
स्व-सीखने वाले एआई एजेंट्स, पारंपरिक मशीन लर्निंग मॉडल्स और वर्तमान एलएलएम-आधारित एजेंट्स से कैसे भिन्न हैं?
2026/05/02 15:21:02
परिचय
कृत्रिम बुद्धिमत्ता का दृश्य एक गहरे बदलाव से गुजर रहा है। जबकि पिछले दशक में पारंपरिक मशीन लर्निंग मॉडल प्रमुख रहे और 2022 के बाद से बड़े भाषा मॉडलों ने दुनिया का ध्यान आकर्षित किया, एक नया परिप्रेक्ष्य उभर रहा है जो AI प्रणालियों के कार्य करने के तरीके को मौलिक रूप से बदल रहा है। स्वयं-सीखने वाले AI एजेंट अगली विकासात्मक कूद हैं, जो स्वायत्तता, अनुकूलनीय तर्क, और निरंतर सुधार को ऐसे तरीके से मिलाती हैं जो उन्हें अपने पूर्ववर्ती और वर्तमान LLM-आधारित प्रणालियों से स्पष्ट रूप से अलग करती हैं। तेजी से विकसित होते AI परितंत्र को समझने के लिए इन अंतरों को समझना आवश्यक है।
स्वयं सीखने वाले एआई एजेंट्स क्या हैं?
स्व-सीखने वाले एआई एजेंट स्वायत्त कंप्यूटेशनल इकाइयाँ हैं जो अपने परिवेश को समझने, जानकारी का विश्लेषण करने, निर्णय लेने और विशिष्ट लक्ष्यों को प्राप्त करने के लिए कार्रवाई करने में सक्षम हैं। पारंपरिक एआई प्रणालियों के विपरीत जो प्रत्येक चरण में मानवीय प्रेरणा की आवश्यकता होती है, स्व-सीखने वाले एजेंट को एक उच्च-स्तरीय लक्ष्य दिया जा सकता है और वे स्वतंत्र रूप से यह निर्धारित करेंगे कि इसे कैसे प्राप्त किया जाए। ये एजेंट प्रत्यक्षीकरण, तर्क, सीखने और कार्रवाई की क्षमताओं को मिलाकर केवल जैविक प्रणालियों में ही पहले देखा गया बुद्धिमानी व्यवहार का सिमुलेशन करते हैं।
स्वयं-सीखने वाले एआई एजेंट्स की परिभाषात्मक विशेषताएँ स्वायत्तता, प्रतिक्रियाशीलता, प्रारंभिकता और सामाजिक क्षमता हैं। स्वायत्तता एजेंट्स को निरंतर मानव हस्तक्षेप के बिना स्वतंत्र रूप से कार्य करने की अनुमति देती है। प्रतिक्रियाशीलता उन्हें पर्यावरणीय बदलावों को समझने और उचित तरीके से प्रतिक्रिया करने की सक्षम बनाती है। प्रारंभिकता का अर्थ है कि वे केवल उद्दीपनों के प्रति प्रतिक्रिया नहीं करते, बल्कि योजना बनाकर सक्रिय रूप से लक्ष्यों की प्राप्ति करते हैं। सामाजिक क्षमता बहु-एजेंट प्रणालियों में अन्य एजेंट्स के साथ सहयोग करके जटिल कार्यों को पूरा करने की अनुमति देती है।
माइक्रोसॉफ्ट के 2025 के एआई भविष्यवाणियों के अनुसार, एआई-संचालित एजेंट अधिक कार्यों को निष्पादित करने के लिए अधिक स्वायत्तता प्राप्त कर रहे हैं, जिससे कई क्षेत्रों में जीवन की गुणवत्ता में सुधार हो रहा है। मुख्य अंतर इस बात में है कि इन एजेंट्स कैसे लक्ष्यों को संभालते हैं: जबकि एक बड़ी भाषा मॉडल को गुणवत्तापूर्ण आउटपुट प्राप्त करने के लिए विस्तृत, अच्छी तरह से तैयार किया गया प्रॉम्प्ट की आवश्यकता होती है, एक एआई एजेंट को केवल एक लक्ष्य की आवश्यकता होती है, और यह स्वतंत्र रूप से आवश्यक कार्रवाइयों को सोचेगा और निष्पादित करेगा।
