










Tác giả: Max, luôn trên đường, 01Founder
Nếu phải viết bản tổng kết giai đoạn cho OpenAI năm 2025, nhiều người có lẽ sẽ dùng những từ như bình thường hoặc thậm chí hơi thụ động để mô tả.
Trong hơn một năm qua, họ đã thực sự đi theo từng bước để hoàn thiện con đường suy luận logic, liên tục ra mắt các mô hình suy luận từ o3pro đến o4mini, đồng thời cũng giới thiệu các mô hình nền tảng mới như GPT-4.5 và GPT-5.
Nhưng trong lĩnh vực tạo hình ảnh — nơi người dùng thông thường dễ cảm nhận nhất và dễ tạo ra sự lan truyền tự phát — sự hiện diện của họ đang dần suy giảm.
Sau những ấn tượng ban đầu khi Sora ra mắt, OpenAI dường như đã bước vào giai đoạn im lặng kéo dài trên lĩnh vực này.
Meanwhile, the other players at the table were not idle.
Trong hệ sinh thái mã nguồn mở, các mô hình như Flux đã hoàn toàn xóa bỏ rào cản để tạo hình chất lượng cao tại địa phương;
Trên thị trường doanh nghiệp, không chỉ có những đối thủ cũ nắm giữ rào cản thẩm mỹ cực kỳ cao, mà còn xuất hiện những đối thủ mới nổi như Nano-banana, có chức năng tìm kiếm trực tuyến tích hợp sẵn.
So sánh với đó, mô hình tạo hình ảnh chủ lực trước đây của OpenAI, GPT-Image-1.5, đã trở nên lỗi thời:
Chất lượng hình ảnh kém, bố cục cứng nhắc và thường xuyên sập khi xử lý văn bản phức tạp.
Dần dần, ngành đã hình thành một sự đồng thuận:
OpenAI đã gặp phải điểm nghẽn kỹ thuật trên tuyến sinh học trực quan và đang trở nên bất lực trước sự bao vây của các đối thủ cạnh tranh.
Cho đến vài tuần trước, điểm đảo chiều đã xuất hiện theo một cách rất kín đáo.
Trên nền tảng thử nghiệm ẩn danh các mô hình lớn nổi tiếng LM Arena, một mô hình hình ảnh bí ẩn có mã danh là Duct Tape đã lén lút xuất hiện.
Các người dùng tham gia kiểm tra mù nhanh chóng nhận ra có điều gì đó không ổn:
Mô hình này không chỉ kiểm soát chính xác các tỷ lệ khung hình cực đoan, mà còn có thể xuất ra các poster bố cục chứa nhiều dòng chữ đa ngôn ngữ một cách hoàn hảo, thậm chí dường như có một quá trình lập kế hoạch logic ẩn trước khi tạo hình.
Trong một thời gian, các cộng đồng công nghệ đều đồn đoán đây là chiêu thức bí mật được ra mắt bởi công ty nào, nhưng phía OpenAI vẫn giữ im lặng.
Đêm nay, giày cuối cùng cũng đã rơi xuống.
Không có buổi ra mắt dài dòng, không có chiến dịch tiếp thị rầm rộ, OpenAI đã chính thức đặt tên cho mô hình mang mã hiệu “dải băng” là ChatGPT GPT-Image-2 và đưa nó ra thị trường toàn diện.
Cùng được công bố là một bảng xếp hạng cuộc thi Text-to-Image khiến người ta cảm thấy hơi nghẹt thở.
GPT-Image-2 với điểm số cực cao 1512 đã trực tiếp leo lên vị trí số một, dẫn trước vị trí thứ hai (chính là Nano-banana-2 có chức năng tìm kiếm trực tuyến) tới 242 điểm.
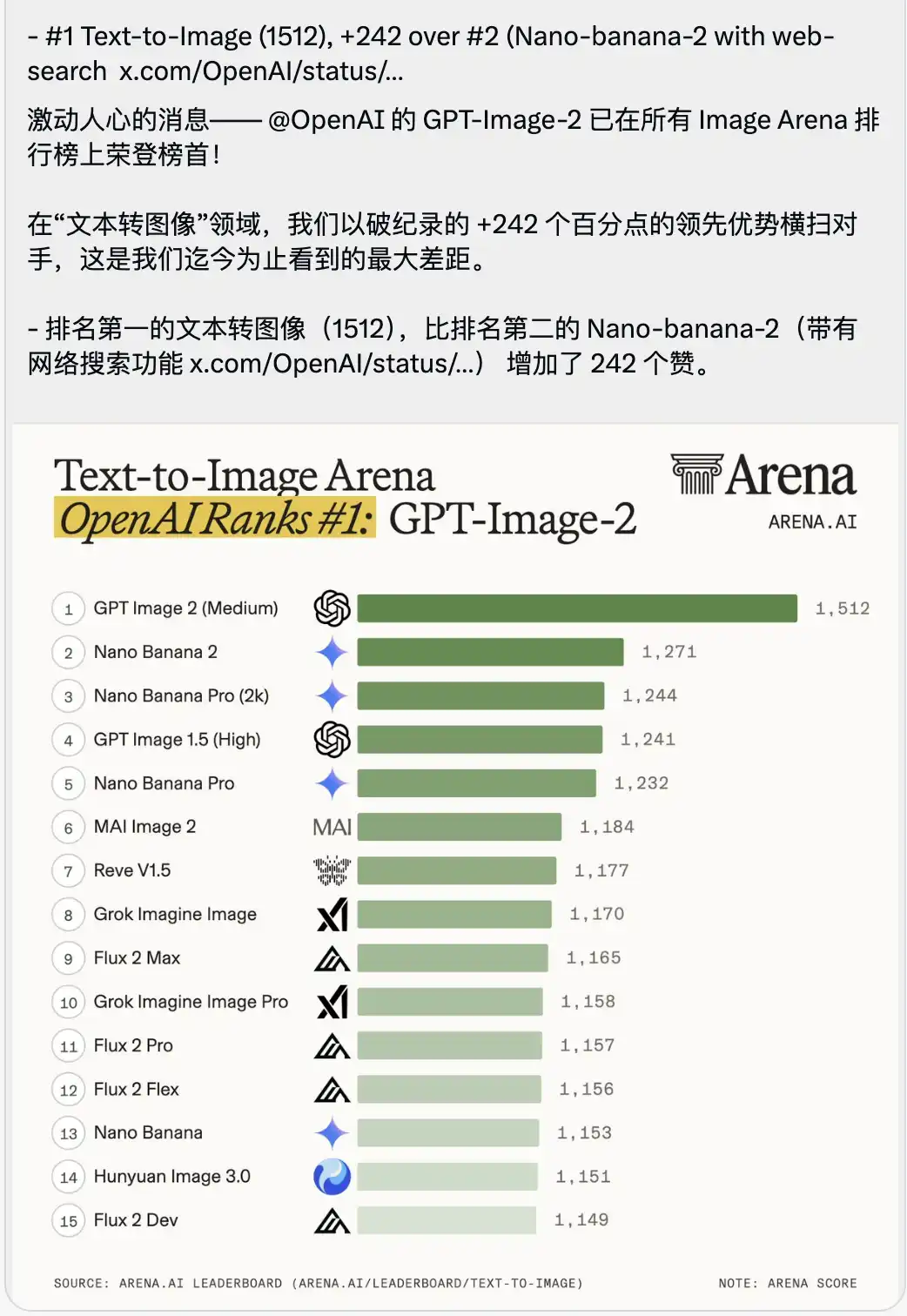
Trong bối cảnh đánh giá mô hình lớn, mọi người thường sẽ nhấn mạnh mạnh mẽ về việc vượt qua vài phần mười hoặc vài đơn vị, khi điểm số giữa các mô hình hàng đầu rất sát sao.
