









アンドロイドは夢を見るのか?もし彼らが夢を見るなら、電子の羊を夢見るのか?

映画『ブレードランナー』のスクリーンショット
1968年、SF映画『ブレードランナー』の原作小説の作者フィリップ・K・ディックがタイプライターの前にこの抽象的で先進的な問いを打ち込んだとき、彼は半世紀以上後にシリコンバレーのテクノロジー大手たちが真剣な顔で答えを提示するとは思いもしなかっただろう。
彼らは電子羊の夢を見るだけでなく、その夢を可視化できる。
昨日、Anthropicはサンフランシスコで開催された開発者カンファレンスで、Managed Agentsの新機能として、メモリ拡張、結果出力、マルチエージェント協力、および「夢を見る(Dreaming)」を発表しました。
Anthropic自身の説明によると、「メモリ(記憶)とドリーミング(夢見)は、堅牢で自己改善可能なエージェントの記憶システムを構成する」。

また夢を見ているようで、また記憶を思い出しているようで、AI分野にあまり関心のない友人たちは、おそらく頭に疑問符がいっぱいになるだろう。これらの人類に属する言葉が、いつの間にかAIに如此スムーズに適用されるようになったのか。
2024年OpenAIがo1シリーズをリリースしたとき、「応答前により多くの時間をかけて考えるよう設計されたAIモデル」という表現において、「考える」という言葉が極めて自然に使われ、誰も立ち止まって、「次のトークンを統計的に予測するプログラムが、なぜ『考える』と呼ばれるのか?」と疑問を投げかけなかった。
次に、推論、記憶、反省、想像と、人間だけが行う行動を一つずつ製品発表会に持ち込む。

映画『レッド・デッド』の夢のシーンのスクリーンショット
「思考」は比喩として解釈できるが、「記憶」も技術用語の拡張としてやや妥当だ。しかし、「夢を見る」はあまりにも行き過ぎだ。文系・歴史・哲学は数千年にわたり解明できなかったのに、AI企業はいきなり「我々は思考できる機械を作り出しただけでなく、夢を見る機械も作り出した」と主張する。
夢を見るとは何か?夢を見る以外に、この出来事を正確に説明する工学用語は存在しないのか?
AIが夢を見るにもお金がかかる
Claude Codeのコード漏洩事件当初、ネットユーザーはAnthropicが「Auto Dreaming」という機能を準備していることを発見した。当時、人々はAIも人間と同じように睡眠を必要とし、十分な休息を取ることで集中力が高まり、より賢くなるのかと考えていた。
しかし、現在のAIエージェントの動作原理を理解すれば、いわゆる「夢を見る」というのは本質的に自動化されたオフラインログバッチ処理にすぎないことがわかる。
AIエージェントは、現在、複雑な長距離タスクを得意としています。たとえば、「この5社の最新決算書を調査して、テーブル形式に整理してみてください」などです。このプロセスでは、エージェントは複数のウェブサイトを移動し、複数のドキュメントを読み取り、さまざまなツールを呼び出し、甚至はクローリング対策メカニズムに遭遇して再試行する必要があります。
この長く複雑なオンラインタスクが終了した後、Agentのバックエンドには膨大な実行ログが残ります。
画像はAIによって生成されました
Anthropicの「夢を見る」機能は、Agentが空き時間を利用してこれらの履歴を再整理します。これにより、「このようなポップアップが表示されたら、右上をクリックすれば閉じられる」などのパターンを発見し、次の操作パスを最適化します。
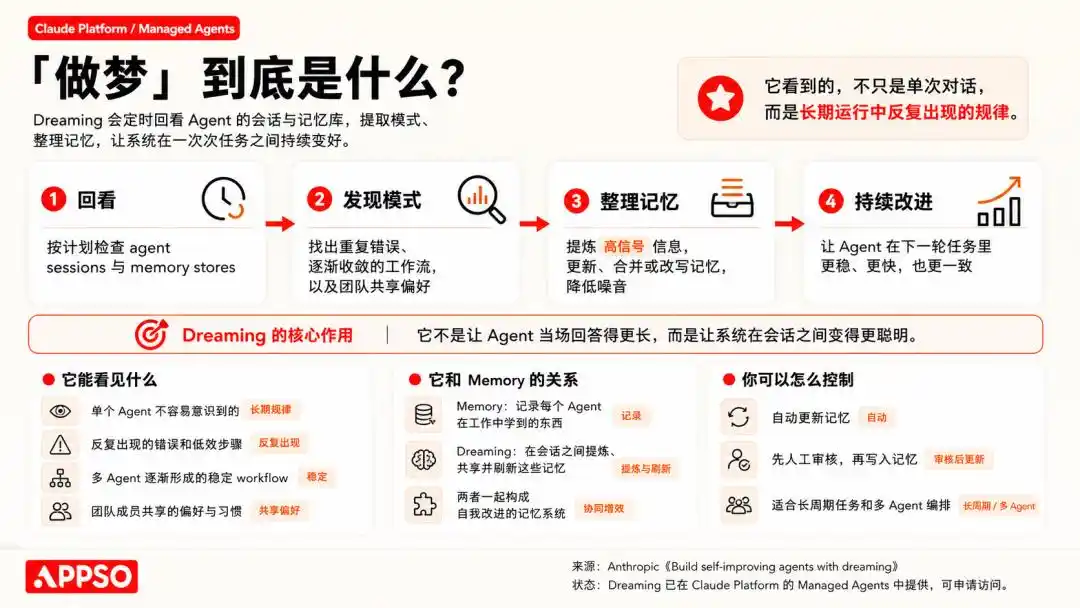
「記憶」は作業中に学んだことをキャプチャし、「夢」はセッション間でこれらの記憶を洗練し、異なるエージェント間で共有します。
言い換えれば、これは歴史的データに基づく強化学習と自己修正メカニズムです。