पारंपरिक मशीन लर्निंग मॉडल: संरचना और सीमाएँ
पारंपरिक मशीन लर्निंग मॉडल आर्टिफिशियल इंटेलिजेंस के लिए एक मूलभूत अलग दृष्टिकोण का प्रतिनिधित्व करते हैं। इन मॉडल्स को आमतौर पर वर्गीकरण, प्रतिगमन या समूहीकरण जैसे संकीर्ण, अच्छी तरह से परिभाषित कार्यों को करने के लिए विशिष्ट डेटासेट पर प्रशिक्षित किया जाता है। एक बार डिप्लॉय करने के बाद, वे निश्चित पैरामीटर के भीतर काम करते हैं और बिना स्पष्ट पुनः प्रशिक्षण के नए अनुभवों के आधार पर अपना व्यवहार नहीं बदल सकते।
पारंपरिक ML मॉडलों की आर्किटेक्चर पुराने डेटा से सांख्यिकीय सीखने पर केंद्रित है। एक मॉडल प्रशिक्षण के दौरान पैटर्न सीखता है और निष्कर्ष निकालने के समय इन सीखे गए पैटर्न को नए इनपुट पर लागू करता है। यह दृष्टिकोण स्पैम पहचान, छवि वर्गीकरण या सिफारिश प्रणाली जैसे स्पष्ट पैटर्न और सुसंगठित इनपुट वाले कार्यों के लिए अत्यंत अच्छी तरह काम करता है। हालाँकि, इन मॉडलों की स्थिर प्रकृति गतिशील, अप्रत्याशित परिवेशों में महत्वपूर्ण सीमाएँ उत्पन्न करती है।
पारंपरिक ML मॉडल्स को मानव इंजीनियर्स द्वारा फीचर्स को परिभाषित करने, एल्गोरिदम चुनने और हाइपरपैरामीटर्स को ट्यून करने की आवश्यकता होती है। जब डेटा वितरण में परिवर्तन होता है या कार्य की आवश्यकताएँ बदल जाती हैं, तो मॉडल्स का प्रदर्शन कमजोर हो सकता है और पुनः प्रशिक्षण की आवश्यकता होती है। डिप्लॉयमेंट के बाद शिक्षण प्रक्रिया मूलतः जम जाती है, जिसका अर्थ है कि इन प्रणालियों में अनुभव से सुधार करने या नए स्थितियों के लिए अनुकूलन करने की क्षमता नहीं होती, बिना स्पष्ट हस्तक्षेप के।
सुरक्षा और अनुपालन टीमें सामान्यतः संरचित डेटा में पैटर्न पहचान के लिए पारंपरिक ML का उपयोग करती हैं, लेकिन ये प्रणालियाँ संदर्भीय समझ या बहु-चरणीय तर्क की आवश्यकता वाले कार्यों का सामना करने पर कठिनाई का सामना करती हैं। इनमें योजना बनाने, कारण-प्रभाव के बारे में तर्क करने या जटिल समस्याओं को छोटे, प्रबंधनीय उप-कार्यों में विघटित करने की क्षमता नहीं होती है।
एलएलएम-आधारित एजेंट: वर्तमान क्षमताएँ और सीमाएँ
वर्तमान LLM-आधारित एजेंट्स पारंपरिक मशीन लर्निंग की तुलना में एक महत्वपूर्ण उन्नति का प्रतिनिधित्व करते हैं। अरबों पैरामीटर के साथ बड़े भाषा मॉडल पर बनाए गए इन प्रणालियों को प्राकृतिक भाषा को समझने, मानव-जैसा पाठ उत्पन्न करने और ऐसे तर्क कार्यों को करने में सक्षम बनाता है जो पहले AI के लिए असंभव थे। OpenAI, Anthropic और Google जैसी कंपनियों ने लगातार क्षमताशाली मॉडल विकसित किए हैं जो आज कई AI अनुप्रयोगों के लिए आधार के रूप में कार्य करते हैं।
