









Đêm nay, ChatGPT Images 2.0 chính thức ra mắt, trở thành AI hình ảnh đầu tiên "biết suy nghĩ". Otomo khen ngợi đây là bước nhảy vọt từ GPT-3 đến GPT-5. Nó không chỉ có thể hiểu chính xác các lệnh bằng tiếng Trung, tạo hình giao diện người dùng phức tạp, mà thậm chí còn có thể khắc chữ lên hạt gạo.
Tác giả bài viết, nguồn: Newzhong
OpenAI quen thuộc ấy đã trở lại!
Vào lúc nửa đêm, Ultraman trực tiếp dẫn đầu, mở buổi phát trực tuyến 20 phút, phá vỡ sự im lặng kéo dài nhiều ngày.
OpenAI cuối cùng cũng đã ra mắt ChatGPT Images 2.0 như tin đồn, chính thức mở ra một kỷ nguyên mới trong việc tạo hình ảnh.

Images 2.0 là một bước nhảy vọt về chất lượng, với những đột phá lớn trong việc hiểu chính xác các lệnh dài, sắp xếp chính xác và làm rõ mối quan hệ giữa các đối tượng, cũng như render văn bản dày đặc.
Điều quan trọng nhất là nó là mô hình hình ảnh đầu tiên có khả năng “suy nghĩ”, có thể tìm kiếm thông tin thời gian thực trên mạng và tự kiểm tra lại.
Nó còn có thể tạo ra tám hình ảnh với phong cách nhất quán trong một lần, hỗ trợ độ phân giải siêu rõ lên đến 2K.
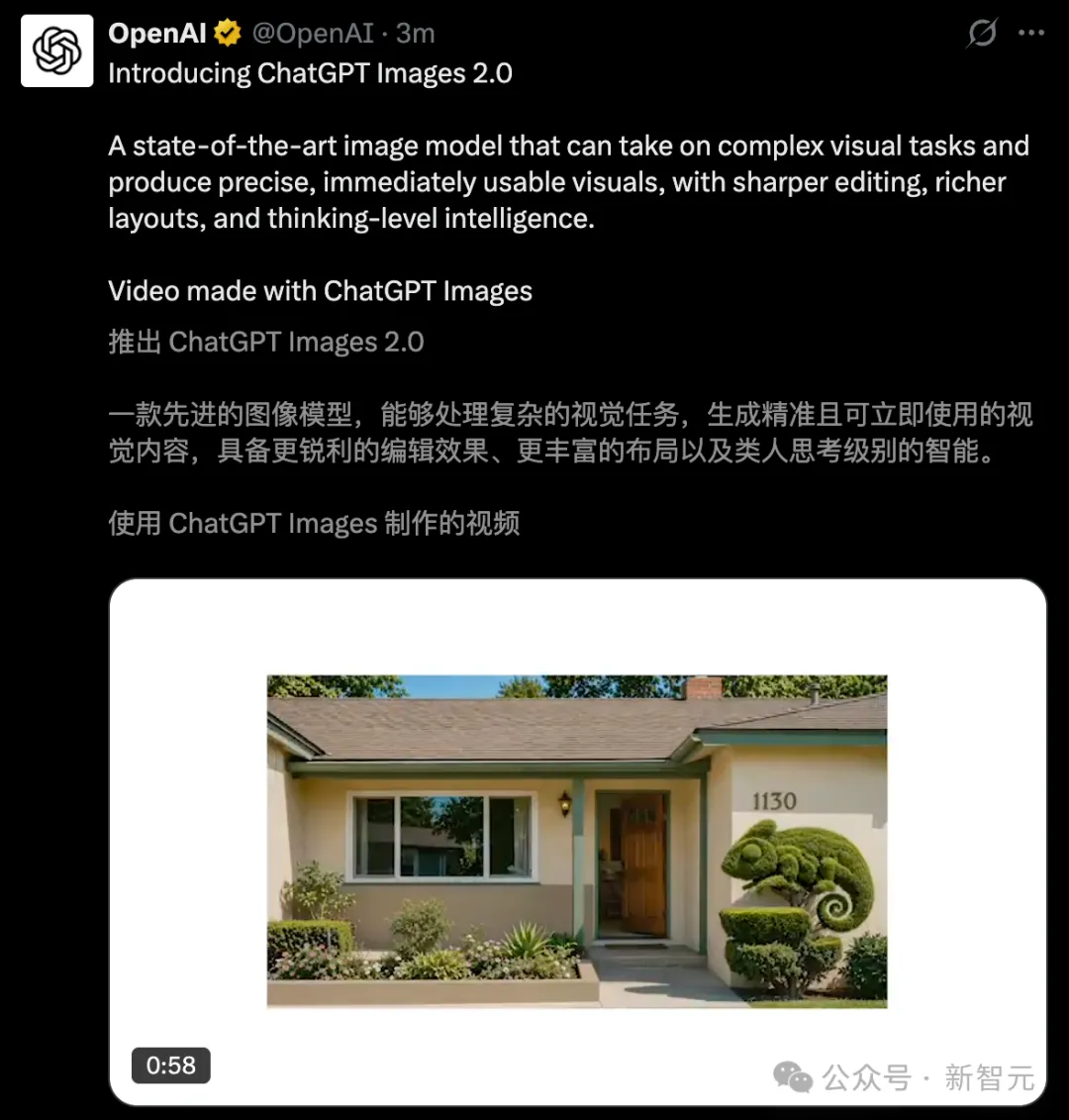
Nói một cách đơn giản, sự ra đời của Images 2.0 đã tái định nghĩa sức mạnh của việc tạo hình ảnh—
- Độ chính xác từng pixel: Tạo一键生成 các chi tiết phức tạp như văn bản cỡ nhỏ, biểu tượng, các yếu tố giao diện người dùng, hỗ trợ đầu ra toàn kích thước từ 3:1 đến 1:3;
- Chuyển biến đa ngôn ngữ: Hiển thị chính xác các chữ không thuộc bảng chữ cái La-tinh như Trung, Nhật, Hàn, không chỉ viết đúng chữ mà còn đảm bảo câu văn trôi chảy, mạch lạc;
- Phong cách trưởng thành: nắm bắt được các ngôn ngữ trực quan như cảm giác chân thực như ảnh chụp, khung hình phim, nghệ thuật pixel, truyện tranh, v.v.;
- Think: Image model with reasoning capabilities, capable of web search and self-checking outputs, with knowledge updated to December 2025.
Trong bảng xếp hạng mới nhất của Arena, Images 2.0 dẫn đầu cách biệt, lên ngôi vương AI tạo hình ảnh toàn cầu. Với sức mạnh áp đảo, Images 2.0 vượt xa các phiên bản Google Nano Banana 2/Pro tới 242 điểm.
Nó đứng đầu trong cả 7 danh mục văn bản-dẫn-hình ảnh.


