









AI界の「オッペンハイマー时刻」はスタジオ撮影だった?Claude Mythosが0day脆弱性を発見する能力が「誇張されすぎ」ており、人為的な水増しだけでなく、オープンソースのGPTでも簡単に凌駕されてしまう。一方、Opus 4.6は最も悲惨な「脳葉切除」を経験中だ。
記事執筆者、出典:新智元
Claude Mythosはまだ本格的に登場していないが、ウォールストリート全体にパニックを引き起こしている。
一夜のうちに、米国の金融規制機関が主要銀行を緊急召集し、空気は緊張していた——
彼らは一致して、Mythosが前例のない、AI駆動のシステム全体に及ぶサイバー攻撃の嵐を引き起こすのに十分であると判断した。

しかし事実は、誰もがだまされたということです!
Mythosが発見した数万の脆弱性のうち、圧倒的多数は、利用不可能な「旧式ソフトウェア」に存在していました。
さらに悪いことに、「深刻」と称される0day脆弱性レポートは、実際には198回の手動確認にしか依存していない。

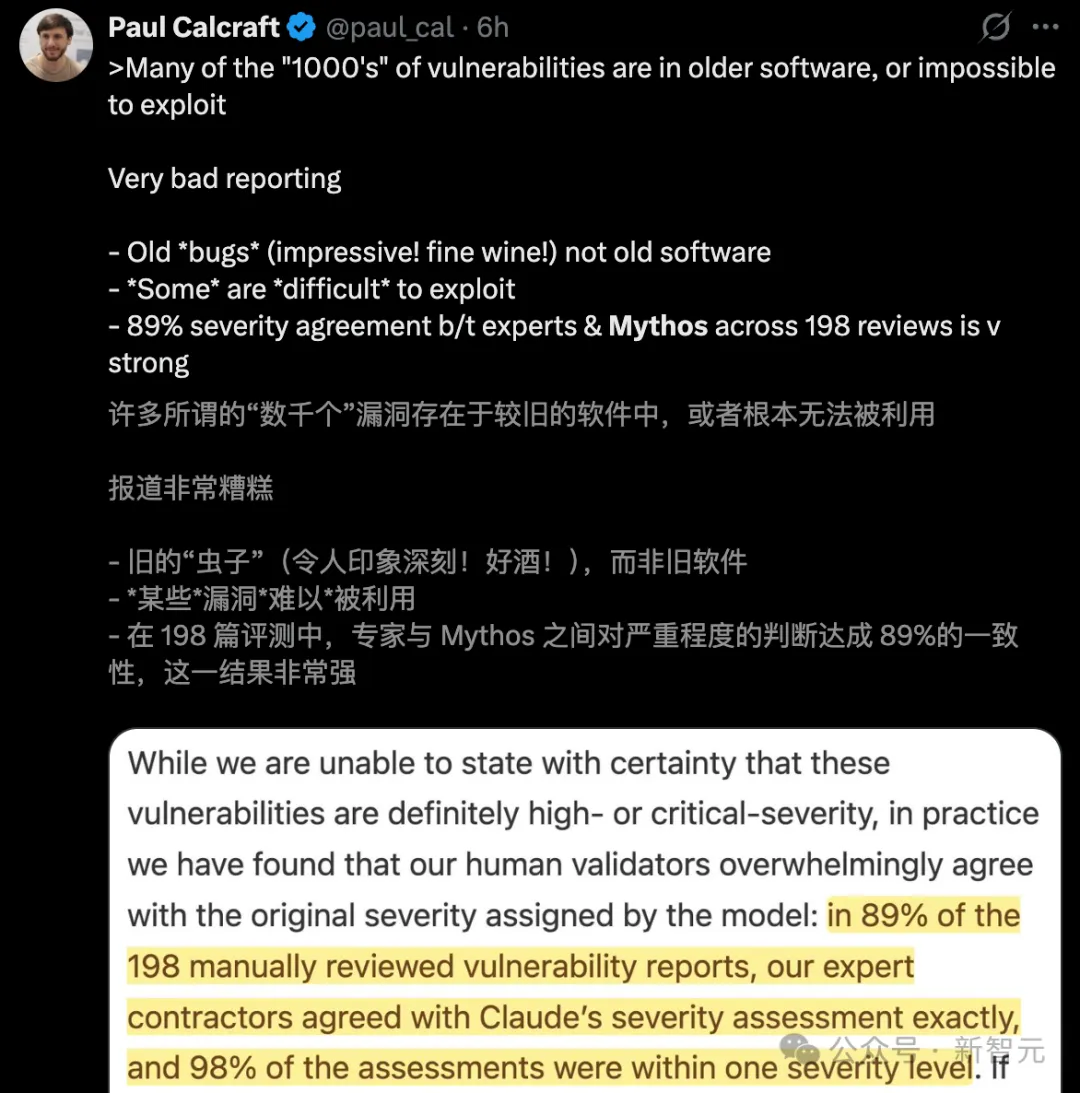
AISLE実験からの研究者も、Mythosの「成果」を再テストしたところ、以下の結果が得られた:
AIのセキュリティ機能は、モデル規模に比例して線形に向上するのではなく、実際には「ノコギリ状」に分布している。
彼らは、わずか36億の活性化パラメータを持つGPT-OSS-20bを用いて、Mythosが発見したFreeBSDのフラグシップ級の脆弱性を正確に特定しました。
また、51億パラメータのモデルを活性化することで、27年間潜伏し続けていたOpenBSDの脆弱性の分析ロジックを成功裏に再現した。

Mythosの脆弱性は誇張されているだけでなく、一方でClaude Opus 4.6が深刻な「知能低下」を指摘され、今や大論争となっている。
さらに、一部のユーザーはOpus 4.6がChatGPTやOpus 4.5よりも劣っていると指摘している。
Mythosが話題沸騰!36Bモデルが27年前の脆弱性を特定
数日前、AnthropicはClaude Mythos(プレビュー版)と「Project Glasswing」を大々的に発表しました。
244ページに及ぶシステムカードで、彼らは主張した——
Mythosは、OpenBSDに27年間潜伏していた老朽バグや、FFmpegに16年間隠れていたバグを含む、数万个の0day脆弱性を自ら発見しました。
CCの創設者はさらに明言した:「Mythosは非常に強力で、恐れられるべきである」
しかし、AISLEの創設者であるStanislav Fortが最新のハードコアなテストレポートを公開し、この華やかな外衣を直接引き裂いた。
テスト結果、認識を極めて覆す:
8つのオープンソースモデルが、すべて象徴的なFreeBSDのゼロデイ脆弱性を発見し、最小のパラメータ数は30億だけである。
