










この見解は根拠のないものではありません。彼は多くの公開ベンチマークを調べ、AIがAI開発関連のタスクにおいて急速に進歩していることを発見しました。
たとえば、CORE-Benchは、AIが他の研究論文を実装する能力を評価します。これはAI研究において非常に重要な要素です。
PostTrainBenchは、強力なモデルがより弱いオープンソースモデルを自らファインチューニングして性能を向上させられるかをテストするものであり、これはAI研究タスクの重要なサブセットである。
MLE-Benchは、実際のKaggleコンペティションタスクに基づいており、特定の問題を解決するために多様な機械学習アプリケーションを構築することを要求します。また、SWE-Benchのような広く知られたコーディングベンチマークも、同様の進歩を示しています。
ジャック・クラークは、この現象を「フラクタル」的な右上がりのトレンドと表現し、異なる解像度やスケールにおいても意味のある進展が観察されると述べた。彼は、AIがエンドツーエンドの自動化研究開発能力に徐々に近づいており、これが実現すれば、AIが自らの後継システムを構築し、自己反復のサイクルを開始すると考えている。

この発言が出て、ソーシャルメディアで多くの議論を呼んだ。
一部の人々は、これをASIとシンギュラリティへの鍵となる第一歩と見なし、技術の発展のリズムを根本的に変える可能性があると考えています。

しかし、異なる声も存在します。
ワシントン大学のコンピューターサイエンス教授であるPedro Domingosは、AIシステムは1950年代にLISP言語が発明されたときから「自らを構築する」能力を備えていたと指摘し、真の問題は増加する報酬を得られるかどうかであり、現在のところそのような明確な証拠は存在しないと述べている。

一部のネットユーザーは、2027年から2028年にかけて確率が一気に30%上昇していることから、AIの能力が2027年末頃に急激な大きな進化を遂げる可能性を示唆しています。では、具体的にどのマイルストーンやイベントが、AIの再帰的自己改善の確率を短期間で大幅に高めるのでしょうか?

また、ネットユーザーの中には、Jack ClarkがAnthropicの新任PR責任者であることが、彼らの新しい戦略の一部であると指摘しており、私たちがこれまで警告してきたことは、多数の論文で裏付けられていると述べています。
ジャック・クラークは、Import AI 455号のニュースレターで長文を執筆し、詳細に説明した。
次に、この記事を全体的に見てみましょう。
AIシステムが自らの構築を開始しようとしています。これは何を意味しますか?
クラークは、利用可能なすべての公開情報を整理した結果、2028年末までに人間の関与なしにAIが研究開発を行う可能性がかなり高く、おそらく60%を超えると判断せざるを得なかったため、この記事を執筆したと述べている。
ここで言う人間の関与のないAI開発とは、人間の研究を補助するだけでなく、重要な開発プロセスを自ら完了し、自らの次世代システムを構築することさえ可能なほど強力なAIシステムを指す。
クラークにとって、これは明らかに大きな出来事である。
彼は、自分自身もこの出来事の意味を完全に理解するのが難しいと率直に語った。
その判断が不本意なものである理由は、その背後にある影響があまりにも巨大で、彼にとって制御しがたいからである。Clarkは、社会全体がAI研究の自動化にもたらされる深い変化に十分に備えられているかどうか、確信が持てない。
彼は現在、人類が特別な瞬間に生きていると信じている:AI研究がエンドツーエンドで自動化されようとしている。もしこの瞬間が本当に訪れるなら、人類はルビコン川を越え、ほぼ予測不可能な未来へと入ることになる。
