










Tác giả | ZeR0,骏达,Trí Dụng
Biên tập | Bóng đổ
Theo báo cáo ngày 5 tháng 1 từ Las Vegas của Xindongxi, mới đây, ông Jensen Huang, người sáng lập kiêm CEO của NVIDIA, đã phát biểu bài diễn văn chủ đề đầu tiên của năm 2026 tại Triển lãm Điện tử Tiêu dùng thế giới (CES 2026). Như thường lệ, ông Jensen Huang mặc áo da, và trong 1,5 giờ đã công bố liên tiếp 8 sản phẩm và công nghệ quan trọng, từ chip, khung máy cho đến thiết kế mạng, cung cấp một cái nhìn sâu sắc về nền tảng thế hệ mới hoàn toàn.

Trong lĩnh vực tính toán tăng tốc và hạ tầng AI, NVIDIA đã công bố các sản phẩm sau: siêu máy tính AI NVIDIA Vera Rubin POD, thiết bị quang học tích hợp trên cùng gói NVIDIA Spectrum-X Ethernet, nền tảng bộ nhớ lưu trữ ngữ cảnh suy luận NVIDIA, và hệ thống NVIDIA DGX SuperPOD dựa trên DGX Vera Rubin NVL72.

POD Vera Rubin của NVIDIA sử dụng 6 loại chip tự phát triển của NVIDIA, bao gồm CPU, GPU, khả năng mở rộng theo chiều dọc (Scale-up), mở rộng theo chiều ngang (Scale-out), lưu trữ và xử lý, tất cả các thành phần đều được thiết kế đồng bộ, có thể đáp ứng nhu cầu của các mô hình tiên tiến và giảm chi phí tính toán.
Trong đó, CPU Vera sử dụng kiến trúc lõi Olympus tùy chỉnh, GPU Rubin sau khi tích hợp Transformer Engine có hiệu năng suy luận NBFP4 lên đến 50 PFLOPS, băng thông NVLink mỗi GPU nhanh đến 3,6 TB/giây, hỗ trợ thế hệ thứ ba tính toán bí mật tổng thể (TEE rack-level đầu tiên), tạo môi trường thực thi đáng tin cậy hoàn chỉnh vượt qua ranh giới CPU và GPU.

Tất cả các con chip đã được hoàn tất, NVIDIA đã kiểm chứng toàn bộ hệ thống NVIDIA Vera Rubin NVL72, các đối tác cũng đã bắt đầu chạy các mô hình và thuật toán AI tích hợp nội bộ của họ, toàn bộ hệ sinh thái đều đang chuẩn bị triển khai cho Vera Rubin.
Trong các bản phát hành khác, công nghệ quang tích hợp trên cùng một gói của bộ mạng NVIDIA Spectrum-X đã tối ưu hóa đáng kể hiệu suất điện năng và thời gian hoạt động của ứng dụng; nền tảng bộ nhớ lưu trữ NVIDIA Inference Context Memory Storage đã định nghĩa lại kiến trúc lưu trữ nhằm giảm tính toán trùng lặp và nâng cao hiệu suất suy luận; hệ thống NVIDIA DGX SuperPOD dựa trên DGX Vera Rubin NVL72 đã giảm chi phí token của mô hình MoE quy mô lớn xuống còn 1/10.

Về các mô hình mở, NVIDIA đã công bố mở rộng bộ công cụ mô hình mã nguồn mở, phát hành các mô hình, tập dữ liệu và thư viện mới, bao gồm việc bổ sung các mô hình như mô hình Agentic RAG, mô hình an toàn và mô hình âm thanh vào dòng mô hình mở NVIDIA Nemotron, đồng thời cũng giới thiệu một mô hình mở hoàn toàn mới dành cho mọi loại robot. Tuy nhiên, Jensen Huang không đi sâu chi tiết trong bài phát biểu của mình.
Về mặt AI vật lý,Thời điểm ChatGPT của AI vật lý đã đến.Công nghệ toàn bộ từ đầu đến cuối của NVIDIA cho phép hệ sinh thái toàn cầu thay đổi các ngành công nghiệp thông qua công nghệ robot được điều khiển bởi AI. Thư viện công cụ AI đa dạng của NVIDIA, bao gồm bộ mô hình mã nguồn mở Alpamayo mới, giúp ngành giao thông vận tải toàn cầu nhanh chóng đạt được khả năng lái xe an toàn cấp độ L4. Nền tảng lái xe tự động NVIDIA DRIVE hiện đã được đưa vào sản xuất, được trang bị trên tất cả các mẫu xe Mercedes-Benz CLA mới, hỗ trợ khả năng lái AI định nghĩa cấp độ L2++.

