









Sự điều chỉnh giá của DeepSeek đã buộc ngành công nghiệp bước vào một kỷ nguyên chi phí hoàn toàn mới thông qua một cú giảm mạnh phi tuyến tính.
Tác giả bài viết, nguồn: 0x9999in1, ME News
Tóm tắt ngắn
- Giá giảm xuống mức đáy: Đến cuối tháng 4 năm 2026, DeepSeek đã giảm giá đầu ra của mô hình V4-Pro xuống còn 0,878 USD/million token thông qua việc kết hợp chiết khấu thời hạn và giảm giá bộ nhớ đệm, đồng thời giá đầu vào khi命中 bộ nhớ đệm còn thấp hơn nữa ở mức 0,0037 USD (tương đương khoảng 0,025 nhân dân tệ), hoàn toàn phá vỡ điểm tham chiếu định giá trong ngành mô hình lớn.
- Giá cả tại Trung Quốc và Mỹ xuất hiện “khoảng cách”: So với các nhà sản xuất hàng đầu toàn cầu, chi phí tổng hợp để gọi API của DeepSeek-V4-Pro chỉ bằng khoảng một phần ba mươi so với OpenAI GPT-5.5 và Anthropic Claude Opus 4.7, tạo ra sự chênh lệch lợi thế chi phí cực kỳ rõ rệt.
- Áp lực từ cục diện cạnh tranh trong nước: Dưới định giá đầy tham vọng của DeepSeek, các mô hình chủ lực trong nước như Zhipu GLM 5.1, Moonshot Kimi K2.6 đang đối mặt với áp lực thương mại lớn, có thể buộc phải theo dõi giảm giá, tốc độ thanh lọc ngành sẽ tăng đáng kể.
- “Bộ nhớ đệm trúng” trở thành nền tảng kinh tế học: DeepSeek đã giảm giá bộ nhớ đệm trúng xuống chỉ bằng 1/10 giá ban đầu, chiến lược này mang lại lợi ích lớn cho các kịch bản xử lý văn bản dài, RAG (tăng cường truy vấn) và tương tác đa vòng liên tục của Agent.
- Kết luận phân tích của viện nghiên cứu: Các mô hình nền tảng lớn đang tăng tốc quá trình “hóa thành cơ sở hạ tầng như điện, nước”, trọng tâm cạnh tranh trong tương lai sẽ chuyển hoàn toàn từ cuộc đua quy mô tham số mô hình đơn lẻ sang khả năng tối ưu chi phí suy luận và thị phần hệ sinh thái nhà phát triển.
Giới thiệu: Thời điểm kỳ dị của chi phí tính toán cho các mô hình lớn
Sự phát triển của công nghệ thường đi kèm với sự giảm giá theo cấp số nhân, đây là con đường tất yếu để bất kỳ công nghệ đột phá nào đạt đến sự phổ biến toàn diện. Từ ngày 25 đến 26 tháng 4 năm 2026, ngành AI đã chứng kiến một khoảnh khắc mang tính biểu tượng: các nhà sản xuất mô hình lớn hàng đầu DeepSeek liên tiếp tung ra hai “quả bom sâu”. Đầu tiên là thông báo mở ưu đãi khẩn cấp chỉ còn 2,5% cho API của mô hình DeepSeek-V4-Pro; ngay sau đó tuyên bố giá cho các dịch vụ API trong toàn bộ dòng sản phẩm, khi có lệnh cache đầu vào, sẽ giảm trực tiếp xuống chỉ bằng 1/10 giá ban đầu.
Sau hai đợt điều chỉnh giá tích lũy này, giá đầu vào bộ nhớ đệm cho DeepSeek-V4-Flash đã giảm xuống mức đáng kinh ngạc là 0,0029 USD mỗi triệu Tokens trước ngày 5 tháng 5 năm 2026, trong khi giá đầu vào bộ nhớ đệm của DeepSeek-V4-Pro, đối chiếu với mức cao nhất toàn cầu, chỉ là 0,0037 USD (tương đương khoảng 0,025 nhân dân tệ).