LLM-आधारित एजेंट्स प्राकृतिक भाषा समझ और उत्पादन में उत्कृष्ट होते हैं। वे अर्थपूर्ण संवाद कर सकते हैं, दस्तावेज़ों का सारांश बना सकते हैं, कोड लिख सकते हैं और जटिल अवधारणाओं को समझा सकते हैं। उदाहरण के लिए, OpenAI का o1 मॉडल उन्नत तर्क क्षमताएँ प्रदर्शित करता है जो इसे कठिन प्रश्नों के उत्तर देने से पहले मानव विश्लेषण के समान तार्किक कदमों का उपयोग करके जटिल समस्याओं को हल करने में सक्षम बनाती हैं।
हालाँकि, वर्तमान में अधिकांश LLM-आधारित एजेंट मूल रूप से प्रतिक्रियाशील प्रणालियाँ हैं। वे उपयोगकर्ता के प्रॉम्प्ट का जवाब देते हैं, लेकिन दुनिया में लक्ष्यों का आगे बढ़ने या कार्रवाई करने के लिए प्रारंभिक रूप से कदम नहीं उठाते। जब आप एक चैटबॉट के साथ बातचीत करते हैं, तो प्रणाली आपके इनपुट और अपने प्रशिक्षण डेटा के आधार पर एक प्रतिक्रिया उत्पन्न करती है, लेकिन बिना निरंतर मानव मार्गदर्शन के यह स्वतंत्र रूप से एक व्यापक उद्देश्य को पूरा करने के लिए कदम नहीं उठाती है।
LLM-आधारित एजेंट्स की सीमाएँ तब स्पष्ट हो जाती हैं जब कार्यों में एक से अधिक चरणों में लगातार प्रयास, बाहरी उपकरणों के साथ एकीकरण, या प्रतिक्रिया के आधार पर अनुकूलन की आवश्यकता होती है। हालाँकि इन मॉडल्स क्षमता होती है कि वे एक एक्सचेंज के भीतर समस्याओं का तर्क दे सकें, लेकिन वे अक्सर बातचीत के दौरान स्थिति को बनाए रखने, बाहरी प्रणालियों में क्रियाएँ निष्पादित करने, या अपने निर्णयों के परिणामों से सीखने की क्षमता नहीं रखते।
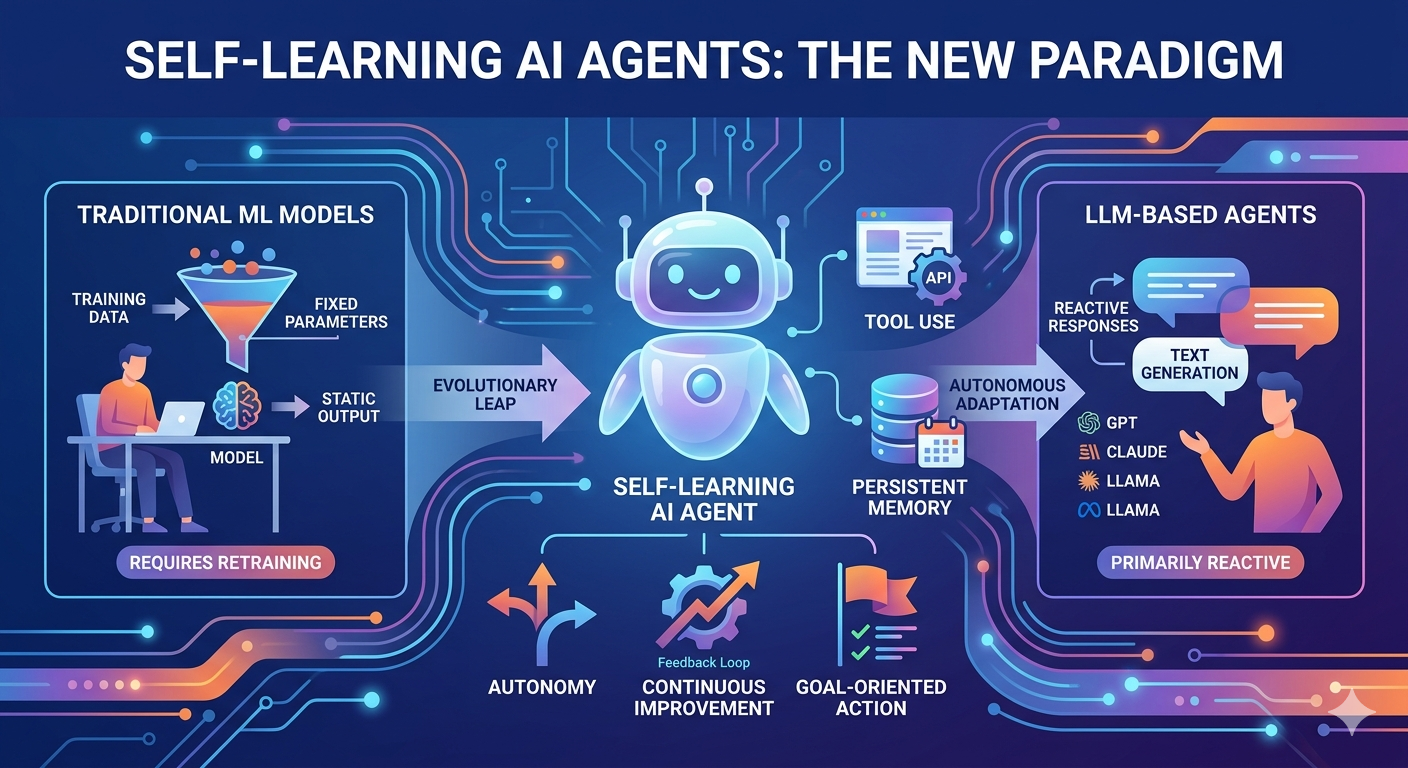
मुख्य अंतर: स्व-सीखने वाले एआई एजेंट्स बनाम पारंपरिक एमएल
स्वयं सीखने वाले एआई एजेंट्स और पारंपरिक मशीन लर्निंग मॉडल्स के बीच के अंतर आर्किटेक्चर, क्षमता और संचालन सिद्धांत में हैं। इन भिन्नताओं को समझने से स्पष्ट होता है कि कई विशेषज्ञ एजेंट्स को एआई विकास की अगली सीमा के रूप में देखते हैं।
-
सीखना और अनुकूलन
पारंपरिक ML मॉडल एक निश्चित प्रशिक्षण चरण के दौरान सीखते हैं और फिर स्थैतिक रूप से कार्य करते हैं। ऐतिहासिक लेन-देन के डेटा पर प्रशिक्षित धोखाधड़ी पता लगाने वाला मॉडल उसी पैटर्न को अनंत तक लागू करता रहेगा, जब तक कि इसे पुनः प्रशिक्षित न किया जाए। इसके विपरीत, स्वयं-सीखने वाले एजेंट अपने पर्यावरण के साथ अपनी बातचीत से लगातार सीख सकते हैं। वे अपने कार्यों के परिणामों को देखते हैं, विश्लेषण करते हैं कि क्या काम किया और क्या नहीं, और अपनी रणनीतियों को इसी के अनुसार समायोजित करते हैं।
