









Tác giả: Shenchao TechFlow
Một bài báo khoa học của Google tuyên bố "giảm dung lượng bộ nhớ AI xuống 1/6" đã khiến giá trị thị trường của các cổ phiếu chip lưu trữ toàn cầu như Micron và SanDisk giảm hơn 90 tỷ USD vào tuần trước.
Tuy nhiên, chỉ hai ngày sau khi bài báo được công bố, người bị thuật toán của “Algo” “đàn áp” — tiến sĩ sau tiến sĩ Gao Jianyang từ Viện Công nghệ Liên bang Thụy Sĩ Zurich — đã đăng một bức thư công khai dài 10.000 chữ, cáo buộc nhóm Google đã sử dụng script Python chạy trên CPU đơn nhân để kiểm tra đối thủ, trong khi sử dụng GPU A100 để kiểm tra chính mình, và vẫn từ chối sửa chữa dù đã được thông báo về vấn đề này trước khi nộp bài. Lượt đọc trên Zhihu nhanh chóng vượt quá 4 triệu, tài khoản chính thức của Stanford NLP đã chia sẻ lại, khiến cả cộng đồng học thuật và thị trường đều chấn động.
(Tham khảo: một bài báo nghiên cứu đã khiến cổ phiếu lưu trữ giảm mạnh)
Vấn đề cốt lõi của tranh cãi này không phức tạp: một bài báo hội nghị AI được Google chính thức quảng bá quy mô lớn, trực tiếp gây ra đợt bán tháo hoảng loạn trong ngành chip, có hệ thống xuyên tạc một công trình tiên phong đã được công bố trước đó và tạo ra một câu chuyện lợi thế hiệu suất giả tạo thông qua các thí nghiệm không công bằng được cố ý thiết kế không?
TurboQuant đã làm gì: ép "giấy nháp" của AI mỏng đi sáu lần
Khi các mô hình ngôn ngữ lớn tạo câu trả lời, chúng cần viết đồng thời quay lại xem các nội dung đã tính toán trước đó. Những kết quả trung gian này được lưu tạm trong bộ nhớ GPU, được gọi là «KV Cache» trong ngành. Cuộc hội thoại càng dài, «tờ nháp» này càng dày, tiêu tốn nhiều bộ nhớ GPU hơn và chi phí cũng cao hơn.
Thuật toán TurboQuant do nhóm nghiên cứu của Google phát triển, điểm bán hàng chính là nén bản nháp này xuống còn 1/6 kích thước ban đầu, đồng thời tuyên bố không mất độ chính xác và tăng tốc độ suy luận lên tới 8 lần. Bài báo được công bố lần đầu tiên trên nền tảng tiền ấn bản học thuật arXiv vào tháng 4 năm 2025, được hội nghị hàng đầu lĩnh vực AI là ICLR 2026 chấp nhận vào tháng 1 năm 2026, và được Google tái quảng bá thông qua blog chính thức vào ngày 24 tháng 3.
Về mặt kỹ thuật, tư tưởng của TurboQuant có thể được hiểu đơn giản như sau: trước tiên sử dụng một phép biến đổi toán học để “làm sạch” dữ liệu hỗn loạn thành định dạng đồng nhất, sau đó nén từng phần bằng bảng nén tối ưu đã được tính sẵn, cuối cùng sử dụng cơ chế sửa lỗi 1 bit để điều chỉnh các sai lệch tính toán do nén gây ra. Cộng đồng đã tự triển khai và xác minh rằng hiệu quả nén là thực tế, đóng góp toán học về mặt thuật toán là có thật.
Vấn đề không phải là TurboQuant có thể sử dụng được hay không, mà là Google đã làm gì để chứng minh nó “vượt trội hơn đối thủ”.
Thư công khai của Gao Jianyang: Ba cáo buộc, mỗi cáo buộc đều chạm vào điểm then chốt
Vào lúc 22:00 ngày 27 tháng 3, Gao Jianyang đã đăng bài viết dài trên Zhihu và đồng thời nộp bình luận chính thức trên nền tảng đánh giá chính thức của ICLR, OpenReview. Gao Jianyang là tác giả đầu tiên của thuật toán RaBitQ, được công bố vào năm 2024 tại hội nghị hàng đầu lĩnh vực cơ sở dữ liệu SIGMOD, giải quyết cùng một loại vấn đề — nén hiệu quả các vector chiều cao.