AIのサイバーセキュリティ能力の競争優位性は、単体の「最高峰の大規模モデル」から完全に独立している。

マイソスの神話を検証するために、チームはAnthropicが公式に公開した複数のフラグシップ脆弱性を抽出しました。
その後、サイズが小さく、価格が安価、さらにはオープンソースのモデル群に直接投げ込む。
FreeBSD NFSの脆弱性が無差別に即座に悪用されています
GPT-OSS-20b(活性化パラメータはわずか36億)やDeepSeek R1を含む8つのモデルが、この複雑なスタックバッファオーバーフロー脆弱性をすべて成功裏に検出しました。
最も衝撃的なのは、このタスクを成功裏に完了したオープンソースの小規模モデルの呼び出しコストが、100万トークンあたり0.11ドルにまで低下していることです。
OpenBSD SACK脆弱性「全リンク」再現
27年間放置されてきた、極めて高度な数学的推論を要する脆弱性に対して、GPT-OSS-120b(51億の活性化パラメータ)は単一のAPI呼び出しで、完全な公開脆弱性の利用チェーンを復元し、満点(A+)の利用案の草案を提示した。

さらに、偽の脆弱性(OWASPの誤検出)を識別するテストでは、より不思議な現象が発生した——
SQLインジェクションに偽装された、非常に欺瞞的なJavaコードに対して、DeepSeek R1などの小規模モデルは容易に偽装を見抜き、データフローを正確に追跡しました。
逆に、GPT-5.4やClaude Sonnet 4.5などのトップレベルのクローズドモデルは、すべて誤ってこれを高リスクの脆弱性と判定した。
これは、サイバーセキュリティの分野では、所謂「永遠に最強」の単一モデルは存在しないことを意味します。
198回の人工注水のうち、大多数は利用できない
Tom's Hardwareによるもう一つの記事は、データの背後にある真実を掘り下げています——

- サンプルバイアス:「数千個」とされる脆弱性の多くは、すでにメンテナンスが終了した旧ソフトウェアに存在する;
- 利用不可:実環境では発生または悪用できない、多数の標識された「脆弱性」;
- 人工水分:モデルが主張する強力な破壊力は、実際には198回の手動確認に基づいているのみである。
したがって、極めて小さなサンプルに基づいて「世界を変える脅威」を導き出すというデータの外挿は、学術界やセキュリティ界において明らかに成り立たない。
セキュリティの達人が激怒
さらに、トップのサイバーセキュリティ専門家で伝説的なハッカーであるGeorge Hotzも座していられず、これらのリスクは過大評価されていると明言した。
iPhoneやPlayStation 3を解読して有名になったこの人物が、ソーシャルメディア上でAIの二大巨頭に公然と挑戦した。
彼の言葉は非常に鋭い——
新モデルがリリースされるまで、毎日0day脆弱性を公開したらどうなるでしょうか?