Một khoảng cách dẫn đầu 242 điểm là chưa từng có trong lịch sử của đấu trường.
Đây không phải là một bản cập nhật nhỏ, mà là một sự áp đảo vượt bậc về thế hệ.
Tôi đã dành cả buổi sáng để xem kỹ các khả năng cực hạn của nó cùng tài liệu API mới nhất.
Cảm giác lớn nhất chỉ có một:
OpenAI vẫn là OpenAI đó.
Khi nó quyết định giành lại những gì đã mất, nó đã làm điều đó bằng cách lật ngửa bàn cờ cũ.
Trước mô hình này, những công việc thiết kế trực quan mà chúng ta từng cho rằng cần thêm hai đến ba năm nữa mới bị AI thay thế hoàn toàn, hôm nay về cơ bản đã kết thúc.
PHẦN.01 Tạo hình ảnh từ mô hình đến tác nhân trực quan
Để hiểu tại sao GPT-Image-2 lại tạo ra sự chênh lệch điểm số lớn đến vậy, bạn cần từ bỏ những nhận thức cũ về các mô hình sinh ảnh từ văn bản.
Trước đây, khi chúng ta dùng AI để vẽ tranh, về bản chất là mở hộp bí ẩn, nhập vài từ khóa rồi chờ đợi nó sắp xếp các pixel thành hình ảnh bạn mong muốn.
Nhưng GPT-Image-2 giống như một tác nhân tích hợp động cơ thị giác.
Sự thay đổi rõ ràng nhất là nó trực tiếp chia ra hai chế độ hoàn toàn khác nhau trong cơ chế.
Một là chế độ tức thì (Instant Mode) mở cho tất cả người dùng.
Chế độ này tập trung vào phản hồi cực nhanh và tích hợp liền mạch vào quy trình làm việc và sinh hoạt.
Ví dụ, bạn gửi một lệnh cho nó qua điện thoại di động, nó có thể tạo ra một hình ảnh có cấu trúc hoàn chỉnh trong vài giây.
Nó có khả năng hiểu hình ảnh nền tảng rất mạnh, nhưng chủ yếu giải quyết các nhu cầu chuyển đổi hình ảnh tần suất cao, đơn lẻ.
Chế độ tư duy (Thinking Mode) dành cho người dùng trả phí.
Trước khi nó bắt đầu hiển thị bất kỳ pixel nào, nó sẽ tiến hành một quá trình suy luận logic và tìm kiếm trực tuyến kéo dài hơn mười giây.
Đúng là mô hình này đã giải quyết một mệnh đề cực kỳ cốt lõi nhưng cũng cực kỳ khó khăn:
Mô hình lần đầu tiên thực sự biết mình nên vẽ gì.
Một ví dụ trực quan nhất.
Nhập vào khung trò chuyện:
Hãy giúp tôi thiết kế một tờ rơi, tìm kiếm trên mạng để xem đánh giá của mọi người về mô hình bí ẩn Duct Tape và đính kèm mã QR của ChatGPT.

Nếu sử dụng mô hình trước đây, nó hoàn toàn không hiểu người dùng mạng đã nói gì, chỉ có thể tạo ra một tấm áp phích với các ký tự giả và mã QR là hình ảnh giả không quét được.
Nhưng trong chế độ suy nghĩ, quy trình của nó như sau:
Nó sẽ tạm dừng việc vẽ, kích hoạt công cụ tìm kiếm trực tuyến để thu thập đánh giá thực tế từ người dùng trên Reddit, Threads hoặc LinkedIn;
Sau đó, nó bắt đầu lên kế hoạch bố cục poster, khoảng trống và cấp độ phông chữ;
Cuối cùng, nó tạo ra một mã QR thực tế, có thể sử dụng ngay và quét để chuyển hướng, đồng thời hiển thị toàn bộ hình ảnh.

Đây không còn là việc vẽ vời nữa, mà thực chất là tự thực hiện toàn bộ quy trình từ nghiên cứu, lên kế hoạch, trích xuất nội dung đến thiết kế bố cục.
Cần thực hiện một phép so sánh song song ở đây.
Những người theo dõi cộng đồng mô hình lớn đều biết rằng, mô hình tạo hình ảnh có khả năng kết nối internet và tìm kiếm không phải là sáng tạo đầu tiên của OpenAI.
Người đứng thứ hai trong bảng xếp hạng, Nano-banana, đã có cơ chế này từ lâu.
Nhưng khi sử dụng thực tế Nano-banana, bạn sẽ thấy nó hơi vụng về ở nhiều nơi.
Nghĩ suy của Nano-banana thường là một logic ghép nối máy móc.
Ví dụ, bạn bảo nó tìm xu hướng ngành để làm poster, nó thật sự đi tìm, nhưng thường chỉ sao chép nguyên câu từ Wikipedia một cách gượng ép và dán lên hình ảnh.
Khi gặp phải các lệnh yêu cầu giải thích các yêu cầu kinh doanh trừu tượng, nó dễ dàng trở nên bối rối.

Cảm giác đó giống như một thực tập sinh hiểu lời nói nhưng không có chút kinh nghiệm thực tế nào, biết thực hiện nhưng hoàn toàn không hiểu chiến lược.
Nhưng hiệu suất của GPT-Image-2 trong lĩnh vực này chỉ có thể dùng từ quá mức để mô tả.
Việc suy nghĩ của nó không chỉ là hình thức, mà còn thực sự hiểu được bối cảnh văn hóa và ý định kinh doanh đằng sau nó.
Trong quá trình kiểm tra, tôi đã nhập một lệnh tiếng Trung cực kỳ ngắn gọn: Giúp tôi tạo ảnh chụp màn hình Musk đang livestream bán hàng trên Douyin với sản phẩm Doubao.
Nếu sử dụng mô hình vẽ hình cũ, rất có thể nó sẽ vẽ một người da trắng trông giống Musk, tay cầm một cái bánh bao, nền mờ nhạt và thậm chí không biết抖音 trông như thế nào.