-
स्वायत्तता और लक्ष्य-निर्देशित व्यवहार
पारंपरिक ML मॉडल ऐसे उपकरण हैं जिन्हें मनुष्य विशिष्ट कार्यों को पूरा करने के लिए उपयोग करते हैं। वे स्वतंत्र रूप से लक्ष्यों का पीछा नहीं करते; वे केवल इनपुट को प्रोसेस करते हैं और सीखे गए पैटर्न के अनुसार आउटपुट उत्पन्न करते हैं। स्वयं-सीखने वाले एजेंट लक्ष्य-उन्मुख प्रणालियाँ हैं जो उच्च-स्तरीय लक्ष्य प्राप्त कर सकती हैं और उन्हें प्राप्त करने के लिए सर्वोत्तम कार्रवाई का पथ निर्धारित कर सकती हैं। वे जटिल लक्ष्यों को उप-कार्यों में विघटित करते हैं, उन उप-कार्यों को निष्पादित करते हैं, और प्रगति के आधार पर अपनी दृष्टिकोण को समायोजित करते हैं।
-
टूल उपयोग और पर्यावरणीय अन्योन्यक्रिया
स्वयं सीखने वाले एजेंट बाहरी उपकरणों, API और सॉफ्टवेयर प्रणालियों के साथ इंटरफेस कर सकते हैं। वे इंटरनेट ब्राउज़ कर सकते हैं, फाइलों को संशोधित कर सकते हैं, कोड निष्पादित कर सकते हैं और डेटाबेस के साथ बातचीत कर सकते हैं। पारंपरिक ML मॉडल आमतौर पर ऐसा नहीं कर सकते; वे केवल अपने स्वयं के कम्प्यूटेशन ग्राफ में प्राप्त इनपुट और उत्पन्न आउटपुट तक सीमित होते हैं।
-
संदर्भ समझ और योजना
जबकि पारंपरिक ML संरचित डेटा में पैटर्न पहचान में उत्कृष्ट है, स्वयं-सीखने वाले एजेंट संदर्भ को समझने और बहु-चरणीय समाधान योजना बनाने में उत्कृष्ट क्षमता प्रदर्शित करते हैं। एक ऐसा एजेंट जिसे यात्रा की योजना बनाने का लक्ष्य दिया गया हो, गंतव्यों की शोध करेगा, कीमतों की तुलना करेगा, उपलब्धता जांचेगा और व्यवस्थाएँ बुक करेगा—व्यवहार जो स्थिर वर्गीकरण मॉडल के लिए असंभव हैं।
मुख्य अंतर: स्व-सीखने वाले एआई एजेंट्स बनाम एलएलएम-आधारित एजेंट्स
स्व-सीखने वाले एआई एजेंट्स और वर्तमान एलएलएम-आधारित एजेंट्स के बीच का अंतर सूक्ष्म है लेकिन परिणामस्वरूप महत्वपूर्ण है। दोनों का उपयोग मुख्य घटकों के रूप में बड़े भाषा मॉडल कर सकते हैं, लेकिन उनकी आर्किटेक्चर और संचालन विधियाँ काफी अलग हैं।
-
प्रतिक्रियाशील बनाम प्राक्रमिक संचालन
अब तक के अधिकांश LLM-आधारित एजेंट प्रतिक्रियाशील प्रणालियाँ हैं जो प्रॉम्प्ट्स के जवाब में प्रतिक्रिया उत्पन्न करती हैं। एक उपयोगकर्ता एक प्रश्न पूछता है, और मॉडल एक उत्तर प्रदान करता है। हालाँकि, स्वयं-सीखने वाले एजेंट सक्रिय रूप से कार्य कर सकते हैं। एक लक्ष्य दिए जाने पर, वे प्रत्येक चरण पर मानव इनपुट का इंतजार किए बिना सूचना इकट्ठा करने, योजनाएँ बनाने और कार्रवाई करने की पहल करते हैं।
-
स्टेट प्रबंधन और मेमोरी
