
自己学習型AIエージェントは、従来の機械学習モデルや現在のLLMベースのエージェントとどのように異なるのでしょうか?
2026/05/02 15:21:02
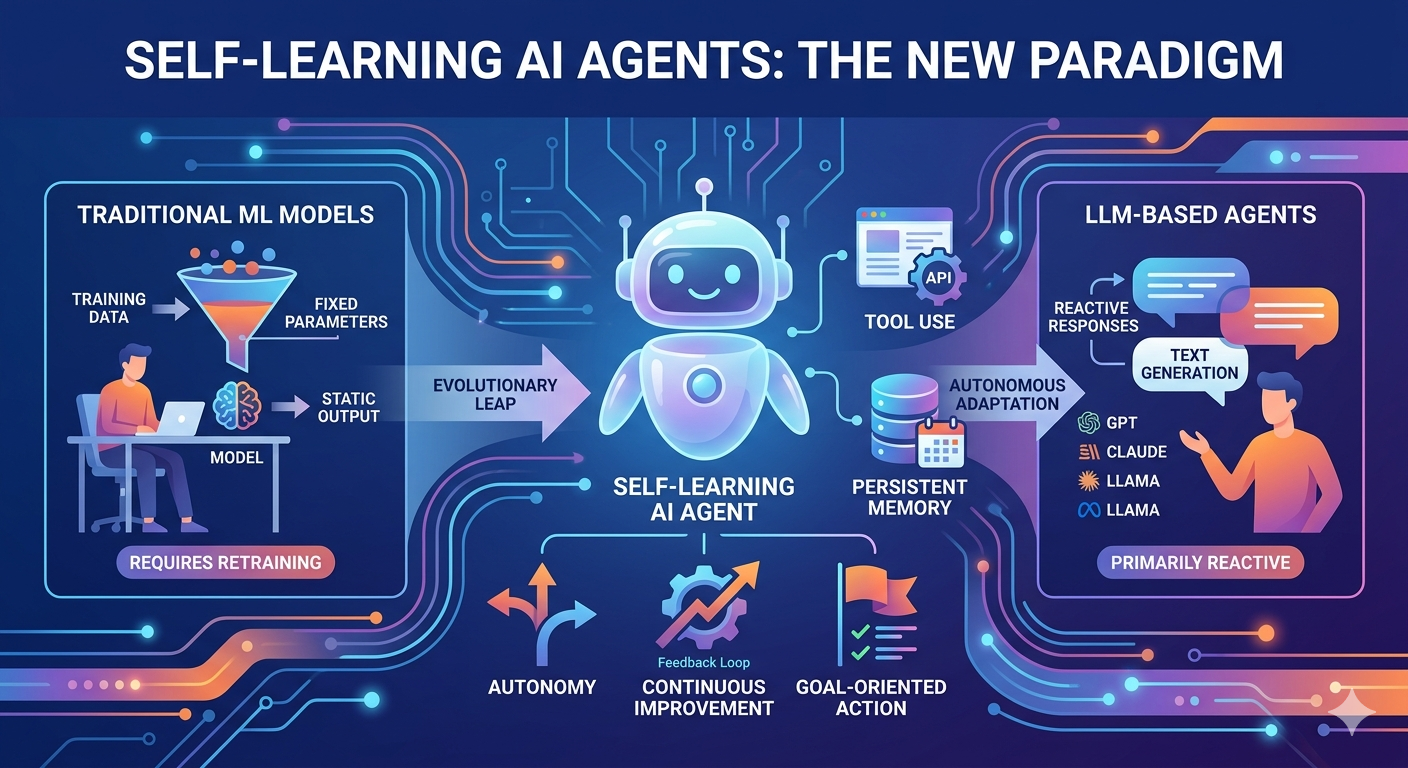
人工知能の領域は、根本的な変革を遂げています。過去10年間は従来の機械学習モデルが支配的であり、2022年以降の大規模言語モデルが世界の注目を集めましたが、AIシステムの動作方法を根本的に変える新たなパラダイムが登場しています。自己学習AIエージェントは、自律性、適応的推論、継続的な改善を組み合わせた次世代の進化段階であり、従来のモデルや現在のLLMベースのシステムとは明確に異なります。この違いを理解することは、急速に進化するAIエコシステムをナビゲートする上で不可欠です。
自己学習型AIエージェントは、環境を認識し、情報を分析し、意思決定を立て、特定の目標を達成するために行動を実行できる自律的な計算エンティティです。従来のAIシステムとは異なり、すべてのステップで人間の指示を必要とせず、高レベルの目的を与えられれば、自らその達成方法を決定できます。これらのエージェントは、知覚、推論、学習、行動の機能を組み合わせることで、これまで生物システムにしか見られなかった知的行動を模倣します。
自己学習AIエージェントの特徴には、自律性、反応性、能動性、社会性が含まれます。自律性により、エージェントは継続的な人間の介入なしに独立して動作できます。反応性により、環境の変化を認識し、適切に応答できます。能動性とは、単に刺激に反応するだけでなく、計画を通じて目標を積極的に追求することを意味します。社会性により、複数エージェントシステム内で他のエージェントと協力して複雑なタスクを完了することが可能になります。
マイクロソフトの2025年AI予測によると、AI駆動エージェントはより多くのタスクを実行するための自律性を高めており、さまざまな分野での生活の質を向上させています。このエージェントの主な違いは、目的の処理方法にあります。大規模言語モデルは高品質な出力を得るために詳細で丁寧に作成されたプロンプトを必要とするのに対し、AIエージェントは目標を示すだけで、自ら考え、必要なアクションを実行します。
従来の機械学習モデルは、人工知能に対する本質的に異なるアプローチを示しています。これらのモデルは、分類、回帰、クラスタリングなどの限定的で明確なタスクを実行するように、特定のデータセットで訓練されます。デプロイ後は、明示的な再学習なしに、新しい経験に基づいて行動を変更することはできません。
従来のMLモデルのアーキテクチャは、履歴データからの統計的学習に中心を置きます。モデルは学習中にパターンを学習し、推論時にこれらの学習したパターンを新しい入力に適用します。このアプローチは、スパム検出、画像分類、レコメンデーションシステムなど、明確なパターンと一貫した入力を持つタスクに非常に適しています。しかし、これらのモデルの静的性質は、動的で予測不可能な環境において大きな制限を生み出します。
従来のMLモデルでは、人間のエンジニアが特徴量を定義し、アルゴリズムを選択し、ハイパーパラメータを調整する必要があります。データの分布が変化したり、タスクの要件が変わったりすると、モデルの性能が低下し、再学習が必要になります。学習プロセスはデプロイ後は本質的に固定され、明示的な介入なしに経験から改善したり、新たな状況に適応したりすることはできません。
セキュリティおよびコンプライアンスチームは、構造化データにおけるパターン認識に従来のMLをよく使用しますが、文脈的理解や複数ステップの推論を要するタスクには対応が困難です。これらのシステムは、計画を立てたり、因果関係を考慮したり、複雑な問題を小さな管理可能なサブタスクに分解したりする能力が欠けています。
現在のLLMベースのエージェントは、従来の機械学習を大幅に進化させたものです。数十億のパラメータを備えた大規模言語モデルに基づいて構築されたこれらのシステムは、自然言語を理解し、人間のようなテキストを生成し、かつてAIでは不可能だった推論タスクを実行できます。OpenAI、Anthropic、Googleなどの企業は、今日の多くのAIアプリケーションの基盤となる、ますます高度なモデルを開発してきました。
