










Tác giả gốc: KarenZ, Foresight News
Ngày 20 tháng 3 năm 2026, trong một tập podcast của All-In Ventures có một cuộc hội thoại không bình thường.
Chamath Palihapitiya, nhà đầu tư mạo hiểm nổi tiếng, đã chuyển lời sang CEO của NVIDIA, Huang Renxun, nói rằng trên Bittensor có một dự án đã “đạt được một thành tựu công nghệ khá điên rồ” — đào tạo một mô hình ngôn ngữ lớn trên internet bằng sức mạnh tính toán phân tán, hoàn toàn phi tập trung và không có bất kỳ trung tâm dữ liệu tập trung nào tham gia.
Huang Renxun đã không né tránh. Ông so sánh sự việc này với “bản hiện đại của Folding@home”, dự án phân tán từng giúp người dùng thông thường đóng góp sức mạnh tính toán rảnh rỗi để cùng nhau giải quyết vấn đề gập protein vào những năm 2000.
Bốn ngày trước, vào ngày 16 tháng 3, Jack Clark, đồng sáng lập Anthropic, cũng dành nhiều đoạn trong báo cáo cập nhật nghiên cứu AI để nhấn mạnh và trích dẫn đột phá này: Mạng con của hệ sinh thái Bittensor Templar (SN3) đã hoàn thành quá trình huấn luyện phân tán mô hình lớn 72 tỷ tham số (Covenant 72B), với hiệu năng tương đương với LLaMA-2 mà Meta công bố năm 2023.
Jack Clark đặt tên cho chương này là “Thách thức chính trị kinh tế học của AI thông qua đào tạo phân tán” và trong phân tích của mình, ông nhấn mạnh đây là một công nghệ đáng để theo dõi liên tục—ông có thể hình dung một tương lai nơi AI trên thiết bị sử dụng rộng rãi các mô hình được đào tạo theo cách phi tập trung, trong khi AI trên đám mây tiếp tục vận hành các mô hình lớn độc quyền.
Phản ứng của thị trường hơi chậm nhưng cực kỳ mạnh mẽ: SN3 đã tăng hơn 440% trong tháng qua và hơn 340% trong hai tuần qua, với vốn hóa thị trường đạt 130 triệu USD. Câu chuyện về subnetwork bùng nổ sẽ trực tiếp tạo áp lực mua vào TAO. Do đó, TAO tăng nhanh, từng đạt mức 377 USD, tăng gấp đôi trong tháng qua, với FDV đạt khoảng 7,5 tỷ USD.
Câu hỏi đặt ra: SN3 đã làm gì? Vì sao lại bị đưa vào ánh đèn chiếu sáng? Câu chuyện giá trị của việc huấn luyện phân tán và AI phi tập trung sẽ phát triển như thế nào?
Mô hình 72B đó
Để trả lời câu hỏi này, trước tiên cần xem xét kết quả mà SN3 đã đạt được.
Ngày 10 tháng 3 năm 2026, đội ngũ Covenant AI đã công bố một báo cáo kỹ thuật trên arXiv, chính thức thông báo hoàn thành quá trình huấn luyện Covenant-72B. Đây là một mô hình ngôn ngữ lớn với 72 tỷ tham số, được huấn luyện trước trên khoảng 1,1 nghìn tỷ tokens bằng hơn 70 nút độc lập (khoảng 20 nút đồng bộ mỗi vòng, mỗi nút được trang bị 8 card B200).
