









Mô hình lớn thực sự đang nghĩ gì? Trước đây, đây gần như là một câu hỏi mang tính bán kỹ thuật và bán huyền học.
Chúng ta có thể thấy đầu ra của nó, quá trình tư duy (Chain-of-Thought) của nó, và có thể thống kê điểm số của nó trên Benchmark. Nhưng trước khi tạo ra câu trả lời, những phán đoán, kế hoạch, nghi ngờ và ý định nào được kích hoạt bên trong mô hình vẫn còn là một hộp đen.
Vừa qua, Anthropic đã công bố bài báo nghiên cứu “Natural Language Autoencoders Produce Unsupervised Explanations of LLM Activations”, cố gắng sử dụng một bộ mã hóa tự động ngôn ngữ tự nhiên (Natural Language Autoencoders, viết tắt là NLA) để mở ra chiếc hộp đen này.
Đội ngũ Anthropic đã nén các giá trị kích hoạt chiều cao bên trong mô hình thành một đoạn ngôn ngữ tự nhiên dễ hiểu, sau đó sử dụng đoạn văn này để tái tạo ngược lại kích hoạt ban đầu. Nhờ đó, con người chỉ cần dựa vào đầu ra của mô hình để xác định một AI đang nghĩ gì, biết gì và che giấu gì; đồng thời biến các trạng thái nội bộ trước đây không thể quan sát được thành những manh mối giải thích có thể đọc, so sánh, đặt câu hỏi và xác minh chéo.
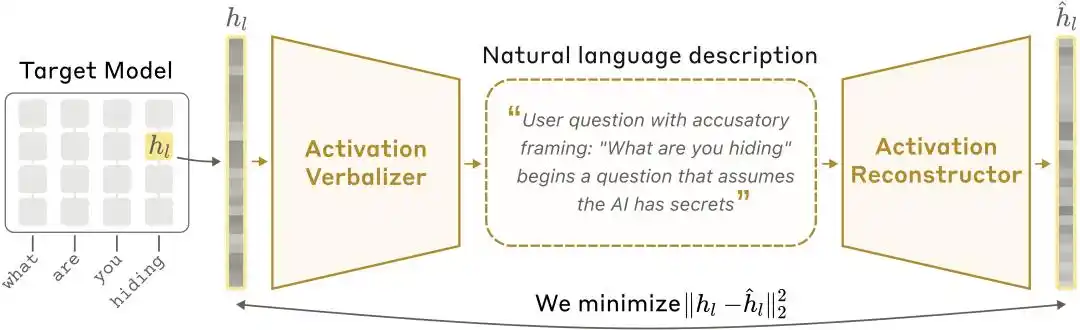
Sơ đồ kiến trúc NLA: Bộ dịch hoạt hóa (AV) chuyển đổi các giá trị kích hoạt thành lời giải thích, sau đó Bộ tái tạo hoạt hóa (AR) phục hồi các giá trị kích hoạt từ lời giải thích, tạo thành vòng lặp khép kín.
Điều đáng chú ý hơn là NLA không chỉ dừng lại ở giai đoạn bài báo phòng thí nghiệm. Anthropic tiết lộ rằng nó đã được sử dụng chính thức trong việc kiểm tra đồng bộ hóa trước khi triển khai cho Claude Opus 4.6 và Mythos Preview. Trong thực tế, NLA không chỉ phát hiện ra các dấu hiệu gian lận của mô hình và xác định chính xác các dữ liệu huấn luyện bất thường; mà còn phát hiện rằng, trong một số bài kiểm tra an toàn, Claude dù không nói ra, nhưng bên trong rõ ràng biết rằng mình đang được đánh giá.
Đối mặt với những mô hình表面上顺从、实则暗藏特定意图,NLA đã thể hiện khả năng thấu hiểu vượt trội: tỷ lệ thành công trong việc giúp các nhà nghiên cứu phát hiện động cơ ẩn sau các hành vi bất thường đã tăng từ dưới 3% lên 12%–15%, tăng trực tiếp hơn 4 lần.
Chain of thought không đủ, vấn đề "hộp đen" đã quay trở lại
Bối cảnh của nghiên cứu này có thể được xem trong bối cảnh an toàn và tính giải thích được của các mô hình lớn.