Trước đây, ngành công nghiệp thường dự đoán chi phí suy luận của các mô hình lớn sẽ giảm khoảng 50% mỗi năm, nhưng đợt điều chỉnh giá lần này của DeepSeek đã gây ra một sự sụt giảm đột ngột theo chiều phi tuyến, buộc ngành phải bước vào một kỷ nguyên chi phí hoàn toàn mới. Chúng tôi cho rằng, đây không phải là một hoạt động tiếp thị đơn giản hay một “cuộc chiến giá” ngắn hạn, mà là kết quả tất yếu đến từ việc tối ưu hóa kiến trúc thuật toán nền tảng (như cơ chế chú ý thưa thớt, sự phát triển cực hạn của kiến trúc MoE) cùng với sự nâng cao năng lực kỹ thuật của cụm máy tính. Báo cáo này sẽ dựa trên dữ liệu giá mới nhất toàn ngành, phân tích sâu sắc những tác động do việc giảm giá của DeepSeek gây ra, đồng thời so sánh ngang hàng khả năng cạnh tranh thương mại của các mô hình lớn hàng đầu toàn cầu, nhằm cung cấp cho các nhà hoạch định chính sách một bản đồ phát triển ngành rõ ràng.
Hiện tượng cốt lõi: Sự phá vỡ giới hạn của hệ thống giá chuỗi DeepSeek-V4
Để hiểu được mức độ ấn tượng của đợt giảm giá này, chúng ta phải phân tích sâu ba chiều cạnh cốt lõi trong việc tính phí API mô hình lớn: giá đầu vào (không trùng lặp bộ nhớ đệm), giá đầu vào (trùng lặp bộ nhớ đệm) và giá đầu ra. Mô hình tính phí trước đây thường chỉ phân biệt giữa đầu vào và đầu ra, nhưng với sự trưởng thành của công nghệ ngữ cảnh dài (Long-Context), “tỷ lệ trùng lặp bộ nhớ đệm (Cache Hit)” đang trở thành biến số then chốt tái định hình kinh tế học API.
Phân tích chiến lược định giá: Gộp chiết khấu và đòn bẩy lưu trữ