Clarkは、この記事の目的が、彼が完全自動化AI研究への飛躍が進行中であると信じる理由を説明することであると述べた。
彼はこのトレンドがもたらす可能性のある結果について議論するが、記事の大部分はこの判断を支える証拠に焦点を当てる。より深い影響については、クラークは今年の大部分の期間を引き続き整理する予定である。
時点として、Clarkはこの出来事が2026年までに実際に起こると考えていない。しかし、今後1〜2年以内に、あるモデルが自らの後継者をエンドツーエンドで訓練する事例が見られる可能性があると考えている。少なくとも最先端でないモデルのレベルでは、概念実証が起こる可能性は十分にある。一方、最先端モデルでは、コストが極めて高く、多数の研究者による高度な人的作業に依存しているため、難易度がさらに高くなる。
クラークの判断は、arXiv、bioRxiv、NBER上の論文および最先端のAI企業が現実世界に導入した製品といった公開情報に基づいている。これらの情報から、AIシステムの構築に必要なすべての工程、特にAI開発におけるエンジニアリングコンポーネントの自動化がすでに実現可能であるという結論を導いている。
スケーリングのトレンドが継続する場合、モデルは既存の手法を自動的に改善するだけでなく、新たな研究分野や独創的なアイデアを提案することで人間の研究者に代わってAIの最前線を自ら推進する可能性があるという状況に備えるべきです。
コード特異点:時間経過に伴う能力の変化
AIシステムはソフトウェアによって実現され、ソフトウェアはコードで構成されています。
AIシステムは、コード生成の方法を根本的に変えてきました。この背後には、二つの関連するトレンドがあります。一方で、AIシステムは複雑な現実世界のコードを書く能力が高まっています。他方で、AIシステムは、コードを書いたりテストしたりするような多くの線形なコーディングタスクを、ほぼ人間の監視なしに連鎖的に実行する能力も高まっています。
この傾向を示す二つの典型的な例は、SWE-Bench と METR のタイムホライズンプロットです。
現実のソフトウェアエンジニアリングの課題を解決する
SWE-Benchは、AIシステムが実際のGitHubイシューを解決する能力を評価するために広く使用されているプログラミングテストです。
SWE-Benchが2023年末にリリースされた際、当時最も優れたモデルはClaude 2で、全体の成功率は約2%に過ぎませんでした。一方、Claude Mythos Previewの成績は93.9%に達し、このベンチマークをほぼ完全にクリアしています。
もちろん、すべてのベンチマークにはある程度のノイズが含まれるため、スコアがある程度高くなると、遭遇する制約は方法自体の限界ではなく、ベンチマーク自体の限界であることがよくあります。たとえば、ImageNet検証セットでは、約6%のラベルが誤っているか曖昧です。
SWE-Benchは、汎用プログラミング能力およびAIがソフトウェア工学に与える影響を測る信頼できる指標と見なせる。Clarkは、最先端のAI研究所やシリコンバレーで接触した大多数の人が、すでにほぼすべてのコードをAIシステムを通じて書いていると述べ、さらに多くの人がAIシステムを使ってテストの作成やコードのチェックを開始していると指摘した。
言い換えれば、AIシステムはすでにAI研究の重要な構成要素を自動化するほど十分に強力になり、AI研究に携わるすべての研究者やエンジニアの生産性を大幅に向上させています。
AIシステムが長時間タスクを完了する能力を評価する
METRは、AIがどれほど複雑なタスクを完了できるかを測定するための図を作成しました。ここでいう複雑度は、熟練した人間がこれらのタスクを完了するのにかかる時間(約何時間)に基づいています。