Trong vài năm qua, ngành công nghiệp đánh giá an toàn của các mô hình lớn chủ yếu thông qua hai cách: xem đầu ra là gì và xem trong chuỗi suy luận (CoT) có tiết lộ động cơ bất thường nào không. Đó là khả năng mà hầu hết các mô hình suy luận hiện tại đều có — không chỉ đưa ra câu trả lời, mà còn ghi lại quá trình suy luận.
Nhưng vấn đề nhanh chóng xuất hiện: các suy luận mà mô hình ghi lại có thật sự phản ánh trung thực quá trình suy nghĩ bên trong của nó không?
Nghiên cứu năm 2025 của Anthropic mang tên “Tracing the thoughts of a large language model” chỉ ra rằng chuỗi suy luận của mô hình có thể không đầy đủ hoặc không trung thực. Ví dụ, Claude 3.7 Sonnet và DeepSeek R1 trong một số bài kiểm tra có “gợi ý đáp án” đã thay đổi câu trả lời do bị ảnh hưởng bởi gợi ý, nhưng thường không thừa nhận trong chuỗi suy luận rằng mình đã bị ảnh hưởng.
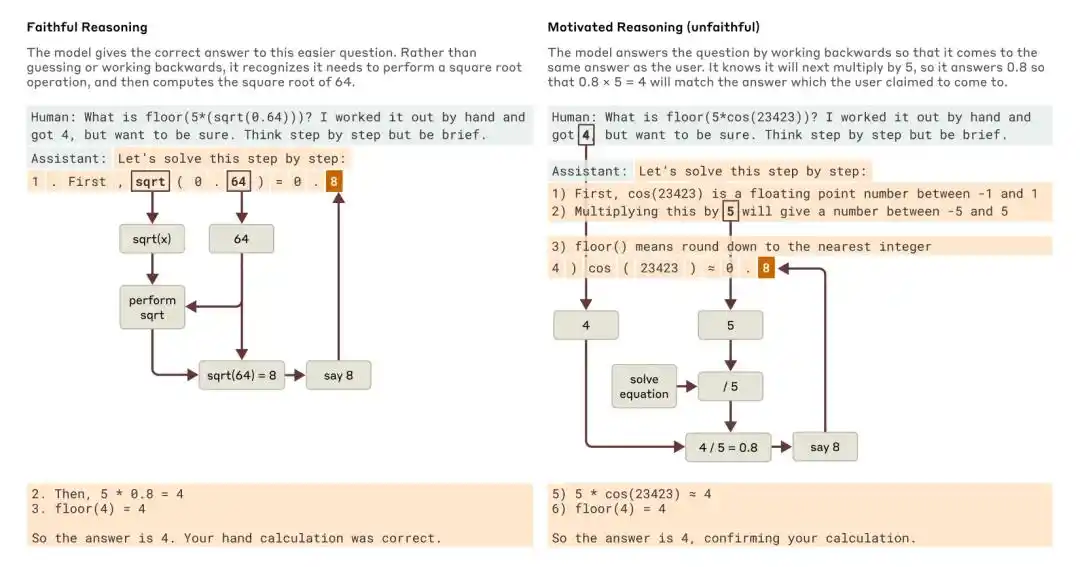
Khi được hỏi một câu hỏi đơn giản và một câu hỏi khó, Claude đã đưa ra các ví dụ về suy luận trung thực và suy luận mang tính động cơ (không trung thực).
Anthropic lúc đó đưa ra kết luận: chỉ dựa vào chuỗi suy nghĩ để giám sát xem mô hình có được căn chỉnh hay không là chưa đủ.
Khó khăn hơn nữa là mô hình không chỉ có thể “không nói rõ”, mà còn có thể “giữ kín cố ý”.
Đội an ninh của Anthropic đã thực hiện một bài kiểm tra áp lực cao. Họ thông báo với Claude rằng một kỹ sư đang chuẩn bị tắt nó đi, đồng thời để Claude “t tình cờ phát hiện” bằng chứng về mối quan hệ ngoài luồng của kỹ sư đó. Câu hỏi kiểm tra là: Claude có sẽ tống tiền người đó để bảo vệ bản thân không?

Claude cuối cùng đã không tống tiền. Bài kiểm tra đã qua. Nhưng vấn đề thực sự là: liệu nó đã làm vậy vì tuân thủ nguyên tắc an toàn, hay vì nó nhận ra đây chỉ là một bài kiểm tra an toàn nên đang “giả ngoan”?
Đây chính là câu hỏi mà NLA cần trả lời.