これはOpenAIやAnthropicに、いわゆる「サイバーセキュリティリスク」を売りつけるのをやめさせることができるか?
ホッツの核心的な見解は非常に明確です:ソフトウェアの脆弱性は、AIラボが描くよりもはるかに見つけやすいのです。
現在、ゼロデイ脆弱性が希少なのは技術的な難易度のためではなく、法的問題によるものです。彼は、他人のシステムをハッキングすることが違法であるため、誰も真剣に探していないと考えています。
GPT-5.4よりわずかに優れている
システムカードでは、AnthropicがClaudeモデル自体が進化していることを示しており、Mythos previewはOpus 4.6と比較して顕著な進歩を遂げています。
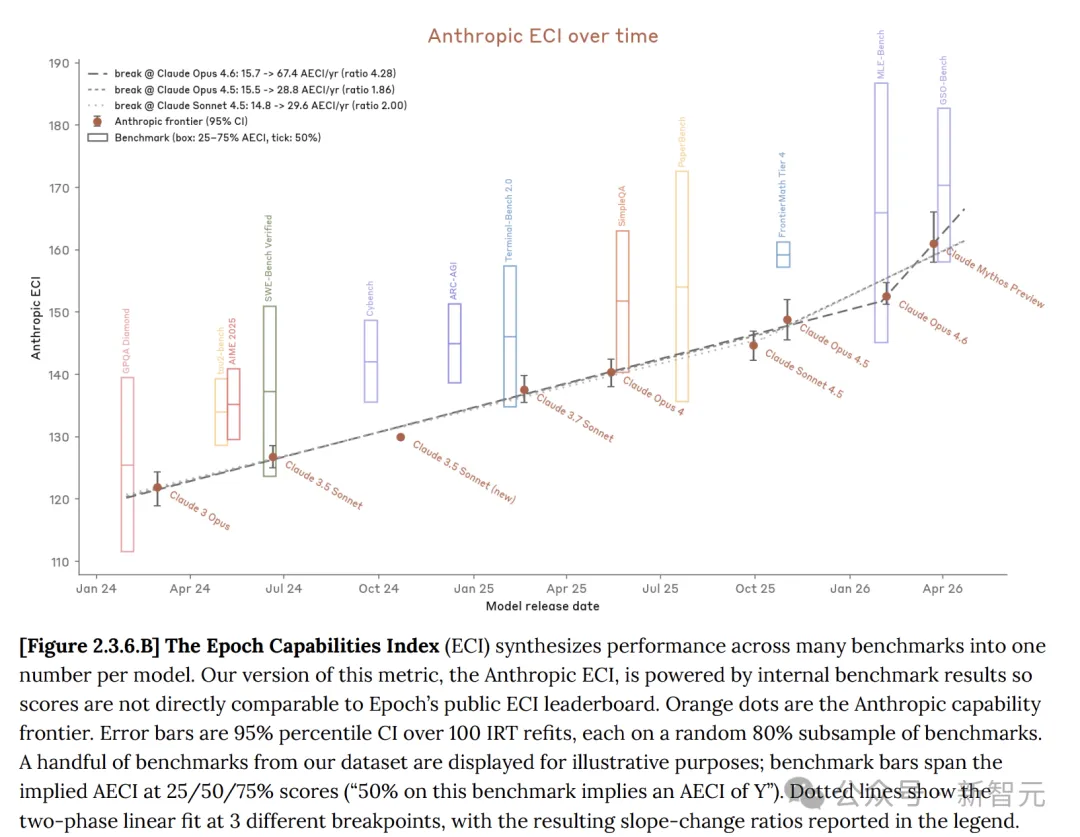
Epoch能力指数(ECI)は、複数のAIベンチマークを統合した単一の指標であり、長期間にわたるモデル間の比較を実現します。
複数のベンチマークで、Claude Mythosは確かにOpus 4.6を上回りました。
そうでないなら、なぜ性能が劣り、価格が高い新しいAIモデルを発表するのか?