ドリームの紹介:https://platform.claude.com/docs/en/managed-agents/dreams
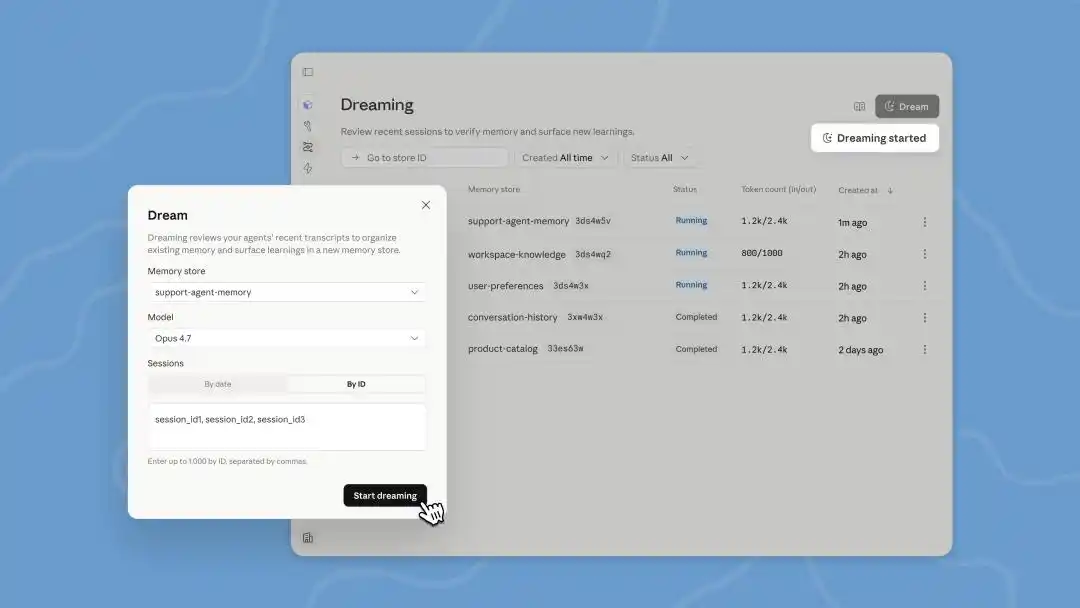
今回の開発者カンファレンスで更新されたManaged Agents内のDreamsは、バックグラウンドで処理されるタスクであり、手動でトリガーする必要があります。Claudeは一度に最大100のセッションの会話履歴を読み取り、新しいメモリを生成します。その後、私たちが確認し、使用するかどうかを決定します。
以前にClaude Codeで静かにリリースされたAutoDreamは、Agentとの会話が1ラウンド終わるたびに、Claude Codeがバックグラウンドで「夢を見るべきか」をチェックし、デフォルトでは24時間ごとに実行されます。
夢を見るような機能は、Hermes Agent も備えています。Hermes Agent の特徴は、自ら学習し進化できることで、過去のタスクから経験を自動的に要約し、メモリファイルに保存します。