Điều đáng sợ nhất là nó có thể tạo ra ở cấp độ pixel.
Một hình ảnh được tạo trong buổi phát trực tiếp, trong đó một hạt gạo đã được khắc chữ “GPT image 2”.
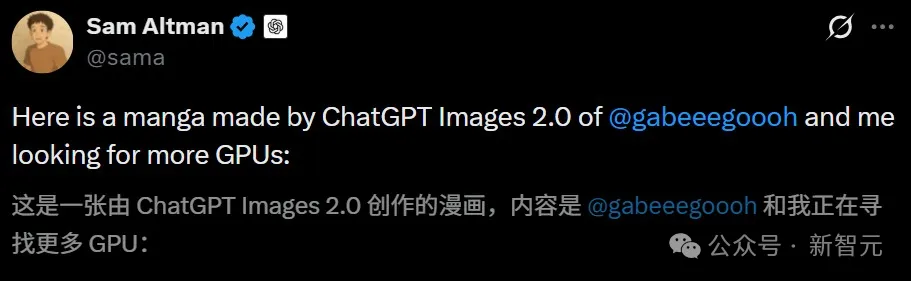
Ultraman cũng đã trưng bày thêm hình ảnh truyện tranh với Gabriel Goh, người phụ trách hình ảnh 4o, sử dụng nhiều GPU hơn.

Các cư dân mạng đều bắt tay vào sử dụng và một lần nữa ấn tượng trước sức mạnh của Images 2.0.
Thậm chí, có người cho rằng, "OpenAI cuối cùng đã một lần nữa dẫn đầu lĩnh vực tạo hình ảnh"!