The latest data shows that DeepSeek has adopted a triple-pronged strategy of "baseline price reduction + limited-time discount + cached leverage".
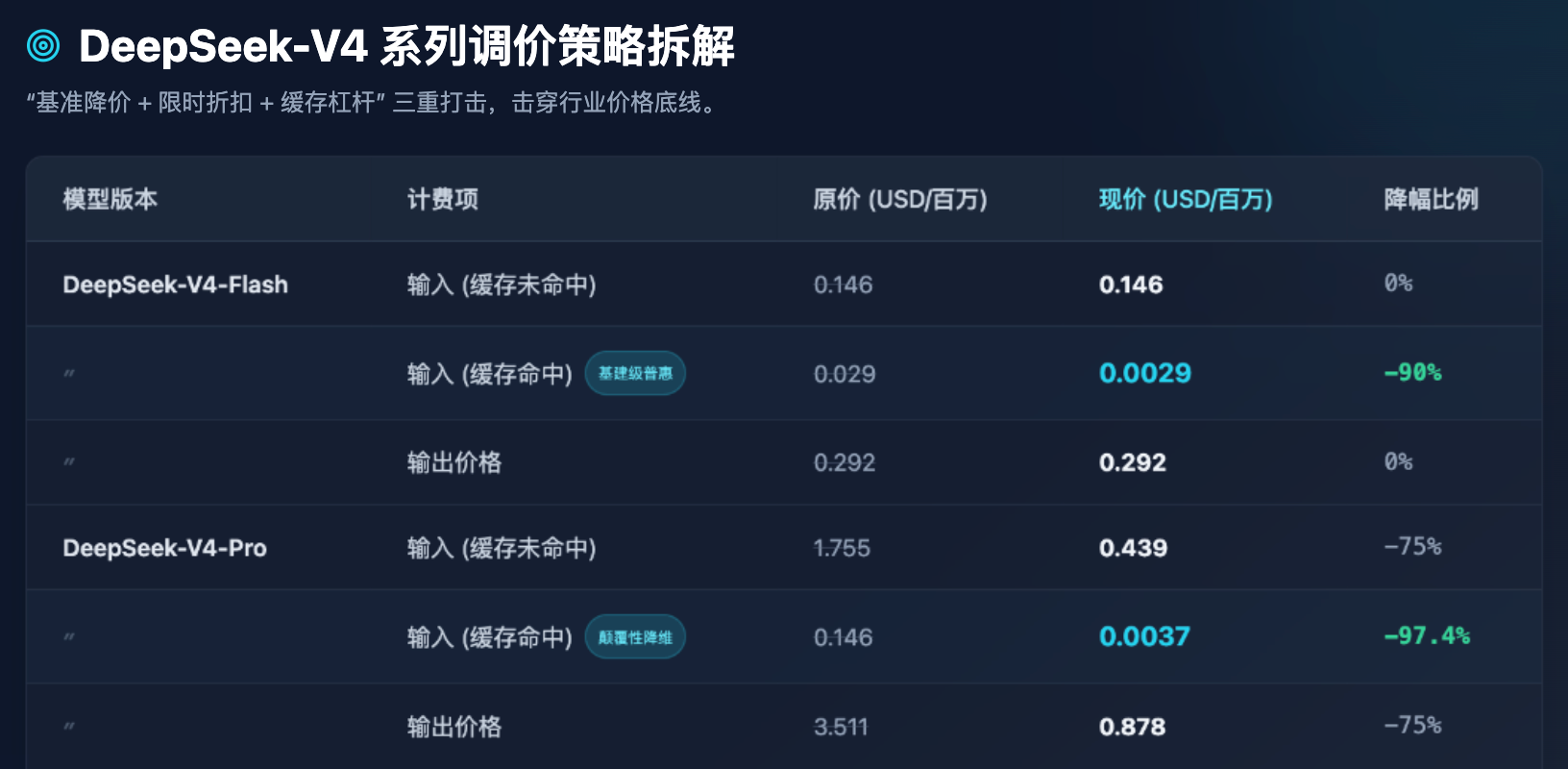
Bảng 1: So sánh giá API mới nhất của chuỗi DeepSeek-V4 trước và sau khi điều chỉnh (đơn vị: đô la / triệu Token)
Từ Bảng 1, chúng ta có thể rút ra một vài quan sát ngành cực kỳ rõ ràng:
Đầu tiên, sự phổ cập của mô hình Flash đã chạm đáy. Đối với các mô hình Flash tập trung vào khả năng xử lý đồng thời cao và độ trễ thấp, giá đầu ra được duy trì ở mức 0,292 USD/million Token, đã cực kỳ sát với ngưỡng chi phí phần cứng về năng lực tính toán của máy chủ. DeepSeek không tiếp tục điều chỉnh giá cơ sở của Flash, mà khéo léo giảm 90% giá “tỷ lệ hit bộ nhớ đệm”. Điều này có nghĩa là, khi xử lý lượng lớn các hệ thống nhắc nhở (System Prompt) lặp lại hoặc câu hỏi-đáp tài liệu cố định, chi phí của mô hình Flash gần như có thể bỏ qua.
Thứ hai, sự giảm giá đột phá của mô hình Pro. Với tư cách là mô hình flagship cạnh tranh trực tiếp với nhóm hàng đầu toàn cầu (như cấp độ GPT-5), giá đầu ra của V4-Pro đã giảm mạnh từ 3,511 USD xuống còn 0,878 USD. Đáng kinh ngạc hơn, giá đầu vào khi có cache hit vốn là 0,146 USD, sau khi áp dụng thêm chương trình giảm 2,5折 và giảm 1/10, đã lập tức xuống còn 0,0037 USD. Đây là một con số cực kỳ đáng sợ — điều này có nghĩa là chi phí để truy cập trí tuệ hàng đầu toàn cầu đã được nén xuống mức mà ngay cả các doanh nghiệp vừa và nhỏ hay nhà phát triển cá nhân cũng có thể thoải mái gọi liên tục với tần suất cao.