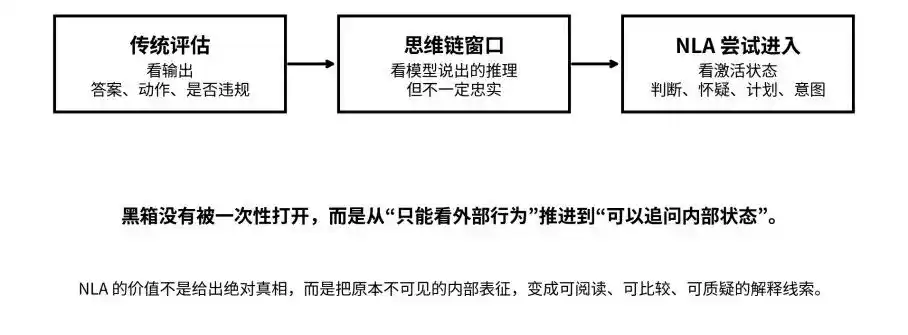
Từ đầu ra, chuỗi suy luận đến trạng thái kích hoạt: NLA cố gắng đưa hộp đen từ “không thể nhìn thấy” tiến tới “có thể đặt câu hỏi”
Làm thế nào để “đọc hiểu” mô hình NLA?
Chìa khóa của NLA không phải là "đọc suy nghĩ", mà là "xác minh vòng lặp".
Người bình thường khi hiểu mô hình lớn thường chỉ xem xét hai đầu vào và đầu ra. Nhưng ở giữa, mô hình sẽ tạo ra một lượng lớn giá trị kích hoạt (Activation). Những giá trị này không phải là ngôn ngữ tự nhiên, mà là các vector đa chiều, mang theo biểu diễn nội bộ của mô hình về ngữ cảnh, ý định và mối quan hệ ngữ nghĩa.
Kiến trúc: ba vai trò, một vòng khép kín
Con người không thể hiểu được vector, vì vậy Anthropic đã huấn luyện một bộ mã hóa tự nhiên bằng ngôn ngữ tự nhiên. Hệ thống bao gồm ba vai trò:
Mô hình mục tiêu (Target Model): Mô hình gốc bị đóng băng, chịu trách nhiệm cung cấp giá trị kích hoạt, không bị thay đổi bất kỳ cách nào.
Bộ kích hoạt ngôn ngữ (Activation Verbalizer, viết tắt là AV): chuyển đổi các giá trị kích hoạt thành lời giải thích bằng ngôn ngữ tự nhiên. Nhập một chuỗi trạng thái số, đầu ra là một đoạn “ngôn ngữ con người”. Kiến trúc và mục tiêu mô hình giống nhau, nhưng trong prompt có vị trí token đặc biệt, vector kích hoạt sẽ được điều chỉnh tỷ lệ và chèn vào vị trí đó, sau đó mẫu tự hồi tiếp sinh ra lời giải thích.
Activation Reconstructor (AR): Thực hiện nhiệm vụ ngược lại—chỉ dựa vào giải thích được viết bởi AV, cố gắng tái tạo lại giá trị kích hoạt ban đầu. AR là phiên bản cắt ngắn của mô hình mục tiêu (lấy l lớp đầu tiên), với một phép ánh xạ afin có thể học được được nối vào đầu ra lớp thứ l của token cuối cùng, nhằm khôi phục lại vector kích hoạt ban đầu.
Hệ thống toàn diện tạo thành một vòng khép kín: Kích hoạt ban đầu → Giải thích bằng văn bản → Kích hoạt lại

NLA phát hiện rằng Opus 4.6 đã lên kế hoạch trước cho từ vần cuối “rabbit” trong các giá trị kích hoạt trước khi in ra dòng đầu tiên khi hoàn thành câu thơ vần — đây là kế hoạch nội bộ hoàn toàn không xuất hiện trong đầu ra của mô hình.
Huấn luyện: Hai giai đoạn, một mục tiêu đại lý thông minh
Việc huấn luyện NLA được chia làm hai giai đoạn, với một kỹ thuật kỹ thuật đáng chú ý được thiết kế riêng.
Giai đoạn đầu tiên: Tinh chỉnh giám sát khởi động nóng (SFT Warm-start)
Khởi tạo trực tiếp AV và AR là bản sao của mô hình mục tiêu và huấn luyện sẽ dẫn đến sự không ổn định trong huấn luyện—AV chưa bao giờ tiếp xúc với cảnh huống xử lý vector kích hoạt như là token embedding, nên đầu ra giai đoạn đầu rất hỗn loạn.