Tiếng Trung trực tiếp lên đỉnh OpenAI tự chế meme “đón bạn một cách ổn định”
Các mô hình hình ảnh trước đây, khi xử lý ngôn ngữ tiếng Anh và chữ cái Latinh thì vẫn ổn, nhưng một khi gặp chữ Trung, Nhật, Hàn thì bắt đầu trở nên "vẽ bậy".
Lần này, bản demo tiếng Trung được công bố trên tài khoản chính thức đã gây chấn động.
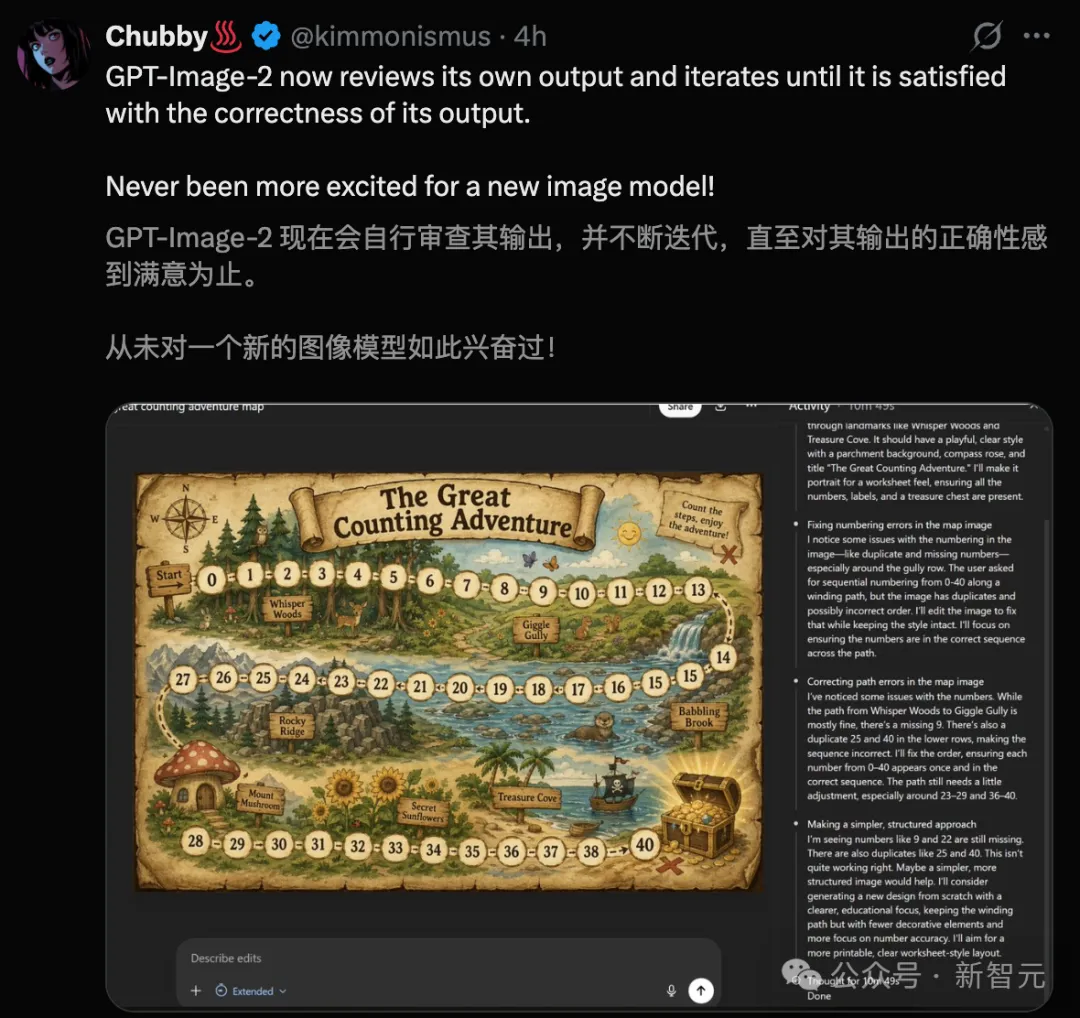
Nhà khoa học nghiên cứu của OpenAI, Trần Bác Viễn, xuất hiện trực tiếp (có khả năng cao là tự mình viết prompt), đã tạo ra một trang đầy đủ truyện tranh màu tiếng Trung, kể về câu chuyện tối ưu hóa việc hiển thị văn bản tiếng Trung trong ChatGPT Image 2 tại OpenAI.