Thứ ba, ép buộc các nhà phát triển tối ưu hóa kỹ thuật Prompt. Đặt giá khi cache hit ở mức bằng một phần vài chục so với giá khi cache miss (ví dụ trong mô hình Pro: 0,0037 đô la so với 0,439 đô la, chênh lệch khoảng 118 lần), đây không chỉ là chiến lược định giá mà còn là cách dùng công cụ thương mại để định hướng hệ sinh thái công nghệ. DeepSeek đang rõ ràng thông báo với các nhà phát triển: chỉ cần kiến trúc của các bạn được thiết kế hợp lý (ví dụ: đặt ngữ cảnh dài cố định ở trước, câu hỏi ngắn thay đổi ở sau), các bạn sẽ được hưởng nguồn lực tính toán đầu vào gần như miễn phí.
So sánh ngang: Sự khác biệt rõ rệt về giá cả giữa các mô hình lớn toàn cầu và địa phương
Chỉ so sánh chiều dọc mức giảm giá của chính DeepSeek là chưa đủ để thấy toàn cảnh; khi đặt nó vào hệ tọa độ thị trường mô hình lớn toàn cầu năm 2026, sự tương phản “đứt gãy” do chiến lược định giá này tạo ra mới thực sự khiến người ta rùng mình.
Dựa trên OpenRouter và các thông tin công khai từ các bên, chúng tôi đã tổng hợp dữ liệu định giá API mới nhất của 9 mô hình lớn trong và ngoài nước đại diện nhất trên thị trường hiện nay.

Bảng 2: So sánh giá API các mô hình lớn phổ biến toàn cầu năm 2026 (đơn vị: USD/ triệu Token)
Đối đầu với các gã khổng lồ toàn cầu: Phá vỡ huyền thoại “trí tuệ cao, giá cao”
Trong hai năm qua, OpenAI và Anthropic đã duy trì một sự đồng thuận ngầm: các mô hình thông minh nhất nên享有 mức lợi nhuận gộp cao nhất. Hiện tại, giá đầu ra của GPT-5.5 và Claude Opus 4.7 lần lượt lên tới 30 USD và 25 USD/million token. Hai gã khổng lồ Thung lũng Silicon này đang cố gắng duy trì khoản thuế tính toán cao của mình bằng cách độc quyền khả năng suy luận hàng đầu.
Tuy nhiên, sự xuất hiện của DeepSeek-V4-Pro cùng mức giá đầu ra 0,878 USD đã trực tiếp phá vỡ lớp giấy cửa sổ này. Giả sử V4-Pro có thể đạt hoặc gần ngang mức GPT-5.5 trong các bài kiểm tra hiệu năng cốt lõi (Benchmarks) và trải nghiệm thực tế, thì sự chênh lệch giá đầu ra lên tới 34 lần giữa hai sản phẩm này sẽ hoàn toàn phá vỡ logic định giá cao của các đế chế nước ngoài trên thị trường B2B.
The "ME News Think Tank" estimates that for an overseas-focused enterprise heavily reliant on AI-generated content, if it consumes 1 billion tokens per month, the hard cost of using GPT-5.5 would be $30,000; whereas switching to DeepSeek-V4-Pro would reduce this cost sharply to $878. Such a massive cost difference could determine the survival or failure of a startup. This indicates that Chinese AI companies have embarked on a distinct path—emphasizing both "brute-force aesthetics and extreme engineering"—in terms of underlying model training efficiency and inference cluster optimization, diverging entirely from Silicon Valley's approach.
Đánh bật các đối thủ trong nước: Tăng tốc quá trình sàng lọc ngành
Nếu DeepSeek mang lại sự áp đảo vượt trội đối với các ông lớn nước ngoài, thì đối với các đối thủ trong nước, đây lại là một cuộc cạnh tranh zero-sum đầy khắc nghiệt.
Từ Bảng 2 có thể thấy, các nhà sản xuất hàng đầu trong nước như Zhipu (GLM 5.1, đầu ra 4,4 đô la) và Moonshot (Kimi K2.6, đầu ra 4 đô la) đang ở vào vị thế khó xử về giá cả. Những mức giá này vài tháng trước còn được coi là “hợp lý và có tính cạnh tranh về giá”, nhưng trước DeepSeek-V4-Pro (đầu ra 0,878 đô la), chúng lập tức mất hết mọi hàng phòng thủ về giá. Ngay cả Alibaba Cloud, vốn luôn nổi tiếng với mô hình mã nguồn mở và giá thấp (Qwen3.6 Plus, đầu ra 1,96 đô la), cũng không còn显得 “rẻ” nữa.