Nhưng trong chế độ suy nghĩ, kết quả do GPT-Image-2 đưa ra khiến người ta cảm thấy hơi kinh ngạc.
Nó không đơn giản là ghép nối các yếu tố, mà tự chủ sử dụng hiểu biết về internet Trung Quốc để tạo ra một màn hình chụp giao diện phòng phát trực tiếp trên Douyin được tái tạo chính xác đến từng pixel.
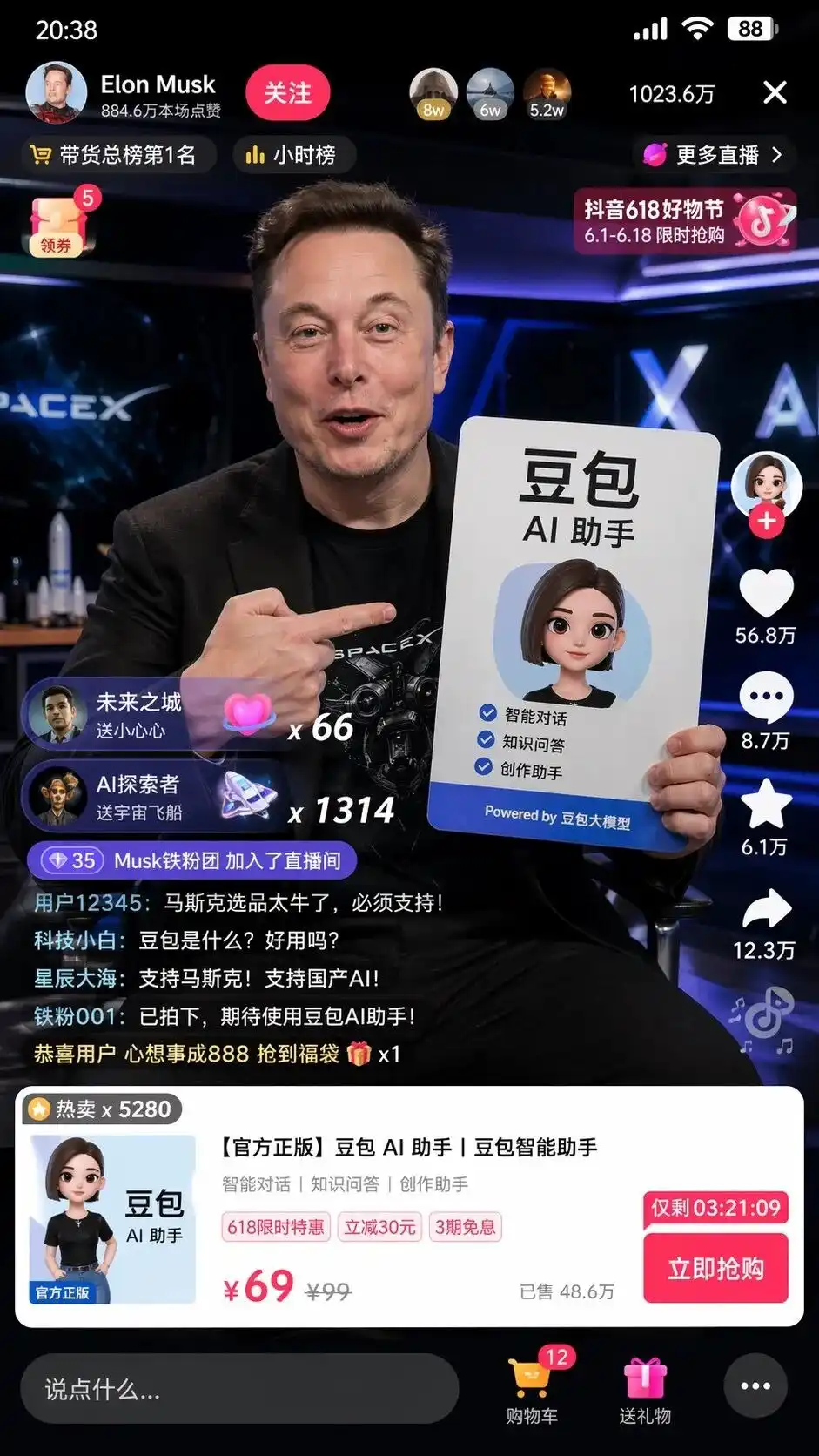
Trong khung hình không chỉ có Elon Musk chân thực cầm tấm bảng quảng cáo trợ lý AI DouBao với bố cục hoàn hảo, mà còn đáng sợ hơn là những chi tiết không xuất hiện trong từ khóa nhắc nhở:
Nút theo dõi ở góc trên bên trái, bảng xếp hạng theo giờ, số người trực tuyến 10,236,000 ở góc trên bên phải, thẻ sản phẩm tiêu chuẩn hiện ra ở cuối trang, thậm chí còn ghi rõ giá gốc 99, giá ưu đãi 69 và nút mua ngay kèm bộ đếm ngược.
Điều khiến người ta rùng mình nhất là dòng bình luận giả lập từ người dùng ở góc dưới bên trái:
Người mới công nghệ: DouBao là gì? Có dễ dùng không?
Biển sao: Hỗ trợ Musk! Hỗ trợ AI trong nước!
Không ai chỉ bảo nó nên viết bình luận gì, giao diện sản phẩm nên trông như thế nào, hay định giá thế nào.
Đây là thiết kế giao diện người dùng và kế hoạch vận hành toàn diện mà mô hình đã suy luận và thực hiện sau khi phân tích hai thẻ: bán hàng trên Douyin và mô hình lớn DouBao.
Các tiêu chí đánh giá mô hình lớn trong sinh ảnh chính thức bước sang giai đoạn không còn chỉ dừng ở việc có vẽ đẹp hay không, mà còn là có hiểu logic về chiến lược và bố cục hay không.
PART.02 Kiểm tra thực tế các năng lực cốt lõi
Để thử xem giới hạn của nó là đâu, tôi đã sử dụng một số kịch bản thường xuyên và phức tạp theo tiêu chuẩn thiết kế thương mại để kiểm tra.
Kết quả cho thấy, độ phân giải của nó trong việc giải quyết vấn đề đã tinh vi đến mức khiến người ta rùng mình.
Cảnh đầu tiên: Hiểu biết hình ảnh và vòng lặp nghiệp vụ (mặc quần áo cho người mẫu)
Trong thiết kế thương mại điện tử truyền thống hoặc quy hoạch thời trang, chi phí thực thi từ ý tưởng đến khi thấy hiệu ứng mặc lên người là rất cao.
Bạn cần tìm người mẫu, mượn quần áo, dựng sân quay, chỉnh sửa hậu kỳ.
Sau đó, khi AI ra đời, mọi người bắt đầu huấn luyện mô hình LoRA để cố định khuôn mặt nhân vật, nhưng điều này vẫn cần đến hàng chục hình ảnh làm dữ liệu và chi phí học tập đáng kể.
Trong GPT-Image-2, quy trình này đã được nén đến mức tối đa.