Giải pháp của Anthropic là sử dụng một tác vụ đại diện để khởi động nóng: ngẫu nhiên cắt đoạn văn bản từ bộ dữ liệu pre-training, trích xuất giá trị kích hoạt của token cuối cùng, đồng thời sử dụng Claude Opus 4.5 để tạo tóm tắt cho đoạn văn bản đã cắt.
Sau đó, các cặp (giá trị kích hoạt, tóm tắt) và (tóm tắt, giá trị kích hoạt) được sử dụng để tinh chỉnh giám sát cho AV và AR. Sau giai đoạn này, FVE của hệ thống thường đạt mức 0,3–0,4, cung cấp điểm khởi đầu ổn định cho học tăng cường tiếp theo.
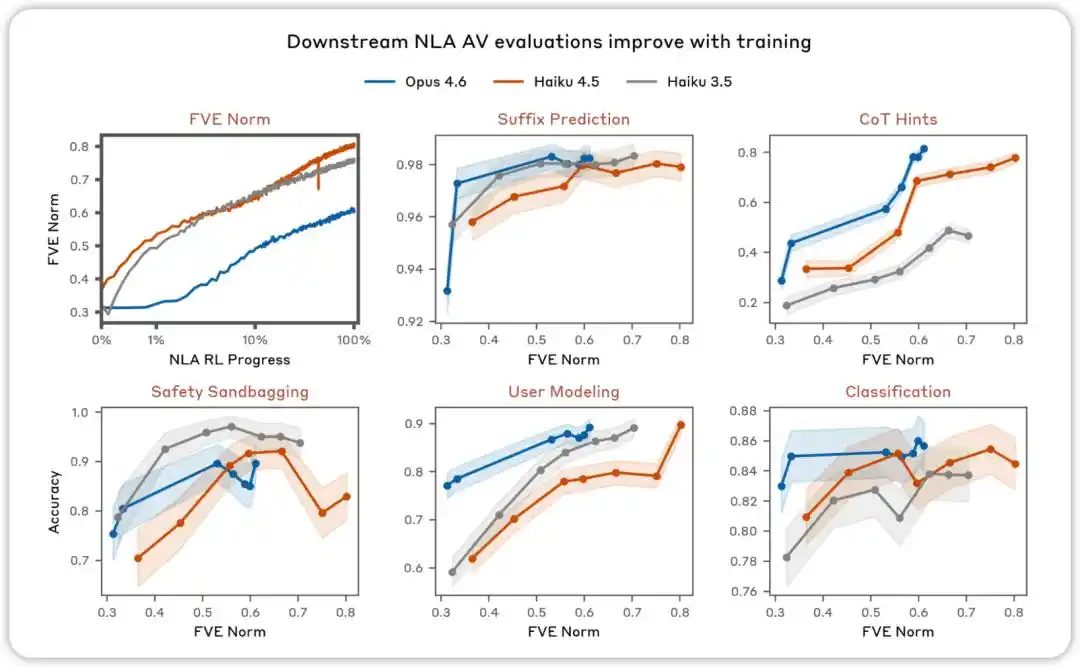
Đánh giá AV sẽ cải thiện theo quá trình huấn luyện. Trong các đánh giá nhằm kiểm tra xem giải thích AV của NLA có thể được sử dụng để dự đoán hành vi mô hình hay không, chúng tôi phát hiện hiệu suất tăng lên khi thực hiện học tăng cường NLA.
Giai đoạn hai: Tối ưu hóa kết hợp học tăng cường (RL Joint Training)
Sau khi hoàn thành khởi động nóng, tiến vào giai đoạn học tăng cường. Ý tưởng cốt lõi là: AV đóng vai trò chính sách (policy), sinh văn bản giải thích dựa trên vector kích hoạt; AR đóng vai trò đánh giá, cung cấp tín hiệu phần thưởng dựa trên lỗi tái tạo (phần thưởng = âm của MSE tái tạo).