पारंपरिक LLM प्रत्येक बातचीत को अवस्थाहीन मानते हैं, हालांकि कुछ लागूकरण संदर्भ खिड़कियाँ जोड़ते हैं। स्वयं-सीखने वाले एजेंट सुविकसित स्मृति प्रणालियों को शामिल करते हैं जो सत्रों के भर में जानकारी को बनाए रखती हैं, लक्ष्यों की ओर प्रगति का अनुसरण करती हैं और पिछले अनुभवों से सीखने की सुविधा प्रदान करती हैं। यह स्थायी स्मृति एजेंट को प्रत्येक बातचीत के साथ नया आरंभ करने के बजाय पिछले कार्य पर आधारित काम करने की अनुमति देती है।
-
टूल एकीकरण और कार्रवाई निष्पादन
LLM-आधारित एजेंट मुख्य रूप से पाठ उत्पन्न करते हैं, भले ही वह पाठ कोड या कमांड्स को दर्शाए। स्व-सीखने वाले एजेंट इन कमांड्स को वास्तव में निष्पादित करने और बाहरी प्रणालियों के साथ बातचीत करने के लिए डिज़ाइन किए गए हैं। OpenAI का Operator और Claude का Computer Use इस दिशा में पहले कदम हैं, जो AI को ब्राउज़र, कमांड-लाइन इंटरफेस और सॉफ़्टवेयर अनुप्रयोगों को नियंत्रित करने में सक्षम बनाते हैं।
-
डायनामिक वर्कफ्लो अनुकूलन
जब एक LLM-आधारित एजेंट का सामना किसी बाधा से होता है, तो यह आमतौर पर विफल हो जाता है या एक त्रुटि संदेश प्रदान करता है। एक स्व-सीखने वाला एजेंट यह पहचान सकता है कि उसकी प्रारंभिक दृष्टिकोण काम नहीं कर रही है, कारण विश्लेषण कर सकता है, और अपनी रणनीति को गतिशील रूप से समायोजित कर सकता है। यह पुनरावृत्ति और अनुकूलन की क्षमता जटिल, वास्तविक-दुनिया के कार्यों को संभालने के लिए महत्वपूर्ण है, जो लगभग कभी योजना के अनुसार ही आगे नहीं बढ़ते।
स्व-अधिग्रहण करने वाले एजेंट्स की अर्चिटेक्चर
स्वयं सीखने वाले एजेंट्स को क्या अलग बनाता है, इसे समझने के लिए उनकी नींव की आर्किटेक्चर की जांच करना आवश्यक है। ये प्रणालियाँ कई घटकों को मिलाती हैं जो स्वायत्त, अनुकूलनयोग्य व्यवहार को सक्षम बनाने के लिए एक साथ काम करते हैं।
-
योजना और तर्क इंजन
एक स्वयं-सीखने वाले एजेंट के केंद्र में एक तर्कना इंजन होता है, जो आमतौर पर एक बड़े भाषा मॉडल द्वारा संचालित होता है, जो जटिल लक्ष्यों को कार्यान्वयन योग्य कदमों में विघटित कर सकता है। यह इंजन एजेंट को योजना बनाने, कारण-परिणाम के बारे में तर्क करने और संभावित कार्रवाइयों के परिणामों का मूल्यांकन करने में सक्षम बनाता है। माइक्रोसॉफ्ट के शोध के अनुसार, प्रशिक्षण विधियाँ और एजेंट क्षमताएँ सहयोगी प्रभाव पैदा कर सकती हैं, जिसमें सुधारित मॉडल अधिक प्रभावी एजेंट सक्षम बनाते हैं।
-
मेमोरी सिस्टम्स
स्व-अध्ययन एजेंट्स विभिन्न प्रकार की स्मृति रखते हैं: वर्तमान कार्यों के लिए अल्पकालिक कार्य स्मृति, स्थायी ज्ञान के लिए दीर्घकालिक स्मृति, और अतीत के अनुभवों के लिए घटनात्मक स्मृति। ये स्मृति प्रणालियाँ एजेंट्स को प्रतिक्रिया से सीखने, सफल रणनीतियों को याद रखने, और गलतियों को दोहराने से बचने की अनुमति देती हैं। इन स्मृति प्रणालियों की जटिलता सच्चे स्व-अध्ययन एजेंट्स को सरल प्रतिक्रियात्मक प्रणालियों से अलग करती है।
