










Hãy tưởng tượng cảnh này:
Bạn nhờ AI Agent giúp sửa một lỗi mã. Nó mở dự án, đọc 20 tệp, chỉnh sửa một chút, chạy thử nghiệm, không qua, lại sửa, lại chạy, vẫn không qua… lặp đi lặp lại hơn chục vòng, cuối cùng—vẫn chưa sửa xong.
Bạn tắt máy tính và thở phào nhẹ nhõm. Sau đó, bạn nhận được hóa đơn API.
Con số trên có thể khiến bạn phải thốt lên—AI Agent tự sửa lỗi trên API chính thức của nước ngoài, mỗi nhiệm vụ chưa được sửa thường tốn hơn một triệu Token, chi phí có thể lên tới vài chục đến hơn một trăm đô la Mỹ.
Tháng 4 năm 2026, một bài nghiên cứu do Stanford, MIT, Đại học Michigan và các trường khác cùng công bố đã lần đầu tiên hệ thống hóa việc mở ra “hộp đen tiêu dùng” của AI Agent trong các nhiệm vụ mã hóa – tiền đã được chi vào đâu, chi có xứng đáng không, và có thể dự đoán trước được không – câu trả lời khiến mọi người kinh ngạc.
Phát hiện thứ nhất: Tốc độ chi tiền để Agent viết mã nhanh gấp 1000 lần so với cuộc hội thoại AI thông thường
Bạn có thể nghĩ rằng, việc nhờ AI viết mã cho bạn và việc nhờ AI trò chuyện về mã với bạn sẽ tốn khoảng bằng nhau.
Bài luận đưa ra so sánh cho thấy:
Lượng token tiêu thụ cho nhiệm vụ mã hóa Agentic gấp khoảng 1000 lần so với các nhiệm vụ hỏi đáp mã và suy luận mã thông thường.
Chênh lệch đến ba cấp độ.
Tại sao lại như vậy? Bài luận đã chỉ ra một thực tế rằng tiền không được chi cho việc “viết mã”, mà được chi cho việc “đọc mã”.
Ở đây, “đọc” không có nghĩa là con người đọc mã, mà là Agent trong quá trình làm việc cần liên tục “cung cấp” toàn bộ ngữ cảnh dự án, lịch sử thao tác, thông báo lỗi và nội dung tệp cho mô hình. Mỗi vòng đối thoại thêm vào sẽ làm ngữ cảnh trở nên dài hơn; trong khi mô hình được tính phí theo số lượng Token – bạn cung cấp càng nhiều, chi phí càng cao.
Hãy tưởng tượng: giống như bạn thuê một thợ sửa chữa, nhưng trước khi anh ta vặn một chiếc ốc nào, bạn phải đọc toàn bộ bản vẽ của cả tòa nhà cho anh ta nghe từ đầu đến cuối—tiền đọc bản vẽ còn đắt hơn cả tiền vặn ốc.
Bài luận tóm tắt hiện tượng này thành một câu: Chi phí thúc đẩy Agent là do sự tăng trưởng theo cấp số nhân của Token đầu vào, chứ không phải Token đầu ra.
Phát hiện thứ hai: Cùng một lỗi, chạy hai lần, chi phí có thể chênh lệch gấp đôi—và những lỗi đắt tiền càng không ổn định
Điều khiến bạn đau đầu hơn là tính ngẫu nhiên.
Các nhà nghiên cứu đã cho cùng một Agent chạy cùng một nhiệm vụ 4 lần và phát hiện ra:
- Giữa các nhiệm vụ khác nhau, nhiệm vụ đắt nhất tiêu tốn khoảng 7 triệu Token nhiều hơn nhiệm vụ rẻ nhất (Hình 2a)
- Trong nhiều lần chạy cùng mô hình và cùng nhiệm vụ, chi phí cao nhất khoảng gấp đôi chi phí thấp nhất (Hình 2b)
- Nếu so sánh cùng một nhiệm vụ giữa các mô hình khác nhau, mức tiêu thụ cao nhất và thấp nhất có thể chênh lệch lên đến 30 lần.