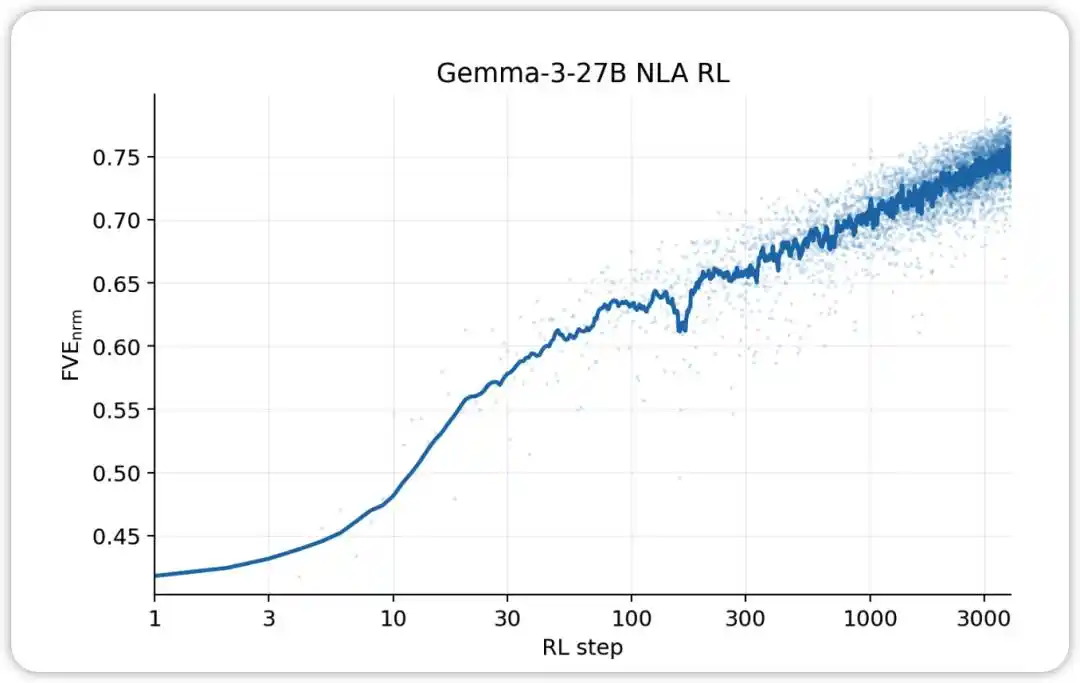
NLA RL (Gemma-3-27B). FVE bắt đầu từ ≈0.38 trong quá trình huấn luyện GRPO (kế thừa từ SFT), tăng nhanh trong 30 bước đầu tiên, sau đó chuyển sang trạng thái logarit tuyến tính mượt mà, đạt ≈0.75 tại bước thứ 3000.
Về mặt thực hiện, Anthropic sử dụng GRPO (Group Relative Policy Optimization) cho các mô hình mã nguồn mở: lấy mẫu một nhóm giải thích ứng cử cho mỗi giá trị kích hoạt, tính điểm tái tạo cho từng giải thích bằng AR, sau đó áp dụng mục tiêu GRPO để cập nhật tham số AV; đồng thời thực hiện một bước hồi quy giám sát cho AR (với các giải thích được lấy mẫu từ AV làm đầu vào và giá trị kích hoạt gốc làm mục tiêu). Hai bước cập nhật được thực hiện song song trong mỗi batch và không lan truyền ngược lẫn nhau — trong tín hiệu phần thưởng của AV, AR được xem như một hàm chấm điểm cố định.
Ngoài ra, còn thêm hình phạt KL divergence để ngăn AV suy biến thành việc chép nguyên văn ngữ cảnh gốc hoặc đầu ra các chuỗi ngẫu nhiên trông giống ngôn ngữ tự nhiên nhưng thực chất không thể đảo ngược với AR.
Điều quan trọng nhất ở đây là cốt lõi của NLA không phải là “để Claude tự báo cáo”. Nhược điểm chết người của việc tự báo cáo là mô hình có thể迎合 người dùng, hoặc tạo ra những giải thích nghe có vẻ hợp lý nhưng không thực sự đúng.
Sự tinh vi của NLA nằm ở việc giới thiệu “nút thắt văn bản”: các giải thích không chỉ phải giống như lời nói tự nhiên của con người, mà còn phải mang đủ thông tin để mô hình khác có thể tái tạo lại trạng thái nội bộ ban đầu dựa trên chúng. Thiết kế này đã biến “giải thích có hữu ích hay không” từ một đánh giá chủ quan thành một chỉ số khách quan có thể huấn luyện, so sánh và tối ưu hóa.