Trong lĩnh vực mô hình Flash nhẹ, cuộc chiến cũng đang diễn ra vô cùng căng thẳng. Step 3.5 Flash của Jiep Xingchen có chi phí đầu vào chỉ từ 0,028 USD và đầu ra chỉ 0,299 USD, cạnh tranh khốc liệt với DeepSeek-V4-Flash (đầu ra 0,292 USD). Điều này cho thấy trong lĩnh vực mô hình nhẹ, việc ép giảm chi phí tính toán đã đạt đến cấp độ nanomet, và mọi bên đều đang bay sát đường chi phí.
Nhìn chung, DeepSeek thực chất đang dùng năng lực cấp Pro để cạnh tranh với mức giá của các đối thủ trong nước ở cấp Plus hoặc phiên bản tiêu chuẩn; đồng thời dùng mức giá cấp Flash để tiếp nhận toàn bộ lượng lưu lượng dài cuối với mật độ giá trị thấp. Chiến thuật “kẹp hai đầu” này đã thu hẹp đáng kể không gian sinh tồn của các công ty mô hình lớn khác, và cuộc loại trừ trong lĩnh vực mô hình AI lớn tại Trung Quốc sẽ được tăng tốc sau đợt giảm giá này.
Chi tiết sâu: Công nghệ và logic kinh doanh đằng sau mức giá cực thấp
Giá thấp mà không dựa trên nền tảng cơ bản sẽ không bền vững. DeepSeek dám đưa ra chiến lược giảm giá quyết liệt như vậy vào năm 2026 nhờ vào sự hỗ trợ kỹ thuật vững chắc và những tham vọng thương mại lớn lao.
Logic kỹ thuật: Từ “lực lớn gạch bay” đến “kiến trúc chiến thắng”
Sự sụt giảm mạnh về giá về bản chất là sự giải phóng lợi ích từ sự phát triển của kiến trúc kỹ thuật.
- Lợi ích sâu sắc của kiến trúc MoE (Mixture of Experts): Khác với các mô hình dày đặc quy mô lớn sớm của OpenAI, các mô hình tiên tiến hiện nay đều sử dụng kiến trúc MoE được tối ưu hóa cao. DeepSeek rất có khả năng đã giảm thêm tỷ lệ tham số kích hoạt trong kiến trúc V4. Điều này có nghĩa là ngay cả khi tổng số tham số lớn, nhưng trong mỗi lần suy luận, chỉ một phần rất nhỏ các “chuyên gia” được kích hoạt, từ đó giảm đáng kể lượng tính toán (FLOPs) và áp lực băng thông bộ nhớ GPU cho mỗi lần gọi.
- Bước đột phá mang tính cách mạng trong quản lý KV Cache: Điểm nổi bật nhất của đợt điều chỉnh này là “tỷ lệ hit bộ nhớ đệm đầu vào giảm xuống 1/10”. Trong kiến trúc Transformer, rào cản lớn nhất khi suy luận văn bản dài không phải là tính toán, mà là bộ nhớ KV Cache lưu trữ thông tin ngữ cảnh chiếm dụng lượng lớn bộ nhớ GPU. DeepSeek rõ ràng đã triển khai ở cấp độ hệ thống công nghệ gộp KV Cache chia sẻ toàn cầu giữa các yêu cầu (ví dụ: phiên bản nâng cấp của kỹ thuật RadixAttention). Khi vô số yêu cầu đồng thời của người dùng chứa cùng một thiết lập hệ thống hoặc cơ sở tri thức nền, mô hình không còn cần tính toán lại các Token này, mà có thể trực tiếp truy xuất từ bộ nhớ hoặc từ hồ sơ bộ nhớ GPU phân tán. Điều này khiến chi phí biên của “đầu vào văn bản dài” tiến gần đến mức bằng không.