-
टूल उपयोग और API एकीकरण
एजेंट्स को बाहरी उपकरणों को कॉल करने, डेटाबेस तक पहुँचने, वेब ब्राउज़ करने और सॉफ्टवेयर अनुप्रयोगों के साथ बातचीत करने की क्षमता प्राप्त है। यह उपकरण उपयोग क्षमता एजेंट की पहुँच को केवल पाठ उत्पन्न करने से आगे, वास्तविक दुनिया की क्रियाओं तक विस्तारित करती है। एजेंट कार्य के आधार पर उपयुक्त उपकरणों का चयन कर सकता है, उपकरण कॉल्स को निष्पादित कर सकता है, और परिणामों को अपने तर्क में शामिल कर सकता है।
-
प्रतिक्रिया और अधिगम तंत्र
स्वयं सीखने वाले एजेंट्स की सबसे विशिष्ट विशेषता शायद अनुभव से सीखने की क्षमता है। जब कोई एजेंट किसी कार्य का प्रयास करता है, तो वह परिणाम का मूल्यांकन कर सकता है, पहचान सकता है कि क्या गलत हुआ, और भविष्य के प्रयासों के लिए अपनी दृष्टिकोण में सुधार कर सकता है। यह सीखना विभिन्न तंत्रों के माध्यम से हो सकता है, जिनमें प्रबलन सीखना, स्व-परावलोकन, और आवर्ती सुधार शामिल हैं।
वास्तविक दुनिया के अनुप्रयोग और परिणाम
स्व-सीखने वाले एआई एजेंट्स की अद्वितीय क्षमताएँ विभिन्न उद्योगों में नए अनुप्रयोगों को सक्षम बना रही हैं। माइक्रोसॉफ्ट रिपोर्ट करता है कि फॉर्च्यून 500 के लगभग 70% कर्मचारी पहले से ही माइक्रोसॉफ्ट 365 कोपिलट एजेंट्स का उपयोग ईमेल फिल्टरिंग और टीम्स सम्मेलनों के दौरान मीटिंग नोट्स लेने जैसे दोहराव वाले दैनिक कार्यों को संभालने के लिए कर रहे हैं।
आपूर्ति श्रृंखला प्रबंधन में, एजेंट पुराने डेटा और वास्तविक समय की जानकारी के आधार पर इन्वेंटरी मांग में बदलाव का अनुमान लगा सकते हैं, ताकि स्टॉकआउट या अतिरिक्त स्टॉक की स्थिति से बचा जा सके। स्वास्थ्य सेवा में, एजेंट मरीजों के मामलों का विश्लेषण कर सकते हैं, निदान के सुझाव प्रदान कर सकते हैं और चिकित्सा साहित्य और मरीज के रिकॉर्ड की विशाल मात्रा को प्रोसेस करके उपचार योजना में सहायता कर सकते हैं।
परिणाम केवल दक्षता में वृद्धि तक सीमित नहीं हैं। स्वयं-सीखने वाले एजेंट कार्य के ज्ञान के तरीके को बदल रहे हैं। मनुष्यों के AI उपकरणों का उपयोग सीखने के बजाय, यह प्रतिरूप AI एजेंट्स की ओर बदल रहा है जो मनुष्यों की सहायता करने के लिए सीखते हैं। यह मानव-AI संबंध में एक मौलिक बदलाव है, जहाँ मनुष्य उपकरणों का संचालन करने के बजाय स्वायत्त एजेंट्स की निगरानी करते हैं और उनके साथ सहयोग करते हैं।
संगठन एजेंट युग के लिए कैसे तैयार हो सकते हैं?