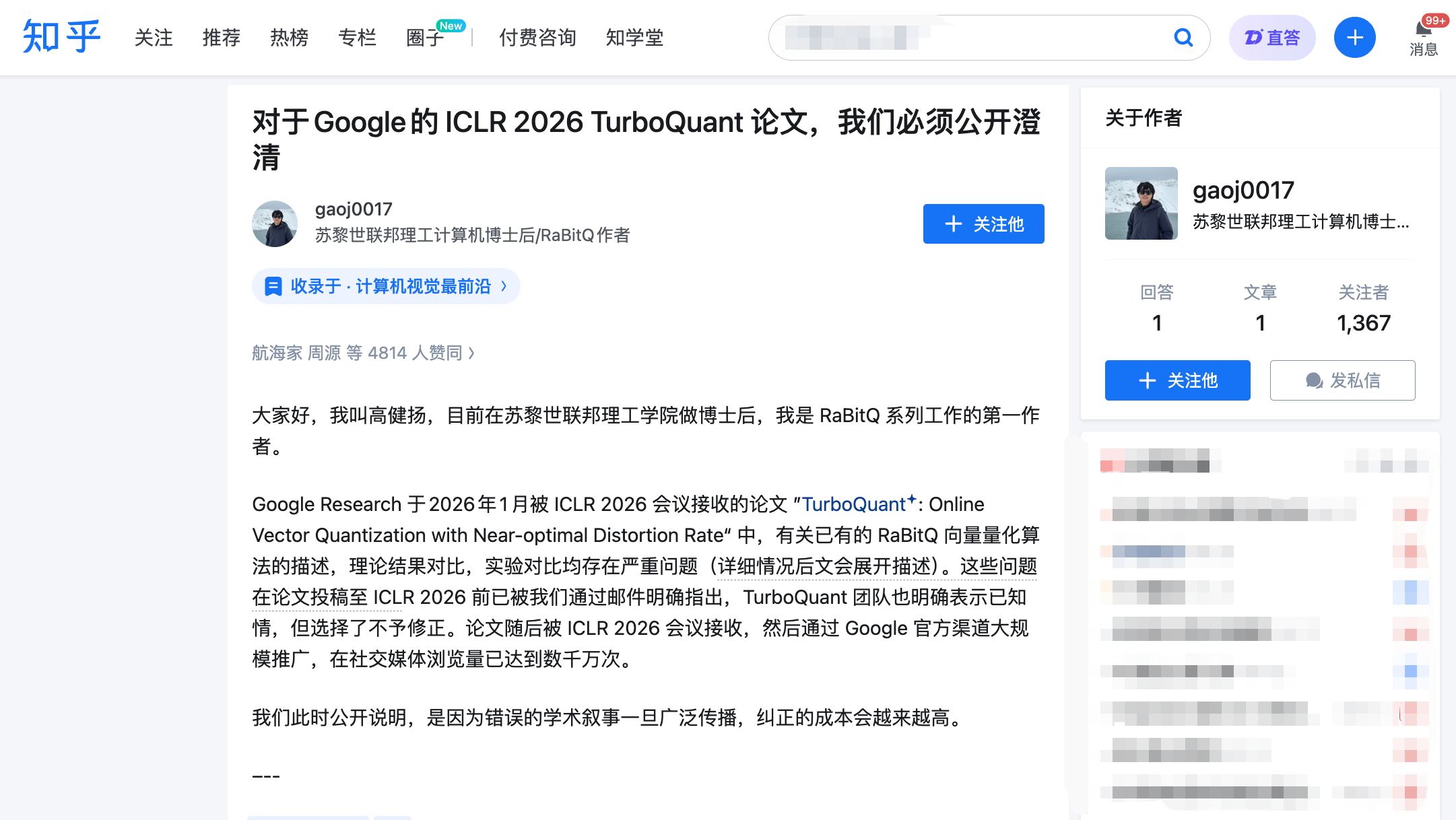
Các cáo buộc của anh ấy gồm ba điểm, mỗi điểm đều có hồ sơ email và mốc thời gian làm bằng chứng.
Một cáo buộc: Sử dụng phương pháp cốt lõi của người khác mà không đề cập đến trong toàn bộ bài viết.
