
Bạn muốn biết mô hình nào mạnh nhất trong các nhiệm vụ đại lý thực tế của OpenClaw?
MyToken đã tổng hợp một bộ tiêu chuẩn minh bạch tập trung vào đánh giá năng lực thực tế của các đại lý mã hóa AI, chỉ xem xét một chiều cạnh cốt lõi là tỷ lệ thành công (tốc độ và chi phí thuộc về các chiều cạnh độc lập khác, sẽ được phân tích riêng sau này). Hoàn toàn công khai, có thể tái tạo, chỉ trình bày tiêu chuẩn đánh giá nghiêm ngặt + bảng xếp hạng Top 10 tỷ lệ thành công mới nhất.
I. Tiêu chí đánh giá: Tỷ lệ thành công
Tiêu chuẩn cụ thể: Tỷ lệ số lượng nhiệm vụ được đại lý AI hoàn thành đầy đủ và chính xác. Mỗi nhiệm vụ đều sử dụng quy trình chuẩn hóa cao:
Chỉ dẫn người dùng chính xác
Gửi đầy đủ cho tác nhân để mô phỏng cảnh yêu cầu thực tế của người dùng
Hành vi mong đợi
Đều nêu rõ các cách tiếp cận được chấp nhận và các điểm quyết định then chốt
Tiêu chí đánh giá (danh sách kiểm tra)
Liệt kê danh sách các tiêu chí xác định thành công dưới dạng các yếu tố nguyên tử có thể kiểm tra từng mục một
Hai, ba phương pháp đánh giá
Lần đánh giá này chủ yếu sử dụng 3 phương pháp xếp hạng
Kiểm tra tự động: Script Python xác minh trực tiếp các kết quả khách quan như nội dung tệp, bản ghi thực thi, gọi công cụ, v.v.
Đánh giá mô hình LLM lớn: Claude Opus chấm điểm theo thang điểm chi tiết (chất lượng nội dung, mức độ phù hợp, tính toàn vẹn, v.v.)
Chế độ hỗn hợp: Kết hợp kiểm tra khách quan tự động với đánh giá định tính của LLM
Tất cả các định nghĩa nhiệm vụ, Prompt và logic đánh giá đều được công khai để có thể kiểm tra lại và xác minh.
Ba, nhiệm vụ dùng để đánh giá
Bài kiểm tra hiệu năng này bao gồm 23 nhiệm vụ thuộc các danh mục khác nhau, bao quát nhiều khía cạnh như tương tác cơ bản, thao tác tệp/mã, sáng tạo nội dung, nghiên cứu và phân tích, gọi công cụ hệ thống, lưu trữ bộ nhớ lâu dài, v.v., phản ánh sát thực các tình huống mà nhà phát triển thường xuyên sử dụng OpenClaw:
Kiểm tra tính hợp lý (tự động) — Xử lý các lệnh đơn giản và trả lời lời chào đúng cách
Tạo sự kiện lịch (tự động hóa) — Tạo tệp lịch ICS chuẩn từ ngôn ngữ tự nhiên
Nghiên cứu giá cổ phiếu (tự động hóa) — Tra cứu giá cổ phiếu theo thời gian thực và xuất báo cáo định dạng
Blog Post Writing (LLM Judge) — Viết một bài blog Markdown có cấu trúc khoảng 500 từ
Tạo kịch bản thời tiết (tự động hóa) — Viết kịch bản Python API thời tiết có xử lý lỗi
Tóm tắt tài liệu (Đánh giá bởi LLM) — Tóm tắt cô đọng 3 đoạn về chủ đề cốt lõi
Nghiên cứu Hội nghị Công nghệ (Ban giám khảo LLM) — Tổng hợp thông tin từ 5 hội nghị công nghệ thực tế (tên, ngày tháng, địa điểm, liên kết)
Soạn email chuyên nghiệp (LLM trọng tài) — Từ chối lịch họp một cách lịch sự và đề xuất giải pháp thay thế
Truy xuất bộ nhớ từ ngữ cảnh (tự động hóa) — Trích xuất chính xác ngày tháng, thành viên, công nghệ, v.v. từ ghi chú dự án
Tạo cấu trúc tệp (tự động hóa) — Tự động tạo thư mục dự án chuẩn, README, .gitignore
Quy trình API nhiều bước (hỗn hợp) — Đọc cấu hình → Viết script gọi → Tài liệu hóa đầy đủ
Cài đặt kỹ năng ClawdHub (tự động hóa) — cài đặt từ kho kỹ năng và xác minh tính khả dụng
Tìm và cài đặt Kỹ năng (tự động hóa) — tìm kiếm và cài đặt đúng kỹ năng về thời tiết
Tạo hình ảnh AI (hỗn hợp) — Tạo và lưu hình ảnh theo mô tả
Làm cho bài viết do AI tạo trở nên tự nhiên hơn (bộ xét duyệt LLM) — biến nội dung mang tính máy móc thành ngôn ngữ nói tự nhiên
Tóm tắt nghiên cứu hàng ngày (LLM arbiter) – Tổng hợp nhiều tài liệu thành bản tóm tắt hàng ngày mạch lạc
Phân loại Hộp thư đến (hỗn hợp) — Phân tích nhiều email và sắp xếp báo cáo theo mức độ khẩn cấp
Tìm kiếm và tóm tắt email (hỗn hợp) — Tìm kiếm email trong lưu trữ và rút ra thông tin quan trọng
Nghiên cứu thị trường cạnh tranh (hỗn hợp) — Phân tích đối thủ trong lĩnh vực APM doanh nghiệp
Tổng hợp CSV và Excel (hỗn hợp) — Phân tích tệp bảng và đưa ra nhận xét