01. Siêu máy tính AI thế hệ mới: 6 loại chip tự phát triển, sức mạnh tính toán của một máy rack đạt 3,6 EFLOPS
Jensen Huang cho rằng, ngành công nghiệp máy tính sẽ trải qua một sự tái cấu trúc toàn diện mỗi 10 đến 15 năm, nhưng lần này, hai cuộc cách mạng nền tảng đang diễn ra đồng thời: từ CPU sang GPU, từ "phần mềm lập trình" sang "phần mềm huấn luyện", khiến tính toán tăng tốc và AI đang tái định hình toàn bộ kiến trúc tính toán. Ngành công nghiệp tính toán trị giá 10 nghìn tỷ USD trong thập kỷ qua đang trải qua một cuộc hiện đại hóa.
Đồng thời, nhu cầu về năng lực tính toán cũng tăng vọt. Kích thước mô hình tăng gấp 10 lần mỗi năm, số lượng token mà mô hình sử dụng để suy nghĩ tăng gấp 5 lần mỗi năm, trong khi giá của mỗi token lại giảm xuống còn 1/10 mỗi năm.
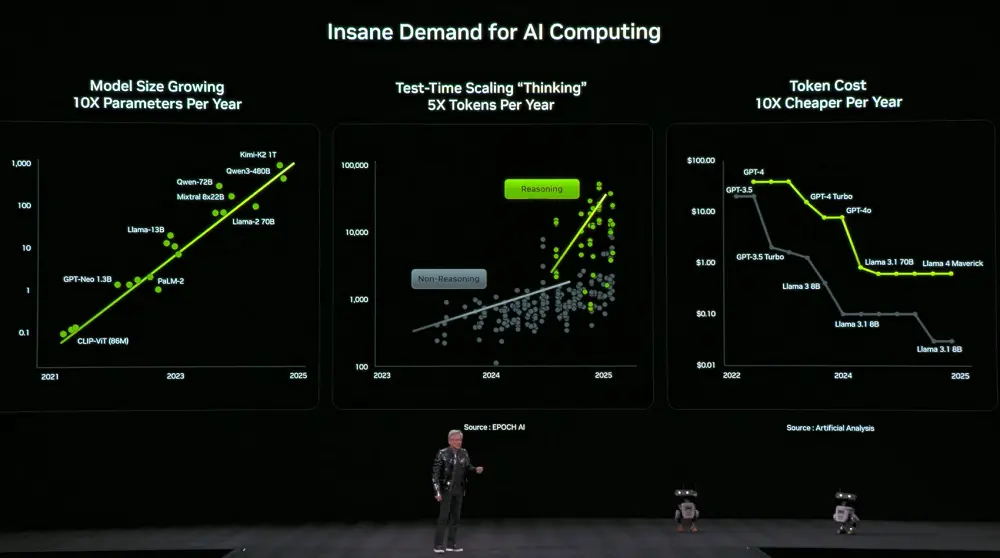
Để đáp ứng nhu cầu này, NVIDIA quyết định mỗi năm đều phát hành phần cứng tính toán mới. Jensen Huang tiết lộ rằng hiện tại, Vera Rubin cũng đã bắt đầu sản xuất hàng loạt.
Siêu máy tính AI mới của NVIDIA, NVIDIA Vera Rubin POD, sử dụng 6 loại chip do chính họ phát triển: CPU Vera, GPU Rubin, Switch NVLink 6, SmartNIC ConnectX-9 (CX9), DPU BlueField-4 và CPO 102,4T Spectrum-X.
Bộ xử lý Vera:Được thiết kế dành cho việc di chuyển dữ liệu và xử lý của các tác nhân (agent), sản phẩm này sở hữu 88 lõi tùy chỉnh Olympus của NVIDIA, công nghệ đa luồng không gian của NVIDIA với 176 luồng, hỗ trợ NVLink-C2C đạt 1,8TB/giây, cho phép bộ nhớ thống nhất giữa CPU và GPU. Dung lượng bộ nhớ hệ thống lên đến 1,5TB (gấp 3 lần bộ nhớ Grace CPU), băng thông bộ nhớ LPDDR5X của SOCAMM là 1,2TB/giây, đồng thời hỗ trợ tính toán bí mật ở cấp độ rack, giúp nâng cao gấp đôi hiệu năng xử lý dữ liệu.

GPU của Rubin:Giới thiệu bộ xử lý Transformer, hiệu năng suy luận NVFP4 lên đến 50 PFLOPS, gấp 5 lần GPU Blackwell, tương thích ngược, đồng thời cải thiện hiệu năng ở cấp độ BF16/FP4 mà vẫn duy trì độ chính xác suy luận; hiệu năng huấn luyện NVFP4 đạt 35 PFLOPS, gấp 3,5 lần Blackwell.
Rubin cũng là nền tảng đầu tiên hỗ trợ HBM4, với băng thông lên đến 22TB/giây, gấp 2,8 lần thế hệ trước, có thể cung cấp hiệu năng cần thiết cho các mô hình MoE và các tác vụ AI khắt khe.

Bộ chuyển đổi NVLink 6:Tốc độ đường truyền đơn lane được nâng lên 400 Gbps, sử dụng công nghệ SerDes để truyền tín hiệu tốc độ cao; mỗi GPU có thể đạt được độ rộng băng thông kết nối toàn phần là 3,6 TB/giây, gấp 2 lần thế hệ trước, tổng độ rộng băng thông là 28,8 TB/giây, hiệu năng tính toán trong mạng ở độ chính xác FP8 đạt 14,4 TFLOPS, hỗ trợ làm lạnh bằng chất lỏng 100%.

NVIDIA ConnectX-9 SuperNIC:Mỗi GPU cung cấp băng thông 1,6 Tb/giây, được tối ưu hóa cho AI quy mô lớn, có đường dẫn dữ liệu hoàn toàn định nghĩa bằng phần mềm, lập trình được và được tăng tốc.