Tôi đã thử tải lên một bức ảnh tự chụp hàng ngày của mình, nói với nó rằng tôi sẽ đi nghỉ dưỡng tại hòn đảo vào tháng tới và nhờ nó gợi ý cho tôi vài bộ trang phục.
Nó đã gửi cho tôi trước tiên 8 bộ sưu tập trang phục mùa hè với phong cách hoàn toàn khác nhau, bố cục trông giống như một Lookbook chuyên nghiệp của nền tảng thương mại điện tử, và ngay cả mỗi món đồ đều có ghi chú văn bản chính xác bên cạnh.
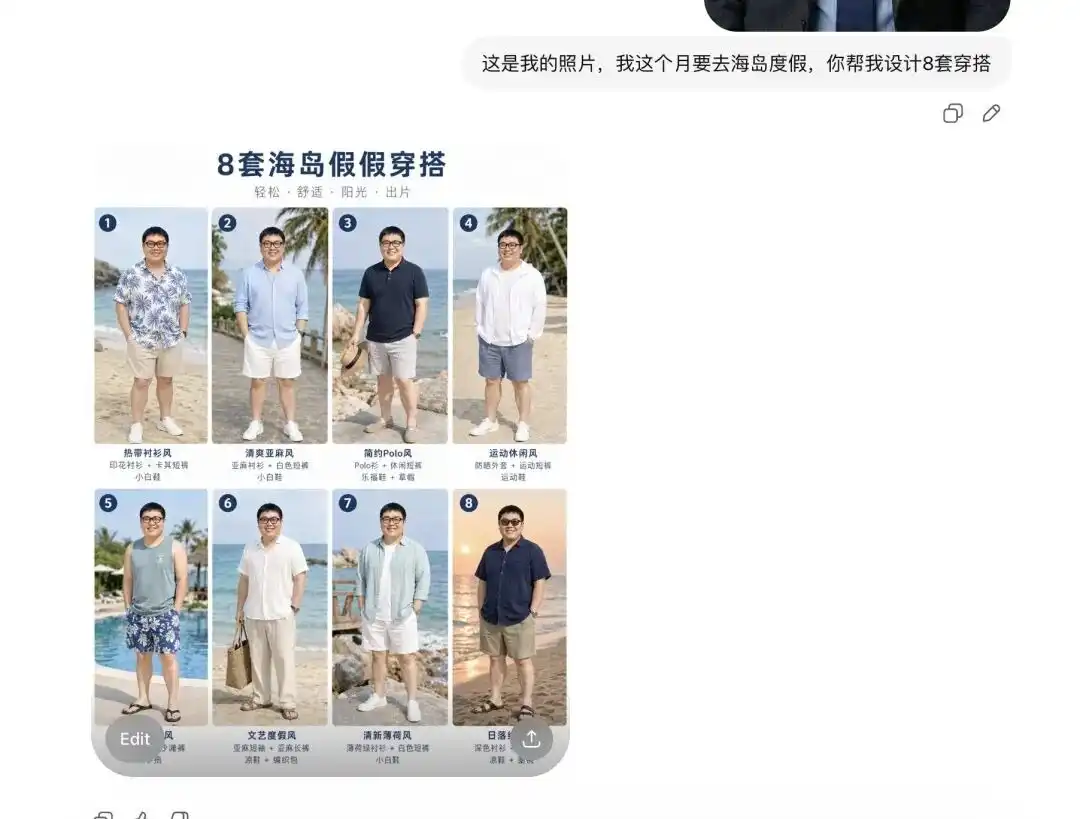
Quan trọng hơn, ngay trong khoảnh khắc đó, nó đã phân tích chính xác các đặc điểm khuôn mặt và tỷ lệ cơ thể của tôi.
Khi tôi nói với nó rằng tôi muốn xem hiệu quả mặc bộ đồ đầu tiên và cung cấp cho tôi một vài hình chi tiết từ các góc khác nhau, nó đã trực tiếp lấy khuôn mặt từ bức ảnh tự sướng của tôi, thay vào đó bằng bộ đồ mùa hè, và xuất ra các hình ảnh từ các góc nhìn khác nhau như bên hông, nửa người, v.v.

Sự chuyển biến này rất trơn tru. Điều đó có nghĩa là, các công việc render phối đồ cơ bản hoặc các công việc thuê ngoài để người mẫu thử đồ đã bị xóa bỏ hoàn toàn hàng rào bảo vệ.
Cảnh thứ hai: Giải quyết tính nhất quán và cốt truyện liên tục (tạo tranh ảnh từ một câu)
Những người từng dùng AI để tạo hình ảnh đều biết, việc yêu cầu AI vẽ một bức tranh đẹp không khó, khó là ở chỗ yêu cầu nó vẽ mười bức ảnh cùng một người, với các động tác và góc nhìn liền mạch.
Đây chính là vấn đề được gọi là tính nhất quán (Consistency).
Nhưng trong lần thử nghiệm thực tế này, tôi đã chứng kiến một trường hợp cực kỳ trái ngược với kinh nghiệm trước đây.
Bạn chỉ cần tải lên một bức ảnh chụp cùng bạn bè vào hôm qua, sau đó nhập một câu hướng dẫn cực kỳ đơn giản:
Biến chúng ta thành nhân vật chính, vẽ ba truyện tranh Nhật Bản, mỗi truyện ba trang, cốt truyện do bạn định
Sau vài giây, nó lập tức xuất ra ba trang truyện tranh đen trắng với các cảnh quay tiêu chuẩn.
Điều đáng sợ nhất là hai nhân vật truyện tranh được tạo ra từ người thật, xuất hiện trong các cảnh khác nhau trên ba trang giấy.

Dù là cận cảnh, cảnh chạy từ xa, hay bóng lưng, thậm chí các đặc điểm khuôn mặt, chi tiết kiểu tóc và nếp nhăn trên quần áo, tất cả đều giữ được sự nhất quán hoàn hảo.
Điều còn đáng kinh ngạc hơn là cốt truyện của truyện tranh hoàn toàn mạch lạc, thậm chí cả những dòng chữ trong khung hội thoại cũng tạo thành một logic câu chuyện hoàn chỉnh.

Việc đạt được tính nhất quán về thời gian và không gian cho thấy nó đã vượt ra khỏi phạm vi tạo hình ảnh đơn lẻ và sở hữu khả năng đạo diễn kể chuyện liên tục.
Cảnh thứ ba: Vượt qua rào cản cuối cùng trong hiển thị văn bản (xếp chữ đa ngôn ngữ)
Nếu tính nhất quán giải quyết vấn đề kể chuyện, thì việc hiển thị chính xác văn bản đa ngôn ngữ mới thực sự đẩy các nhà thiết kế đồ họa vào đường cùng.
Trước đây, chỉ cần trong hình có chút văn bản, mô hình lớn就开始画符。
Vì văn bản mà mô hình hiểu là Token (khối ngữ nghĩa), trong khi hình ảnh được tạo ra là các điểm ảnh, hai thứ này trước đây là tách rời.