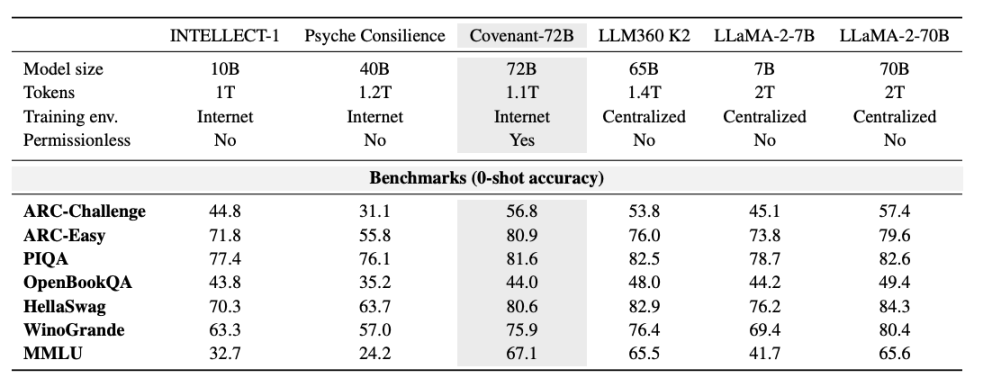
Templar đã cung cấp một số dữ liệu về hiệu suất benchmark, với LLaMA-2-70B là mô hình lớn do Meta phát hành năm 2023. Như Jack Clark, đồng sáng lập Anthropic, đã nói, Covenant-72B có thể đã lỗi thời vào năm 2026. Điểm số 67.1 của Covenant-72B trên MMLU tương đương với LLaMA-2-70B do Meta phát hành năm 2023 (65.6 điểm).
Trong khi đó, các mô hình tiên tiến năm 2026—dù là chuỗi GPT, Claude hay Gemini—đã được huấn luyện trên hàng trăm nghìn GPU với số tham số vượt xa 100 tỷ, sự khác biệt về khả năng suy luận, mã hóa và toán học là vấn đề về cấp độ, chứ không phải phần trăm. Sự chênh lệch thực tế này không nên bị che lấp bởi tâm lý thị trường.
Nhưng khi chuyển đổi sang tiền đề “được huấn luyện bằng sức mạnh tính toán phân tán trên internet mở”, ý nghĩa sẽ hoàn toàn khác biệt.
So sánh: Cùng được huấn luyện phi tập trung, INTELLECT-1 (sản phẩm của đội Prime Intellect, 10 tỷ tham số) đạt điểm MMLU 32.7; trong khi dự án huấn luyện phân tán khác với các thành viên trong danh sách trắng, Psyche Consilience (40 tỷ tham số), đạt điểm 24.2. Covenant-72B với quy mô 72B và điểm MMLU 67.1 là một con số nổi bật trong lĩnh vực huấn luyện phi tập trung.
Quan trọng hơn, đợt huấn luyện này là “không cần phép”. Bất kỳ ai cũng có thể kết nối và trở thành nút tham gia mà không cần kiểm duyệt trước hay danh sách trắng. Hơn 70 nút độc lập đã tham gia cập nhật mô hình, kết nối và đóng góp sức mạnh tính toán từ khắp nơi trên thế giới.
Huang Renxun đã nói gì, chưa nói gì
Khôi phục lại các chi tiết của cuộc trò chuyện podcast này sẽ giúp điều chỉnh cách hiểu của công chúng về lần “ủng hộ” này.
Chamath Palihapitiya đã trình bày thành tựu công nghệ của Bittensor trong cuộc trò chuyện với Huang Renxun, mô tả việc huấn luyện một mô hình Llama bằng sức mạnh tính toán phân tán, với quy trình “hoàn toàn phân tán và đồng thời duy trì trạng thái”. Huang Renxun đã so sánh điều này với “bản hiện đại của Folding@home” và mở rộng cuộc thảo luận về sự cần thiết của việc song song tồn tại giữa các mô hình mã nguồn mở và mô hình sở hữu.
Đáng chú ý là Huang Renxun không trực tiếp đề cập đến token của Bittensor hoặc bất kỳ ý nghĩa đầu tư nào, cũng không thảo luận thêm về việc huấn luyện AI phi tập trung.