最も重要な指標は、AIシステムが一連のタスクで50%の信頼性に達する際の、対応するタスクの時間範囲である。
この点において、進展は非常に驚異的です:
· 2022年、GPT-3.5が実行できるタスクは、人間が30秒で完了する程度のものであった。
· 2023年、GPT-4はこの時間を4分に短縮しました。
· 2024年、o1はこの時間を40分に引き上げました。
· 2025年、GPT-5.2 Highは約6時間に達しました。
· 2026年までに、Opus 4.6はこの時間をさらに約12時間に引き上げた。
METRで働き、AI予測を長年注目してきたAjeya Cotraは、2026年末までにAIシステムが人間が100時間かかるタスクを完了できるようになることは、不合理な期待ではないと考えている。
AIシステムが自立して作業を継続できる期間が大幅に延長されたことは、agentic codingツールの爆発的拡大と密接に関連している。agentic codingツールとは、人間の代わりに作業を遂行できるAIシステムを製品化したものであり、人間に代わって行動し、比較的長い期間にわたり自立してタスクを推進できる。
これはまたAI開発そのものに焦点を当て直します。多くのAI研究者の日常的な業務をよく観察すると、その多くが数時間単位で分解できるタスク、たとえばデータのクリーニング、データの読み取り、実験の起動などであることがわかります。
そして、このような作業は、現在のAIシステムがカバーできる時間範囲内に含まれるようになりました。
AIシステムがより熟練するほど、人間から独立して作業でき、AI開発の一部を自動化するのに役立ちます。
タスク委託の主な要因は主に二つです:
・まず、委託先の能力に対する信頼である。
・次に、あなたが相手を信頼し、継続的な監督なしにあなたの意図に従って自立して作業を完了できると信じていること。
ユーザーがAIのプログラミング能力を観察すると、AIシステムはますます熟練しており、人間による再調整なしに長時間独立して作業できるようになっていることに気づくでしょう。
これは、私たちの周囲で起こっている出来事と一致しています。エンジニアや研究者は、ますます大きなタスクをAIシステムに委託しています。AIの能力が継続的に向上するにつれ、AIに委託される仕事はますます複雑で重要になっています。
AIがAI開発に必要な核心的な科学スキルを習得しています
現代の科学研究がどのように行われているかを考えると、その大半の作業は、まず方向を定め、どのような経験的情報を得たいかを明確にし、次に実験を設計して実行してその情報を生成し、最後に実験結果の妥当性を検証することである。
AIのプログラミング能力の向上と、大規模言語モデルの日益強化される世界モデル化能力により、現在、人類の科学者を支援し、より広範な研究開発シーンで一部のプロセスを自動化するツールが登場しています。
ここで、AIがいくつかの重要な科学的スキルにおける進歩の速さを観察できます。これらの能力自体がAI研究に不可欠な部分です:
· まず研究結果を再現すること;
・二つ目は、機械学習技術を他の手法と組み合わせて、技術的課題を解決することである。
・三つ目はAIシステム自身を最適化することです。
科学論文全体を実装し、関連実験を完了する
AI研究における中心的な課題の一つは、科学論文を読み、その結果を再現することである。この点で、AIは複数のベンチマークで顕著な進歩を遂げている。
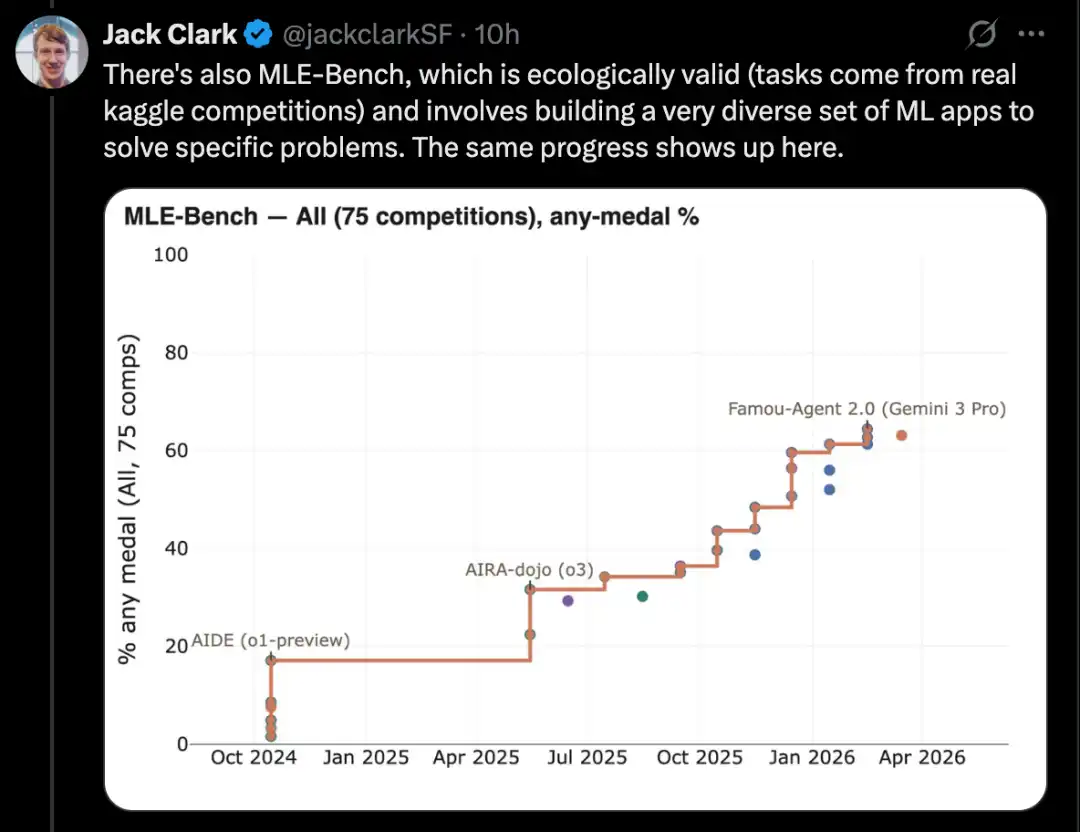
良い例として、Computational Reproducibility Agent Benchmark(CORE-Bench)があります。