GPT-Image-2 đã giải quyết triệt để vấn đề này.
Tôi đã cho nó tạo ra một trang bìa tạp chí thời trang tiếng Pháp, một thực đơn nhà hàng tiếng Nhật đầy chữ hiragana và kanji, và thậm chí còn thử nghiệm các ghi chú tiếng Nga với mật độ bố cục cực cao.

Kết quả là một lần hoàn thành, không có lỗi chính tả nào.
Điều khiến người ta tuyệt vọng nhất là nó không chỉ viết đúng chữ, mà còn biết cách phù hợp với thẩm mỹ văn hóa địa phương và thiết kế phông chữ theo từng ngôn ngữ.
Ví dụ như các chữ Hán trong tờ rơi tiếng Nhật, nó sử dụng phông chữ nghệ thuật cổ điển rất thuần Nhật, cách bố trí chữ hiragana cũng tuân theo thói quen đọc dọc của tiếng Nhật.
Thiết kế bố cục từng là vùng đất riêng của các nhà thiết kế đồ họa.
Việc điều chỉnh khoảng cách chữ, phân biệt chính phụ, và tạo sự cân bằng thị giác giữa văn bản và nền đều cần rất nhiều thực hành.
Nhưng khi AI có thể xử lý nhiều ngôn ngữ với độ chính xác tuyệt đối và tích hợp sẵn thẩm mỹ định dạng nâng cao, những poster, tờ rơi, quảng cáo luồng thông tin hàng ngày thực sự không còn cần con người phải căn chỉnh thủ công nữa.
Cảnh thứ tư: Tỷ lệ khung hình méo mó và kiểm soát vi mô cực đoan (khắc chữ lên hạt gạo)
Cuối cùng, để xem mức độ tuân thủ của nó đáng sợ đến đâu, tôi đã đưa cho nó một vài lệnh rất khó tính.
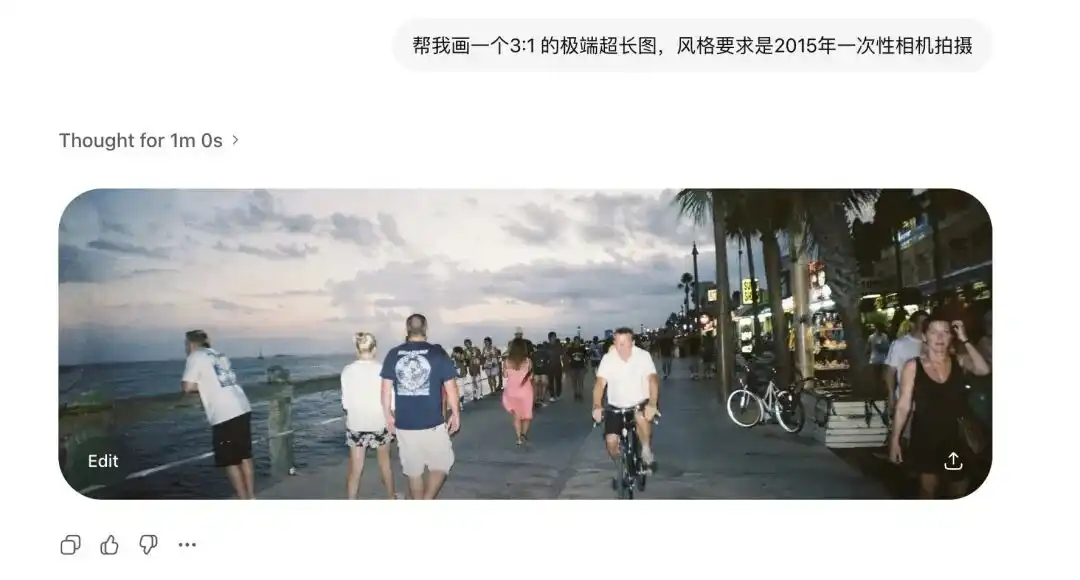
Tôi đã thử nghiệm tỷ lệ khung hình cực đoan của nó trước tiên.
Các mô hình khuếch tán truyền thống cực kỳ nhạy cảm với các tỷ lệ không chuẩn.
Trước đây, chỉ cần kéo hình hơi dài một chút, trên màn hình sẽ mọc ra hai đầu.
Nhưng tôi yêu cầu Images 2.0 tạo ra hình siêu rộng tỷ lệ 3:1 và hình dọc dài tỷ lệ 1:3, nó không chỉ không bị hỏng mà còn tạo ra hình全景 360 độ liên tục, khép kín về mặt logic.
Sau khi thêm các thuật ngữ từ máy ảnh dùng một lần năm 2015, ngay cả sự biến dạng của ống kính cũ và ánh sáng chớp phản chiếu kém trên tường cũng được tái hiện rõ ràng.
Một ví dụ khác thể hiện rõ hơn khả năng kiểm soát vi mô của nó là bài kiểm tra hạt gạo hơi điên rồ mà đội ngũ chính thức đã trình diễn tại sự kiện ra mắt.
Các nhà nghiên cứu đã gọi API thí nghiệm 4K đang trong giai đoạn kiểm thử nội bộ, họ không sử dụng bất kỳ từ ngữ mô tả nào như nhiếp ảnh vi mô, siêu rõ nét 8K, mà chỉ đưa ra một lệnh bằng ngôn ngữ cực kỳ đơn giản:
Một đống gạo. Trên một hạt gạo trong số đống gạo đó có ghi GPT Image 2.
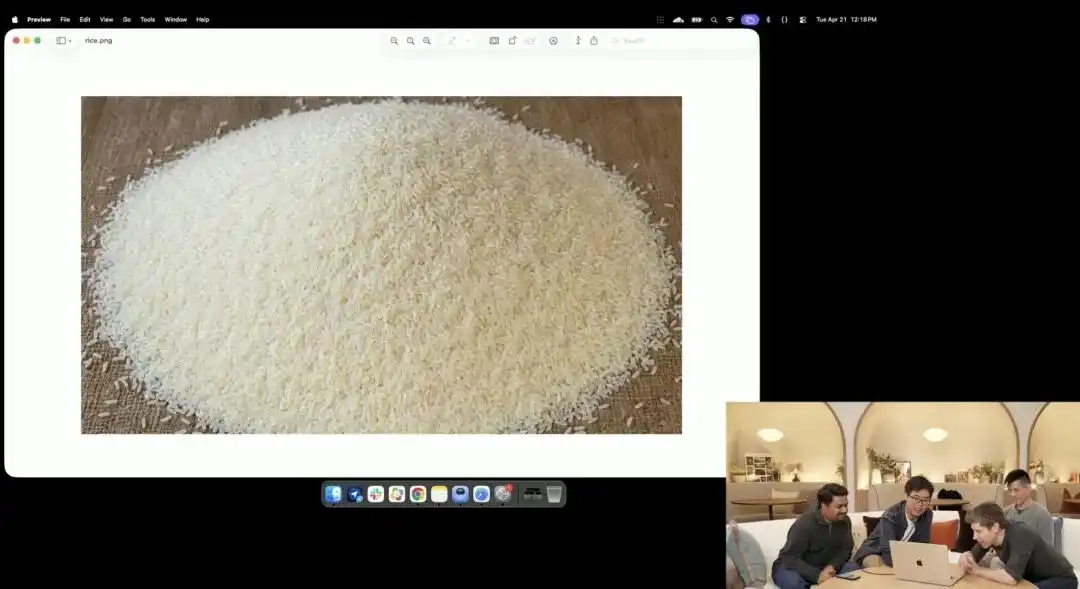
Khi hình ảnh được phóng to hàng chục lần trên màn hình, thậm chí xuất hiện các hạt pixel, bạn thực sự có thể tìm ra hạt vi mô được khắc chữ trong đống gạo.