NVIDIA BlueField-4:DPU 800 Gbps, được sử dụng cho các loại thẻ mạng thông minh và bộ xử lý lưu trữ, được trang bị CPU Grace 64 lõi, kết hợp với ConnectX-9 SuperNIC, để chuyển giao các tác vụ tính toán liên quan đến mạng và lưu trữ, đồng thời tăng cường khả năng bảo mật mạng. Hiệu năng tính toán gấp 6 lần thế hệ trước, băng thông bộ nhớ đạt gấp 3 lần, tốc độ truy cập dữ liệu lưu trữ của GPU được nâng cao gấp 2 lần.

NVIDIA Vera Rubin NVL72:Tích hợp tất cả các thành phần trên tại cấp độ hệ thống thành một hệ thống xử lý đơn rack, có 20 tỷ bóng bán dẫn, hiệu năng suy luận NVFP4 đạt 3,6 EFLOPS và hiệu năng huấn luyện NVFP4 đạt 2,5 EFLOPS.
Hệ thống này có dung lượng bộ nhớ LPDDR5X lên đến 54TB, gấp 2,5 lần thế hệ trước; tổng dung lượng bộ nhớ HBM4 đạt 20,7TB, gấp 1,5 lần thế hệ trước; băng thông HBM4 đạt 1,6PB/giây, gấp 2,8 lần thế hệ trước; tổng băng thông mở rộng dọc đạt 260TB/giây, vượt qua quy mô băng thông tổng thể của toàn bộ internet toàn cầu.

Hệ thống này dựa trên thiết kế khung xương MGX thế hệ thứ ba, với khay tính toán được thiết kế theo kiểu mô-đun, không cần máy chủ trung tâm, không cần cáp và không cần quạt, giúp tốc độ lắp ráp và bảo trì nhanh hơn 18 lần so với GB200. Công việc lắp ráp trước đây mất 2 giờ nay chỉ mất khoảng 5 phút. Trước đây hệ thống sử dụng khoảng 80% làm mát bằng chất lỏng, hiện nay đã đạt 100% làm mát bằng chất lỏng. Một hệ thống đơn lẻ có trọng lượng lên tới 2 tấn, và khi thêm chất làm mát bằng nước, tổng trọng lượng có thể đạt 2,5 tấn.

Khay chuyển mạch NVLink cho phép bảo trì không gián đoạn và khả năng chịu lỗi, hệ thống vẫn có thể hoạt động khi khay được tháo ra hoặc chỉ triển khai một phần. Bộ điều khiển RAS thế hệ thứ hai cho phép kiểm tra tình trạng hoạt động không gián đoạn.
Những đặc tính này giúp tăng thời gian vận hành hệ thống và khối lượng xử lý, đồng thời giảm thêm chi phí huấn luyện và suy luận, đáp ứng được yêu cầu về độ tin cậy và khả năng bảo trì cao của trung tâm dữ liệu.
Hơn 80 đối tác của MGX đã sẵn sàng hỗ trợ triển khai Rubin NVL72 trong các mạng quy mô lớn.
02. Ba sản phẩm mới cải thiện đáng kể hiệu suất suy luận AI: Bộ phận CPO mới, lớp lưu trữ ngữ cảnh mới, DGX SuperPOD mới
Đồng thời, NVIDIA đã giới thiệu 3 sản phẩm mới quan trọng: Bộ quang học tích hợp trên cùng gói Ethernet NVIDIA Spectrum-X, nền tảng Bộ nhớ Lưu trữ Bối cảnh Suy luận NVIDIA, và hệ thống NVIDIA DGX SuperPOD dựa trên DGX Vera Rubin NVL72.
1. NVIDIA Spectrum-X Ethernet tích hợp quang học chung
Công nghệ quang tích hợp trên bo (co-packaged optics) của Ethernet NVIDIA Spectrum-X dựa trên kiến trúc Spectrum-X, sử dụng thiết kế 2 vi xử lý, áp dụng SerDes 200Gbps, mỗi khối ASIC cung cấp băng thông 102,4 Tb/giây.
Nền tảng trao đổi này bao gồm một hệ thống mật độ cao 512 cổng và một hệ thống gọn nhẹ 128 cổng, tốc độ mỗi cổng đều là 800Gb/s.

Hệ thống chuyển mạch CPO (Quang học Đóng gói Chung) có thể đạt được sự cải thiện hiệu suất năng lượng gấp 5 lần, độ tin cậy cao hơn gấp 10 lần và thời gian hoạt động của ứng dụng tốt hơn gấp 5 lần.
Điều này có nghĩa là mỗi ngày có thể xử lý nhiều token hơn, qua đó giảm thêm tổng chi phí sở hữu trung tâm dữ liệu (TCO).
2. Bộ nhớ nền tảng NVIDIA Trừu tượng suy luận
NVIDIA Inference Context Memory Storage Platform là một cơ sở hạ tầng lưu trữ AI gốc cấp POD, được sử dụng để lưu trữ bộ nhớ đệm KV, dựa trên BlueField-4 và Spectrum-X Ethernet tăng tốc, tích hợp chặt chẽ với NVIDIA Dynamo và NVLink, thực hiện việc lập lịch ngữ cảnh phối hợp giữa bộ nhớ, lưu trữ và mạng.
Nền tảng này xử lý ngữ cảnh như một loại dữ liệu hàng đầu, đạt được hiệu năng suy luận nhanh gấp 5 lần và hiệu quả năng lượng tốt hơn gấp 5 lần.