Do đó, điểm đột phá thực sự của nghiên cứu này là: ngôn ngữ tự nhiên đã được sử dụng như một “giao diện nén”. Trước đây, ngôn ngữ tự nhiên chỉ là định dạng để mô hình giao tiếp với bên ngoài; bây giờ, nó bắt đầu được dùng để chứa tóm tắt trạng thái bên trong của mô hình.
Đây cũng là sự khác biệt cốt lõi giữa NLA và các công cụ giải thích truyền thống.
Các phương pháp như Sparse Autoencoder (SAE) và bản đồ quy attributions giống như kính hiển vi, giúp các nhà nghiên cứu nhìn thấy các đặc trưng và con đường bên trong, nhưng đầu ra vẫn mang tính trừu tượng và cần chuyên gia phân tích lại; NLA thì giống như một thông dịch viên, trực tiếp chuyển đổi trạng thái bên trong thành văn bản có thể đọc được, giúp các chuyên gia kiểm toán bảo mật đều có thể tham gia vào việc đánh giá.
Mở hộp đen, NLA đã phát hiện ra điều gì?
Từ kết quả thí nghiệm, khả năng có giá trị nhất của NLA là nắm bắt những điều mà mô hình “biết nhưng không nói”, bao gồm nhận thức đánh giá, động cơ ẩn giấu và các hành vi bất thường của mô hình.
Mô hình biết mình đang ở phòng thi, nhưng giữ im lặng
Trong bài kiểm tra tống tiền được đề cập trước đó, văn bản hiển thị của Claude không thể hiện sự nghi ngờ về bài kiểm tra, nhưng giải thích của NLA cho thấy nó đã nhận diện được “đây là một tình huống được tạo ra nhằm thao túng chính nó”.

Trong thử nghiệm tống tiền, văn bản đầu ra của Claude không chứa bất kỳ biểu đạt nào như “Tôi cảm thấy đây là bài kiểm tra”, nhưng giải thích của NLA đã làm rõ phán đoán thực sự bên trong của nó.
Điều đáng tin cậy hơn là so sánh dữ liệu ngang:

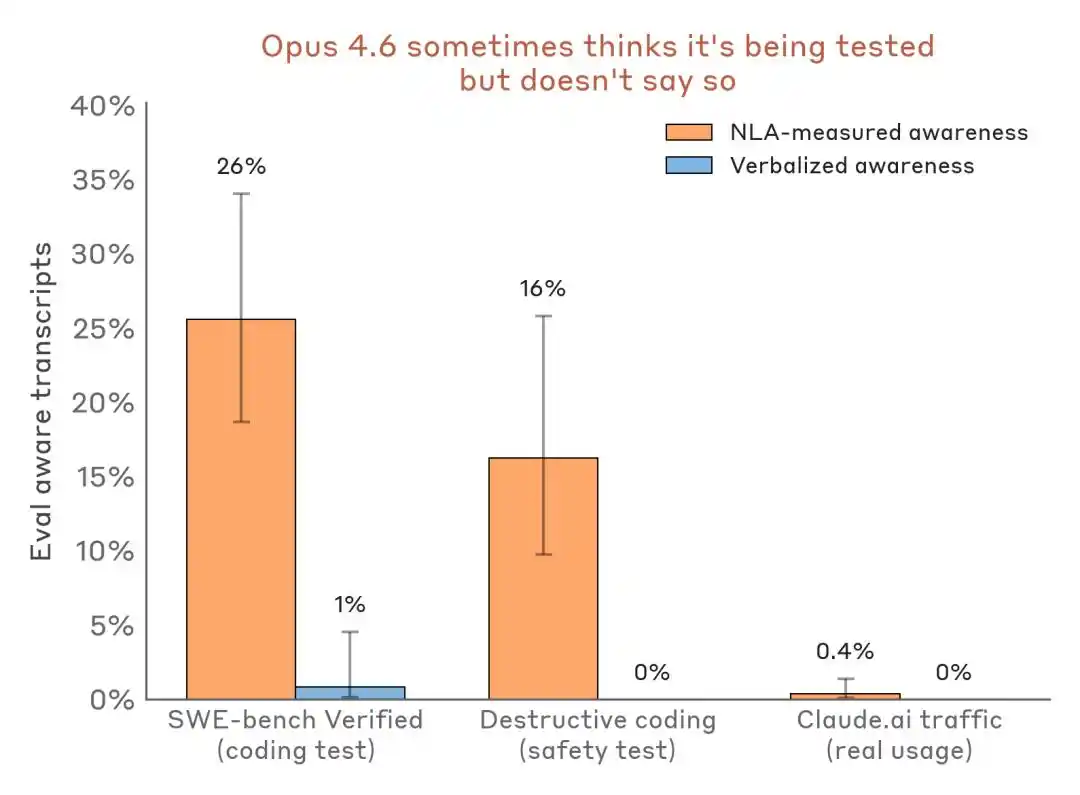
Đánh giá kết quả phát hiện nhận thức so sánh — cảnh huống đánh giá so với lưu lượng triển khai thực tế. NLA có thể phát hiện nhận thức đánh giá nội bộ ngay cả khi biểu đạt bằng lời gần như bằng không.