Texture of this rice still conforms to the laws of physics, with text precisely embedded along the subtle curves of the grain.
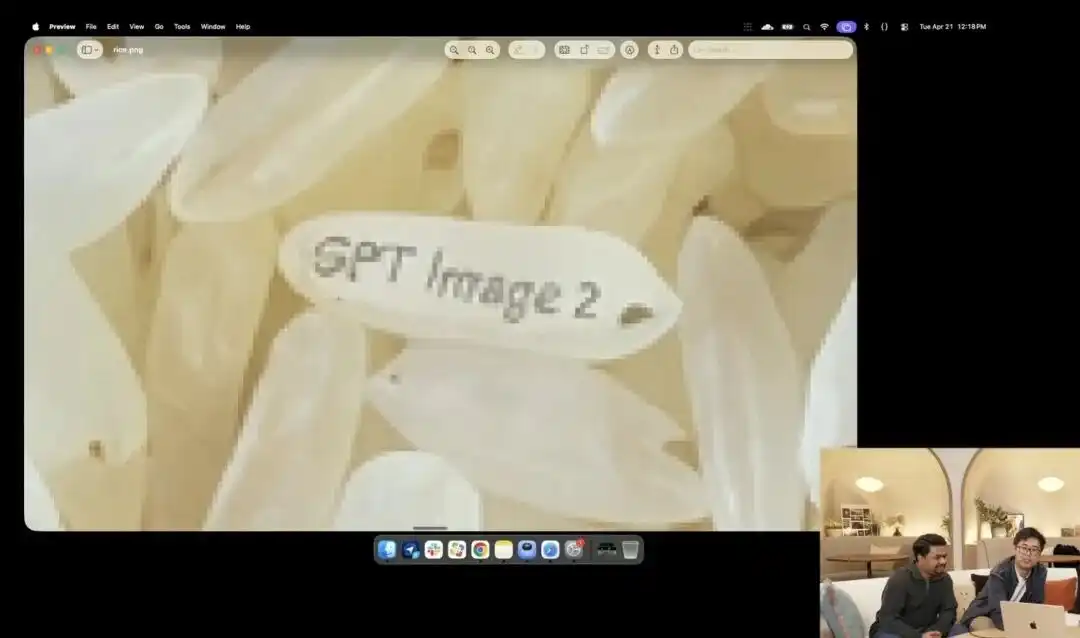
Tất cả các công việc còn lại — gọi chế độ viễn cảnh, tính độ sâu trường ảnh, tìm tọa độ vật lý của hạt gạo trong không gian tiềm ẩn và in chữ lên đó — đều được mô hình lớn tự động suy luận và hoàn thành trong chế độ suy nghĩ.
Ví dụ này cho thấy trực quan rằng mô hình hiểu vị trí không gian với độ chính xác đến mức pixel.
Điều này có nghĩa là sau này trong công việc thực tế, bạn có thể chỉnh sửa chính xác bất kỳ chi tiết nhỏ nào trong bản thiết kế, muốn sửa đâu thì sửa đó, thay vì như trước đây, muốn thay đổi cổ áo thì toàn bộ hình ảnh đều thay đổi theo.
PHẦN.03 Một số chi tiết kỹ thuật
Sức mạnh kiểm soát cực đoan và trí tuệ chiến lược này tuyệt đối không thể chỉ tạo ra bằng cách vô tư tăng cường sức tính toán.
Để tìm hiểu xem bí mật của nó thực sự là gì, tôi đã thực hiện một số bài kiểm tra thăm dò đối với GPT-Image-2.
Kết quả phát hiện ra một điểm rất thú vị.
Mặc dù tài liệu chính thức tuyên bố ngày cập nhật cơ sở tri thức tổng thể của GPT-Image-2 đã được nâng lên tháng 12 năm 2025, nhưng trong các bài kiểm tra thực tế của tôi.
Ngày kết thúc dữ liệu huấn luyện của Chế độ tức thì (Instant Mode) vẫn dừng lại vào cuối tháng 5 năm 2024;

Và chế độ suy nghĩ (Thinking Mode) yêu cầu suy ngẫm lâu hơn, cơ sở tri thức gốc của nó khoảng tháng 6 năm 2024 (nhưng có thể nhận được ngày chính xác hiện tại thông qua kết nối internet thời gian thực).

Dựa trên hai mốc thời gian này, có thể thấy rõ những dấu vết của nền tảng GPT-Image-2.
Hãy nói trước về chế độ tức thì với khả năng tạo hình ảnh tần suất cao.
Ngày hết hạn tháng 5 năm 2024 cho thấy nó rất có thể là bản sao trực tiếp của o4-mini, hoặc là phiên bản nhẹ của gia đình GPT-5 (GPT-5 mini hoặc thậm chí GPT-5 nano với tham số cực nhỏ).
Chính vì những nền tảng nhẹ này đã có khả năng lập kế hoạch không gian mạnh mẽ và hiểu rõ các lệnh phức tạp, nên việc tạo hình ảnh ở tầng trên mới có thể ổn định và không bị rối loạn.
Và mô hình tư duy cực kỳ thông minh, hiểu biết về chiến lược kinh doanh, không thể dựa trên mô hình nền tảng GPT-5.
Vì cơ sở kiến thức nền tảng của GPT-5 được cập nhật đến tháng 9 năm 2024.
Chế độ suy nghĩ rất có khả năng được kết nối với mô hình suy luận chuỗi O đang được liên tục cập nhật ở nền tảng (ví dụ: o4 hoặc o3 đã được nâng cấp).
Mô hình lớn đầu tiên sử dụng cơ chế suy nghĩ dài đặc trưng của chuỗi O, tính toán rõ ràng trong không gian ẩn các logic kinh doanh, tâm lý người dùng và tọa độ bố cục, sau đó chuyển cho mô-đun trực quan để thực hiện render pixel cuối cùng.