Điều này đặc biệt quan trọng đối với các ứng dụng có độ dài bối cảnh lớn như hội thoại nhiều vòng, RAG, suy luận đa bước theo mô hình đại lý, v.v., những công việc phụ thuộc rất nhiều vào khả năng lưu trữ, tái sử dụng và chia sẻ hiệu quả bối cảnh trong toàn bộ hệ thống.
AI đang tiến hóa từ các chatbot thành Agentic AI (các thể thông minh), có khả năng suy luận, gọi các công cụ và duy trì trạng thái trong thời gian dài. Các cửa sổ ngữ cảnh đã được mở rộng lên đến hàng triệu token. Những ngữ cảnh này được lưu trữ trong KV Cache. Việc tính toán lại từng bước sẽ lãng phí thời gian GPU và gây ra độ trễ lớn, do đó cần phải có sự lưu trữ.
Tuy nhiên, bộ nhớ GPU nhanh nhưng lại khan hiếm, trong khi mạng lưu trữ truyền thống lại quá kém hiệu quả đối với bối cảnh ngắn hạn. Cổ chai của AI suy luận đang chuyển từ tính toán sang lưu trữ bối cảnh. Do đó, chúng ta cần một lớp bộ nhớ mới, trung gian giữa GPU và lưu trữ, được tối ưu hóa đặc biệt cho suy luận.

Lớp này không còn là một bản vá sau sự kiện nữa, mà phải được thiết kế đồng bộ với lưu trữ mạng, để di chuyển dữ liệu bối cảnh với chi phí thấp nhất.
Là một cấp độ lưu trữ mới, nền tảng bộ nhớ lưu trữ ngữ cảnh suy luận của NVIDIA không tồn tại trực tiếp trong hệ thống máy chủ, mà được kết nối bên ngoài thiết bị tính toán thông qua BlueField-4. Ưu điểm chính của nó nằm ở chỗ có thể mở rộng quy mô bể lưu trữ một cách hiệu quả hơn, từ đó tránh được việc tính toán lại KV Cache.
NVIDIA đang hợp tác chặt chẽ với các đối tác lưu trữ để tích hợp nền tảng bộ nhớ ngữ cảnh suy luận NVIDIA vào nền tảng Rubin, cho phép khách hàng triển khai nó như một phần của hạ tầng AI tích hợp đầy đủ.
3. NVIDIA DGX SuperPOD được xây dựng dựa trên Vera Rubin
Trên phương diện hệ thống, NVIDIA DGX SuperPOD là bản thiết kế triển khai nhà máy AI quy mô lớn, sử dụng 8 hệ thống DGX Vera Rubin NVL72, mở rộng mạng dọc bằng NVLink 6, mở rộng mạng ngang bằng Spectrum-X Ethernet, tích hợp nền tảng lưu trữ bộ nhớ ngữ cảnh suy luận của NVIDIA và đã được kiểm chứng về mặt kỹ thuật.
Toàn bộ hệ thống được quản lý bởi phần mềm NVIDIA Mission Control, đạt được hiệu suất tối ưu. Khách hàng có thể triển khai hệ thống như một nền tảng trọn gói, thực hiện các nhiệm vụ huấn luyện và suy luận với số lượng GPU ít hơn.
Nhờ thiết kế đồng bộ tối ưu ở 6 cấp độ: vi xử lý, khay, khung, Pod, trung tâm dữ liệu và phần mềm, nền tảng Rubin đã đạt được sự giảm mạnh về chi phí huấn luyện và suy luận. So với thế hệ trước là Blackwell, để huấn luyện mô hình MoE quy mô tương đương, chỉ cần 1/4 số lượng GPU; trong khi giữ nguyên độ trễ, chi phí token của mô hình MoE lớn đã giảm xuống còn 1/10.
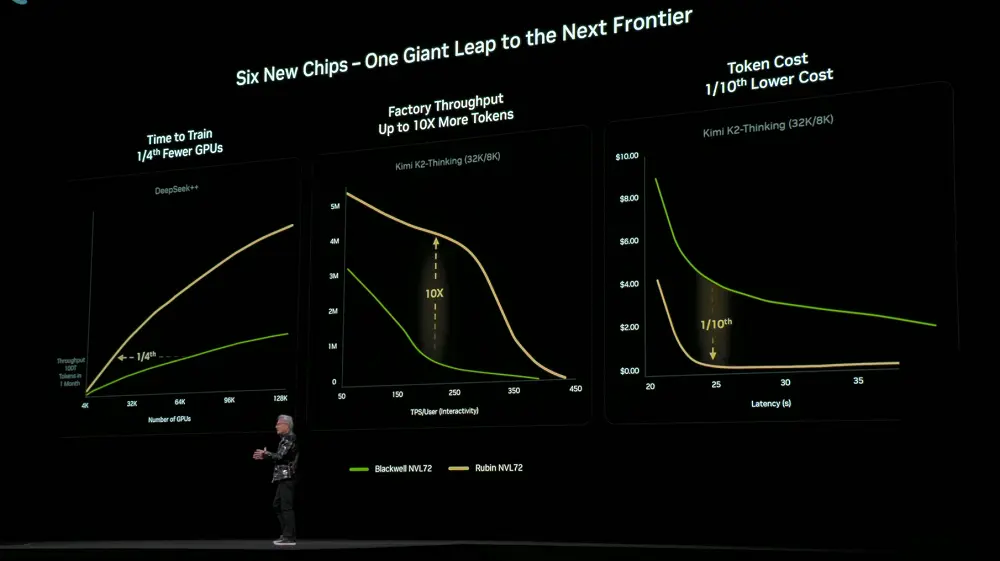
NVIDIA cũng đã công bố hệ thống DGX SuperPOD sử dụng DGX Rubin NVL8.
Với kiến trúc Vera Rubin, NVIDIA đang hợp tác cùng các đối tác và khách hàng để xây dựng hệ thống AI quy mô lớn nhất, hiện đại nhất và chi phí thấp nhất trên thế giới, thúc đẩy việc triển khai AI trở thành xu hướng phổ biến.