LLMベースのエージェントは、自然言語の理解と生成に優れています。意味のある会話の実施、ドキュメントの要約、コードの作成、複雑な概念の説明が可能です。たとえば、OpenAIのo1モデルは、人間の分析と同様に論理的なステップを経て複雑な問題を解決する高度な推論機能を備えています。
ただし、現在のLLMベースのエージェントの多くは本質的に反応型のシステムです。ユーザーのプロンプトには応答しますが、自発的に目標を追求したり、世界で行動を実行したりすることはできません。チャットボットとやり取りする際、システムはあなたの入力と学習データに基づいて応答を生成しますが、継続的な人間のガイドなしには、より広範な目的を達成するために自立して行動することはありません。
LLMベースのエージェントの限界は、複数のステップにわたる継続的な努力、外部ツールとの統合、またはフィードバックに基づく適応を必要とするタスクで顕著になります。これらのモデルは、単一の取引所内で問題を論理的に解決することはできますが、対話間で状態を維持したり、外部システムでアクションを実行したり、自身の意思決定の結果から学習したりする能力が欠けています。
自己学習型AIエージェントと従来の機械学習モデルの違いは、アーキテクチャ、機能、運用哲学に及びます。これらの違いを理解することで、多くの専門家がエージェントをAI開発の次なるフロンティアと見なす理由が明確になります。
-
学習と適応
従来のMLモデルは、固定されたトレーニングフェーズ中に学習し、その後静的に動作します。過去の取引データで訓練された不正検出モデルは、再学習されない限り、同じパターンを永続的に適用します。一方、自己学習エージェントは、環境との相互作用から継続的に学習できます。彼らは自身の行動の結果を観察し、何がうまくいき、何がうまくいかなかったかを分析し、それに応じて戦略を修正します。
-
自律性と目標指向行動
従来のMLモデルは、人間が特定のタスクを達成するために使用するツールです。これらは自ら目標を追求することなく、学習したパターンに従って入力を処理し、出力を生成します。自己学習エージェントは、高レベルの目的を受け取り、それを達成するための最適な行動を決定する目的指向のシステムです。これらは複雑な目標をサブタスクに分解し、それらを実行して、進捗に応じてアプローチを調整します。
-
ツールの使用と環境との相互作用
自己学習エージェントは、外部ツール、API、ソフトウェアシステムと連携できます。インターネットを閲覧し、ファイルを操作し、コードを実行し、データベースとやり取りすることが可能です。従来のMLモデルは、通常、自身の計算グラフ内での入力と出力に制限されており、このような機能を実行できません。
-
文脈の理解と計画
従来の機械学習は構造化データにおけるパターン認識に優れていますが、自己学習エージェントは文脈の理解や複数ステップの解決策の計画においてより優れた能力を発揮します。旅行の計画という目的を与えられたエージェントは、目的地を調査し、価格を比較し、空き状況を確認して予約を手配します—このような行動は静的な分類モデルには不可能です。
自己学習型AIエージェントと現在のLLMベースのエージェントとの違いは微妙ですが、重要な意味を持っています。両者はともに大規模言語モデルをコアコンポーネントとして使用する可能性がありますが、アーキテクチャと動作モードは大きく異なります。
-
反応型と能動型の運用
現在のLLMベースのエージェントの多くは、プロンプトに対する反応型システムであり、ユーザーが質問するとモデルが回答を生成します。しかし、自己学習エージェントは能動的に動作できます。目的が与えられれば、各ステップで人間の入力を待たずに、情報収集、計画立案、アクション実行を自発的に行います。
-
ステート管理とメモリ
従来のLLMは、各会話をステートレスと見なしますが、一部の実装ではコンテキストウィンドウを追加しています。自己学習エージェントは、セッション間で情報を維持し、目標への進捗を追跡し、過去の経験から学習できる高度なメモリシステムを導入しています。この永続的なメモリにより、エージェントは毎回新たに開始するのではなく、以前の作業を基に構築できます。