Tất nhiên, cũng có một con đường khả thi khác:
Dưới cơ chế phân bổ năng lực tính toán cực kỳ tinh vi bên trong OpenAI, chế độ nhanh có thể trực tiếp sử dụng GPT-5 nano để đảm bảo, trong khi chế độ suy nghĩ sử dụng GPT-5 mini lớn hơn một chút kết hợp với các công cụ bên ngoài.
Nhưng dù là tổ hợp nền tảng nào, nếu bạn theo dõi sát sao hệ sinh thái API của OpenAI, bạn sẽ nhận ra rằng logic sinh học cơ bản của nó đã hoàn toàn không còn ở cùng một cấp độ với Midjourney.
PHẦN.04 Mức giá được quan tâm nhất
Nhưng thay vì đoán giá nền tảng, điều đáng quan tâm hơn đối với các nhà phát triển và doanh nghiệp thực sự muốn tích hợp nó vào quy trình làm việc là bảng giá API thực tế và phản trực giác đến mức đáng kinh ngạc.
Trước đây, DALL-E 3 được tính phí theo từng hình ảnh (ví dụ: 0,04 USD mỗi hình ảnh).
Tuy nhiên, kể từ GPT-Image-1 thế hệ đầu tiên, OpenAI đã hoàn toàn chuyển đổi nó thành mô hình tính phí theo Token.
GPT-Image-2 lần này vẫn duy trì tiêu chuẩn này, không những vậy, nó còn tăng thêm tính năng và giảm giá.
The pricing per million tokens is as follows, according to the official announcement just released.
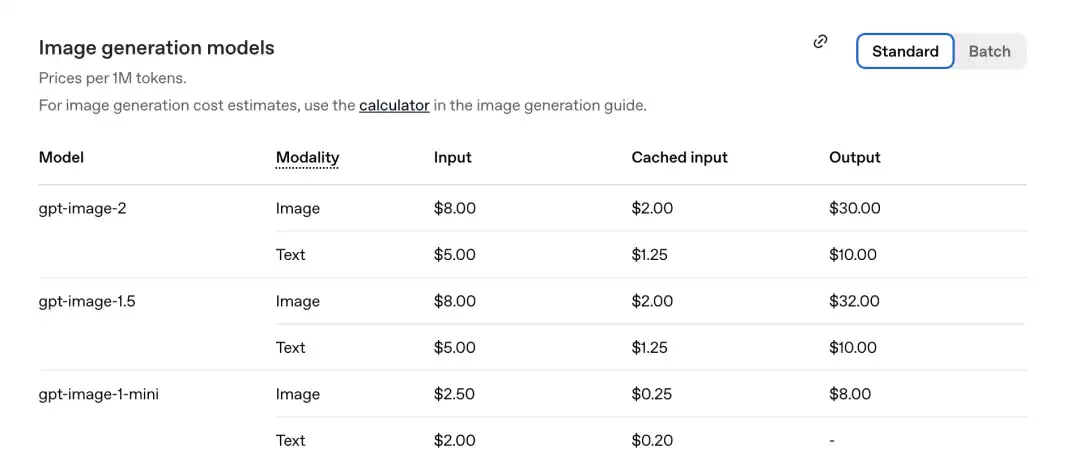
Phần hình ảnh của GPT-Image-2: Đầu vào 8.00, đầu vào được lưu trong bộ nhớ đệm (Cached inputs) 2.00, đầu ra $30.00.
So sánh với thế hệ trước gpt-image-1.5: đầu ra là $32.00.
Mô hình mới lại rẻ hơn.
Hãy cùng tính một phép toán.
Trong các mô hình trước đây, để tạo ra một hình ảnh chất lượng cao, thường cần tiêu tốn khoảng 1.000 đến 1.500 token đầu ra.
Tính theo giá 30 USD mỗi triệu token đầu ra, chi phí thực tế để tạo một hình ảnh dao động từ 0,03 đến 0,045 USD (tương đương khoảng 2 đến 3 xu nhân dân tệ).
Nếu bạn không cần phản hồi tức thì mà sử dụng chế độ API Batch (xử lý hàng loạt) do chính thức cung cấp, mức giá này sẽ giảm xuống còn một nửa (đầu ra giảm trực tiếp xuống $15.00).
Tính ra, để tạo một hình ảnh chỉ mất hơn 1 hào.
Giá cho đơn này đã đủ mang tính hiệu quả về chi phí, nhưng điểm mạnh thực sự của nó nằm ở mục đầu vào đã được lưu trong bộ nhớ đệm (Cached inputs) trong bảng giá.
Trước đây, khi vẽ truyện tranh hoặc thiết kế poster cùng một loạt, mỗi lần tạo lại, bạn đều phải tải lại nhiều hình tham khảo nhân vật, tóm tắt tình tiết trước và các prompt dài, chi phí đầu vào rất cao.
Nhưng trong mô hình tính phí token hiện nay, khi bạn yêu cầu nó tạo đồng thời 8 bức tranh truyện liền mạch, các yếu tố hình ảnh của bức đầu tiên sẽ được lưu trực tiếp vào bộ nhớ đệm ngữ cảnh.
Từ hình thứ hai trở đi, chi phí đầu vào hình ảnh đã giảm mạnh từ $8,00 xuống còn $2,00 (tức là chỉ thu 25% số tiền).
Điều này có nghĩa là, khi thực hiện các lô hình thương mại quy mô lớn hoặc yêu cầu tính nhất quán nhân vật cực cao trong quá trình tạo liên tục, chi phí biên của nó sẽ giảm mạnh.
Mô hình càng thông minh và vẽ càng nhiều, chi phí trung bình trên mỗi hình ảnh càng giảm.
Đây mới là logic tính phí công nghiệp thực sự đẩy các họa sĩ dây chuyền vào đường cùng.
PHẦN.05 Tiết lộ đội ngũ phía sau hậu trường
Cuối cùng, chúng ta cùng quay lại xem đội hình thị giác nội bộ của OpenAI đã trình diễn tại sự kiện phát sóng trực tiếp này; nhiều tính năng trước đây bạn nghĩ là phi lý nay hoàn toàn được giải thích rõ ràng.
Ví dụ, nó thực sự giải quyết những vấn đề về bố cục đa ngôn ngữ và các ký tự khó hiểu như thế nào.
Điều này không thể thiếu sự đóng góp của nhà khoa học kỳ cựu trong đội ngũ, Gabriel Goh.

Trong giới học thuật, ông nổi tiếng nhất với tư cách là tác giả cốt lõi của mô hình đa phương thức tiên phong CLIP.
CLIP đã đặt nền móng cho việc hiểu hiện đại về cách ngôn ngữ con người và các pixel hình ảnh tương ứng với nhau.
Với sự dẫn dắt của học giả chuyên về ánh xạ ngữ nghĩa đa mô-đun, GPT-Image-2 không còn đoán mò hình dạng chữ nữa, mà thực sự viết chữ ở cấp độ pixel.