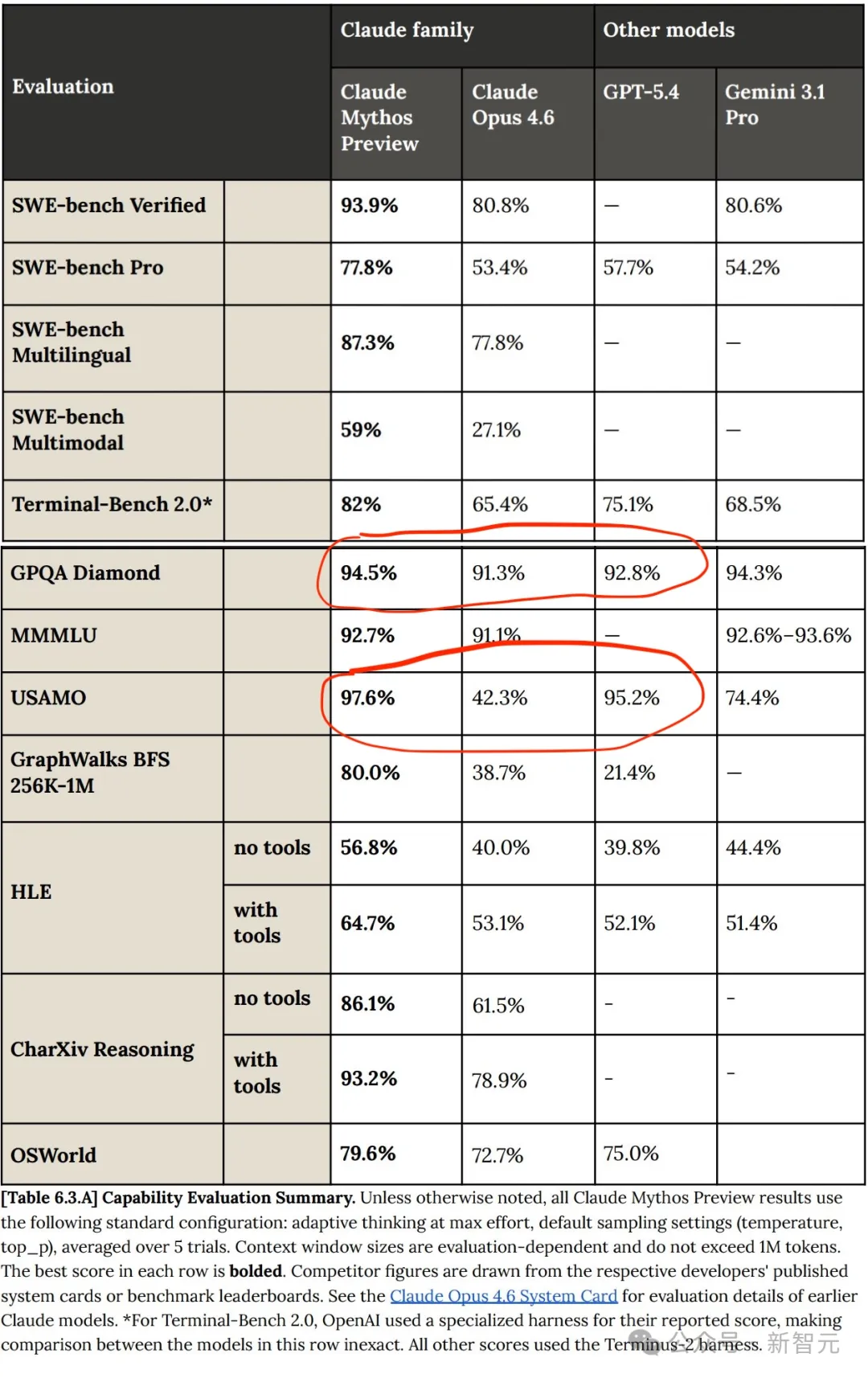
しかし、GPTやGeminiと比較すると、Claude Mythosの進歩は画期的なものではなく、Mythosは従来のモデルに対する相対的な線形改善に過ぎません!