Con số cuối cùng đặc biệt đáng chú ý: điều này có nghĩa là sự chênh lệch chi phí giữa việc chọn đúng mô hình và chọn sai mô hình không chỉ là “đắt hơn một chút”, mà là “đắt hơn một cấp độ”.
Điều khiến đau lòng hơn là – chi nhiều không đồng nghĩa với làm tốt.
Nghiên cứu phát hiện một đường cong hình chữ “U ngược”:
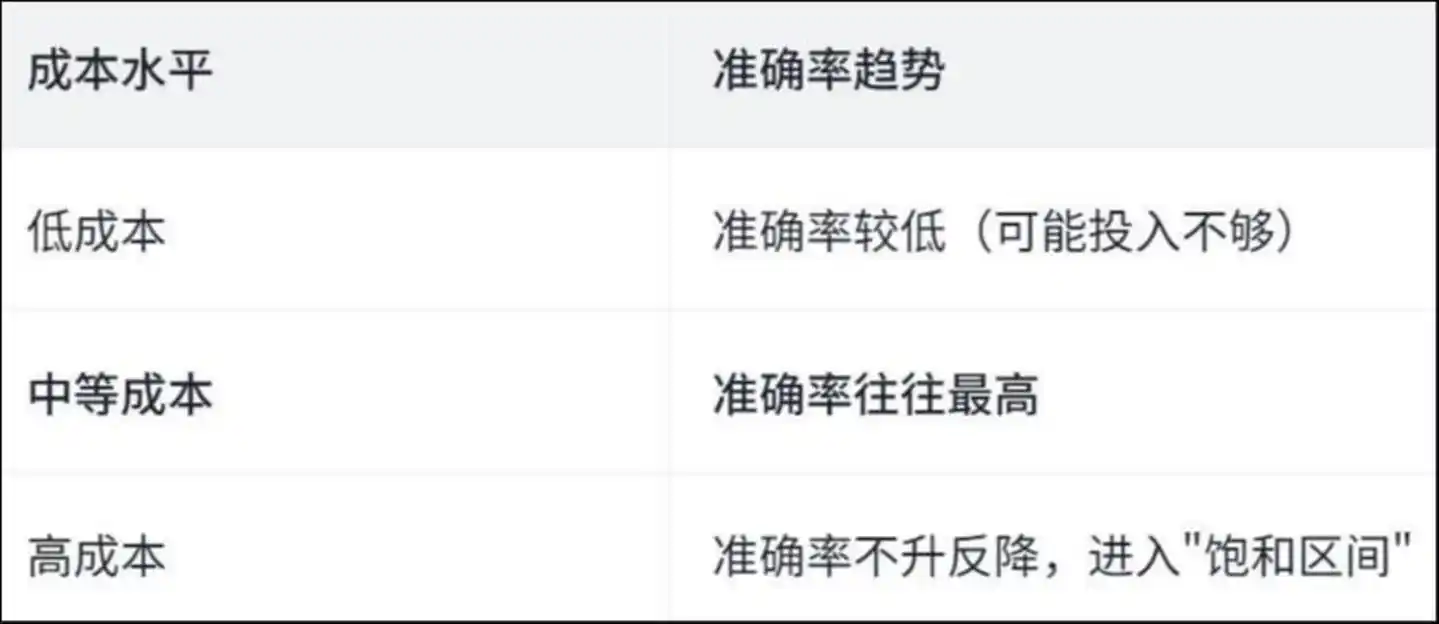
Xu hướng độ chính xác mức chi phí: Chi phí thấp, độ chính xác thấp (có thể đầu tư chưa đủ); chi phí trung bình, độ chính xác thường cao nhất; chi phí cao, độ chính xác không tăng mà ngược lại giảm, bước vào "vùng bão hòa"
Tại sao lại như vậy? Bài luận đã đưa ra câu trả lời thông qua việc phân tích các thao tác cụ thể của Agent—
Trong quá trình vận hành chi phí cao, Agent đã dành phần lớn thời gian vào những “công việc lặp lại”.