ऐसे संगठन जो स्वयं-सीखने वाले एआई एजेंट्स का लेवरेज लेना चाहते हैं, उन्हें उच्च मूल्य वाले उपयोग मामलों की पहचान करनी चाहिए, जहां एजेंट क्षमताएं पारंपरिक दृष्टिकोणों की तुलना में महत्वपूर्ण लाभ प्रदान कर सकती हैं। बहु-चरणीय प्रक्रियाओं, बाहरी प्रणाली समाकलन या गतिशील परिवेशों से संबंधित कार्य एजेंट तैनाती के लिए प्रमुख उम्मीदवार हैं।
तकनीकी बुनियादी ढांचे को एजेंट संचालन का समर्थन करने के लिए विकसित किया जाना चाहिए। इसमें मजबूत API एकीकरण, सुरक्षित उपकरण तक पहुंच, और एजेंट प्रदर्शन को ट्रैक करने और समस्याओं का पता लगाने में सक्षम मॉनिटरिंग प्रणालियाँ शामिल हैं। संगठनों को इस बात की गारंटी देने के लिए शासन ढांचे स्थापित करने चाहिए कि एजेंट स्वायत्तता के लिए उपयुक्त सीमाएँ परिभाषित की जाएँ, जबकि प्रासंगिक नियमों के अनुपालन को सुनिश्चित किया जाए।
जब ये प्रणालियाँ अधिक प्रचलित होती जाएँगी, तो संगठन भर में एजेंट साक्षरता में निवेश करना आवश्यक हो जाता है। कर्मचारियों को यह समझना होगा कि एजेंट कैसे काम करते हैं, कैसे प्रभावी मार्गदर्शन दिया जाए, और एजेंट आउटपुट का मूल्यांकन और सुधार कैसे किया जाए। इस परिवर्तन के लिए केवल तकनीकी निवेश ही नहीं, बल्कि सांस्कृतिक अनुकूलन भी आवश्यक है।
निष्कर्ष
स्वयं सीखने वाले AI एजेंट कृत्रिम बुद्धिमत्ता क्षमताओं में एक मौलिक उन्नति का प्रतिनिधित्व करते हैं। पारंपरिक मशीन लर्निंग मॉडलों के विपरीत, जो स्थिर और कार्य-विशिष्ट होते हैं, एजेंट स्वयं को अनुकूलित कर सकते हैं, योजना बना सकते हैं और जटिल प्रवाहों को स्वतंत्र रूप से निष्पादित कर सकते हैं। वर्तमान LLM-आधारित प्रणालियों की तुलना में, एजेंट सक्रिय संचालन, स्थायी स्मृति, और उपकरण एकीकरण के माध्यम से वास्तविक दुनिया की क्रियाएँ करने की क्षमता जोड़ते हैं।
प्रतिक्रियाशील AI से स्वायत्त एजेंट्स में जाने का परिवर्तन, संकीर्ण AI से सामान्य भाषा समझ में जाने जैसा एक परिप्रेक्ष्य परिवर्तन है। ऐसे संगठन जो इन अंतरों को समझते हैं और उसी के अनुसार तैयारी करते हैं, वे स्व-अधिग्रहणकारी एजेंट्स की रूपांतरकारी क्षमता का लाभ उठाने के लिए सर्वोत्तम स्थिति में होंगे। एजेंट युग आ रहा नहीं है—यह पहले से मौजूद है, जो काम करने के तरीके और AI क्या कर सकता है, इसे पुनर्गठित कर रहा है।
अक्सर पूछे जाने वाले प्रश्न
AI एजेंट और पारंपरिक मशीन लर्निंग मॉडल्स के बीच मुख्य अंतर क्या है?