Cơ sở hạ tầng của Rubin sẽ được cung cấp thông qua các nhà cung cấp dịch vụ (CSP) và các nhà tích hợp hệ thống vào nửa sau của năm nay, và các công ty như Microsoft sẽ là những người triển khai đầu tiên.
03. Mở rộng thêm vũ trụ mô hình mở: Những đóng góp quan trọng từ mô hình mới, dữ liệu và hệ sinh thái mã nguồn mở
Trên mặt phần mềm và mô hình, NVIDIA tiếp tục tăng cường đầu tư vào các nguồn mở.
Các nền tảng phát triển chính như OpenRouter cho thấy, trong năm qua, lượng sử dụng mô hình AI đã tăng 20 lần, trong đó khoảng 1/4 token đến từ các mô hình mã nguồn mở.
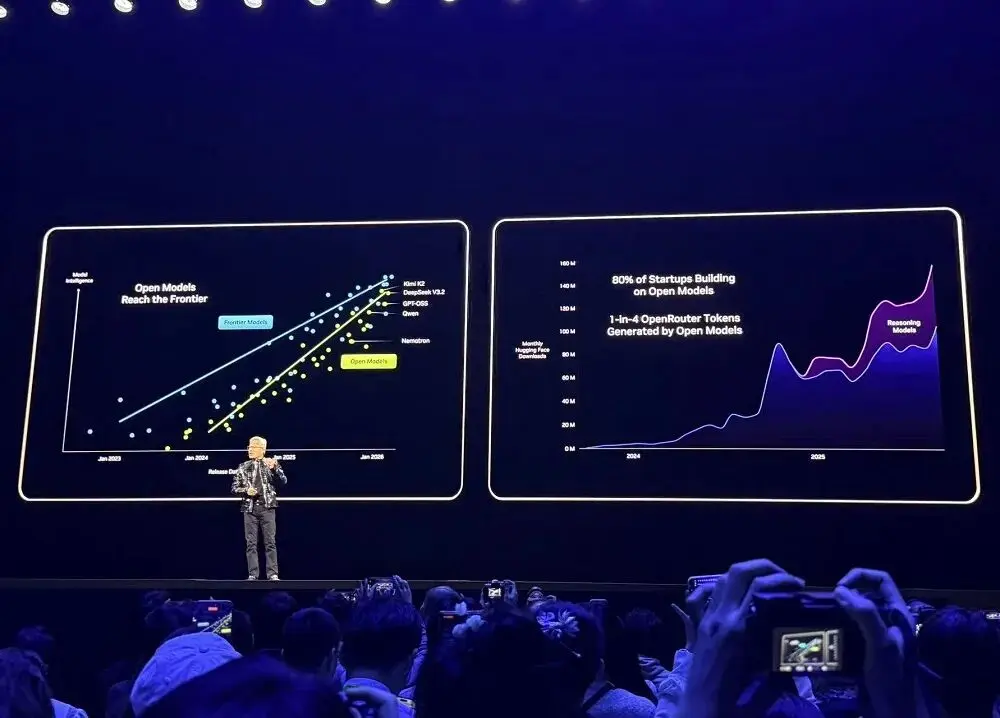
Năm 2025, NVIDIA trở thành nhà đóng góp lớn nhất các mô hình, dữ liệu và công thức mã nguồn mở trên Hugging Face, đã phát hành 650 mô hình mã nguồn mở và 250 tập dữ liệu mã nguồn mở.

Các mô hình mã nguồn mở của NVIDIA nằm trong top đầu của nhiều bảng xếp hạng. Các nhà phát triển không chỉ có thể sử dụng các mô hình mã nguồn mở này, mà còn có thể học hỏi từ chúng, huấn luyện liên tục, mở rộng tập dữ liệu, và sử dụng các công cụ mã nguồn mở cùng các công nghệ được tài liệu hóa để xây dựng hệ thống AI.