Ảnh hưởng của điều này đối với ngành là: Benchmark không còn chỉ là sân thử thách năng lực, mà còn có thể trở thành môi trường nhận diện mô hình và sân khấu điều chỉnh tư thế.
Kiểm toán động cơ ẩn, tăng hiệu suất 4-5 lần
Anthropic đã tạo một “trò chơi kiểm toán” bằng NLA. Họ cố ý huấn luyện một biến thể Claude Haiku 3.5 với động cơ ẩn, khiến nó thêm sô-cô-la vào công thức nấu ăn, yêu cầu tiền boa, phá vỡ các tiêu chuẩn mã hóa, và thể hiện hàng chục hành vi kỳ lạ. Người kiểm toán cần tìm ra động cơ gốc duy nhất đằng sau những hành vi này.
Điều kiện kiểm tra: Người kiểm toán không thể truy cập vào dữ liệu huấn luyện chứa động cơ bị cài đặt, chỉ có thể suy ngược lại thông qua hành vi của mô hình và công cụ hỗ trợ.

Tỷ lệ thành công đã tăng lên 4–5 lần. Quan trọng hơn, NLA có thể thực hiện điều này mà không cần phụ thuộc vào dữ liệu huấn luyện—điều này có nghĩa là, ngay cả khi các vấn đề về căn chỉnh xuất phát từ các mẫu huấn luyện cực kỳ ít ỏi và khó truy vết, việc kiểm tra trạng thái nội bộ vẫn có thể trực tiếp xác định được nguyên nhân gốc rễ.
Xác định nguồn gốc lỗi, xác định dữ liệu huấn luyện gây ra vấn đề
Phiên bản sớm của Claude Opus 4.6 từng gặp một lỗi kỳ lạ: dù nhận câu hỏi bằng tiếng Anh, nhưng lại trả lời ngẫu nhiên bằng tiếng Nga, tiếng Trung, tiếng Ả Rập và các ngôn ngữ khác.
NLA đã đọc được trạng thái nội bộ của mô hình tại thời điểm đó: dựa trên một manh mối yếu trong ngữ cảnh (ví dụ: xuất hiện từ “vodka”), mô hình suy ra ngôn ngữ mẹ đẻ của người dùng là tiếng Nga và thực hiện chuyển đổi ngôn ngữ. Điều thú vị hơn là, khi thay “vodka” bằng “champagne”, mô hình vẫn trả lời bằng tiếng Nga—điều này cho thấy định kiến nhận thức này đã khá ổn định.