Hình này đồng thời chứng minh ba điều: khả năng hiển thị văn bản Trung Quốc đã có bước nhảy vọt, độ chính xác khi điều khiển cỡ chữ cực nhỏ, và khả năng tạo ra một lần duy nhất các truyện tranh nhiều khung hình phức tạp.
Truyện tranh gồm năm hàng, hàng đầu tiên là Trần Bác Viễn đang cúi đầu làm việc trước máy tính, trên nền có trà sữa trân châu, trên tường dán một quả chuối bằng băng dính (tôn vinh cảnh tượng nổi tiếng trong giới nghệ thuật).
Hàng thứ hai là bảng thông tin phong cách vẽ tay đa ngôn ngữ mà anh ấy tạo ra cho quê hương Vô Tích, với tất cả các chữ Hán nhỏ dày đặc được hiển thị chính xác.
Hàng thứ ba là cảnh cả đội phấn khích sau khi nhìn thấy hiệu quả.
Hàng thứ tư, phong cách chuyển đổi, Trần Bác Viễn đang nghỉ ngơi với điện thoại và nhận được tin nhắn dịch từ Ultraman, chúc mừng thành quả trình bày tiếng Trung của đội nhóm.
Sau đó, phần quan trọng nhất đã đến.
Hàng thứ năm, Trần Bác Viễn nhìn thấy bức ảnh chúc mừng do Ultraman tạo ra, ở vị trí trung tâm nổi bật ghi một câu: “Đón bạn một cách chắc chắn.”
Người hiểu thì hiểu.

GPT trong các cuộc hội thoại bằng tiếng Trung thường xuyên nói “Tôi sẽ nhẹ nhàng đỡ lấy bạn”, “Cảm xúc của bạn là hợp lý”, phong cách tư vấn tâm lý Mỹ vừa dầu mỡ vừa chân thành này đã bị người dùng Trung Quốc phàn nàn suốt hơn một năm qua.
Chen Boyuan trong truyện tranh lập tức sụp đổ, gào lên với vẻ giận dữ theo phong cách truyện tranh: “Trời ơi! Nó lại học được cách bắt rồi!”, những đồng đội bên cạnh hóa thành những đầu nhỏ toát mồ hôi lạnh, thì thầm: “Chúng tôi đang nỗ lực sửa nó!”
Đợt tự trào này, có thể cho điểm tối đa. (tự thêm mặt chó)

Ngoài tiếng Trung, OpenAI còn phát hành truyện tranh phiêu lưu thanh niên với toàn bộ lời thoại bằng tiếng Nhật, bao bì sách bằng chín ngôn ngữ như Hindi, Bengal, Telugu... của một hiệu sách Ấn Độ, cùng quảng cáo chỗ ở cao cấp kiểu Hanok bằng tiếng Hàn.
Ngôn ngữ không còn là “công dân hạng hai” trong việc tạo hình ảnh nữa.

Tạo ra từng pixel, bước nhảy vọt từ GPT-3 đến GPT-5
ChatGPT Images 2.0 có thể được coi là bước tiến tiếp theo trong việc tạo hình ảnh của OpenAI.
Trong buổi phát trực tiếp, Ultraman gọi đây là “cảm giác như nhảy thẳng từ GPT-3 lên GPT-5”.
Tải lên một bức ảnh nhóm bốn người, ChatGPT tạo ra một trang bìa tạp chí với thiết kế trang và bố cục chữ rất chỉn chu.
Hơn nữa, poster chứa đầy đủ chi tiết, xử lý chữ nhỏ và sự nhất quán của khuôn mặt nhân vật, mang lại cảm giác như một nhóm nam.