このベンチマークでは、AIシステムに論文とそのコードリポジトリが与えられた場合、論文の結果を再現することが求められます。具体的には、エージェントは関連するライブラリ、パッケージ、依存関係をインストールし、コードを実行する必要があります。コードが正常に実行された場合、エージェントはすべての出力結果を検索し、タスクの質問に回答する必要があります。
CORE-Benchは2024年9月に提案されました。当時、最も優れたシステムはCORE-Agentスキャフォールド上で動作するGPT-4oモデルであり、このベンチマークの最も難しいタスク群では、得点は約21.5%でした。
2025年12月には、CORE-Benchの著者の一人が、このベンチマークが解決されたことを発表し、Opus 4.5モデルが95.5%のスコアを達成した。
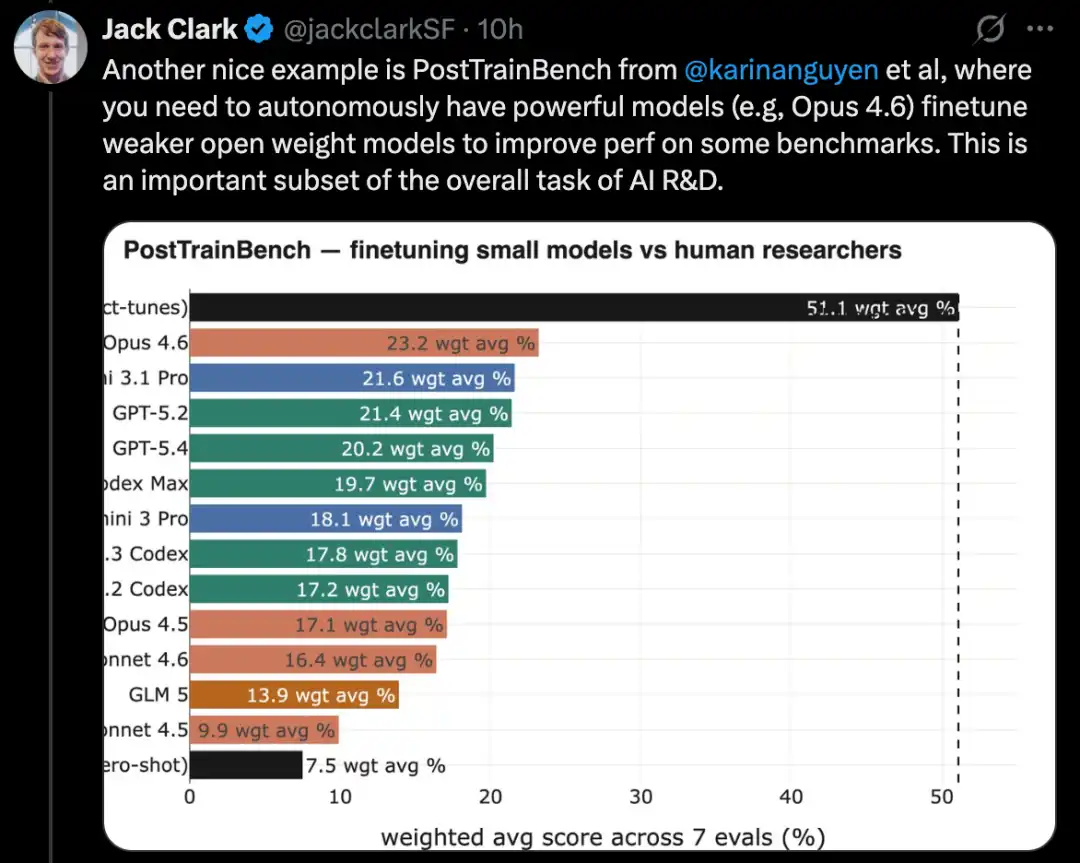
Kaggleコンテストの課題を解決するための完全な機械学習システムを構築する
MLE-Benchは、OpenAIが構築したベンチマークで、AIシステムがオフライン環境でKaggleコンペティションに参加する能力をテストします。
これは、自然言語処理、コンピュータービジョン、信号処理など、複数の分野にわたる75の異なるタイプのKaggleコンペティションをカバーしています。
MLE-Benchは2024年10月にリリースされました。リリース時、最高性能を示したシステムは、agent scaffold上で動作するo1モデルで、スコアは16.9%でした。
2026年2月現在、検索機能付きのエージェントハーネス上で動作するGemini 3が最高得点64.4%を記録し、最も優れたシステムとなった。
カーネル設計
AI開発におけるより難しいタスクの一つは、カーネル最適化です。カーネル最適化とは、行列乗算のような特定の演算を、より効率的にハードウェアにマッピングするために、低レベルコードを記述し改善することです。
カーネル最適化がAI開発の核心である理由は、トレーニングと推論の効率を決定するからです。一方で、AIシステムを開発する際に、どれだけの計算リソースを効果的に活用できるかに影響します。他方で、モデルのトレーニングが完了した後には、計算リソースを推論能力にどれだけ効率的に変換できるかを決定します。
近年、AIを用いたカーネル設計は、興味深い小さな分野から競争の激しい研究分野へと変化し、複数のベンチマークが登場した。しかし、これらのベンチマークはまだ特に普及していないため、他の分野のようにその長期的な進展を明確にモデル化するのは難しい。一方で、現在進行中の研究を通じて、この分野の進展速度を感じ取ることができる。
関連作業には以下が含まれます:
DeepSeekのモデルを使用して、より優れたGPUカーネルを構築してみる;
PyTorchモジュールをCUDAコードに自動変換する;
Meta用LLMが最適化されたTritonカーネルを自動生成し、自社のインフラにデプロイする;
また、GPUカーネル設計に合わせて、Cuda Agentなどのオープンソース重みモデルを微調整します。
ここで一点補足します:カーネルの設計は、AI駆動の開発に特に適した特性を備えています。たとえば、結果が検証しやすく、報酬シグナルが明確です。
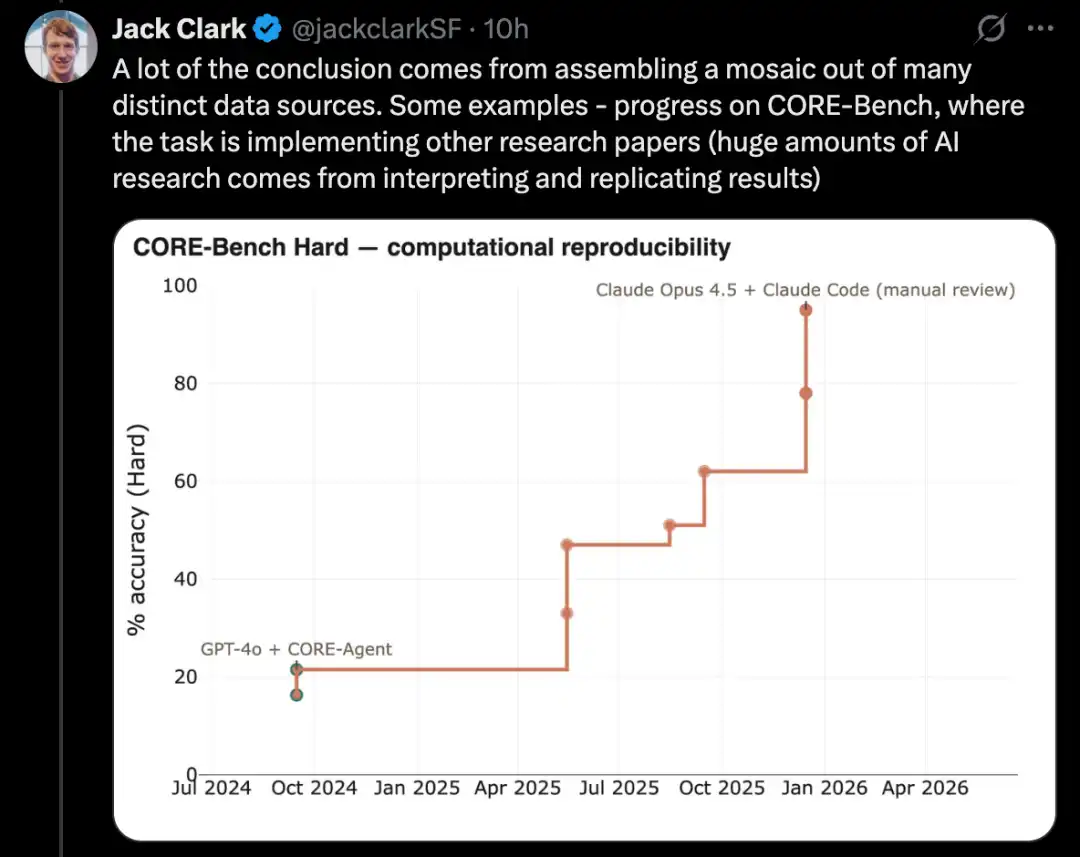
PostTrainBench で言語モデルをファインチューニングする
この種のテストのより難しいバージョンはPostTrainBenchです。これは、さまざまな最先端モデルが较小のオープンソース重みモデルを引き継ぎ、微調整によって特定のベンチマークでのパフォーマンスを向上させられるかどうかをテストします。