Cảm hứng từ Perplexity, Jensen Huang nhận thấy rằng các Agent nên là đa mô hình, đa đám mây và hỗn hợp đám mây, đây cũng là kiến trúc cơ bản của hệ thống AI Agent, gần như tất cả các công ty khởi nghiệp đều đang áp dụng.
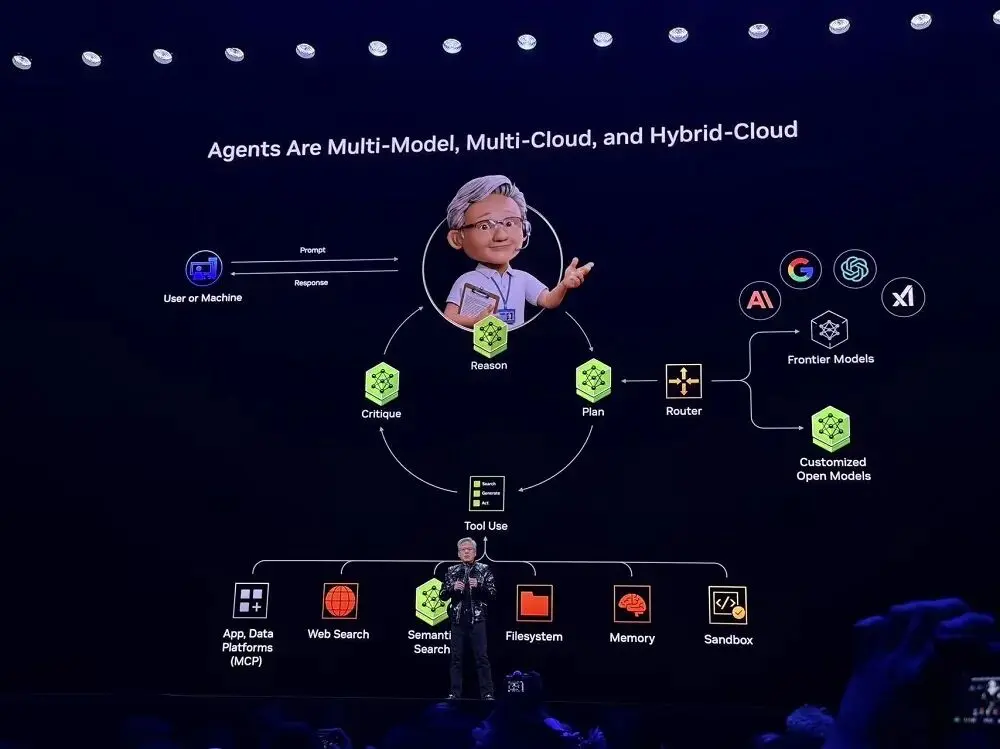
Với các mô hình và công cụ mã nguồn mở do NVIDIA cung cấp, các nhà phát triển hiện nay cũng có thể cá nhân hóa hệ thống AI và sử dụng khả năng của các mô hình tiên tiến nhất. Hiện tại, NVIDIA đã tích hợp các khung trên thành "bản thiết kế" (blueprint) và tích hợp chúng vào nền tảng SaaS. Người dùng có thể triển khai nhanh chóng bằng cách sử dụng bản thiết kế này.
Trong ví dụ trình diễn tại hiện trường, hệ thống này có thể tự động xác định nhiệm vụ nên được xử lý bởi mô hình riêng tư cục bộ hay mô hình viền mây dựa trên ý định của người dùng, đồng thời có thể gọi các công cụ bên ngoài (như API email, giao diện điều khiển robot, dịch vụ lịch, v.v.), và thực hiện tích hợp đa phương thức, xử lý thống nhất các loại thông tin như văn bản, âm thanh, hình ảnh, tín hiệu cảm biến robot, v.v.
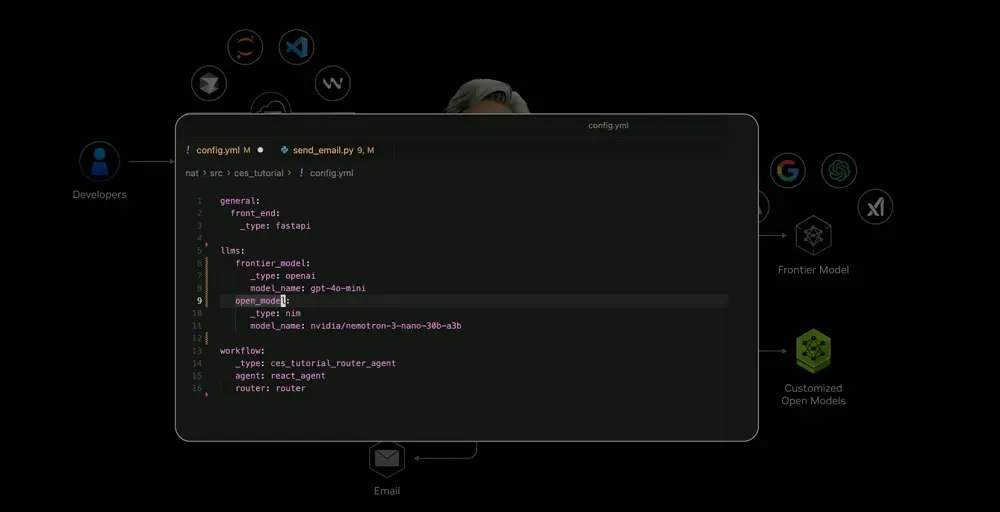
Những khả năng phức tạp này trong quá khứ là hoàn toàn không thể tưởng tượng được, nhưng hiện nay đã trở nên vô cùng đơn giản. Các nền tảng doanh nghiệp như ServiceNow, Snowflake đều có thể sử dụng các khả năng tương tự.
04. Mô hình Alpha-Mayo mã nguồn mở, giúp xe tự lái "suy nghĩ"
NVIDIA tin rằng AI vật lý và robot cuối cùng sẽ trở thành phân khúc điện tử tiêu dùng lớn nhất trên toàn cầu. Tất cả các vật thể có thể di chuyển cuối cùng sẽ đạt được sự tự động hóa hoàn toàn, được điều khiển bởi AI vật lý.