पारंपरिक ML मॉडल ट्रेनिंग के दौरान पैटर्न सीखते हैं और नए इनपुट्स पर उन्हें स्थिर रूप से लागू करते हैं, जिससे अनुकूलन के लिए पुनः ट्रेनिंग की आवश्यकता होती है। स्वयं-सीखने वाले AI एजेंट अनुभव से लगातार सीख सकते हैं, नई स्थितियों के अनुसार अनुकूलित हो सकते हैं और निरंतर मानव हस्तक्षेप या पुनः ट्रेनिंग के बिना स्वतंत्र रूप से कार्य कर सकते हैं।
क्या स्व-सीखने वाले एआई एजेंट वर्तमान एलएलएम-आधारित चैटबॉट्स को बदल सकते हैं?
AI एजेंट और LLM अलग-अलग उद्देश्यों के लिए सेवा करते हैं और अक्सर प्रतिस्पर्धी के बजाय पूरक होते हैं। LLM भाषा समझ और उत्पादन में उत्कृष्ट होते हैं, जबकि एजेंट स्वायत्तता, कार्रवाई क्षमताओं और अनुकूलनयोग्य सीखने को जोड़ते हैं। कई एजेंट वास्तव में अपने तर्कने के इंजन के रूप में LLM का उपयोग करते हैं, जबकि योजना, स्मृति और उपकरणों के उपयोग के लिए परतें जोड़ते हैं।
क्या स्वयं सीखने वाले एआई एजेंट्स को पारंपरिक एमएल मॉडल्स की तुलना में अधिक कंप्यूटेशनल संसाधनों की आवश्यकता होती है?
स्वयं सीखने वाले एजेंट्स अक्सर अपनी जटिलता, लगातार अवस्था प्रबंधन और अक्सर बड़े आधारभूत मॉडल के कारण अधिक कंप्यूटेशनल संसाधनों की आवश्यकता होती है। हालाँकि, स्वायत्त संचालन और मानव निगरानी की कम आवश्यकता से प्राप्त दक्षता में वृद्धि कई अनुप्रयोगों में इन लागतों को कम कर सकती है।
स्वयं-सीखने वाले एजेंट त्रुटियों और विफलताओं को कैसे संभालते हैं?
स्वयं सीखने वाले एजेंट यह पहचान सकते हैं कि उनकी दृष्टिकोण काम नहीं कर रहा है, विफलता के कारणों का विश्लेषण कर सकते हैं और अपनी रणनीति को गतिशील रूप से समायोजित कर सकते हैं। यह आवर्ती सुधार क्षमता उन्हें स्थिर प्रणालियों की तुलना में अप्रत्याशित स्थितियों का प्रबंधन करने में बेहतर बनाती है, हालाँकि मजबूत त्रुटि प्रबंधन और मानवीय निगरानी महत्वपूर्ण बनी रहती है।
क्या स्वयं सीखने वाले एआई एजेंट व्यावसायिक उपयोग के लिए सुरक्षित हैं?
उचित गार्डरेल्स के साथ उचित रूप से डिज़ाइन किए गए, स्वयं-सीखने वाले एजेंट्स को व्यावसायिक परिवेशों में सुरक्षित रूप से लागू किया जा सकता है। संगठनों को एजेंट स्वायत्तता के लिए स्पष्ट सीमाएँ निर्धारित करनी चाहिए, मॉनिटरिंग प्रणालियाँ स्थापित करनी चाहिए और महत्वपूर्ण निर्णयों के लिए मानव नियंत्रण बनाए रखना चाहिए। कुंजी है—एजेंट क्षमताओं और उचित शासन ढांचों के बीच संतुलन बनाना।
डिस्क्लेमर: इस पेज का भाषांतर आपकी सुविधा के लिए AI तकनीक (GPT द्वारा संचालित) का इस्तेमाल करके किया गया है। सबसे सटीक जानकारी के लिए, मूल अंग्रेजी वर्जन देखें।