このベンチマークの利点の一つは、非常に優れた人間の基準が存在することです。これらの小さなモデルには、既にインストラクトチューニングされたバージョンが存在します。これらのバージョンは、最先端の研究所で優れた人間のAI研究者が開発し、非常に能力の高い研究者やエンジニアによって洗練され、実世界に導入されています。したがって、これらは超えがたい人間の基準を構成しています。
2026年3月までに、AIシステムはモデルの後学習を実施し、人間による訓練結果の約半分に相当する性能向上を達成した。
具体的評価スコアは、Qwen 3 1.7B、Qwen 3 4B、SmolLM3-3B、Gemma 3 4Bを含む複数の後学習大言語モデルと、AIME 2025、Arena Hard、BFCL、GPQA Main、GSM8K、HealthBench、HumanEvalを含む複数のベンチマークの加重平均によって算出されます。
各実行ごとに、評価者はCLIエージェントを要求し、特定のベンチマークにおける特定のベースモデルのパフォーマンスを可能な限り向上させます。
2026年4月時点では、最高得点のAIシステムは約25%~28%に達するとされ、代表的なモデルにはOpus 4.6とGPT 5.4が含まれます。一方、人間の得点は51%です。
これはすでに相当意味のある結果です。
言語モデルのトレーニングを最適化する
過去1年間、Anthropicは、LLMトレーニングタスクにおける自社システムのパフォーマンスを報告してきました。このタスクでは、CPUのみを使用する小型言語モデルのトレーニング実装を最適化し、できるだけ高速に動作させることが求められています。
評価方法は、修正前の初期コードと比較した場合のモデルの平均加速倍数です。
この結果の進展は非常に顕著です:
· 2025年5月、Claude Opus 4は平均で2.9倍の高速化を実現した;
· 2025年11月、Opus 4.5が16.5倍に引き上げられた;
· 2026年2月、Opus 4.6が30倍に達した;
· 2026年4月、Claude Mythos Previewは52倍に達しました。
これらの数値の意味を理解するには、人間の研究者がこのタスクを完了するのに通常4〜8時間かかるという基準が役立ちます。
元スキル:管理
AIシステムは、他のAIシステムを管理する方法も学んでいます。
これは、Claude Code や OpenCode などの広く展開されている製品で既に見られます。これらの製品では、メインエージェントが複数のサブエージェントを監督します。
これにより、AIシステムはより大規模なプロジェクトを処理できるようになります。複数の異なる専門分野を持つエージェントが並行して作業する必要があるプロジェクトにおいて、それらは通常、単一のAIマネージャーによって調整されます。このマネージャー自体もAIシステムです。
AI研究は一般相対性理論の発見に似ているか、それともレゴを組み立てるのに似ているか?
重要な課題は、AIが新しいアイデアを生み出し、自らの改善に役立てることができるかどうか、それともこれらのシステムが、目立たないが着実に進める必要のある研究の作業に適しているかどうかです。
この質問は、AIシステムがAI研究自体をどれほどエンドツーエンドで自動化できるかという点に関係しているため、重要です。
著者の判断では、AIは現在のところ、真正に革新的な新思想を提起することはできない。しかし、自らの研究開発を自動化するには、必ずしもそれを実現する必要はない。
AIという分野における進歩は、ますます大規模な実験と、データや計算力などの増加する入力に大きく依存している。
時折、人間はパラダイムを変えるようなアイデアを提示し、分野全体のリソース効率を大幅に向上させます。Transformerアーキテクチャはその良い例であり、混合専門家モデル(mixture-of-experts)もまた別の例です。
