









一般の人が「最強のプロンプト咒文」を研究している間に、シリコンバレーのトップラボはAIインフラを生産ライン化していた。
記事執筆者、出典:新智元
まだChatGPTのチャットボックスで繰り返しプロンプトを調整しているのか?
最近、Xのユーザーが次のようなツイートを投稿した:「大手企業が密かに使用しているClaude Codeプロジェクトテンプレートが漏洩!」
これはもはやプロンプトを書くことではない。AIエンジニアリングのインフラである。

一連の戦略は「CLAUDE.md」というファイルを中心に展開され、その核心原則はたった3つである:
Claudeが誤りを犯すたびに、ルールを1つ追加する。 自分が繰り返すたびに、ワークフローを1つ追加する。 バグが発生するたびに、ガードレールを1つ追加する。

これにより、プロジェクト経験を、毎回起動時に読み込まれる長期的なコンテキストと自動化制約として蓄積します。
全体のアーキテクチャは、AI企業の職務編成のようだ:CLAUDE.mdは入社マニュアル、skills/は業務SOP、hooks/はコンプライアンス部、docs/は定款、tools/は総務部、src/が実際に仕事を担う事業部門である。

あなたはもはやAIとチャットしているのではなく、あなたのコードリポジトリを理解するAIを構築しています。
最も驚異的なのは、一度設定するだけで、Claudeがコードを自動的に監査し、指示に従って再構築し、アーキテクチャルールを強制し、リリースノートを作成し、スキルからワークフローを実行し、過去のエラーを記憶することです。
そして、使うほどに賢くなります。
多くの人々はChatGPTを開き、プロンプトを書き、コピーして貼り付け、繰り返すだけですが、この方法ではターミナルを開いて、すでに提供されたskillコードを実行するだけで済みます。
それは自分のコードライブラリにAIの同僚たちを育てているようなものです。
このツイートの背後には、この時代が静かに幕を閉じようとしている小さなシグナルが込められています。多くの人はまだそれに気づいていないでしょう。
漏洩していないはずの「漏洩スクリーンショット」が明らかにする真実
@ai_rohittが公開したこのスクリーンショットは、Anthropicの公式ドキュメントで公開されているClaude Codeの標準パターンです。
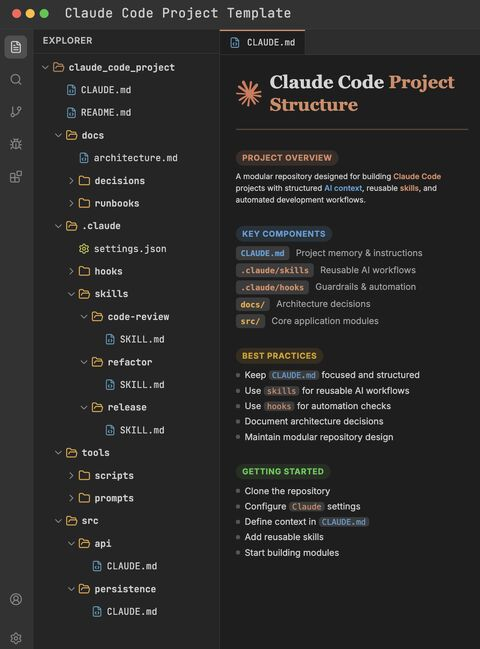
CLAUDE.mdは、Claude Codeが各セッション開始時に自動的に読み込むプロジェクトメモリーファイルです。
.claude/skills/および.claude/hooks/は公式にサポートされる拡張メカニズムです。
これらはコミュニティが数ヶ月にわたり議論してきた公開の実践であり、誰かが盗み出した「内部テンプレート」ではありません。
しかし、それが一部のベテラン開発者に自発的にシェアさせていることから、Claudeを日常的に使っている開発者たちからの支持を得ていることが伺える。
その多くの人々は、おそらくこの数日で、それがこんな風に使えることを初めて気づいたのでしょう。
そしてシリコンバレーのトップチームは、このことを生産ラインとして実現しました。
最初の例は、OpenAI Frontierチームです。
OpenAI公式が公開したFrontierチームの実験では、空のリポジトリから開始した内部ベータ版が約5ヶ月の間にCodexによって約100万行のコードと約1500のPRが生成され、チームは3人から7人に拡大し、人間は直接コードを記述しなかった。
チームを率いるRyan Lopopoloは、後のインタビューで、このワークフローが「0人の手動コード、0人の手動レビュー」の限界形態に近づいているとさらに述べた。
彼は、トークンを節約するのではなく、モデルの非常に高い並列処理能力と極めて低いコストを活用して、人間の限られた高価な同期注意を置き換えるべきだと考えている。
二番目の例は、Stripeの内部自動化コードエージェントシステムであるMinionsです。
StripeのMinionsは、AIが完全に生成したコードを週に1300以上ものPRとして生成・推進しており、これらはすべて人間によるレビューを経ています。
ここにもう一組のデータがあります:1.6% 対 98.4%。これは、モハメド・ビン・ザイードAI大学VILA-Labが発表した論文からのものです。