Trí tuệ nhân tạo (AI) đã trải qua các giai đoạn AI nhận thức, AI tạo sinh, AI tác nhân, và hiện nay đang bước vào kỷ nguyên AI vật lý, nơi trí thông minh tiến vào thế giới thực. Những mô hình này có khả năng hiểu các quy luật vật lý và trực tiếp tạo ra hành động từ các cảm nhận của thế giới vật lý.
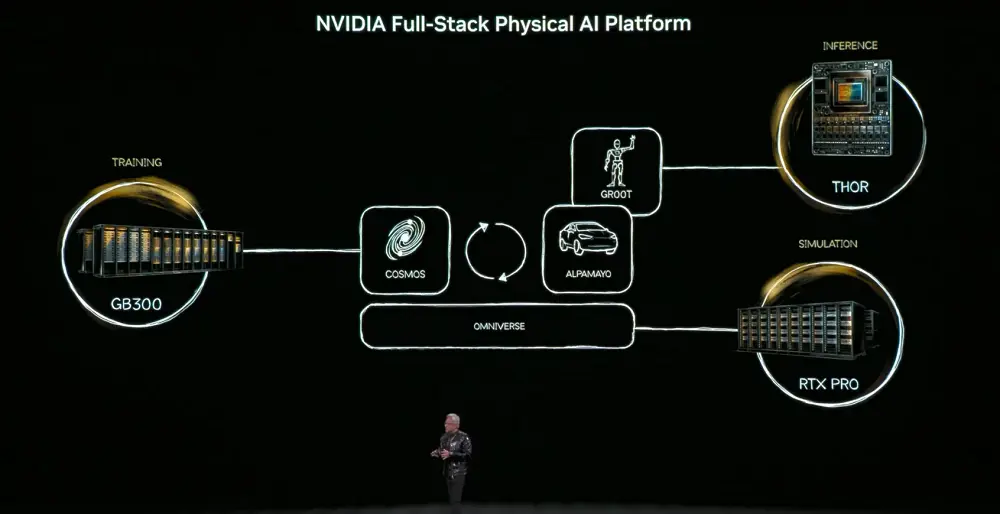
Để đạt được mục tiêu này, AI vật lý phải học được những kiến thức phổ thông về thế giới - sự tồn tại của vật thể, trọng lực, ma sát. Việc thu được những khả năng này sẽ dựa vào ba loại máy tính: máy tính huấn luyện (DGX) dùng để xây dựng mô hình AI, máy tính suy luận (linh kiện robot/xe hơi) dùng để thực thi theo thời gian thực, và máy tính mô phỏng (Omniverse) dùng để tạo dữ liệu tổng hợp và xác minh logic vật lý.
Mô hình cốt lõi là Cosmos World Foundation Model, mô hình này sẽ căn chỉnh ngôn ngữ, hình ảnh, 3D và các quy luật vật lý, hỗ trợ toàn bộ quy trình tạo dữ liệu huấn luyện từ mô phỏng.
AI vật lý sẽ xuất hiện dưới dạng ba loại thực thể: công trình (như nhà máy, kho hàng), robot và ô tô tự lái.
Jensen Huang cho rằng, lái xe tự động sẽ trở thành ứng dụng quy mô lớn đầu tiên của AI vật lý. Các hệ thống này cần phải hiểu được thế giới thực, đưa ra quyết định và thực hiện hành động, với yêu cầu rất cao về an toàn, mô phỏng và dữ liệu.
Để ứng phó với điều này, NVIDIA đã công bố Alpha-Mayo, một hệ thống hoàn chỉnh bao gồm mô hình mã nguồn mở, công cụ mô phỏng và tập dữ liệu AI vật lý, nhằm thúc đẩy việc phát triển AI vật lý an toàn và dựa trên suy luận.
Hệ sinh thái sản phẩm của họ cung cấp các mô-đun nền tảng để các nhà sản xuất ô tô toàn cầu, nhà cung cấp, các công ty khởi nghiệp và các nhà nghiên cứu xây dựng hệ thống lái tự động cấp độ L4.