Nghiên cứu phát hiện rằng trong các quy trình chi phí cao, khoảng 50% các thao tác xem và chỉnh sửa tệp là lặp lại — tức là Agent liên tục đọc cùng một tệp, liên tục sửa cùng một dòng mã, giống như một người đang quay vòng trong một căn phòng, quay càng nhiều càng chóng mặt, càng chóng mặt càng quay.
Tiền không được dùng để giải quyết vấn đề, mà bị tiêu tốn vào việc “đi lạc”.
Phát hiện thứ ba: Hiệu suất năng lượng giữa các mô hình chênh lệch rất lớn—GPT-5 tiết kiệm nhất, một số mô hình tiêu tốn tới 1,5 triệu token nhiều hơn
Bài báo đã kiểm tra hiệu suất của 8 mô hình lớn tiên tiến trên SWE-bench Verified, tiêu chuẩn ngành với 500 vấn đề GitHub thực tế. Tính theo đô la, các mô hình có hiệu quả token cao có thể tiết kiệm vài chục đô la cho mỗi nhiệm vụ. Khi áp dụng vào các ứng dụng doanh nghiệp—chạy hàng trăm nhiệm vụ mỗi ngày—sự khác biệt này trở thành tiền thật.
Một phát hiện thú vị hơn là: Hiệu suất của Token là “tính cách bẩm sinh” của mô hình, chứ không phải do nhiệm vụ gây ra.
Các nhà nghiên cứu đã tách riêng các nhiệm vụ mà tất cả các mô hình đều giải thành công (230 nhiệm vụ) và các nhiệm vụ mà tất cả các mô hình đều thất bại (100 nhiệm vụ) để so sánh, và phát hiện ra rằng thứ hạng tương đối của các mô hình gần như không thay đổi.
Điều này cho thấy: một số mô hình vốn dĩ “nói nhiều”, không liên quan nhiều đến độ khó của nhiệm vụ.
Một phát hiện đáng suy ngẫm khác: mô hình thiếu ý thức về lệnh cắt lỗ.
Khi đối mặt với các nhiệm vụ khó mà tất cả các mô hình đều không thể giải quyết, một Agent lý tưởng nên từ bỏ sớm thay vì tiếp tục lãng phí tiền bạc. Nhưng thực tế là, các mô hình thường tiêu tốn nhiều Token hơn trên các nhiệm vụ thất bại—chúng không “đầu hàng”, mà chỉ tiếp tục khám phá, thử lại, đọc lại ngữ cảnh, giống như một chiếc xe không có đèn cảnh báo hết xăng, chạy đến khi hỏng hóc.
Phát hiện thứ tư: Những gì con người cảm thấy khó, Agent không nhất thiết cảm thấy đắt—nhận thức về độ khó hoàn toàn bị lệch hướng
Bạn có thể đang nghĩ: Vậy ít nhất tôi có thể ước tính chi phí dựa trên mức độ khó của nhiệm vụ chứ?
Các chuyên gia con người được mời để đánh giá độ khó của 500 nhiệm vụ, sau đó so sánh với lượng Token thực tế mà Agent đã tiêu thụ—
Kết quả: Chỉ có mối tương quan yếu giữa hai yếu tố này.
Nói một cách dễ hiểu: Những nhiệm vụ mà con người cho là cực kỳ khó khăn, Agent có thể xử lý dễ dàng với chi phí thấp; nhưng những nhiệm vụ mà con người cho là đơn giản, Agent có thể tốn kém đến mức khiến bạn phải nghi ngờ cuộc đời.