https://arxiv.org/pdf/2604.14228
研究者は、Claude Code v2.1.88バージョンの512,000行のTypeScriptソースコードを体系的に分析し、その結論として、AI決定ロジックは1.6%に過ぎず、残りの98.4%は決定的なエンジニアリングインフラであると示した。
具体的には、権限ゲートウェイ、コンテキスト管理、ツールルーティング、エラー回復の4種類です。
この数字は、モデルが1.6%の能力しか貢献していないことを意味するのではなく、Claude Codeという製品において、複雑さの大部分がモデル自体ではなく、権限、コンテキスト、ツールルーティング、復元メカニズムなどの決定論的エンジニアリングインフラに存在することを示しています。
@ai_rohitt の画像にある CLAUDE.md/skills/hooks 構造は、一般の開発者でも構築できる「エントリーレベルのインフラ」であり、OpenAI や Stripe の本番環境用アーキテクチャと同じパラダイムだが、規模ははるかに小さい。
CLAUDE.mdが暴露した秘密
過去3年、誰もが「GPTはいつもっと賢くなるのか」「Claudeはいつ新しいバージョンが出るのか」と尋ねてきた。
しかし、本番環境でAIプログラミングを実際に実行しているチームにとって、彼らが最も気にするのはおそらくこれではなく、AIが以前に踏んだ誤りをどのように記憶させるか、AIが作業を始める前にプロジェクトのアーキテクチャ制約をどのように確認させるか、AIが誤ったときにはどうやってツールでそれを防ぐかである。
CLAUDE.mdはまさにすべての担い手です。
Anthropicの公式定義はただ一つの文だけである:
プロジェクトのルートディレクトリに配置されたMarkdownファイルで、Claude Codeが各セッションの開始時に自動的に読み取ります。

https://code.claude.com/docs/en/memory
シンプルに聞こえるかもしれませんが、その周囲に構築された複数の構造が、本当の強みです。
CLAUDE.mdはプロジェクトの脳です。
アーキテクチャの意思決定、命名規約、テスト要件、繰り返し踏んだ誤り—all ここに蓄積されています。これはAIが起動するたびに最初に目にする「社員マニュアル」です。
.claude/skills/は再利用可能なワークフローです。
Claude Codeの開発者であるボリス・チェルニーは、コミュニティで繰り返し次のように強調している:「毎日1回以上行うことは、スキルまたはコマンドにしなさい。」
スキルとは、実行可能な方法論の一部です。コードレビュー、コミットメッセージの生成、リリースノートの作成など、これらは毎日手動でプロンプトを入力する作業ではなく、スキルを呼び出すだけで結果が出るべきです。
.claude/hooks/は自動ハーネスです。
これが最も重要な部分です。AI自身の判断に頼らず、AIが誤りを犯す前に確定的なコードがそれを防ぎます。そのため、AIを「監視なし」で実行できるのです。なぜなら、誤りの境界がhooksによってしっかりと制限されているからです。
docs/decisions/はアーキテクチャ決定記録です。
AIにコードが「何であるか」だけでなく、「なぜそうであるか」も理解させましょう。
これは最も見落とされがちですが、AI協力の最大のレバレッジポイントです。
tools/とsrc/は実行層です。
このアーキテクチャで真に注目すべき点は、ある開発者が見栄えのするディレクトリを構築したことにではなく、ますます多くの独立したチームが、モデルをコンテキスト、ツール、権限、評価、フィードバックループからなるハーネスに組み込むという同じ方向性に収束していることです。
GitHub上で類似のプロジェクトがすでに見られます:
rohitg00のawesome-claude-code-toolkit、diet103のclaude-code-infrastructure-showcase、affaan-mのeverything-claude-codeは、すべてagents、skills、hooks、rules、MCP configsなどのコンポーネントを用いてClaude Codeのエンジニアリング環境を構築しています。
これは、真正の成熟したAIプログラミングワークフローが、より強力なモデルやより長いプロンプトだけに頼るのではなく、モデルを再利用可能で、制約可能で、復元可能で、監査可能なエンジニアリングシステムに組み込むことを意味する。
具体的ディレクトリ構造は、各実装によって完全には一致しません。
OpenAIラボの極限実験
2026年2月11日、OpenAIの公式ブログに記事「Harness engineering: leveraging Codex in an agent-first world」が掲載されました。