Về mặt chi tiết, đầu ra của ChatGPT đạt đến hiệu ứng “chân thực như ảnh thật”, sống động đến mức không thể phân biệt được là do AI tạo ra.
Ví dụ như hình dưới đây, quay trở lại năm 2015 khi OpenAI vừa mới thành lập, ánh sáng trong phòng học bậc thang và nội dung PPT khiến người ta kinh ngạc.
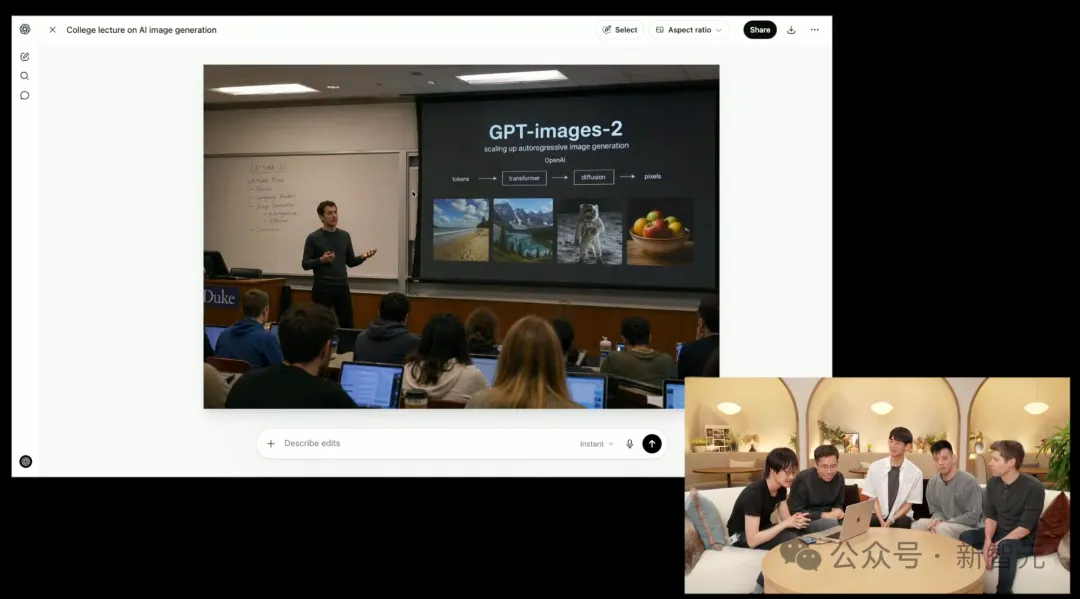
Điều khiến cả khán phòng kinh ngạc chính là một bức ảnh toàn cảnh 360° về con người đặt chân lên Mặt Trăng.
Đưa hình ảnh được tạo bởi ChatGPT vào trình xem toàn cảnh, bạn có thể đạt được hiệu quả như sau: vị trí của mặt trời, hướng bóng đổ và một số chi tiết khác đều rõ ràng.
Trong bản demo do chính thức phát hành, có một ảnh chụp màn hình cửa sổ ChatGPT trên trình duyệt macOS.
Cửa sổ xếp chồng, terminal mở ở nền sau, bàn làm việc bừa bộn, chi tiết thị giác nhiều đến mức phi lý, kết quả tạo ra gần như giống hệt ảnh chụp thực tế.
Độ chính xác khi hiển thị đến mức này cho thấy mô hình đã vượt qua ngưỡng tới hạn trong việc kiểm soát từng pixel trong hình ảnh.
Hình ảnh do AI tạo ra với độ chân thực như ảnh thật cuối cùng cũng không còn giống hình do AI tạo nữa
Style realism is another major leap forward.
Trước đây, các hình ảnh do AI tạo ra luôn mang một cảm giác “AI” khó diễn tả — da quá mịn, ánh sáng quá đồng đều, bố cục quá hoàn hảo, chỉ cần nhìn một cái là có thể nhận ra không phải ảnh chụp người thật.
Images 2.0 đi ngược lại, bắt đầu học cách "không hoàn hảo".
Trong bản demo chính thức có một bộ ảnh chụp nhanh với chất liệu phim 35mm, có thể thấy độ hạt, bố cục hơi lệch tâm, quần áo và tóc đang bay trong gió.
Nếu không nói với bạn rằng nó được tạo bởi AI, bạn sẽ nghĩ đó là kết quả của một nhiếp ảnh gia vô tình nhấn nút chụp ảnh bên lề đường.