-
ツールの統合とアクションの実行
LLMベースのエージェントは、そのテキストがコードやコマンドを表す場合でも、主にテキストを生成します。自己学習エージェントは、これらのコマンドを実際に実行し、外部システムと相互作用することを目的として設計されています。OpenAIのOperatorやClaudeのComputer Useは、AIがブラウザ、コマンドラインインターフェース、ソフトウェアアプリケーションを制御できるようにするという、この方向への初期のステップです。
-
動的ワークフロー適応
LLMベースのエージェントが障害に直面した場合、通常は失敗するかエラーメッセージを生成します。自己学習エージェントは、初期のアプローチがうまくいかないことを認識し、その理由を分析して戦略を動的に調整できます。この繰り返しと適応の能力は、計画通りに進むことがめったにない複雑な現実世界のタスクを処理する上で不可欠です。
自己学習エージェントの特徴を理解するには、その基盤となるアーキテクチャを検討する必要があります。これらのシステムは、自律的で適応的な行動を可能にする複数のコンポーネントを組み合わせています。
-
計画および推論エンジン
自己学習エージェントの核心には、大規模言語モデルによって駆動される推論エンジンがあり、複雑な目標を実行可能なステップに分解できます。このエンジンにより、エージェントは計画を立て、因果関係を考察し、潜在的な行動の結果を評価することが可能になります。マイクロソフトの研究によると、学習方法とエージェントの能力は相乗効果を生み出す可能性があり、改善されたモデルはより効果的なエージェントを実現します。
-
メモリーシステム
自己学習エージェントは、複数の種類のメモリを維持します:現在のタスク用の短期作業メモリ、永続的な知識用の長期メモリ、過去の経験用のエピソード記憶です。これらのメモリシステムにより、エージェントはフィードバックから学び、成功した戦略を記憶し、同じ過ちを繰り返さないようにできます。これらのメモリシステムの洗練度が、真に自己学習するエージェントと単純な反応型システムを区別します。
-
ツールの使用とAPI統合
エージェントは、外部ツールを呼び出したり、データベースにアクセスしたり、ウェブを閲覧したり、ソフトウェアアプリケーションとやり取りしたりする機能を備えています。このツール利用機能により、エージェントの範囲は純粋なテキスト生成を超えて、現実世界のアクションへと拡張されます。エージェントはタスクに応じて適切なツールを選択し、ツール呼び出しを実行して、その結果を推論に組み込むことができます。
-
フィードバックと学習メカニズム
自己学習エージェントの最も特徴的な機能は、経験から学習できる能力です。エージェントがタスクを試行する際、結果を評価し、何がうまくいかなかったかを特定して、今後の試行でアプローチを修正できます。この学習は、強化学習、自己反省、反復的改良などのさまざまなメカニズムを通じて実現されます。
自己学習型AIエージェントの独自の機能により、さまざまな業界で新しいアプリケーションが実現されています。マイクロソフトは、フォーチュン500企業の従業員のほぼ70%が、既にTeams会議中のメールフィルタリングや会議ノート作成などの繰り返し作業にMicrosoft 365 Copilotエージェントを活用していると報告しています。
サプライチェーン管理では、エージェントは過去のデータとリアルタイムの情報を基に在庫需要の変動を予測し、在庫切れや過剰在庫を回避するために調達および生産計画を調整できます。医療分野では、エージェントは患者の症例を分析し、膨大な医療文献や患者記録を処理することで診断の提案や治療計画の支援を行えます。
その影響は効率の向上を超えて広がっています。自己学習エージェントは、知識労働の実行方法を変革しています。人間がAIツールの使い方を学ぶのではなく、パラダイムは、人間をより効果的に支援するために学習するAIエージェントへと移行しています。これは、人間がツールを操作するから、自律エージェントと監督・協力する関係へと、人間とAIの関係における根本的な変化を表しています。