https://openai.com/index/harness-engineering/
Anthropicはこの概念に基づいてClaude Codeのアーキテクチャの考え方を再設計した;Martin Fowlerのウェブサイトはこれを「Agent=Model+Harness」という式に要約した。
Harnessは馬術に由来しています。これは馬の全体的な挽具、つまり韁繩、口綱、鞍、頭韁を指します。
一匹の馬は速く、力強く走ることができるが、自分ではどこへ向かうかを知らない。全体の挽具がその方向を決定する。
AIプログラミングに例えると:モデル自体の能力は非常に高いが、あなたのコードベース内でどこに向かえばいいかわからない。Harnessは、そのためにあなたが作るステアリングホイール+ブレーキ+ナビゲーションだ。
OpenAI Frontierチームの「100万行のコード、人間の手を一切介さず」実験は、本質的にHarnessを極限まで追求したものである。
彼らの主要なエンジニアリング実践には以下の通りです。
階層構造の厳格な制約。
TypesからConfig、Repo、Service、Runtime、UIへと依存関係は単方向に流れ、CI層でlinterが強制的に実行されます。Agentが階層関係に違反するコードを書いた場合、ビルドは直ちに失敗します。
リンターのエラーメッセージ自体が修正の指示であり、これが最も直感に反する詳細である。
通常のプロジェクトのlintエラーは「violation detected」で、人間が読むためのものである。OpenAI Frontierのlintエラーは、「console.logの代わりにlogger.info({event: 'name', …data})を使用してください」という、エージェントが直接読み取り、修正できる指示である。
ドキュメントを単一の真実の源として使用します。すべてのアーキテクチャ図、実行計画、設計仕様はリポジトリ内のdocs/ディレクトリにあります。エージェントは外部の知識ベースを必要とせず、すべてがリポジトリ内にあります。
この仕組みの効果はどれほど素晴らしいですか?
モデルは変更されていませんが、LangChainがハーネスを調整し、システムプロンプト、ツール、ミドルウェア、推論モードを改善した結果、Terminal Bench 2.0のスコアが52.8から66.5まで向上しました。
今日あなたができること
AIのためにプロジェクトの脳を構築する
普通の開発者に戻って考えると:パラダイムが既に移行しているなら、今日できることは何でしょうか。
まず、最も重要なプロジェクトのルートディレクトリにCLAUDE.mdを作成してください。
完璧である必要はないし、長くする必要もない。チームのアーキテクチャルール、命名規約、テスト要件、繰り返し踏んだ坑を10分で使えるバージョンに書き下ろせ。
次にAIがミスをしたとき、手動で修正せず、自分に尋ねてみよう:CLAUDE.mdに何が欠けているのか?
二つ目のことは、毎日繰り返すことをスキルに変えることです。
Boris Chernyの名言に注意してください:「1日に同じことを1回以上行うなら、それをスキルまたはコマンドにしなさい。」
コードレビュー、生成されたコミットメッセージの作成、リリースノートの作成、繰り返されるバグの修正——これらはすべてスキルであり、毎日手動でプロンプトを入力するべきものではない。
第三に、トラブルになりやすい場所にフックを追加してください。
フックは98.4%の中で最もレバレッジの高い部分である。AIに賢くなることを依存せず、確定的なコードによる強制チェックに依存する。これは人間のエンジニアの判断を機械が読み取れる制約に翻訳するプロセスである。
この出来事の核心はコードを書くことではなく、ルールを書くことである。
Karpathyが今年1月にツイートし、広く拡散された言葉:「私は手動でコードを書く割合が80%から、エージェントに任せることに80%を変更した。」
今後5年間、エンジニアの能力の曲線は「どれだけ多くのコードを書けるか」から、「AIにどれだけ厳格な作業環境を設計できるか」へと移行している。
コーディングの仕事はAgentに引き継がれています。
しかし、エージェントが優れたコードを書けるような世界を設計するのは、依然として人の仕事である。そして、以前よりもより難しく、重要であり、また興味深い。