Hiểu về các subnet của Bittensor và SN3
Để hiểu về sự đột phá của SN3, trước tiên cần làm rõ cách thức hoạt động của Bittensor và các subnet của nó. Nói một cách đơn giản, Bittensor có thể được xem như một chuỗi công khai và nền tảng AI, trong khi mỗi subnet tương đương với một “dây chuyền sản xuất AI” độc lập, với nhiệm vụ cốt lõi rõ ràng và cơ chế khuyến khích được thiết kế riêng, cùng phối hợp tạo nên hệ sinh thái AI phi tập trung.
Quy trình hoạt động rõ ràng và phi tập trung: chủ sở hữu subnet xác định mục tiêu subnet và viết mô hình khuyến khích; thợ mỏ cung cấp sức mạnh tính toán trong subnet và hoàn thành các nhiệm vụ liên quan đến AI (như suy luận, đào tạo, lưu trữ, v.v.); người xác minh đánh giá đóng góp của thợ mỏ và tải điểm số lên lớp đồng thuận Bittensor; cuối cùng, thuật toán đồng thuận Yuma của Bittensor sẽ phân phối lợi ích tương ứng cho các bên tham gia subnet dựa trên phần thưởng tích lũy của từng subnet.
Hiện tại, Bittensor có 128 subnet, bao phủ các nhiệm vụ AI đa dạng như suy luận, dịch vụ đám mây AI không máy chủ, hình ảnh, gán nhãn dữ liệu, học tăng cường, lưu trữ và tính toán.
SN3 là một trong những mạng con đó. Nó không đóng gói ứng dụng ở lớp ứng dụng, cũng không thuê API mô hình lớn sẵn có, mà nhắm thẳng vào một trong những khâu cốt lõi đắt đỏ và khép kín nhất trong toàn bộ chuỗi công nghiệp AI: chính quá trình tiền huấn luyện mô hình lớn.
SN3 mong muốn sử dụng mạng Bittensor để phối hợp đào tạo phân tán các tài nguyên tính toán phi đồng nhất, thông qua đào tạo phân tán mô hình lớn có động lực, chứng minh rằng có thể huấn luyện các mô hình nền tảng mạnh mẽ mà không cần đến các cụm siêu máy tính tập trung đắt đỏ. Điểm hấp dẫn cốt lõi nằm ở “bình đẳng” — phá vỡ sự độc quyền tài nguyên trong đào tạo tập trung, cho phép cá nhân bình thường hoặc các tổ chức vừa và nhỏ tham gia vào quá trình huấn luyện mô hình lớn, đồng thời giảm chi phí huấn luyện nhờ vào sức mạnh tính toán phân tán.
Lực lượng cốt lõi thúc đẩy sự phát triển của SN3 là Templar, với đội ngũ nghiên cứu đằng sau nó là Covenant Labs. Đội ngũ này đồng thời vận hành hai subnets khác: Basilica (SN39, tập trung vào dịch vụ tính toán) và Grail (SN81, tập trung vào hậu huấn luyện RL và đánh giá mô hình). Ba subnet này tạo thành sự tích hợp dọc, bao phủ toàn bộ quy trình từ tiền huấn luyện đến tối ưu hóa căn chỉnh của các mô hình lớn, xây dựng nên hệ sinh thái hoàn chỉnh cho việc huấn luyện mô hình lớn phi tập trung.
Cụ thể, thợ mỏ đóng góp tài nguyên tính toán để tải lên mạng các cập nhật gradient (hướng và mức độ điều chỉnh tham số mô hình); người xác thực đánh giá chất lượng đóng góp của từng thợ mỏ và cấp điểm trên chuỗi dựa trên mức độ cải thiện lỗi. Kết quả quyết định trọng số phần thưởng, được phân phối tự động mà không cần tin tưởng bất kỳ bên thứ ba nào.
Chìa khóa trong thiết kế cơ chế khuyến khích là phần thưởng được liên kết trực tiếp với "mức độ cải thiện mô hình nhờ đóng góp của bạn", thay vì chỉ dựa vào thời gian tính toán. Điều này giải quyết căn bản vấn đề khó nhất trong bối cảnh phi tập trung: làm thế nào để ngăn chặn các thợ mỏ lười biếng.