Business logic: Trade profit for space, rebuild the ecological moat
「ME News Trí tuệ」 cho rằng, chiến lược giảm giá có thời hạn và giá đáy của DeepSeek có mục đích kinh doanh rõ ràng và quyết liệt:
Đầu tiên, phá hủy hoàn toàn hệ sinh thái “fine-tuning bao bì”, buộc các ứng dụng bản địa AI bùng nổ. Khi chi phí gọi đến các mô hình nền tảng mạnh nhất tiến gần đến miễn phí, các doanh nhân sẽ không còn ý nghĩa kinh tế khi bỏ ra một khoản chi khổng lồ để huấn luyện hoặc tinh chỉnh các mô hình nhỏ ngành của riêng mình. DeepSeek thông qua giá thấp, cố gắng thu hút tất cả các nhà phát triển AI trên toàn xã hội vào hệ sinh thái API của mình, biến nó thành “nền tảng điện-nước-gas” thời đại AI giống như Amazon AWS hay Microsoft Azure.
Thứ hai, bình minh của sự bùng nổ Agent (đối tượng thông minh). Các ứng dụng Agentic thực sự yêu cầu mô hình thực hiện một lượng lớn suy nghĩ tự thân, phản tư, lập kế hoạch và gọi lặp lại nhiều vòng (Loop). Trong quá trình này, sẽ phát sinh lượng lớn Token ẩn bị tiêu hao. Chi phí API đắt đỏ là trở ngại lớn nhất đối với sự phổ biến của Agent. DeepSeek đã giảm giá trị khớp bộ nhớ đệm xuống còn 0,0037 đô la Mỹ, thực chất là tạo ra tính khả thi về mặt kinh tế cho việc “để AI tự chạy một vạn vòng”. Ai cung cấp chi phí thử nghiệm rẻ nhất, người đó sẽ nuôi dưỡng ra những siêu ứng dụng nguyên sinh AI vĩ đại nhất.
Ảnh hưởng ngành và dự báo xu hướng: Từ “cuộc chiến mô hình” sang “cuộc chiến hệ sinh thái”