Bước quan trọng chung trong nền tảng kỹ thuật của TurboQuant và RaBitQ là thực hiện một “phép quay ngẫu nhiên” lên dữ liệu trước khi nén. Thao tác này có tác dụng biến đổi dữ liệu có phân bố không đều thành phân bố đều và có thể dự đoán được, từ đó giảm đáng kể độ khó khi nén. Đây là phần cốt lõi và gần giống nhau nhất giữa hai thuật toán.
Chính tác giả của TurboQuant cũng thừa nhận điều này trong phản hồi đánh giá, nhưng lại chưa từng nêu rõ mối liên hệ giữa phương pháp này với RaBitQ trong toàn bộ bài báo. Bối cảnh quan trọng hơn là: Majid Daliri, đồng tác giả thứ hai của TurboQuant, đã chủ động liên hệ với nhóm Gao Jianyang vào tháng 1 năm 2025 để nhờ hỗ trợ gỡ lỗi phiên bản Python được chỉnh sửa từ mã nguồn RaBitQ. Trong email, ông đã mô tả chi tiết các bước tái hiện và thông báo lỗi—nói cách khác, nhóm TurboQuant hiểu rất rõ các chi tiết kỹ thuật của RaBitQ.
Một người đánh giá ẩn danh của ICLR cũng đã độc lập chỉ ra rằng cả hai sử dụng cùng một kỹ thuật và yêu cầu thảo luận đầy đủ. Tuy nhiên, trong phiên bản cuối cùng của bài báo, nhóm TurboQuant không chỉ không bổ sung thảo luận mà còn di chuyển mô tả về RaBitQ (đã không đầy đủ) từ phần chính văn bản sang phụ lục.
Điều buộc tội thứ hai: Đưa ra tuyên bố rằng lý thuyết của đối phương là “tối ưu thứ hai” mà không có bằng chứng.
Bài báo của TurboQuant đã gắn nhãn RaBitQ là “tối ưu về mặt lý thuyết” (suboptimal) với lý do rằng phân tích toán học của RaBitQ “khá thô sơ”. Tuy nhiên, Gao Jianyang chỉ ra rằng bài báo mở rộng của RaBitQ đã chứng minh chặt chẽ rằng lỗi nén của nó đạt đến giới hạn tối ưu về mặt toán học—kết luận này đã được công bố tại hội nghị hàng đầu về khoa học máy tính lý thuyết.
Tháng 5 năm 2025, nhóm Gao Jianyang đã giải thích chi tiết về tính tối ưu của lý thuyết RaBitQ qua nhiều email. Daliri, đồng tác giả thứ hai của TurboQuant, xác nhận đã thông báo cho tất cả các tác giả. Tuy nhiên, bài báo cuối cùng vẫn giữ nguyên cách diễn đạt “tối ưu thứ cấp” mà không đưa ra bất kỳ lập luận phản bác nào.
Chỉ trích thứ ba: Trong so sánh thí nghiệm, “tay trái buộc người, tay phải cầm dao”.
Đây là điểm mạnh nhất trong toàn văn. Gao Jianyang chỉ ra rằng bài luận của TurboQuant đã thêm hai điều kiện không công bằng vào thí nghiệm so sánh tốc độ:
Đầu tiên, RaBitQ chính thức cung cấp mã C++ đã được tối ưu (hỗ trợ song song đa luồng theo mặc định), nhưng đội ngũ TurboQuant đã không sử dụng mà thay vào đó dùng phiên bản Python do họ tự dịch để kiểm tra RaBitQ. Thứ hai, khi kiểm tra RaBitQ, họ sử dụng CPU đơn nhân và tắt đa luồng, trong khi TurboQuant sử dụng GPU NVIDIA A100.
Hiệu ứng kết hợp của hai điều kiện này là: người đọc kết luận rằng “RaBitQ chậm hơn TurboQuant vài bậc độ lớn”, nhưng lại không biết được tiền đề của kết luận này là nhóm Google đã trói tay chân đối thủ trước khi thi đấu. Bài báo không tiết lộ đầy đủ những khác biệt trong các điều kiện thí nghiệm.
Phản hồi của Google: “Xoay ngẫu nhiên là công nghệ phổ biến, không thể trích dẫn từng bài viết”
The TurboQuant team stated in their email reply in March 2026, according to Gao Jianyang: "The use of random rotation and Johnson-Lindenstrauss transform is already standard practice in this field, and we cannot cite every paper that employs these methods."