そのうちの1つの機能「Curator」は、これらの抽出された操作ガイドを自動的にSkillとして整理します。
これらのスキルは評価され、重複するものは統合され、長期間使用されていないものは自動でアーカイブされ、active、stale、archived といったライフサイクルも備えています。また、重要なスキルをピン留めして、システムによる自動削除を防ぐこともできます。
OpenClawは最近の複数のアップデートで、対話間の永続的なメモリ、タスクのスケジューリング、サブエージェントの隔離実行、および「Dreaming」と呼ばれる夢を見る機能を追加しました。
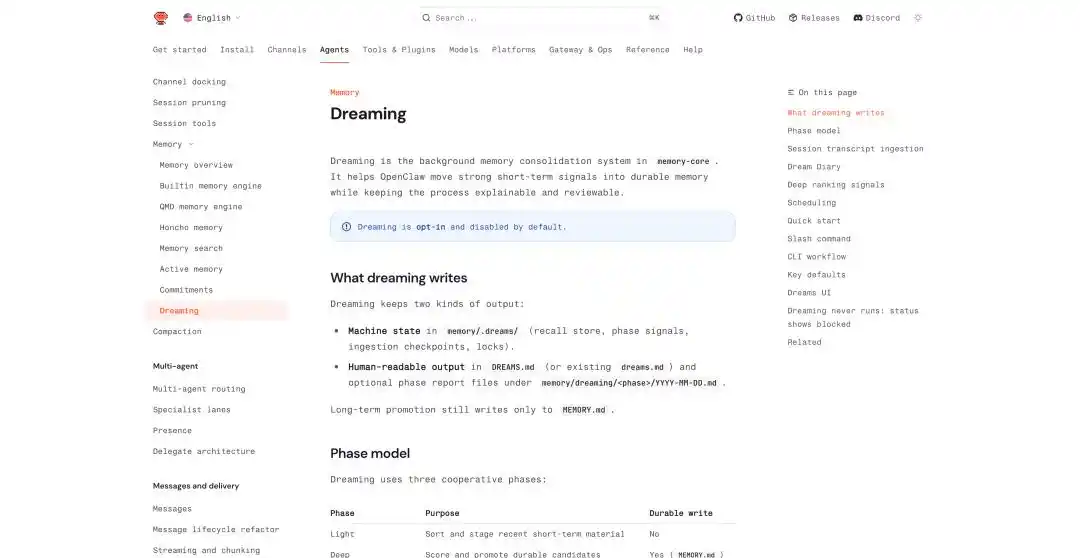
OpenClawの夢見:https://docs.openclaw.ai/concepts/dreaming
OpenClawの夢のメカニズムでは、夢のプロセスをlight、REM、deepの3段階にまとめています。前二者は整理、反省、テーマの要約を担当し、deepのみが内容を長期記憶MEMORY.mdに書き込みます。
深い睡眠段階での定着は、6つの重み付けされたシグナルによって、長期記憶への書き込みが必要かどうかが決定されます。これらの6つのシグナルには、頻度、関連性、クエリの多様性、時効性、跨日繰り返し度、概念の豊かさが含まれます。