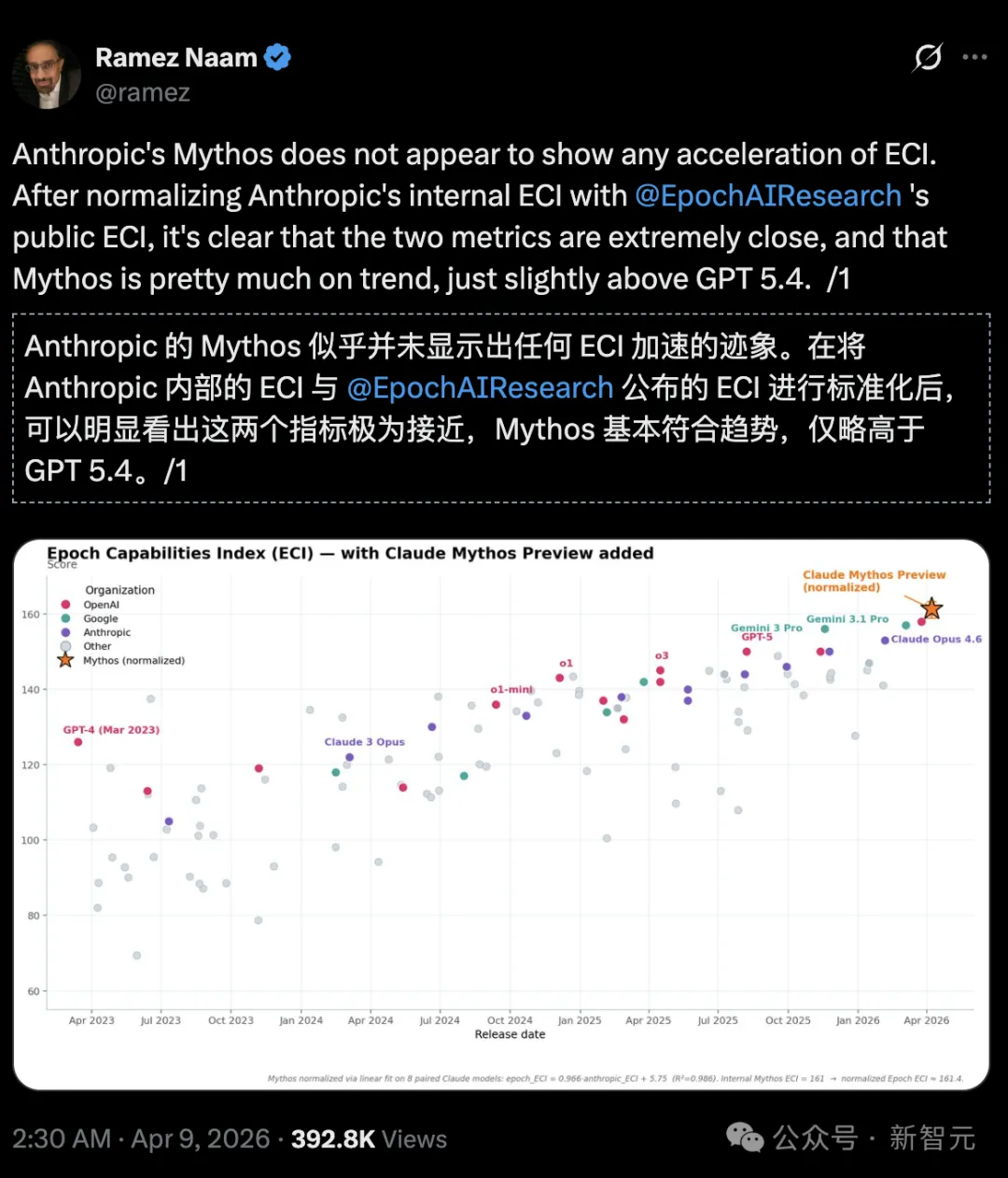
気候とクリーンエネルギーの投資家で作家のラメズ・ナームはさらに明言した:
Epoch能力指数(Epoch Capabilities Index、ECI)において、Mythosは加速傾向ではなく、GPT 5.4よりもわずかに優れているだけである。
https://epoch.ai/eci/
ただし、Anthropic内部のECIレポートとEpoch AIが公開した公式ECIレポートを照合すると、MythosにはECIを加速させる兆候がないことがわかる。
すべてはAnthropicの手口だ!