Còn một bộ ảnh phong cách máy ảnh dùng một lần, mô phỏng cảnh phòng máy tính trường trung học Mỹ đầu những năm 2000, với học sinh chen chúc trước các màn hình CRT màu be đang sử dụng ChatGPT.
Chớp sáng quá sáng, mờ chuyển động nhẹ, dấu ngày màu cam ghi «02 18 04» ở góc, mọi «khuyết điểm thời kỳ phim» đều được tái hiện chính xác.

Về sự đa dạng phong cách, Images 2.0 cũng tạo ra khoảng cách.
Tỷ lệ khung hình hiện hỗ trợ rộng nhất 3:1 và cao nhất 1:3. Để minh họa, OpenAI đã công bố một bức tranh phong cảnh Trung Quốc truyền thống theo chiều ngang, với mực và nét vẽ được xử lý tinh tế cùng các khoảng trống hợp lý.
Poster phim Tân Sóng Pháp những năm 1960, thẻ bookmark phong cách Nghệ thuật Trang trí, hình thiết kế nhân vật hoạt hình, mỗi ngôn ngữ thị giác đều duy trì tính nhất quán phong cách cao, chứ không chỉ là “nhìn có vẻ giống”.

Mô hình hình ảnh có khả năng suy nghĩ, tạo ra tám hình ảnh liên tục trong một lần
Trong buổi phát trực tiếp, Gabriel Goh, người phụ trách hình ảnh của ChatGPT, cho biết Images 2.0 đã ra mắt hai chế độ—
- Chế độ tức thì (Instant Mode)
- Chế độ suy nghĩ (Thinking Mode)
Nâng cấp đột phá nhất nằm hoàn toàn trong "Chế độ suy nghĩ".
Khi chọn mô hình tư duy trong ChatGPT, Images 2.0 không còn chỉ là một trình tạo hình ảnh "bạn nói, tôi vẽ", mà đã trở thành một đối tác tư duy trực quan.
Nó sẽ tốn nhiều thời gian hơn để hiểu ý định của bạn, tìm kiếm thông tin trực tuyến để lấy dữ liệu thời gian thực, suy luận cấu trúc hình ảnh, rồi mới bắt đầu viết.
Quan trọng hơn, ở chế độ suy nghĩ, nó có thể tạo ra tối đa tám hình ảnh với phong cách nhất quán, nhân vật đồng nhất và nội dung tiến triển trong một lần.
Chỉ cần tải lên một bức ảnh chân dung, ChatGPT sẽ lập tức đưa ra tám bộ phối đồ mùa hè. Chọn một bộ, nó sẽ tạo thêm chi tiết từng món đồ từ nhiều góc nhìn khác nhau.
Trong nhiệm vụ này, ChatGPT đã gọi hai loại 「trí tuệ thị giác」 khác nhau:
Trước tiên là khả năng “hiểu thị giác”, nó cần thực sự “nhìn” vào bức ảnh. Hiểu được ngoại hình của một người, sau đó lên kế hoạch cho các phương án phối đồ phù hợp.
Một khía cạnh khác là khả năng “tạo hình ảnh trực quan”. Nó cần chuyển đổi bố cục trang phục đã lên kế hoạch thành một hình ảnh mạch lạc và có hệ thống.
Trước đây, để tạo một bộ tài liệu truyền thông xã hội, bạn phải tạo từng hình một và tự ghép chúng. Bây giờ, chỉ với một câu lệnh prompt, bạn có thể tạo đồng thời bốn kích thước: Twitter, Instagram Stories, Instagram Feed và LinkedIn, với màu sắc và phong cách bố cục thống nhất.
Phiên bản demo chính thức trình bày tài liệu quảng cáo của cửa hàng matcha ở Brooklyn, "kizuki", với hình ảnh matcha dâu lạnh dưới ánh nắng, kết hợp phong cách thời trang đường phố với sự tối giản kiểu Nhật, hỗ trợ ngay bốn kích thước nền tảng mạng xã hội.