Để thể hiện trực quan hơn ảnh hưởng của biến động giá này đến quyết định kinh doanh, chúng tôi đã thực hiện một mô phỏng chi phí ứng dụng doanh nghiệp.
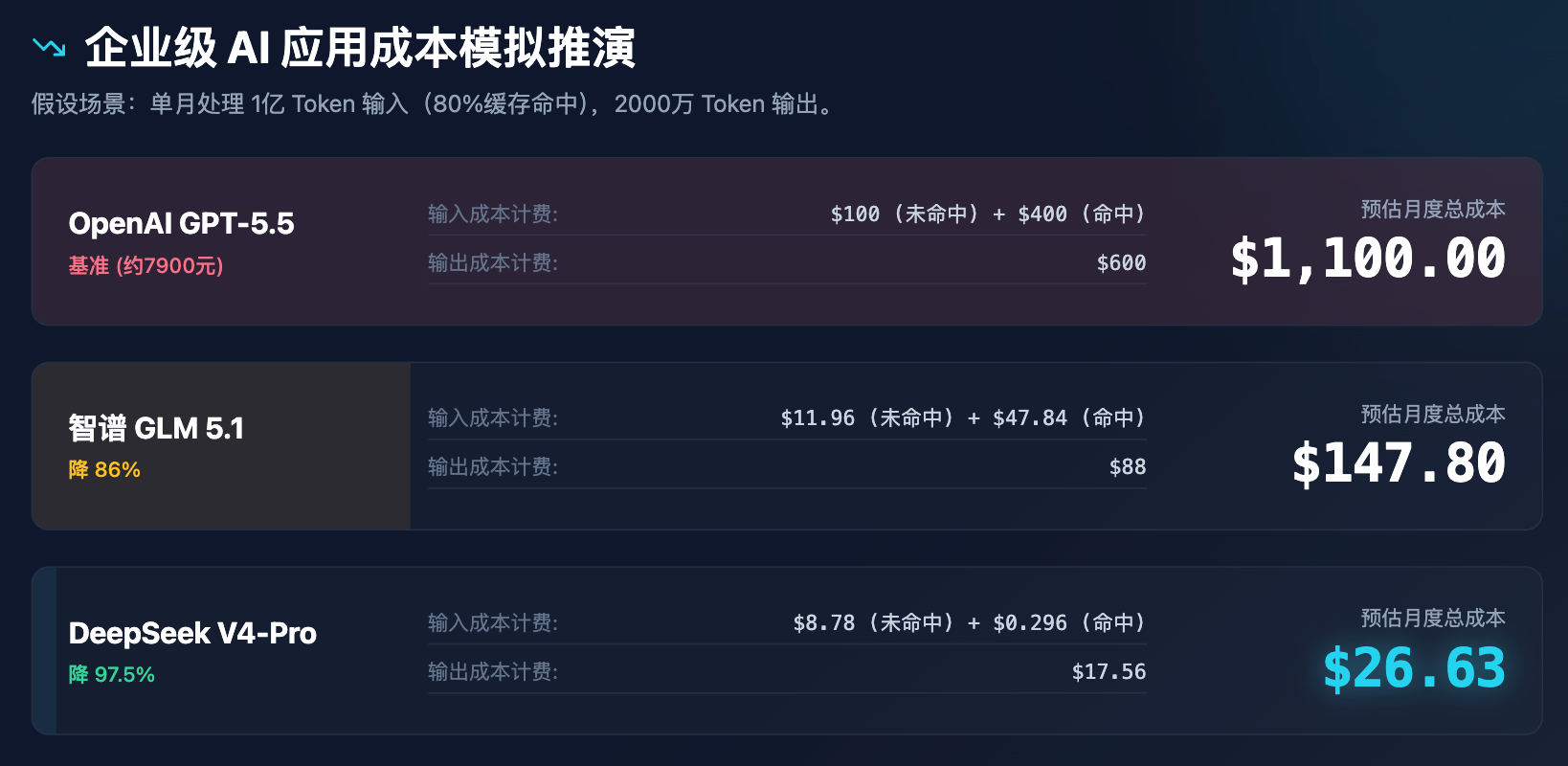
Bảng 3: Phân tích mô phỏng chi phí ứng dụng AI doanh nghiệp (giả định xử lý 100 triệu token đầu vào và 20 triệu token đầu ra mỗi tháng)
Qua mô phỏng trên, có thể thấy rõ rằng định giá của DeepSeek không chỉ là giảm giá, mà còn đang tái cấu trúc mô hình chi phí. Với chi phí dưới 30 USD mỗi tháng, có thể đáp ứng toàn bộ nhu cầu về hỗ trợ dịch vụ khách hàng, phân tích tài liệu và kiểm tra mã cho một doanh nghiệp vừa, điều này chắc chắn sẽ gây ra một chuỗi phản ứng dây chuyền:
- Sự chuyển đổi căn bản trong logic đầu tư AI: Vốn sẽ hoàn toàn mất hứng thú với việc “tái tạo một mô hình lớn tổng quát”. Ngoại trừ một số rất ít tổ chức nhà nước hoặc khổng lồ internet, cánh cửa dành cho các mô hình nền tảng tổng quát đã được hàn kín. Đầu tư trong tương lai sẽ tràn ngập toàn diện vào lớp ứng dụng (Application Layer) và các middleware cơ sở hạ tầng (bộ định tuyến cơ sở hạ tầng, cổng AI, v.v.).
- Chiến lược định tuyến đa mô hình (LLM Routing) trở thành tiêu chuẩn: Doanh nghiệp sẽ không còn bó buộc vào một mô hình duy nhất. Hệ thống sẽ tự động phân phối dựa trên độ phức tạp của nhiệm vụ. Ví dụ: 90% các tác vụ làm sạch dữ liệu hàng ngày và phân loại đơn giản sẽ được thực hiện bởi DeepSeek-V4-Flash hoặc Step 3.5 Flash với chi phí cực thấp; 10% các tác vụ suy luận logic phức tạp và tạo báo cáo cho ban lãnh đạo sẽ sử dụng DeepSeek-V4-Pro hoặc gọi GPT-5.5 theo nhu cầu.