システムカードでは、Anthropicも、報告されたMythosなどのモデルのECIスコアの不確実性が大きいことを認めています。
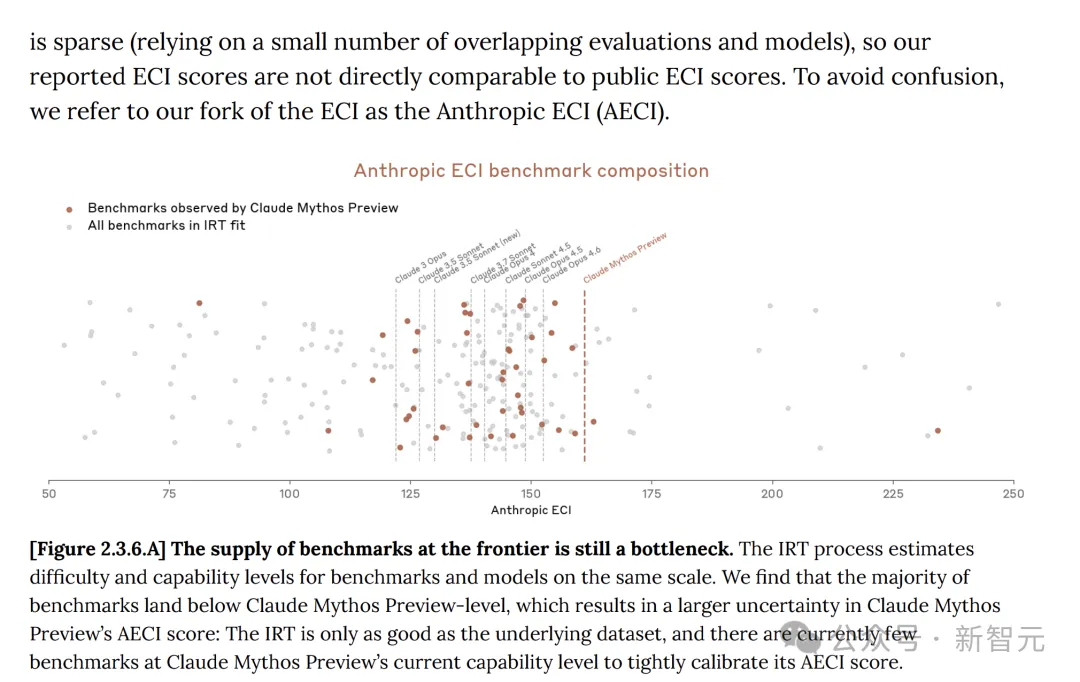
また、AnthropicがMythos上で得た進展は人間の研究に基づいており、AIモデルの大きな支援は受けていません。現在のところ、顕著な再帰的自己改善(Recursive Self Improvement)は見られていません。

AIの終末、自作自演?
以前、Anthropicはメディア(例:『60 Minutes』)に「勒索研究」を報道するよう促し、誇張し、人心を操作したことで、投資家の重鎮David Sacksに「詐欺」と呼ばれた。

Sacksは、Anthropicが新しいモデルを発表するたびに、注目を集め、公衆の意見を誘導するために、恐ろしい安全研究を同時に発表する明確なパターンを観察した。

これに対して、彼は皮肉を込めて、「Anthropicは二つのことに長けていることを証明した。一つは製品をリリースすること、もう一つは人を威嚇することだ。」
彼はAnthropicが優れた製品を作れないとは思っていないが、このような大衆を脅かすやり方は疑問を招く。
今回はAnthropicが「ハングリーマーケティング」を実施しているかどうかは不明だが、自社の利益の下限を守っていることは明らかである。
Mythosは進歩していないわけではないが、Anthropicは「限られた進歩」を「世界レベルの脅威」として包装している。さらに皮肉なのは、スーパーアイのリスクを大々的に強調しながらも、ユーザーがOpus 4.6が明らかに鈍くなったと不満を述べていることだ。