自己学習型AIエージェントを活用したい組織は、エージェントの機能が従来のアプローチと比較して大きな利点をもたらす高価値のユースケースを特定することから始めるべきです。複数ステップのプロセス、外部システムとの統合、または動的環境を伴うタスクは、エージェント導入の最適な候補です。
エージェントの運用を支えるため、技術基盤の進化が必要です。これには、堅牢なAPI統合、安全なツールアクセス、エージェントのパフォーマンスを追跡し問題を検出するモニタリングシステムが含まれます。組織は、関連する規制への準拠を確保しながら、エージェントの自律性の適切な範囲を定義するガバナンスフレームワークを確立すべきです。
これらのシステムがより広く普及するにつれ、組織全体におけるエージェントリテラシーの投資が不可欠になります。従業員はエージェントの動作方法、効果的なガイドanceの与え方、およびエージェント出力の評価と改善方法を理解する必要があります。この変化には技術的な投資だけでなく、文化的な適応も必要です。
自己学習型AIエージェントは、人工知能の能力における根本的な進歩を表しています。従来の機械学習モデルが静的でタスク特化型であるのに対し、エージェントは自律的に適応し、計画を立て、複雑なワークフローを実行できます。現在のLLMベースのシステムと比較して、エージェントは能動的な操作、永続的なメモリ、およびツール統合を通じた現実世界での行動実行能力を追加します。
反応型AIから自律エージェントへの移行は、狭義のAIから汎用言語理解への移行と同等のパラダイムシフトを意味します。これらの違いを理解し、それに応じて準備を整えた組織が、自己学習エージェントの変革的潜力を最大限に活用する立場にあります。エージェントの時代は到来しようとしているのではなく、すでに到来しており、仕事のやり方やAIが達成できる範囲を再定義しています。
AIエージェントと従来の機械学習モデルの主な違いは何ですか?
従来のMLモデルは、学習中にパターンを学習し、新しい入力に静的に適用するため、適応するために再学習が必要です。自己学習AIエージェントは、経験から継続的に学習し、新しい状況に適応し、人間の継続的な介入や再学習なしに自律的に動作できます。
自己学習型AIエージェントは、現在のLLMベースのチャットボットを置き換えることができるでしょうか?
AIエージェントとLLMは異なる目的を持ち、競合するというよりむしろ補完的な関係です。LLMは言語の理解と生成に優れ、エージェントは自律性、行動能力、適応的学習を追加します。多くのエージェントは、計画、メモリ、ツール利用のレイヤーを追加しながら、LLMを推論エンジンとして実際に使用しています。
自己学習型AIエージェントは、従来のMLモデルよりもより多くの計算リソースを必要としますか?
自己学習エージェントは、その複雑さ、永続的な状態管理、およびしばしばより大きな基盤モデルのため、より多くの計算リソースを必要とします。しかし、自律的な運用による効率の向上と人間の監督の必要性の削減により、多くのアプリケーションでこれらのコストを相殺できます。
自己学習エージェントは、エラーと失敗をどのように処理しますか?
自己学習エージェントは、自分のアプローチが効果を発揮していないことを認識し、失敗の原因を分析して戦略を動的に調整できます。この繰り返しの改善機能により、静的システムよりも予測不可能な状況に優れた対応が可能ですが、堅牢なエラーハンドリングと人間の監督が依然として重要です。
自習型AIエージェントはビジネス利用に安全ですか?
適切なガードレールを備えて設計されれば、自己学習エージェントはビジネス環境に安全に導入できます。組織はエージェントの自律性に対する明確な境界を設定し、監視システムを構築し、重要な意思決定には人間の監督を維持すべきです。鍵となるのは、エージェントの機能と適切なガバナンスフレームワークのバランスを取ることです。
免責事項: このページは、お客様の便宜のためにAI技術(GPT活用)を使用して翻訳されています。最も正確な情報については、元の英語版を参照してください。