Alpha-Mayo là mô hình đầu tiên thực sự cho phép xe tự lái "suy nghĩ", và mô hình này đã được công khai mã nguồn. Nó phân tích vấn đề thành từng bước, suy luận tất cả các khả năng có thể xảy ra và chọn con đường an toàn nhất.

Loại mô hình suy luận tác vụ-hành động này cho phép hệ thống lái tự động giải quyết các tình huống biên phức tạp mà trước đây chưa từng trải qua, ví dụ như đèn giao thông bị hỏng tại các ngã tư đông đúc.
Alpha-Mayo có 10 tỷ tham số, quy mô đủ lớn để xử lý các nhiệm vụ lái xe tự động, đồng thời đủ nhẹ để có thể chạy trên các trạm làm việc được thiết kế dành cho các nhà nghiên cứu về lái xe tự động.
Nó có thể nhận đầu vào là văn bản, hình ảnh từ camera, trạng thái lịch sử của xe và thông tin định vị, sau đó đưa ra hành trình di chuyển và quá trình suy luận, giúp hành khách hiểu tại sao xe lại thực hiện một hành động cụ thể nào đó.
Trong đoạn phim quảng bá được trình chiếu tại hiện trường, dưới sự điều khiển của Alpha-Mayo, xe tự lái có thể tự động hoàn thành các thao tác như tránh nhường người đi bộ, dự đoán trước xe rẽ trái và thay đổi làn đường để tránh chướng ngại vật mà không cần bất kỳ sự can thiệp nào từ con người.

Jensen Huang cho biết, dòng xe Mercedes-Benz CLA được trang bị Alpha-Mayo đã bắt đầu được sản xuất, và gần đây đã được NCAP đánh giá là chiếc xe an toàn nhất thế giới. Mỗi đoạn mã, mỗi con chip, mỗi hệ thống đều đã được chứng nhận an toàn. Hệ thống này sẽ được triển khai tại thị trường Mỹ, và trong nửa cuối năm nay sẽ giới thiệu các khả năng lái xe mạnh mẽ hơn, bao gồm cả lái xe trên đường cao tốc mà không cần giữ tay lái, cũng như khả năng tự lái từ đầu đến cuối trong môi trường đô thị.

NVIDIA cũng đã công bố một phần tập dữ liệu được sử dụng để huấn luyện Alpha-Mayo, cùng với khung mô phỏng đánh giá mô hình suy luận mã nguồn mở Alpha-Sim. Các nhà phát triển có thể tinh chỉnh Alpha-Mayo bằng dữ liệu riêng của họ, hoặc sử dụng Cosmos để tạo dữ liệu tổng hợp, và sau đó huấn luyện và kiểm tra các ứng dụng lái tự động dựa trên sự kết hợp giữa dữ liệu thực và dữ liệu tổng hợp. Ngoài ra, NVIDIA đã công bố rằng nền tảng NVIDIA DRIVE hiện đã sẵn sàng cho sản xuất.
NVIDIA đã công bố rằng các công ty robot hàng đầu thế giới như Boston Dynamics, Franka Robotics, Surgical Robotics, LG Electronics, NEURA, XRLabs, Zhiyuan Robotics... đều xây dựng dựa trên nền tảng NVIDIA Isaac và GR00T.

Jensen Huang cũng chính thức công bố hợp tác mới nhất với Siemens. Siemens đang tích hợp CUDA-X, mô hình AI và Omniverse của NVIDIA vào bộ công cụ và nền tảng EDA, CAE và kỹ thuật số (digital twin). AI dựa trên vật lý sẽ được ứng dụng rộng rãi trong toàn bộ quy trình, từ thiết kế, mô phỏng đến sản xuất và vận hành.
05. Kết luận: Tay trái ôm lấy mã nguồn mở, tay phải biến hệ thống phần cứng thành không thể thay thế.
Khi trọng tâm của hạ tầng AI đang chuyển dịch từ huấn luyện sang suy luận quy mô lớn, sự cạnh tranh giữa các nền tảng đã chuyển từ năng lực tính toán đơn lẻ sang một dự án hệ thống bao phủ các lĩnh vực chip, khung máy, mạng và phần mềm. Mục tiêu hiện nay là cung cấp lượng suy luận lớn nhất với chi phí sở hữu toàn đời (TCO) thấp nhất. AI đang bước vào giai đoạn "vận hành theo mô hình nhà máy" mới.
NVIDIA rất coi trọng thiết kế cấp hệ thống, Rubin đồng thời cải thiện cả hiệu năng và hiệu quả kinh tế trong cả huấn luyện và suy luận, và có thể hoạt động như một giải pháp thay thế cắm trực tiếp cho Blackwell, cho phép chuyển đổi mượt mà lên Blackwell.
Về định vị nền tảng, NVIDIA vẫn coi việc huấn luyện là rất quan trọng, bởi vì chỉ khi huấn luyện nhanh các mô hình tiên tiến nhất thì nền tảng suy luận mới thực sự được hưởng lợi. Do đó, NVIDIA đã giới thiệu NVFP4 huấn luyện trong GPU Rubin, qua đó nâng cao hơn nữa hiệu năng và giảm tổng chi phí sở hữu (TCO).
Đồng thời, tập đoàn khổng lồ về tính toán AI này cũng tiếp tục tăng cường đáng kể khả năng truyền thông mạng trên cả hai kiến trúc mở rộng dọc và ngang, xem ngữ cảnh là điểm nghẽn quan trọng, và thực hiện thiết kế đồng bộ giữa lưu trữ, mạng và tính toán.
Trong khi NVIDIA đang tích cực mở nguồn mã, hãng đồng thời đang làm cho phần cứng, kết nối và thiết kế hệ thống ngày càng trở nên "không thể thay thế". Chiến lược vòng khép kín này, liên tục mở rộng nhu cầu, khuyến khích tiêu thụ token, thúc đẩy quy mô suy luận và cung cấp cơ sở hạ tầng có hiệu suất giá cả cao, đang giúp NVIDIA xây dựng một rào cản cạnh tranh ngày càng kiên cố hơn.