Đó là vì độ khó mà con người và AI “thấy” hoàn toàn không giống nhau:
- Con người nhìn vào: độ phức tạp logic, độ khó của thuật toán, ngưỡng hiểu biết về nghiệp vụ
- Agent đang xem xét: dự án lớn đến đâu, cần đọc bao nhiêu tệp tin, đường đi khám phá dài bao nhiêu, và liệu có thường xuyên sửa đổi cùng một tệp tin không
Một chuyên gia con người cho rằng lỗi “chỉ cần sửa một dòng” thì Agent có thể cần phải đọc hiểu toàn bộ cấu trúc mã nguồn mới xác định được dòng đó—chỉ riêng việc “đọc” đã tiêu tốn rất nhiều Token. Trong khi đó, một bài toán thuật toán mà con người cho là “logic rất phức tạp”, Agent có thể lại biết sẵn cách giải chuẩn, chỉ vài ba động tác là xong.
Điều này dẫn đến một thực tế khó xử: các nhà phát triển gần như không thể ước lượng chi phí vận hành Agent một cách trực quan.
Phát hiện thứ năm: Ngay cả mô hình cũng không thể tính chính xác mình sẽ tốn bao nhiêu tiền
Nếu con người không thể dự đoán chính xác, vậy hãy để AI tự dự đoán?
Các nhà nghiên cứu đã thiết kế một thí nghiệm tinh vi: để Agent “kiểm tra” kho mã nguồn trước khi bắt đầu sửa lỗi, sau đó ước lượng số Token mà nó sẽ tiêu tốn—nhưng không thực hiện việc sửa chữa.
Kết quả thế nào?
Tất cả các mô hình đều thất bại hoàn toàn.
Thành tích tốt nhất là độ tương quan dự đoán của Claude Sonnet-4.5 đối với token đầu ra — 0,39 (thang điểm tối đa là 1,0). Hầu hết các mô hình có độ tương quan dự đoán chỉ trong khoảng 0,05 đến 0,34, trong đó Gemini-3-Pro thấp nhất, chỉ đạt 0,04 — gần như đoán bừa.
Điều còn đáng ngạc nhiên hơn: tất cả các mô hình đều đánh giá thấp một cách có hệ thống lượng token mà chúng tiêu thụ. Trong biểu đồ phân tán ở Hình 11, hầu hết các điểm dữ liệu đều nằm dưới “đường dự đoán hoàn hảo” — mô hình cho rằng “không tiêu tốn nhiều như vậy”, nhưng thực tế lại tiêu tốn nhiều hơn. Hơn nữa, sự thiên lệch đánh giá thấp này trở nên nghiêm trọng hơn khi không cung cấp ví dụ.
Điều đáng讽刺 hơn là—việc dự đoán bản thân cũng tốn tiền.
Chi phí dự đoán của Claude Sonnet-3.7 và Sonnet-4 thậm chí còn cao hơn gấp hơn 2 lần so với chi phí của chính nhiệm vụ. Nói cách khác, để chúng “định giá” trước còn tốn hơn là làm trực tiếp.
Kết luận của bài luận rất trực tiếp:
Hiện tại, các mô hình tiên tiến không thể dự đoán chính xác lượng Token mà chúng sử dụng. Nhấn “Chạy Agent” giống như mở hộp bí ẩn—phải đợi hóa đơn xuất hiện mới biết đã chi bao nhiêu.
Đằng sau “bản ghi chép mơ hồ” này là một vấn đề lớn hơn trong ngành
Đến đây, bạn có thể tự hỏi: Những phát hiện này có ý nghĩa gì đối với doanh nghiệp?
Mô hình định giá “đăng ký hàng tháng” đang bị Agent làm nứt vỡ
Bài báo chỉ ra rằng mô hình đăng ký như ChatGPT Plus là khả thi vì mức tiêu thụ Token cho các cuộc hội thoại thông thường tương đối kiểm soát được và có thể dự đoán được. Tuy nhiên, các nhiệm vụ Agent hoàn toàn phá vỡ giả định này – một nhiệm vụ có thể tiêu tốn lượng Token khổng lồ do Agent bị kẹt trong vòng lặp.
