は非常に正確である。
SN3はプロトコルを実行し、分散学習の実現可能性を検証しました。しかし、技術的および業界の観点から見ると、この成績の裏には、ほとんど誰も真剣に議論したがらない多くの問題が存在します。
MMLU自体も学界で議論の的となっている指標であり、公開ベンチマークの問題と解答がトレーニングセットに漏洩するリスクがある。さらに注目すべきは比較基準の選定である:本論文で対比されているLLaMA-2-70BとLLM360 K2はいずれも2023〜2024年の旧モデルであり、同じ65〜70点のスコアは、Grokや豆包を対象とした場合、中下位〜入門レベルと評価され、Claudeの観点では深刻な遅れと見なされる。これを動的に更新されるランキングや汚染耐性を備えた次世代ベンチマークに適用すれば、結論はより誠実なものとなるだろう。
より重要なのは、モデルの能力の上限を決定する高品質なデータ—会話データ、コード、数学的導出、科学文献—は、大手企業、出版機関、学術データベースがほぼ独占しているということである。計算リソースは民主化されたが、データ側は依然として寡頭構造であり、この矛盾はこれまで議論されていない。
セキュリティの観点から、許可なしの参加とは、その70以上のノードの正体が誰であるか、またどのようなデータで学習しているかが不明であることを意味します。Gauntletは明らかに異常な勾配をフィルタリングできますが、繊細なデータポイズニングには対応できません。たとえば、あるノードが特定の有害コンテンツの方向に体系的に複数ラウンド追加で学習した場合、その勾配の変化は非常に微細であり、損失スコアのスクリーニングを通過する可能性がありますが、モデルの行動に累積的なバイアスをもたらします。最終的な課題は、金融、医療、法律など、高いコンプライアンスとセキュリティ要件が求められるシナリオにおいて、少数の匿名ノードによって学習され、データソースの追跡が不完全なモデルを使用することによるリスクは何でしょうか?
もう一つ、明確に指摘すべき構造的な問題があります:Covenant-72B は Apache 2.0 ライセンスでオープンソース化されており、SN3 トークンは使用されていません。SN3 トークンを保有することは、モデルの利用による直接的な収益ではなく、このサブネットが今後継続的に新しいモデルを生成することによって生じるエミッション収益を共有することを意味します。この価値連鎖は、継続的なトレーニング出力と、Bittensor ネットワーク全体のエミッションメカニズムの健全な運用に依存しています。今後のトレーニングが停滞したり、新たなトレーニング成果の品質が期待に応えられなかった場合、トークンの評価ロジックは揺らぎます。
これらの質問を挙げるのは、Covenant-72Bの意義を否定するためではない。これまで不可能だと考えられていたことが実現可能であることを証明したという事実は、決して消えない。しかし、実現したということと、それが何を意味するかとは、別の話である。
SN3トークンは過去1か月で440%上昇しました。この差は単なる投機ではなく、物語の進行速度が現実を常に上回っているからかもしれません。この差が現実によって埋められるか、市場の修正によって吸収されるかは、Covenant AIチームが今後実際に何を提示するかにかかっています。
注目すべきは、Grayscaleが2026年1月にTAO ETFを申請したことで、これは機関資本がこの分野に参入するシグナルを示しています。さらに、2025年12月にBittensorはTAOの日次供給量を半減させ、供給側の構造的引き締めが進行中です。
参考リンク:
https://arxiv.org/pdf/2603.08163
https://importai.substack.com/p/importai-449-llms-training-other
https://docs.tplr.ai/
https://systems-analysis.ru/int/MMLU_Benchmark_%E2%80%94_MMLU_%E5%9F%BA%E5%87%86%E6%B5%8B%E8%AF%95