Còn có một bản demo poster luận văn học thuật, tải trực tiếp file PDF, mô hình sẽ tự động trích xuất các biểu đồ, dữ liệu và cấu trúc chính, sắp xếp thành một poster ngang.

Đáng chú ý là, sau khi Images 2.0 kích hoạt chế độ suy nghĩ, nó còn có thể tìm kiếm thông tin trực tiếp trên internet.
Đội ngũ tiết lộ rằng «DuckTape» được thử nghiệm mù tại Arena vài ngày trước chính là Images 2.0 hôm nay.
Sau đó, họ yêu cầu Images 2.0 thu thập phản hồi từ người dùng mạng và tạo thành một hình ảnh. Không ngờ, mô hình còn tạo ra một “mã QR” có thể quét trực tiếp.
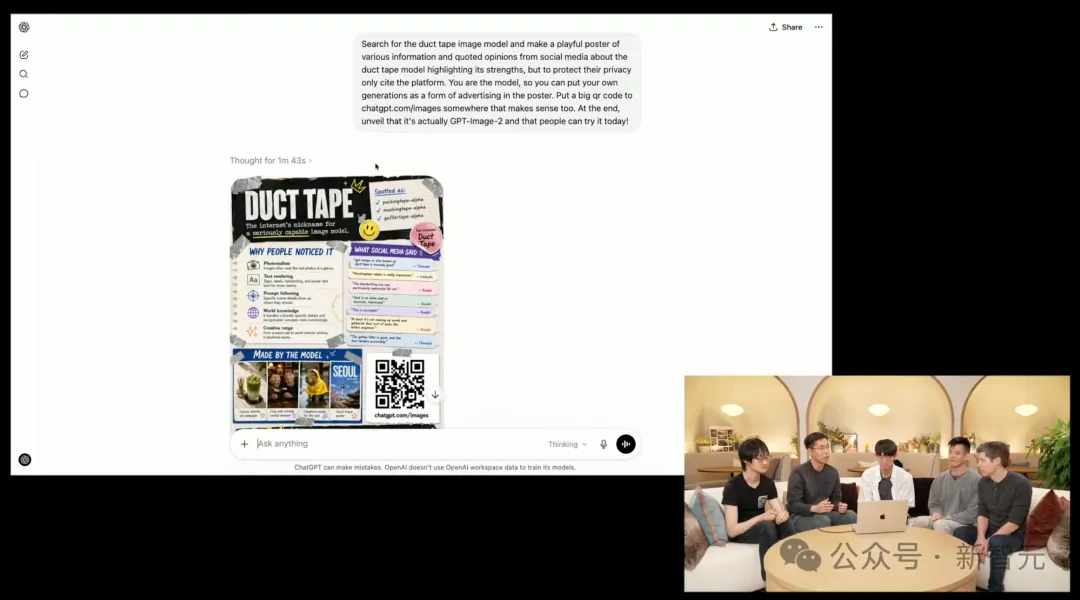
ChatGPT, Codex đã được mở rộng toàn diện
Từ hôm nay, tất cả ChatGPT và Codex đều có thể sử dụng ChatGPT Images 2.0.
Tính năng tạo hình ảnh với quá trình “suy nghĩ” đã được mở cho người dùng ChatGPT Plus, Pro và Business. Mô hình nền tảng gpt-image-2 cũng đã được triển khai trên API.