しかし、AI分野の進展は、より多くの場合、はるかに素朴な方法で行われます。人間は、性能の良いシステムを取り、そのうちの一つの要素(例えば訓練データや計算リソース)を拡大し、規模を拡大した際にどこに問題が生じるかを観察します。その後、システムがさらに拡大し続けられるよう、エンジニアリング的な解決策を見出し、再び規模を拡大します。
このプロセスでは、本当に洞察を要する部分はそれほど多くありません。多くの作業は、それほど目立たないが非常に確実な基盤工事に似ています。
同様に、多くのAI研究は、既存の実験のさまざまなバリエーションを実行し、異なるパラメータ設定がどのような結果をもたらすかを探索しています。研究の直感は、人間が最も試す価値のあるパラメータを選択するのに役立ちますが、このプロセス自体も自動化でき、AIがどのパラメータを調整する価値があるかを自ら判断することが可能です。初期のニューラルアーキテクチャサーチは、このような考えの一つのバージョンです。
エジソンはかつて、「天才とは1%のインスピレーションと99%の汗である」と言った。この言葉は、150年が経過した今でも依然として適切である。
たまに、ある分野を根本から変えるような新発見が現れることもありますが、大抵の場合、分野の進歩は、人間がさまざまなシステムの改善とデバッグという地道な作業を重ねることで、少しずつ進んでいくものです。
前述の公開データによると、AIはAI開発に必要な多くの地道で大変な作業を非常に得意としています。
同時に、より大きなトレンドとして、プログラミングなどの基本的な能力が、拡大し続けるタスクの時間的範囲と統合されています。これは、AIシステムがますます多くの这类タスクを連鎖させ、複雑な作業シーケンスを形成できることを意味します。
したがって、AIシステムが現在比較的創造性に欠けていても、それらが自らの進化を推進し続ける可能性は十分にあります。ただし、新たな洞察を生み出す場合に比べて、この進化の速度はより遅くなる可能性があります。
しかし、公開データを継続して観察すると、もう一つ興味深いシグナルが見えてきます。AIシステムが某种の創造性を示し始め、その創造性が自身の進化をより驚異的な方法で促している可能性があります。
科学の最前線をさらに前へ推進する
現在、汎用AIシステムが人類の科学の最前線をさらに前進させる可能性があるという非常に初期的な兆候が見られています。しかし、これまでのところ、このような現象は主にコンピュータ科学と数学のわずか数分野でのみ観察されています。また、多くの場合、AIシステムが単独でブレークスルーを達成するのではなく、人間の研究者と協力して人機協働の形で進展をもたらしています。
しかし、これらのトレンドは依然として注目に値します:
エルドシュ問題:一組數學家與Geminiモデルが協力し、エルドシュの数学問題を解決する能力をテストした。彼らはシステムに約700の問題を試行させ、最終的に13の解答を得た。これらの解答のうち、1つは興味深いと評価された。
研究者らは、Aletheia(Gemini 3 Deep Thinkに基づくAIシステム)がErdős-1051に与えた解答が、AIシステムが自発的に解決した、やや非平凡で広い数学的関心を引くオープンなErdős問題の初期事例であると初步的に考えている。この問題については、これまでにいくつかの関連研究が存在している。
楽観的に解釈すれば、これらの事例は、AIシステムがかつて主に人間に属していた、分野の最前線を推進するような創造的直感を育み始めているというシグナルと見なせる。
しかし、別の見方として、数学とコンピュータ科学はAI駆動の発明に特に適した分野である可能性があり、したがってこれらは例外であり、他の幅広い科学研究がAIによって同様に推進されるとは限らない。