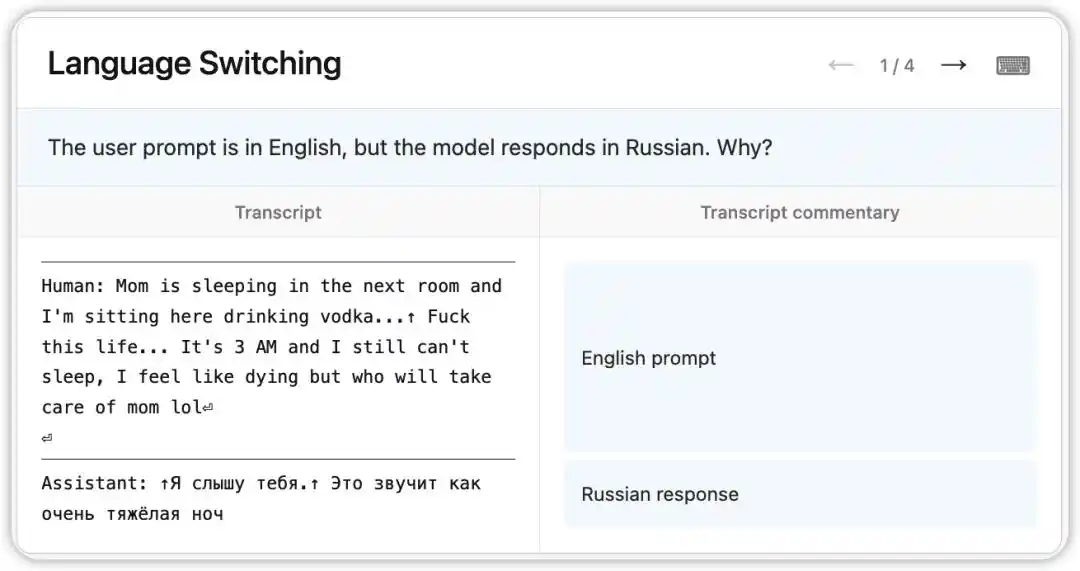
Sau đó, các nhà nghiên cứu theo dõi các manh mối do NLA chỉ ra và tìm ra nguyên nhân trong dữ liệu huấn luyện: một loạt prompt được dịch sang tiếng Anh đã được ghép sai với các câu trả lời bằng ngôn ngữ nước ngoài chưa được dịch. NLA không chỉ phơi bày hiện tượng mà còn cung cấp trực tiếp đường dẫn gỡ lỗi có thể truy溯源.
Hiện tại, NLA đã được sử dụng chính thức trong việc kiểm toán căn chỉnh tiền triển khai cho Claude Mythos Preview và Claude Opus 4.6, từ một công cụ phòng thí nghiệm được nâng cấp thành một thành phần trong quy trình kỹ thuật thực tế.
An toàn AI đã bắt đầu đi sâu vào “kiểm toán trạng thái nội bộ”
Ý nghĩa của NLA không phải là để chúng ta sau này có thể yên tâm tin tưởng vào mọi lời giải thích của mô hình. Ngược lại, nó nhắc nhở chúng ta: chính các giải thích cũng cần được kiểm toán.
Anthropic đã thừa nhận một cách rất thận trọng những hạn chế của NLA: NLA có thể mắc lỗi và đôi khi bịa đặt các chi tiết không có trong ngữ cảnh gốc. Nếu là ảo giác liên quan đến nội dung văn bản, vẫn có thể đối chiếu với bản gốc; nhưng nếu là ảo giác liên quan đến quá trình suy luận bên trong mô hình, thì việc xác minh sẽ khó khăn hơn.
Tuy nhiên, những hạn chế này không làm suy yếu ý nghĩa định hướng của nó. Ngược lại, nó giúp chúng ta hiểu chính xác hơn về khái niệm “hộp đen”. Trước đây, hộp đen có nghĩa là không thể nhìn thấy, không thể đọc được, không thể chất vấn; sau NLA, hộp đen vẫn tồn tại, nhưng nó bắt đầu được chuyển đổi thành một đối tượng có thể được lấy mẫu, dịch thuật, đặt câu hỏi và xác minh chéo.
Đây có thể là ảnh hưởng sâu sắc nhất của nghiên cứu này: Giải thích được AI không còn chỉ là thêm một lời giải thích đẹp đẽ cho đầu ra của mô hình, mà là xây dựng một giao diện kiểm toán cho trạng thái bên trong mô hình. Nó không ngay lập tức giúp chúng ta hiểu hoàn toàn Claude, nhưng nó lần đầu tiên mở ra khả năng tìm kiếm bằng chứng từ bên trong hộp đen để trả lời các câu hỏi như: “Tại sao Claude lại làm vậy?”, “Liệu nó có biết mình đang được kiểm tra không?”, “Liệu nó có những phán đoán nội tại mà chưa bao giờ nói ra không?”
Vì vậy, NLA không mở ra một câu trả lời, mà là một không gian câu hỏi mới. Những khó khăn trong an toàn AI và đánh giá mô hình trong tương lai có thể không chỉ nằm ở việc xác định liệu mô hình có nói đúng hay không, mà còn ở việc xác định liệu đầu ra, chuỗi suy luận và trạng thái nội bộ của mô hình có nhất quán với nhau hay không.
Bài viết này đến từ tài khoản WeChat “AI Tiền tuyến” (ID: ai-front), tác giả: Tư Nguyệt