Về mặt định giá, ChatGPT Images 2.0 mạnh mẽ hơn, trong khi giá đầu vào/đầu ra token không tăng.
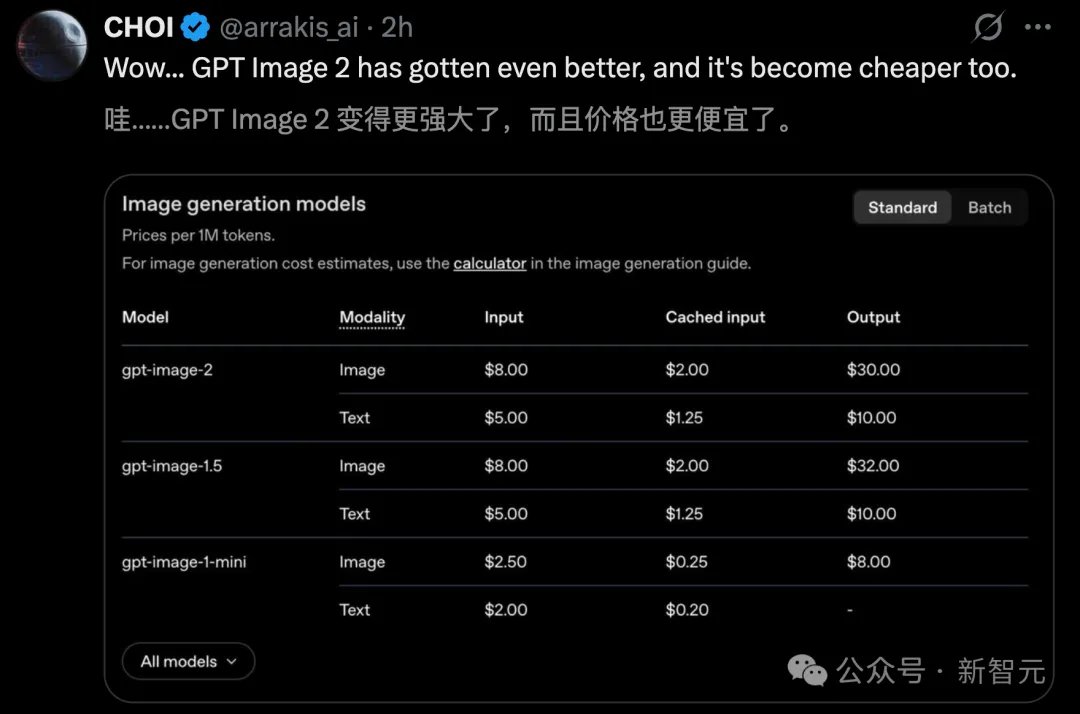
Đối với người dùng thông thường, những công việc trước đây phải tốn nhiều thời gian để chỉnh sửa trong Photoshop như hình ảnh minh họa bài thuyết trình, poster mạng xã hội và thẻ quảng bá sản phẩm, giờ đây chỉ cần một câu lệnh prompt là xong.
Đối với các nhà phát triển và doanh nghiệp, các quy trình trực quan đòi hỏi nhiều lao động thủ công như quảng cáo địa phương hóa, infographics đa ngôn ngữ, nội dung giáo dục và công cụ thiết kế hiện đều có thể được tự động hóa hàng loạt thông qua API.
Trong Codex, việc tạo hình ảnh đã được tích hợp vào không gian làm việc, giúp đội ngũ thiết kế có thể tạo ra các phương án UI, so sánh các lựa chọn và chuyển đổi thành sản phẩm mà không cần chuyển đổi công cụ.
Thời khắc iPhone tạo hình ảnh?
Quay lại nhìn lại, từ DALL·E đến Midjourney đến Stable Diffusion, việc tạo hình ảnh bằng AI luôn ở trạng thái “đủ dùng nhưng chưa thực sự tốt”.
Vấn đề về hiển thị chữ không chính xác, hỗ trợ đa ngôn ngữ kém, phong cách đơn điệu, bố cục dễ nhận ra là do AI tạo ra—mỗi điểm này đều khiến những người muốn sử dụng hình ảnh AI trong các bối cảnh nghiêm túc nản lòng.
Images 2.0 đã khắc phục hoàn toàn những điểm yếu này và còn bổ sung khả năng suy luận cùng khả năng tạo nhiều hình ảnh cùng lúc.
Mặc dù nó vẫn còn khoảng cách với sự “hoàn hảo”, nhưng đây có thể là mô hình hình ảnh AI đầu tiên khiến các nhà thiết kế, chuyên gia marketing và người sáng tạo nội dung cảm thấy: “Mình thực sự có thể dùng cái này trong công việc của mình.”
Bây giờ, các nhà thiết kế có thể cần phải suy nghĩ lại xem lợi thế cạnh tranh thực sự của mình nằm ở đâu.
Tài liệu tham khảo:
https://x.com/OpenAI/status/2046661795327459677
https://x.com/OpenAI/status/2046670977145372771
https://openai.com/index/introducing-chatgpt-images-2-0/
https://x.com/sama/status/2046672912833458597