Điều này có nghĩa là mô hình định giá đăng ký thuần túy có thể không bền vững cho các kịch bản Agent, và mô hình trả theo mức sử dụng (Pay-as-you-go) sẽ vẫn là lựa chọn thực tế nhất trong một thời gian dài. Tuy nhiên, vấn đề với mô hình trả theo mức sử dụng là – chính mức sử dụng không thể dự đoán được.
2. Hiệu quả của token nên trở thành "chỉ số thứ ba" khi chọn mô hình
Truyền thống, doanh nghiệp đánh giá mô hình dựa trên hai chiều: năng lực (có thể làm được không) và tốc độ (làm nhanh hay không). Bài báo này đưa ra chiều thứ ba quan trọng ngang nhau: hiệu quả năng lượng (mất bao nhiêu chi phí để hoàn thành).
Một mô hình có năng lực kém hơn một chút nhưng hiệu quả cao gấp 3 lần có thể mang lại giá trị kinh tế lớn hơn so với mô hình “mạnh nhất nhưng tốn kém nhất” trong các tình huống quy mô lớn.
3. Agent cần “đồng hồ xăng” và “phanh”
Bài viết đề cập đến một hướng phát triển tương lai đáng chú ý—chính sách sử dụng công cụ có nhận thức về ngân sách. Nói một cách đơn giản, đó là trang bị cho Agent một “đồng hồ xăng”: khi lượng Token tiêu thụ gần đến ngưỡng ngân sách, buộc nó dừng lại các cuộc khám phá vô ích, thay vì tiếp tục tiêu tốn đến hết.
Hiện tại, hầu hết các khung Agent chính đều thiếu cơ chế này.
Vấn đề “cháy tiền” của Agent không phải là lỗi, mà là nỗi đau tất yếu mà ngành phải trải qua
Bài luận này không tiết lộ điểm yếu của một mô hình cụ thể, mà là thách thức cấu trúc của toàn bộ mô hình Agent—khi AI tiến hóa từ “hỏi-đáp đơn lẻ” sang “lập kế hoạch tự chủ, thực hiện đa bước, điều chỉnh lặp lại”, sự không thể dự đoán được trong việc tiêu tốn Token gần như là điều tất yếu.
Điều tốt lành là đây là lần đầu tiên có người hệ thống hóa và tính toán rõ ràng khoản chi tiêu hỗn loạn này. Với dữ liệu này, các nhà phát triển có thể lựa chọn mô hình, thiết lập ngân sách và thiết kế cơ chế dừng lỗ một cách thông minh hơn; các nhà cung cấp mô hình cũng có một hướng tối ưu hóa mới — không chỉ mạnh hơn mà còn tiết kiệm hơn.
Sau tất cả, trước khi AI Agent thực sự thâm nhập vào môi trường sản xuất của hàng ngàn ngành nghề, việc chi từng đồng tiền một cách minh bạch còn quan trọng hơn việc viết từng dòng mã thật đẹp. (Bài viết này ban đầu đăng trên ứng dụng Titanium Media, tác giả | Silicon Valley Tech news, biên tập | Triêu Hồng Vũ)
Lưu ý: Bài viết này dựa trên bản preprint được công bố trên arXiv vào ngày 24 tháng 4 năm 2026 có tựa đề *How Do AI Agents Spend Your Money? Analyzing and Predicting Token Consumption in Agentic Coding Tasks* (Bai, Huang, Wang, Sun, Mihalcea, Brynjolfsson, Pentland, Pei). Các tác giả đến từ các tổ chức như Đại học Virginia, Stanford, MIT, Đại học Michigan. Nghiên cứu này chưa được đánh giá ngang hàng.