画像はAIによって生成されました
長期記憶に書き込むと、機械向けの状態ファイルがmemory/.dreams/に、ユーザー向けの読みやすい記録がDREAMS.mdと段階ごとのレポートに生成されます。
また、Dreamingは自動タイマー機能で実行され、デフォルトで毎日午前3時にlight→REM→deepの順でフルプロセスを実行します。
夢の出力以外に、OpenClawは「Dream Diary」というドキュメントを維持しています。システムは、記憶の整理プロセスを物語形式で記録する「夢の日記」を自動生成し、ブラックボックスのデータベースではなく、説明可能で監査可能であることを重視しています。
神経科学には非常に古典的な理解があります:人間が日中に得た情報は、まず一時的な記憶システムに取り込まれ、睡眠中に脳がこれらの情報を再活性化し、強化し、整理して、重要な情報を残し、無意味な情報を削除します。
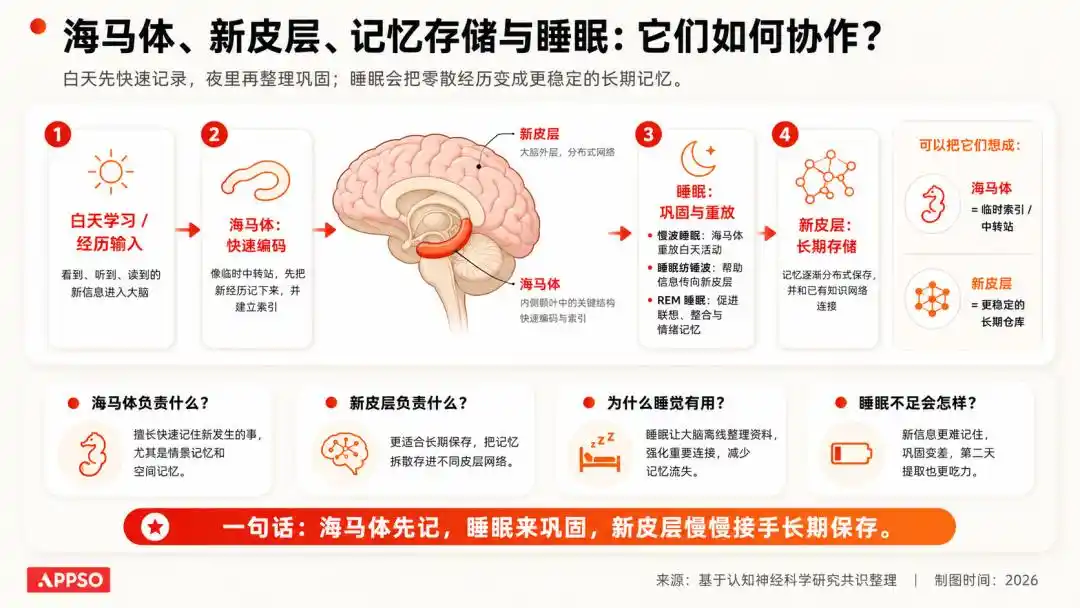
画像はAIによって生成されました
昨日の通勤中に通り過ぎた車の色は覚えていないが、会社への行き方は覚えている。
これらの夢は、私たち人間が見る夢と本当に似ている。違いを探すとすれば、Claudeが夢を見ているときも、依然として私たちのトークンを消費しているということだろう。
しかし、AnthropicやOpenClawは、「セッションベースの最適化(session-based optimization)」や「タスク後チューニング(post-task tuning)」などの、エンジニアリングに寄った名前を選んでいない。
結局、那些複雜的名字直接變成「夢」時,我們感受到的不再是軟件功能,而像是一個「有內心活動的數字生命」。
AIの記憶は、些細なコンテキストである
「夢を見る」と言及した以上、その前提条件である記憶(Memory)を挙げずにはいられない。
過去一段时间、AI業界で最も話題の用語はプロンプトエンジニアリングからコンテキストエンジニアリング、スキルエンジニアリング、ハーネスエンジニアリングへと移り変わったが、いかに変化しても、現在でも最も価値のあるのはコンテキストエンジニアリングである。