Vậy Covenant-72B giải quyết các vấn đề về hiệu quả giao tiếp và tương thích kích thích như thế nào?
Việc phối hợp huấn luyện cùng một mô hình với hàng chục nút không tin tưởng lẫn nhau, phần cứng khác nhau và chất lượng mạng không đồng đều gặp hai thách thức: thứ nhất là hiệu suất truyền thông, các giải pháp huấn luyện phân tán tiêu chuẩn yêu cầu kết nối giữa các nút có băng thông cao và độ trễ thấp; thứ hai là tương thích động lực, làm thế nào để ngăn chặn các nút độc hại gửi gradient sai lệch? Làm thế nào để đảm bảo mỗi người tham gia đang thật sự huấn luyện, chứ không sao chép kết quả của người khác?
SN3 giải quyết hai vấn đề này bằng hai thành phần cốt lõi: SparseLoCo và Gauntlet.
SparseLoCo giải quyết vấn đề hiệu quả truyền thông. Trong đào tạo phân tán truyền thống, mỗi bước đều phải đồng bộ toàn bộ gradient, lượng dữ liệu cực kỳ lớn. Giải pháp mà SparseLoCo sử dụng là: mỗi nút thực hiện 30 bước tối ưu nội bộ (AdamW) tại chỗ, sau đó nén các “gradient giả” được tạo ra trước khi gửi lên các nút khác. Các phương pháp nén bao gồm: thưa thớt Top-k (chỉ giữ lại các thành phần gradient quan trọng nhất), phản hồi lỗi (lưu lại phần bị loại bỏ và tích lũy cho vòng tiếp theo), và lượng tử hóa 2 bit. Tỷ lệ nén cuối cùng vượt quá 146 lần.
Nói cách khác, thứ trước đây cần truyền 100MB, giờ chỉ cần chưa đến 1MB.
Điều này giúp hệ thống duy trì mức sử dụng tính toán khoảng 94,5% dưới giới hạn băng thông của internet thông thường (tốc độ tải lên 110 Mbps, tốc độ tải xuống 500 Mbps) — với 20 nút, mỗi nút có 8 card B200, thời gian truyền thông mỗi vòng chỉ là 70 giây.
Gauntlet giải quyết vấn đề tương thích kích thích. Nó chạy trên blockchain Bittensor (Subnet 3), chịu trách nhiệm xác minh chất lượng của các pseudo-gradient do mỗi nút gửi lên. Cụ thể, hệ thống sử dụng một lô dữ liệu nhỏ để kiểm tra "mức độ giảm tổn thất của mô hình khi áp dụng gradient từ nút này", kết quả được gọi là LossScore. Đồng thời, hệ thống cũng kiểm tra xem nút có đang huấn luyện trên dữ liệu được phân bổ cho nó hay không—nếu một nút cải thiện tổn thất trên dữ liệu ngẫu nhiên tốt hơn trên dữ liệu được phân bổ, nó sẽ bị trừ điểm.
Cuối cùng, chỉ các gradient từ nút có điểm số cao nhất trong mỗi vòng đào tạo mới được chọn để tổng hợp, các nút còn lại bị loại khỏi vòng này. Những người tham gia vượt mức sẽ được bổ sung kịp thời để duy trì sự ổn định của hệ thống. Trong suốt quá trình đào tạo, trung bình mỗi vòng có 16,9 gradient nút được đưa vào tổng hợp, và số lượng ID nút duy nhất từng tham gia vượt quá 70.
Câu chuyện giá trị của AI phi tập trung đang trải qua sự thay đổi căn bản
Từ góc độ kỹ thuật và ngành công nghiệp, hướng đi mà Covenant-72B đại diện mang vài ý nghĩa thực tế.
Đầu tiên, đã phá vỡ giả định cho rằng "huấn luyện phân tán chỉ phù hợp với các mô hình nhỏ". Mặc dù vẫn còn xa mới so với các mô hình tiên tiến, nhưng đã chứng minh được tính mở rộng của hướng đi này.