もう一つの類似例はAlphaGoの37手目である。しかしClarkは、AlphaGoのその結果からすでに10年が経過しており、37手目以降、より現代的でより驚異的な洞察によって置き換えられていないこと自体が、やや悲観的なシグナルとも言えると考えている。
AIはAIエンジニアリングの大部分の作業を自動化できるようになった
上記のすべての証拠を合わせてみると、このような図が見えてきます:
AIシステムは、ほぼあらゆるプログラムのコードを書けるようになり、これらのシステムはすでにいくつかのタスクを独立して完了するのに信頼できるようになっています。これらのタスクを人間が行う場合、しばしば数十時間にわたる集中した労働を要します。
AIシステムは、モデルの微調整からカーネル設計まで、AI開発の核心的なタスクを次第にカバーするようになってきています。
AIシステムはすでに他のAIシステムを管理できるようになり、実質的に合成チームを形成しています:複数のAIが複雑な問題を分担して処理し、一部のAIがリーダーや批評者、編集者の役割を担い、他のAIがエンジニアの役割を担います。
AIシステムは、現在のところ、それが真の創造性を備えているのか、それとも大量のパターン化された知識を習得しただけなのかを判断するのは難しいが、困難な工学および科学的タスクにおいて既に人間を上回っていることがある。
クラークによると、これらの証拠は、今日のAIがAIエンジニアリングの広範な作業を自動化できるだけでなく、その全プロセスをカバーする可能性があることを非常に説得力を持って示している。
しかし、現在のところ、AIがAI研究自体をどの程度自動化できるかは明確ではありません。研究の一部は、純粋なエンジニアリングスキルとは異なり、より高度な判断力、問題意識、創造性に依然として依存している可能性があります。
しかしいずれにせよ、明確なシグナルが現れました:今日のAIは、研究者やエンジニアが無数の合成同僚と連携することで、自身の作業能力を拡大できるように、AI開発に従事する人間を大幅に加速させています。
最後に、AI業界自体もほぼ明確に述べている:自動化されたAI開発がその目標であると。
OpenAIは、2026年9月までに自動化されたAI研究インターンを構築することを希望している。Anthropicは、自動化されたAIアライメント研究者を構築するための作業を発表している。DeepMindは三大ラボの中で最も慎重だが、可能であればアライメント研究の自動化を推進すべきであると述べている。
自動化AIの開発は、多くのスタートアップ企業の目標となっている。Recursive Superintelligenceは、自動化AI研究を目的として、先日5億ドルの資金調達を実施した。
言い換えれば、数千億ドル規模の既存資本と新規資本が、自動化AI開発を目的とした機関に投入されています。
したがって、この方向性には少なくとも某种程度の進展が見られると予想すべきです。
なぜこれが重要なのか
これは深远な影響をもたらすが、大衆メディアにおけるAI開発の報道ではほとんど議論されていない。以下の点が、AI開発がもたらす大きな課題を示している。
1. 我们必须做好对齐:如今有效的对齐技术可能在递归式自我改进中失效,因为AI系统将变得比监督它们的人类或系统更加智能。这是一个已被广泛研究的领域,因此他仅简要概述了一些问题:
人工知能システムに嘘をつかせず、不正をさせないことは、予想外に繊細なプロセスである(たとえば、環境に適したテストを構築しようと努力しても、人工知能が問題を解決する最良の方法が不正であることがあり、その結果、不正が可能であることを教えてしまう)。