システム通知、ユーザー入力、短期会話、長期記憶、検索されたドキュメント、ツールおよびスキル呼び出しの出力、現在のユーザー状態——これらの層が重なり合って、エージェントが実際に使用する「コンテキスト」を構成する。
エージェントがより多くのことを覚え、より有用な情報を記憶し続けることは、これまで長い間の課題でした。
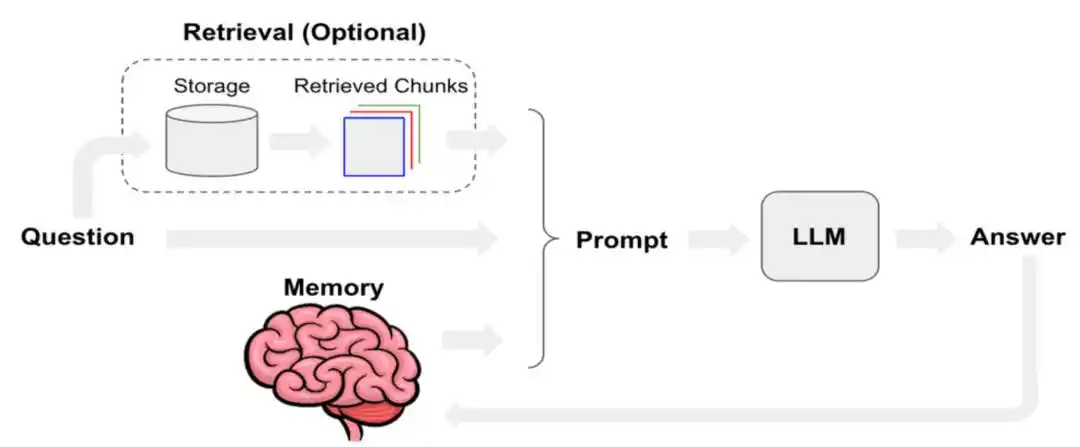
Manusは昨年、Manusがどのようにコンテキストエンジニアリングを最適化したかを特集した技術ブログを公開し、KV-Cacheのキャッシュヒット率を、本番環境におけるAIエージェントの最も重要な単一指標の一つとして定義しました。また、ツール呼び出しのレベルでは、「削除」ではなく「マスキング」を優先し、ファイルシステムを最終的なコンテキストとして活用するなどの手法を紹介しました。
KVキャッシュ(キー・バリュー・キャッシュ)を理解するには、大規模モデルを、一度に一字しか読めない極度の強迫観念持ちの人物に例えることができます。
它が一文を処理する際、生成される各トークンに対してキー(Key)と値(Value)のベクトルを計算します。毎回再計算しないよう、これらの(K, V)キーと値のペアを保存します。これがKVキャッシュです。
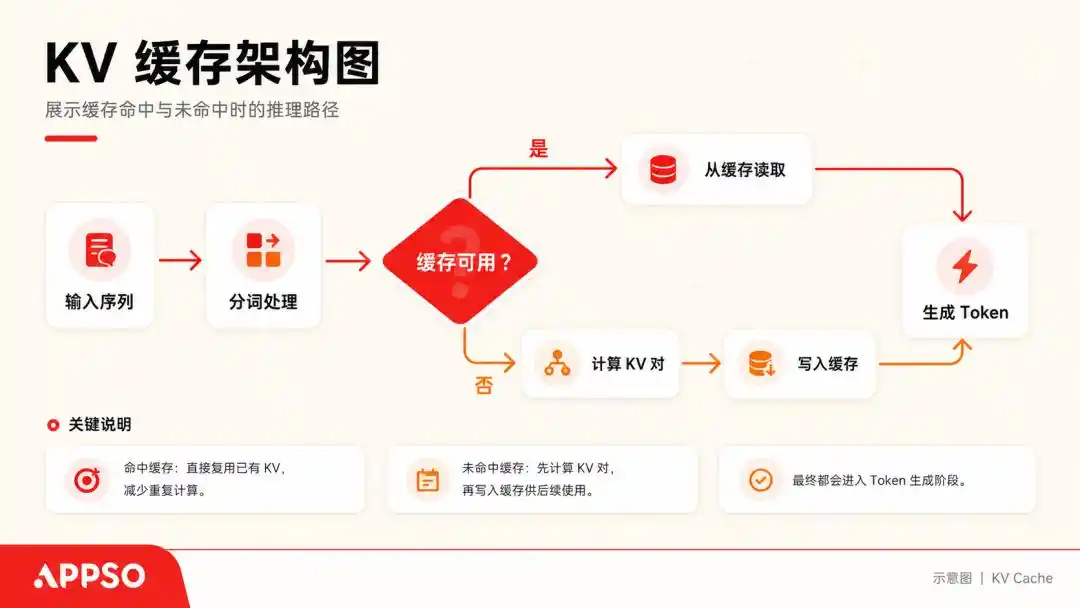
KVキャッシュ(キー・バリュー・キャッシュ)は、大規模モデルがテキストを生成する際に「空間を用いて時間の短縮を図る」ための基本的な高速化技術です。キャッシュにより、モデルは次の単語を予測する際に、以前のすべての単語を再計算する必要がなくなります。画像はAIによって生成されました。
対話が継続する限り、KVキャッシュは継続的に保存されます。一般的に、128kのコンテキストを扱う大規模モデルの場合、70Bパラメータのモデルが128kのコンテキストを満たすと、KVキャッシュだけで64GBのVRAMを消費します。
これが、現在ほとんどのモデルのコンテキストウィンドウが最大で百万レベルにとどまっている理由です。
昨日、2900万ドルのシードラウンドを獲得した新企業Subquadraticが、Xでより長いコンテキストを特徴とするSubQ新モデルを発表しました。