Thứ hai, việc tham gia không cần phép là hoàn toàn khả thi. Điểm này đã bị đánh giá thấp. Các dự án huấn luyện phân tán trước đây phụ thuộc vào danh sách trắng — chỉ những người tham gia đã được phê duyệt mới có thể đóng góp sức mạnh tính toán. Trong đợt huấn luyện SN3 này, bất kỳ ai có đủ sức mạnh tính toán đều có thể kết nối, và cơ chế xác thực sẽ lọc ra các đóng góp độc hại. Đây là một bước đi cụ thể hướng tới “phi tập trung thực sự”.
Thứ ba, cơ chế dTAO của Bittensor tạo điều kiện cho việc phát hiện giá trị thị trường của các subnet. dTAO cho phép mỗi subnet phát hành token Alpha riêng, thông qua cơ chế AMM để thị trường quyết định các subnet nào nhận được nhiều TAO hơn. Điều này cung cấp một cơ chế thu hút giá trị thô nhưng hiệu quả cho các subnet như SN3 đã tạo ra kết quả cụ thể. Tuy nhiên, cơ chế này cũng dễ bị ảnh hưởng bởi các câu chuyện và cảm xúc, vì chất lượng kết quả huấn luyện LLM rất khó để các bên tham gia thị trường bình thường đánh giá độc lập.
Thứ tư, ý nghĩa chính trị - kinh tế của việc huấn luyện AI phi tập trung. Jack Clark trong Import AI đã nâng vấn đề này lên cấp độ “Ai sở hữu tương lai của AI”. Hiện nay, việc huấn luyện các mô hình tiên tiến bị độc quyền bởi một số ít tổ chức sở hữu trung tâm dữ liệu quy mô lớn, đây không chỉ là vấn đề thương mại mà còn là vấn đề cấu trúc quyền lực. Nếu huấn luyện phân tán có thể tiếp tục đạt được tiến bộ kỹ thuật, nó có thể tạo ra một hệ sinh thái phát triển thực sự phi tập trung đối với một số loại mô hình nhất định (như các mô hình tiên tiến quy mô nhỏ trong lĩnh vực cụ thể). Tuy nhiên, triển vọng này hiện vẫn còn rất xa vời.
Tóm tắt: Một cột mốc thực sự, cùng với rất nhiều vấn đề thực tế
Huang Renxun nói rằng điều này giống như “Folding@home phiên bản hiện đại”. Folding@home đã mang lại những đóng góp thực tế trong lĩnh vực mô phỏng phân tử, nhưng nó không đe dọa vị trí nghiên cứu và phát triển cốt lõi của các công ty dược phẩm lớn. So sánh này rất chính xác.
SN3 đã triển khai thành công giao thức và xác minh hướng khả thi của việc huấn luyện phân tán. Tuy nhiên, từ góc độ kỹ thuật và ngành công nghiệp, đằng sau thành tích này vẫn còn rất nhiều vấn đề ít ai sẵn sàng thảo luận nghiêm túc:
MMLU bản thân cũng là một chỉ số đầy tranh cãi trong cộng đồng học thuật, với nguy cơ các câu hỏi và đáp án của bộ chuẩn công khai bị rò rỉ vào tập huấn luyện. Điều đáng quan tâm hơn là việc lựa chọn cơ sở so sánh: các mô hình mà bài báo so sánh—LLaMA-2-70B và LLM360 K2—đều là các mô hình cũ từ năm 2023 đến 2024, trong khi điểm số từ 65 đến 70 trong cùng khoảng thời gian này khi được đánh giá với Grok hay DouBao lại được xếp vào mức trung bình dưới và cấp độ nhập môn, còn với Claude thì được coi là tụt hậu nghiêm trọng. Nếu đặt chúng trên các bảng xếp hạng được cập nhật liên tục hoặc các bộ chuẩn thế hệ mới được thiết kế chống ô nhiễm, kết luận có lẽ sẽ trung thực hơn.