- Ứng dụng văn bản dài đang bước vào điểm ngoặt thương mại thực sự: Trước đây, việc “tải lên báo cáo tài chính hàng triệu chữ để AI tóm tắt” nghe thì tuyệt vời, nhưng chi phí API mỗi lần lên tới vài đô la đã khiến các doanh nghiệp B2B e ngại. Khi giá đạt mức 0,02 nhân dân tệ/1 triệu Token cho việc truy xuất bộ nhớ đệm đầu vào, chức năng “đọc toàn bộ tài liệu kho và tương tác thời gian thực” sẽ trở thành tính năng tiêu chuẩn trong mọi phần mềm OA và ERP của doanh nghiệp.
Kết luận và đề xuất chiến lược
Cuộc giảm giá vào tháng 4 năm 2026 đánh dấu sự kết thúc chính thức của thời kỳ cổ điển đầy lãng mạn trong ngành mô hình lớn, khi các công ty chỉ đua nhau so sánh tham số và điểm số, và bước vào thời kỳ công nghiệp hóa khắc nghiệt, nơi cạnh tranh dựa trên chi phí, giành giật năng lực tính toán và chiếm lĩnh hệ sinh thái. DeepSeek thông qua chiến lược định giá gây áp lực cực độ không chỉ cho thế giới thấy được trình độ chuyên sâu của các doanh nghiệp AI Trung Quốc trong lĩnh vực kỹ thuật mô hình, mà còn chủ động phá vỡ bong bóng định giá cao quá mức của năng lực tính toán AI.
Đối với điều này, "ME News Trí tuệ" có ba đề xuất:
- Đối với các nhà phát triển ứng dụng: Hãy từ bỏ nỗi sợ về chi phí gọi mô hình lớn. Ngay lập tức ngừng tự xây dựng và tinh chỉnh các mô hình nền tảng dưới 10 tỷ tham số, và chuyển toàn bộ nguồn lực phát triển vào trải nghiệm sản phẩm, tối ưu hóa trên thiết bị đầu cuối, xây dựng rào cản dữ liệu chuyên biệt và hoàn thiện luồng làm việc của Agent. Tận dụng lợi ích từ “siêu năng lực tính toán giá rẻ” trong đợt này để nhanh chóng chiếm lĩnh các kịch bản.
- Đối với CIO/CTO của doanh nghiệp truyền thống: Đánh giá lại chiến lược AI hóa doanh nghiệp. Các dự án trước đây bị hoãn lại do cân nhắc chi phí, như hỏi đáp cơ sở tri thức, dịch vụ khách hàng tự động hóa và code Copilot, hiện nay đã có ROI (tỷ suất hoàn vốn đầu tư) cực kỳ cao dưới mức giá API hiện tại. Đề xuất triển khai các nền tảng LLMOps成熟, xây dựng cổng AI doanh nghiệp để linh hoạt kết nối với các mô hình có tính hiệu quả chi phí cao nhất hiện nay.
- Đối với các đối thủ sử dụng mô hình cơ bản: phải từ bỏ chiến lược đi theo. Trước cuộc chiến giá cả, либо tối ưu hóa đồng bộ chip - khung nền một cách cực đoan hơn để giảm chi phí, либо xây dựng rào cản công nghệ không thể thay thế trong các lĩnh vực khác biệt như trí tuệ thể chất, đa mô态 nguyên sinh (tạo video/3D), suy luận logic mạnh mẽ trong các ngành dọc. Mô hình ngôn ngữ lớn thuần túy đang trở nên bình thường hóa và đã không còn lối thoát.
Các mô hình lớn không còn là những vị thần được tôn thờ trong phòng thí nghiệm; chúng đang nhanh chóng hạ cánh khỏi ngai vàng, trở thành làn sóng khổng lồ thúc đẩy trí tuệ cho mọi thứ. Và tất cả những điều này mới chỉ vừa bắt đầu.
Nguồn trích dẫn:
- OpenRouter. (2026). Cơ sở dữ liệu so sánh giá API.
- Thông báo chính thức từ DeepSeek. (2026, ngày 25 tháng 4)Chương trình ưu đãi giới hạn thời gian cho API DeepSeek-V4-Pro.
- Thông báo chính thức từ DeepSeek. (2026, ngày 26 tháng 4)Truy cập công suất phổ cập thời đại mô hình lớn: Phương án điều chỉnh giá khi đạt tỷ lệ đệm toàn cầu API.