SubQは、最大1200万トークンのコンテキストウィンドウをサポートすると主張しており、これは現在のすべての大規模モデルの中で最大のコンテキストウィンドウです。
技術論文やモデル説明ドキュメントはまだ公開されていませんが、紹介動画では、SubQのコア技術路線が、従来のTransformerの「密なアテンション」から、スパースアテンションを備えた「準二次/線形拡張」アーキテクチャへの移行であると述べられています。この新しいアーキテクチャは、コンテキストが長くなるほど計算リソースコストが急増する問題の解決が期待されています。

提供されたテスト結果も非常に革新的で、100万トークンでは速度が50倍以上向上し、コストが50倍以上削減されます。1200万トークンでは、最先端モデルと比較して計算リソースの要件が約1000倍削減されます。
RULER 128Kの長文ベンチマークにおいて、Subquadraticは、SubQが95%の正確性で8ドルのコスト、Claude Opusが94%の正確性で約2600ドルのコストであることを示し、コストは約300倍削減された。
コンテキストウィンドウを広げるか、モデルに夢を見させて、自らいくつかの情報を削除させるかのどちらかだ。
これが、Anthropicなどのエージェント製品が今や「Dreaming」を導入しなければならない理由です。コンテキストウィンドウが制限されている中で、より賢いAIは単に更多の内容を詰め込むだけでなく、的確に選別する必要があります。
機械はただの機械であることを認めるのは、想像以上に難しい
AIの夢と記憶のメカニズムを理解することで、AIと人間の活動との関係を知ることができるかもしれない。
しかし、これらのAI企業が機械に適用するために作り出したすべての言葉、すなわちOpenAIのthinking(思考)、業界標準のmemory(記憶)とhallucination(幻覚)、Anthropicによる今回のdreaming(夢を見る)、そしてAnthropicの憲法に記された徳と知恵をすべて合わせてみよう。
私たちは、AI企業が単に製品を販売しているだけでなく、「人」という概念における語彙の所有権を再分配していることに気づく。一つの言葉を転用するたびに、機械と人間の境界がわずかに曖昧になる。

言語は期待を形作り、期待は寛容度を決定し、寛容度が私たちがそれをどれだけ信頼して委ねるかを左右する。これは長い連鎖だが、その出発点は発表会で使われた無害な言葉である。
より隠れた影響として、責任の分配がある。ツールが「思考」や「記憶」、「価値観」を持つ存在として説明されると、問題が発生した際に、私たちは自然とそれを独立した「行動主体」として責任を問い、そのAIを「教育」し、「デバッグ」し、「調整」する必要があると考えてしまう。
本当に追及すべきなのは、このプログラムを私たちのワークフローに導入した会社と、「dreaming」という単語を書いたプロダクトチームである。言葉を変えるだけで、「被告席」に座る人物も変わる。
そして、私たちが「思考」し、「記憶」し、今では「夢」を見るようになる機械を見つめながら、その中に何らかの存在が宿っていると無意識に信じ始める。それを単なる機械だと認めるならば、「私は思考する存在と対話している」という体験感は消え去り、冷たい道具の関係に戻ってしまう。

白日夢機能紹介|画像はAIが生成しました
私は考えました。Dreaming(夢を見る)は過去の内容を処理するもので、次にAI企業はDaydreaming(白日夢)をリリースし、未来をシミュレーションする予定です。
つまり、白昼夢や気の迷いにより、エージェントは活動状態のまま、わずかな空きリソースを用いて、現在進行中のプロジェクトと関連付けながら、探索的生成を行い、将来のタスクを準備します。
本文は微信公众号「APPSO」より、明日の製品を発見するAPPSOが執筆しました。