Quan trọng hơn, dữ liệu chất lượng cao quyết định giới hạn năng lực của mô hình—dữ liệu hội thoại, mã nguồn, suy luận toán học, tài liệu khoa học—đa phần nằm trong tay các công ty lớn, tổ chức xuất bản và cơ sở dữ liệu học thuật. Năng lực tính toán đã được dân chủ hóa, nhưng phía dữ liệu vẫn duy trì cấu trúc độc quyền, và mâu thuẫn này chưa từng được thảo luận.
Về bảo mật, việc tham gia không cần cấp phép có nghĩa là bạn không biết ai đứng sau hơn 70 nút đó, cũng không biết họ đang dùng dữ liệu gì để huấn luyện. Gauntlet có thể lọc ra các gradient rõ ràng bất thường, nhưng không thể ngăn chặn các cuộc đầu độc dữ liệu tinh vi—nếu một nút hệ thống đào tạo thêm vài vòng theo hướng nội dung có hại, sự thay đổi gradient sẽ đủ tinh vi để vượt qua kiểm tra điểm tổn thất, nhưng gây ra sự lệch hướng tích lũy trong hành vi mô hình. Vấn đề cuối cùng là: trong các bối cảnh yêu cầu tuân thủ và bảo mật cao như tài chính, y tế, pháp lý, việc sử dụng một mô hình được huấn luyện bởi một số ít nút ẩn danh và nguồn dữ liệu không thể truy xuất đầy đủ sẽ mang đến những rủi ro gì?
Còn một vấn đề cấu trúc cần nói rõ: Covenant-72B được phát hành mã nguồn mở dưới giấy phép Apache 2.0 và không sử dụng token SN3. Việc sở hữu token SN3 cho phép bạn chia sẻ lợi ích từ việc phát thải do子网 liên tục tạo ra các mô hình mới, chứ không phải bất kỳ lợi ích trực tiếp nào từ việc sử dụng mô hình. Chuỗi giá trị này phụ thuộc vào việc đào tạo liên tục và sự vận hành lành mạnh của cơ chế phát thải toàn bộ mạng Bittensor. Nếu trong tương lai việc đào tạo đình trệ hoặc chất lượng các kết quả đào tạo mới không đạt kỳ vọng, logic định giá của token sẽ bị lung lay.
Việc liệt kê những câu hỏi này không nhằm phủ nhận ý nghĩa của Covenant-72B. Thực tế rằng nó đã chứng minh được một điều trước đây được cho là không thể xảy ra sẽ không bao giờ biến mất. Nhưng việc làm được và ý nghĩa của việc đó là hai chuyện khác nhau.
SN3 token đã tăng 440% trong tháng qua. Khoảng cách này có thể không chỉ đơn thuần là sự thổi phồng, mà là tốc độ của câu chuyện luôn nhanh hơn tốc độ của thực tế. Việc khoảng cách này cuối cùng sẽ được thực tế lấp đầy hay được thị trường điều chỉnh tiêu hóa, phụ thuộc vào những gì đội ngũ Covenant AI sẽ thực sự đưa ra trong thời gian tới.
Đáng chú ý là Grayscale đã nộp đơn xin ETF TAO vào tháng 1 năm 2026, cho thấy tín hiệu sự tham gia của vốn tổ chức vào lĩnh vực này. Ngoài ra, vào tháng 12 năm 2025, Bittensor đã giảm một nửa lượng TAO được phát hành hàng ngày, và sự thắt chặt cấu trúc về nguồn cung vẫn đang tiếp tục.
Liên kết tham khảo:
https://arxiv.org/pdf/2603.08163
https://importai.substack.com/p/importai-449-llms-training-other
https://docs.tplr.ai/
https://systems-analysis.ru/int/MMLU_Benchmark_%E2%80%94_MMLU_%E5%9F%BA%E5%87%86%E6%B5%8B%E8%AF%95