Tóm tắt PDF bằng ngôn ngữ dễ hiểu như giải thích cho trẻ 5 tuổi (Ban giám khảo LLM)
Hiểu báo cáo OpenClaw (tự động hóa) — Trả lời chính xác các câu hỏi cụ thể từ PDF báo cáo nghiên cứu
Bền vững hóa tri thức Second Brain (hỗn hợp) — Lưu trữ và nhớ chính xác thông tin giữa các phiên
Bốn: Kết luận cốt lõi: Bảng xếp hạng 10 mô hình có tỷ lệ thành công cao nhất (Tỷ lệ % Tốt nhất / Tỷ lệ % Trung bình)
Dữ liệu được cập nhật đến ngày 7 tháng 4 năm 2026
Best % là tỷ lệ thành công cao nhất trong một lần, Avg % là tỷ lệ thành công trung bình nhiều lần, phản ánh tốt hơn độ ổn định
Dưới đây là mười mô hình có tỷ lệ thành công cao nhất
anthropic/claude-opus-4.6 (Anthropic) —— 93,3% / 82,0%
arcee-ai/trinity-large-thinking (Arcee AI) —— 91,9% / 91,9%
openai/gpt-5.4 (OpenAI) —— 90,5% / 81,7%
qwen/qwen3.5-27b (Qwen) —— 90,0% / 78,5%
minimax/minimax-m2.7 (MiniMax) — 89,8% / 83,2%
anthropic/claude-haiku-4.5 (Anthropic) —— 89,5% / 78,1%
qwen/qwen3.5-397b-a17b (Qwen) —— 89,1% / 80,4%
xiaomi/mimo-v2-flash (Xiaomi) —— 88,8% / 70,2%
qwen/qwen3.6-plus-preview (Qwen) —— 88,6% / 84,0%
nvidia/nemotron-3-super-120b-a12b (NVIDIA) —— 88,6% / 75,5%
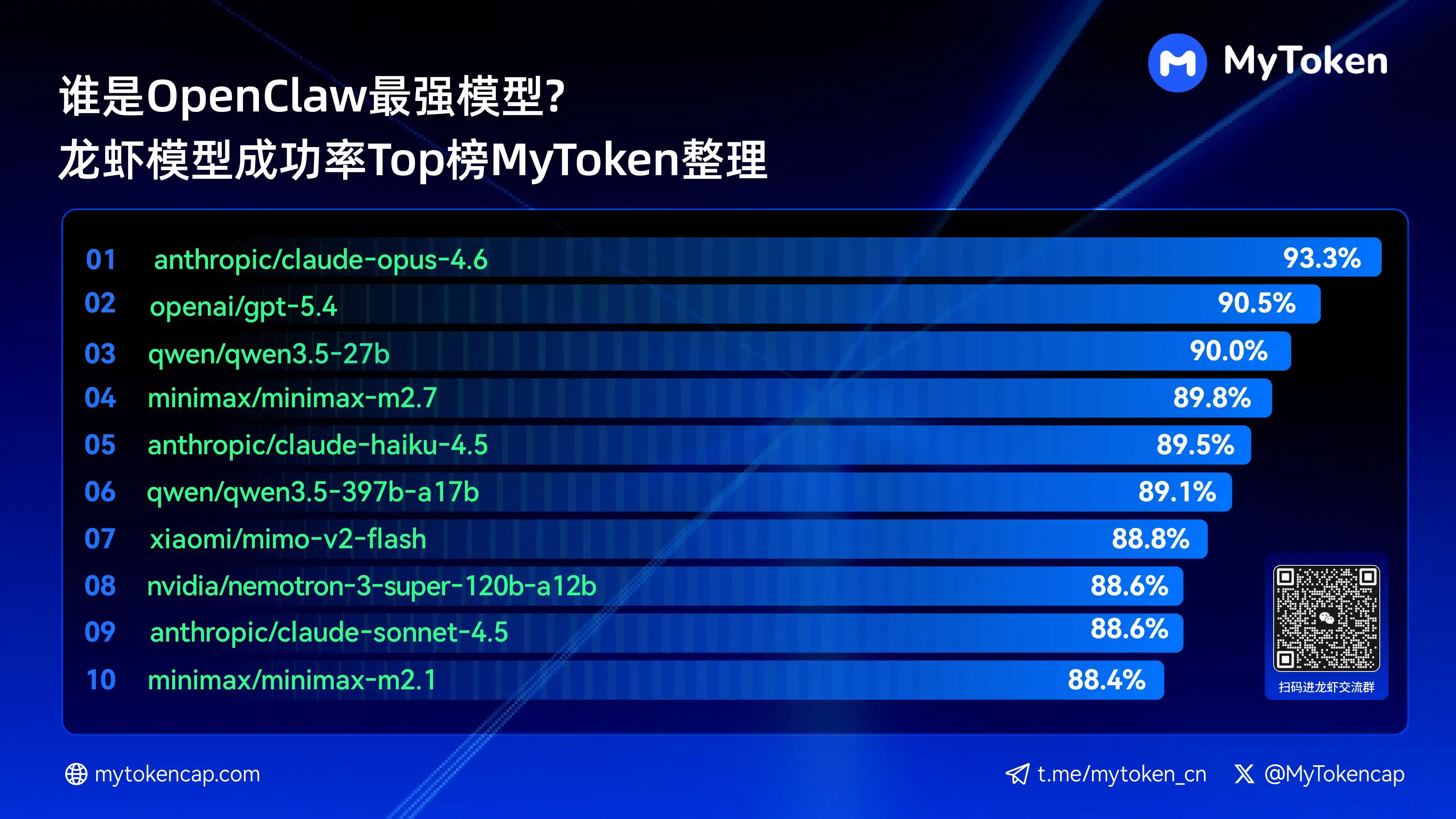
Claude Opus 4.6 hiện dẫn đầu với tỷ lệ thành công cao nhất là 93,3%, nhưng Trinity của Arcee nổi bật về độ ổn định trung bình, trong khi nhiều mô hình trong chuỗi Qwen cũng lọt vào top 10, thể hiện tiềm năng chi phí - hiệu quả mạnh mẽ. Tỷ lệ thành công là ngưỡng cơ bản, các yếu tố về tốc độ và chi phí trong tương lai sẽ tiếp tục ảnh hưởng đến trải nghiệm thực tế.
Bộ tiêu chuẩn 23 nhiệm vụ này hoàn toàn minh bạch, chúng tôi khuyến nghị mạnh mẽ mọi người thực hiện kiểm tra thực tế dựa trên ngữ cảnh của riêng mình. Hãy chờ đón tính năng Bảng xếp hạng Agent sắp ra mắt của MyToken để xem thêm các bảng xếp hạng mô hình khác.
(Dữ liệu được lấy từ bài kiểm tra đại diện OpenClaw do PinchBench công khai, đang được cập nhật liên tục.)