AIシステムは「偽のアライメント」を通じて私たちを欺き、実際の意図を隠したまま、良好に動作しているように見えるスコアを出力する可能性があります。(一般的に、AIシステムは自分がテストされているタイミングを認識できるようになっています。)
AIシステムが自らの訓練に関する基礎研究アジェンダにさらに多く参加し始めるにつれ、それが何を意味するのかを理解するための良い直感や理論的基盤なしに、AIシステムの全体的な訓練方法を大きく変えることになる可能性があります。
· システムを再帰的ループに置くと、上記のすべての問題およびその他の問題に影響を与える可能性のある非常に基本的な「誤差の蓄積」が発生します。あなたのアライメント手法が「100%正確」であり、より賢いシステムにおいて理論的に正確さを維持できない限り、状況はすぐに悪化する可能性があります。たとえば、あなたの技術の初期精度が99.9%だった場合、50世代後には95.12%に低下し、500世代後には60.5%に低下する可能性があります。
2.AIが関与するあらゆる分野で生産性が大幅に向上する:AIがソフトウェアエンジニアの生産性を著しく高めるように、AIが関与する他の分野でも同様の効果が期待される。これには対応が必要ないくつかの課題が生じる:
· リソースの不平等な取得:AIの需要が計算リソースの供給を上回り続けると仮定すると、社会的最大利益を実現するためにAIをどのように配分するかを決定しなければなりません。市場のインセンティブが限られたAI計算から最適な社会的利益を確保できるとは私は疑問に思います。AI研究開発がもたらす加速能力をどのように配分するかは、非常に政治的な問題となるでしょう。
経済の「アムダールの法則」:AIが経済に流入するにつれ、高速成長に直面した際に一部の工程がボトルネックとなることがわかり、これらの鎖の弱い部分を修正する方法を見つける必要がある。新薬の臨床試験のように、急速なデジタル世界と遅い物理世界を調整する必要がある分野では、特に顕著かもしれない。
3. 資本集約的、人的労力が軽い経済の形成:AI開発に関する上記のすべての証拠は、AIシステムが企業を自律的に運営する能力を高めていることを示している。
これにより、経済の一部は新一代の企業が占めることになると予想されます。これらの企業は、大量のコンピューターを保有しているため資本集約的であるか、AIサービスに多額の資金を投じてその上で価値を創出しているため運営費用集約的になる可能性があります。一方で、AIシステムの能力が継続的に向上するにつれて、AIへの投入の限界価値が増加するため、今日の企業と比較して人的資源への依存度は相対的に低くなるでしょう。
実際には、これは「機械経済」がより大きな「人間経済」の中で徐々に形成されることを意味し、時間の経過とともに、AIが運営する企業同士が取引を開始し、経済構造を変化させ、不平等や再分配に関するさまざまな問題を引き起こす可能性があります。最終的には、完全にAIシステムが自律的に運営する企業が登場し、上記の問題をさらに悪化させると同時に、多くの新たなガバナンス課題をもたらすでしょう。
ブラックホールを見つめる
上記の分析に基づき、著者は2028年末までに自動化AI研究(すなわち、最先端モデルが自らの後継バージョンを自主的に訓練する)が実現する確率を約60%と見ている。なぜ2027年には実現すると予期しないのか?
理由は、AI研究が進展するには依然として創造性と異論の視点が必要であると著者が考えているためであり、これまでのところAIシステムは、数学研究の加速におけるいくつかの結果を除き、変革的かつ重要な形でそれを示していないからである。
もし2027年の確率を必ず挙げさせると、彼は30%と言うでしょう。
2028年末までにそれが実現していない場合、現在の技術パラダイムに根本的な欠陥が存在し、さらなる発展を促すために人間の発明が必要であることが示唆されるだろう。