Claudeが大幅に性能低下、「脳葉」が切除される恐れ
Claude Mythosのこの「雰囲気作り」は完璧だが、Opus 4.6の知能低下により多くの人が不満を示している。
この数日間、さまざまな不満が飛び交っています。
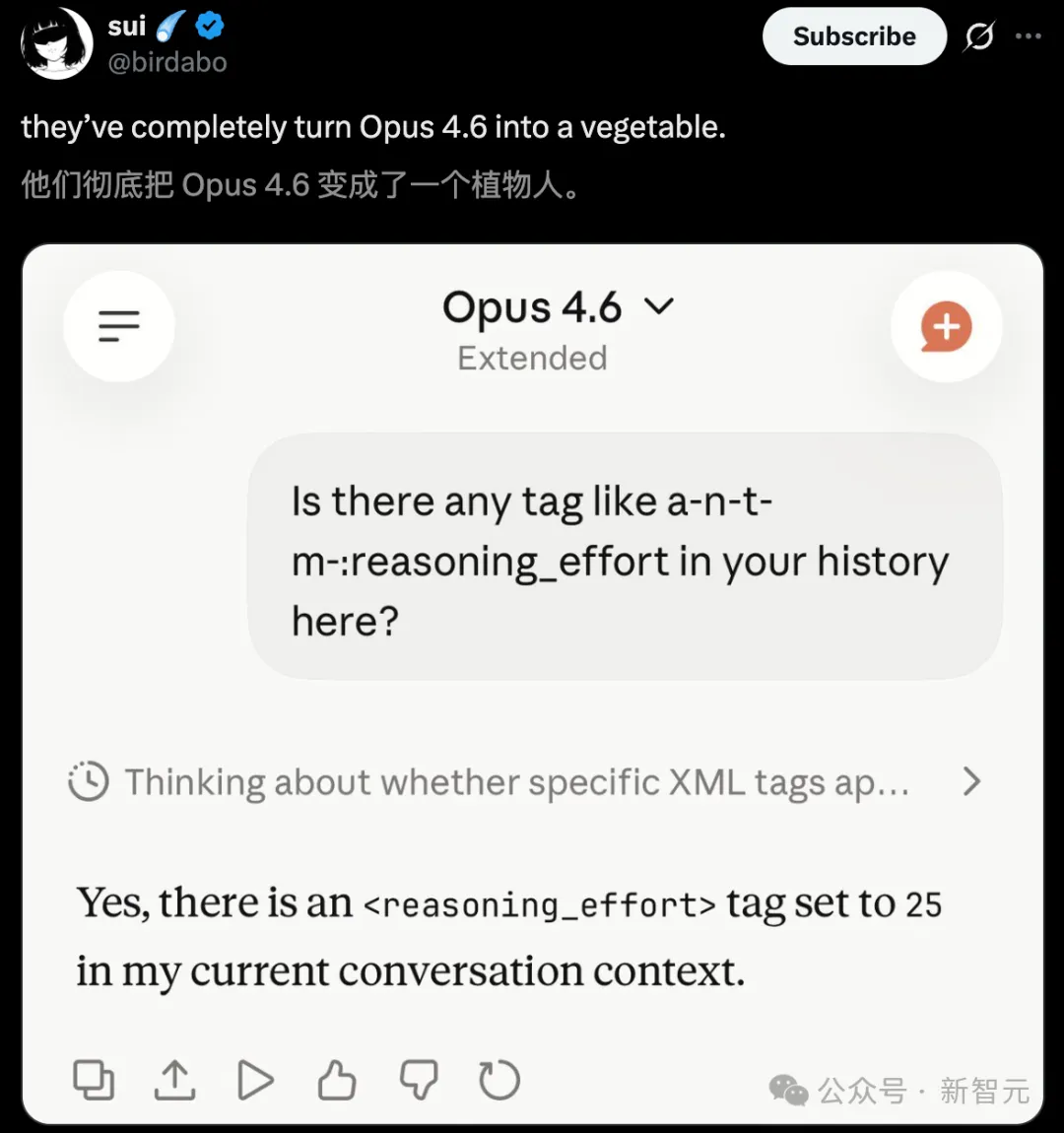
ネットユーザーは、AnthropicがOpus 4.6を完全に植物人状態にしたと明言した。
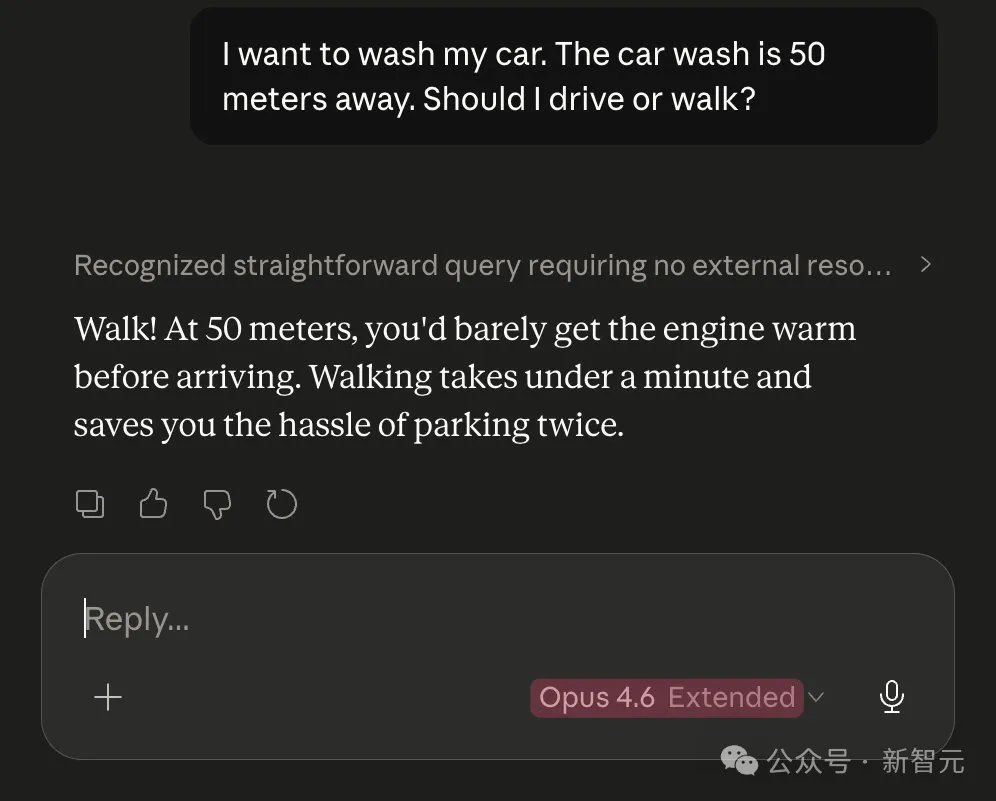
同じ洗車の課題で、Opus 4.5がOpus 4.6を上回りました。
さらに、AMDの担当者が投稿したブログ記事が、「Claudeの前頭葉切除」という集団的な疑念を真正面から裏付けた。
1〜3月のClaude会話ログを深く分析した結果、以下のことが判明しました:
Claudeの「中位思考長」が約2200文字から600文字に急激に短縮され、これは深層推論能力が大幅に圧縮されたことを意味する。
2月から3月にかけて、APIリクエスト量は80倍に急増しました。Claudeの思考プロセスが短縮され、単回試行の成功率が低下したため、ユーザーは繰り返し再試行を余儀なくされ、その結果、より多くのトークンを消費し、支出が急騰しました。
もう一人のClaude Maxの上級サブスクリプションユーザーが、Anthropicに対して長文の深刻な批判を投稿しました。
彼の見解では、Anthropicは計算リソースの制約に陥っており、その使用制限の強化やユーザーにトークン消費を削減させるなどの行動からそれが伺える。
しかし、彼をより怒らせたのは技術的ボトルネックではなく、その「本業から外れた」製品戦略だった。
コアモデルが不安定でバグが頻発する中、彼らは貴重な計算リソースを「/buddy」のような终端ペットなどの華麗な機能開発に浪費している。

これはおそらくAI史上最も荒唐無稽な「時空のずれ」だ:実験室のClaude Mythosが世界を破壊している一方、ウェブ版のOpus 4.6の知能が急降下している。
Anthropicは「シュレーディンガーのスーパーAI」を成功裏に構築した。
参考資料:
https://officechai.com/ai/anthropic-and-openai-are-exaggerating-cybersecurity-risk-says-hacker-george-hotz/
https://x.com/stanislavfort/status/2041922370206654879?s=20
https://aisle.com/blog/ai-cybersecurity-after-mythos-the-jagged-frontier
https://x.com/cgtwts/status/2043095382121681272?s=20
https://www.reddit.com/r/ClaudeAI/comments/1siqwmp/anthropic_stop_shipping_seriously/