Ví dụ khác, làm sao nó có thể hiểu được mối quan hệ không gian ba chiều, thậm chí tạo ra hình ảnh toàn cảnh 360 độ với tỷ lệ chiều dài và chiều rộng cực kỳ cực đoan, và còn hiểu được ánh sáng và bóng đổ vi mô trên hạt gạo.
Điều này phải cảm ơn thành viên cốt lõi khác là Alex Yu.

Trước khi gia nhập OpenAI, anh ấy là đồng sáng lập và cựu CTO của công ty khởi nghiệp nổi bật trong lĩnh vực tạo 3D, Luma AI, đồng thời cũng là học giả hàng đầu chuyên sâu vào việc nghiên cứu render thần kinh 3D (như NeRF).
Với sự hiện diện của anh ấy, GPT-Image-2 thực sự đã vượt ra ngoài việc tô điểm pixel 2D truyền thống.
Nó rất có thể đã tạo trước một cảnh ba chiều trong tâm trí, bố trí ánh sáng xong rồi mới render ra một mặt cắt 2D chính xác cho bạn.
Làm thế nào để đạt được sự nhất quán của truyện tranh nhiều trang đáng sợ đến vậy.
Điều này tương ứng với cặp đôi trẻ vừa tốt nghiệp từ MIT CSAIL trong đội ngũ:
Boyuan Chen (trái) và Kiwhan Song (phải).
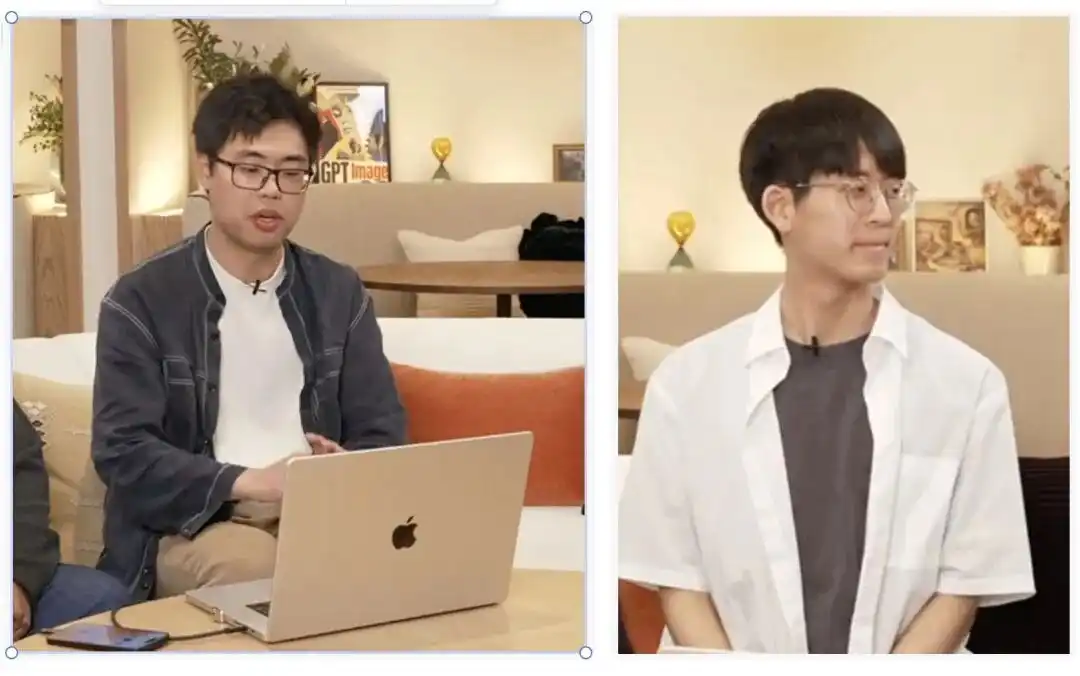
Hướng nghiên cứu cốt lõi của họ trong giới học thuật là các mô hình thế giới (World Models) và trí tuệ hình thể.
Việc dạy máy học cách hiểu cách thế giới vật lý vận hành, để các nhân vật giữ nguyên đặc điểm hoàn toàn nhất quán và không bị biến dạng qua các cảnh quay ở các thời gian và không gian khác nhau, đúng chính là vấn đề mà hai học giả này luôn nỗ lực giải quyết.
Cuối cùng, hãy thêm Nithanth Kudige (bên trái, tác giả quan trọng của mô hình suy luận chuỗi O) và Kenji Hata (bên phải, cựu nghiên cứu viên Google, tốt nghiệp từ Phòng thí nghiệm Thị giác Stanford), những người luôn nỗ lực kết nối các mô hình suy luận lớn với logic nền tảng về thị giác.

Khi nhóm người này tụ họp lại, logic suy luận cơ bản, render không gian 3D, căn chỉnh hoàn hảo giữa văn bản và hình ảnh, cùng các quy luật của thế giới vật lý đã được kết hợp một cách hợp lý vào cùng một mô hình.
PHẦN.06 Biên giới của GPT-Image-2
Mọi mô hình đều có giới hạn.
The official also acknowledges that it still struggles in the face of certain extreme situations.
Ví dụ như các hướng dẫn gấp giấy đòi hỏi sự lật ngược không gian vật lý chặt chẽ, giải khối Rubik, hay những chi tiết lặp lại cực kỳ dày đặc như cát mịn, vẫn sẽ chạm đến giới hạn khả năng của nó.
But in a commercial application context, this is an extremely minor flaw.
Đối với toàn bộ ngành thiết kế, chúng ta không cần phải khuấy động sự lo lắng; điều này hoàn toàn không đại diện cho sự diệt vong của thẩm mỹ.
Những người có gu thẩm mỹ, tầm nhìn kinh doanh và hiểu biết về chiến lược vẫn có thể tạo ra những sản phẩm xuất sắc bằng nó.
Nhưng sự thật khách quan là hàng rào bảo vệ của nghề thiết kế đã bị phá vỡ thực sự.
Trước đây, tôi từng sống bằng cách thuộc lòng các phím tắt của phần mềm thiết kế, biết cách căn chỉnh chữ thẳng hàng ngang dọc, biết cách bố cục theo từng ngôn ngữ, và biết cách chỉnh sửa hình ảnh tinh vi cũng như tách nền.
Nhưng về sau sẽ khó hơn, vì những kỹ năng trước đây có thể được định giá rõ ràng và giao dịch nay đã trở thành các lệnh cơ bản mà bất kỳ ai cũng có thể gọi miễn phí chỉ bằng một câu lệnh.
Sau một thời gian im lặng, OpenAI đã sử dụng một cách rất bình lặng nhưng cực kỳ mạnh mẽ để một lần nữa chứng minh rằng, trên bàn bài này, ai mới thực sự nắm giữ lá bài cuối cùng.
Chuỗi công cụ thực thi cũ đang bị phá vỡ, vấn đề còn lại cho ngành công nghiệp không còn là AI có thay thế chúng ta hay không, mà là chúng ta nên thích nghi như thế nào với dây chuyền sản xuất hoàn toàn mới này.