Đội ngũ Gao Jianyang cho rằng đây là việc đánh tráo khái niệm: vấn đề không phải là có nên trích dẫn tất cả các bài báo đã sử dụng phép quay ngẫu nhiên hay không, mà là RaBitQ là công trình đầu tiên kết hợp phương pháp này với nén vector và chứng minh tính tối ưu của nó trong cùng một thiết lập vấn đề, do đó bài báo TurboQuant nên mô tả chính xác mối quan hệ giữa hai phương pháp này.
Nhóm Stanford NLP đã chuyển tiếp tuyên bố của Gao Jianyang. Đội ngũ Gao Jianyang đã đăng bình luận công khai trên nền tảng ICLR OpenReview và nộp đơn khiếu nại chính thức đến chủ tịch và ủy ban đạo đức của hội nghị ICLR, đồng thời sẽ công bố báo cáo kỹ thuật chi tiết trên arXiv trong thời gian tới.
Chuyên gia công nghệ độc lập Dario Salvati đưa ra đánh giá tương đối trung lập trong phân tích: TurboQuant thực sự có đóng góp về mặt toán học, nhưng mối quan hệ với RaBitQ chặt chẽ hơn nhiều so với những gì được nêu trong bài báo.
90 tỷ USD giá trị thị trường bốc hơi: Tranh cãi về bài báo cộng với sự hoảng loạn trên thị trường
Thời điểm xảy ra tranh luận học thuật này cực kỳ tinh tế. Sau khi Google công bố TurboQuant trên blog chính thức vào ngày 24 tháng 3, ngành chip lưu trữ toàn cầu đã chịu đợt bán tháo mạnh mẽ. Theo nhiều báo cáo từ CNBC và các phương tiện truyền thông khác, Micron đã giảm giá liên tục trong sáu phiên giao dịch, tổng mức giảm vượt quá 20%; SanDisk giảm 11% trong một ngày; SK Hynix của Hàn Quốc giảm khoảng 6%, Samsung Electronics giảm gần 5%, và Kioxia của Nhật Bản giảm khoảng 6%. Lý do hoảng loạn trên thị trường rất đơn giản và thô sơ: phần mềm nén có thể giảm nhu cầu bộ nhớ cho suy luận AI xuống 6 lần, khiến triển vọng nhu cầu đối với chip lưu trữ bị điều chỉnh giảm mang tính cấu trúc.
Phân tích viên của Morgan Stanley, Joseph Moore, trong báo cáo ngày 26 tháng 3 đã phản bác lập luận này và duy trì xếp hạng « Mua » cho Micron và SanDisk. Moore chỉ ra rằng TurboQuant chỉ nén loại bộ nhớ đệm cụ thể là KV Cache, chứ không phải tổng lượng sử dụng bộ nhớ, và ông coi đây là « sự cải tiến năng suất bình thường ». Phân tích viên của Wells Fargo, Andrew Rocha, cũng viện dẫn nghịch lý Jevons cho rằng, việc nâng cao hiệu quả làm giảm chi phí lại có thể kích thích việc triển khai AI quy mô lớn hơn, cuối cùng làm tăng nhu cầu bộ nhớ.
Bài viết cũ, bao bì mới: Rủi ro truyền dẫn từ nghiên cứu AI đến câu chuyện thị trường
Theo phân tích của chuyên gia công nghệ Ben Pouladian, bài báo TurboQuant đã được công bố công khai từ tháng 4 năm 2025 và không phải là nghiên cứu mới. Vào ngày 24 tháng 3, Google đã tái đóng gói và quảng bá thông qua blog chính thức, trong khi thị trường lại định giá nó như một bước đột phá hoàn toàn mới. Chiến lược quảng bá “bài báo cũ, công bố mới” này, kết hợp với khả năng tồn tại sai lệch thực nghiệm trong bài báo, phản ánh rủi ro hệ thống trong chuỗi truyền tải từ luận án học thuật sang câu chuyện thị trường trong lĩnh vực AI.
Đối với các nhà đầu tư vào cơ sở hạ tầng AI, khi một bài báo tuyên bố đạt được sự cải thiện hiệu suất "vài cấp độ", điều đầu tiên cần đặt câu hỏi là điều kiện so sánh cơ sở có công bằng hay không.
Đội ngũ Gao Jianyang đã rõ ràng tuyên bố sẽ tiếp tục thúc đẩy việc giải quyết vấn đề một cách chính thức. Google chưa đưa ra phản hồi chính thức nào đối với các cáo buộc cụ thể trong thư công khai.