









Penulis asal: David, DeepTide TechFlow
Pada petang 20 Januari, X memperkenalkan algoritma penganjuran versi baharu.
Balasan yang disediakan oleh Musk agak menarik: "Kita tahu algoritma ini bodoh dan memerlukan perubahan besar, tetapi sekurang-kurangnya anda boleh melihat kita sedang berjuang untuk memperbaikinya secara langsung. Platform sosial lain tidak berani melakukan ini."
Pernyataan ini mempunyai dua maksud.Pertama, mengakui terdapat masalah dengan algoritma, dan kedua, menjadikan "kejelasan" sebagai ciri jual.
Ini adalah algoritma sumber terbuka kedua untuk X. Kod versi 2023 tidak dikemaskini selama tiga tahun dan sudah lama tidak selari dengan sistem sebenar. Kali ini sepenuhnya ditulis semula, model inti telah bertukar dari pembelajaran mesin tradisional kepada Grok transformer, dan kenyataan rasmi ialah "menyingkirkan sepenuhnya kejuruteraan ciri manual."
Sebelum ini, algoritma bergantung kepada jurutera untuk menetapkan parameter secara manual, tetapi kini AI boleh terus melihat sejarah interaksi anda untuk menentukan sama ada kandungan anda akan disyorkan atau tidak.
Ini bermakna buat kreator kandungan, mitos lama seperti "masa terbaik untuk berkongsi kandungan" atau "tag apa yang boleh menambah pengikut" mungkin tidak lagi berkesan.
Kami juga telah melihat melalui repositori Github yang terbuka, dengan bantuan AI, dan menemui beberapa logik keras yang tersembunyi dalam kod, yang patut dianalisis.
Perubahan logik algoritma: daripada ditentukan secara manual kepada penilaian automatik oleh AI
Katakan dengan jelas perbezaan antara versi lama dan baru terlebih dahulu, jangan tidak nanti perbincangan akan menjadi keliru.
Pada 2023, versi yang dinyahcangkakan oleh Twitter dikenali sebagai Heavy Ranker, secara asasnya adalah pembelajaran mesin tradisional. Jurutera perlu menentukan secara manual beratus-ratus "ciri": adakah mesej ini mempunyai imej, berapa banyak pengikut pengguna, berapa lama masa mesej dihantar dari sekarang, adakah mesej ini mempunyai pautan...
Kemudian beri setiap ciri berat, tukar-tukar, lihat kombinasi yang mana berkesan.
Versi terbuka sumber kali ini dikenali sebagai Phoenix, mempunyai arsitek yang sepenuhnya berbeza. Anda boleh memahaminya sebagai algoritma yang lebih bergantung kepada model AI yang besar, intinya menggunakan model transformer Grok, dan teknologi yang sama digunakan oleh ChatGPT dan Claude.
Dokumen README rasmi menulis dengan jelas: "Kami telah membuang setiap ciri yang direka secara manual."
Semua peraturan tradisional yang bergantung kepada ciri-ciri kandungan secara manual telah dihapuskan sepenuhnya.
Sekarang ini, algoritma ini mengandalkan apa untuk menentukan kandungan yang baik atau tidak?
Jawapannya bergantung kepada kamu.Siri tindakanApa yang pernah anda suka, siapa yang pernah anda balas, di mana post yang pernah anda tonton lebih dari dua minit, dan akaun jenis apa yang pernah anda sembunyikan. Phoenix memberi semua tindakan ini kepada transformer, membolehkan model itu sendiri mempelajari pola dan membuat kesimpulan.
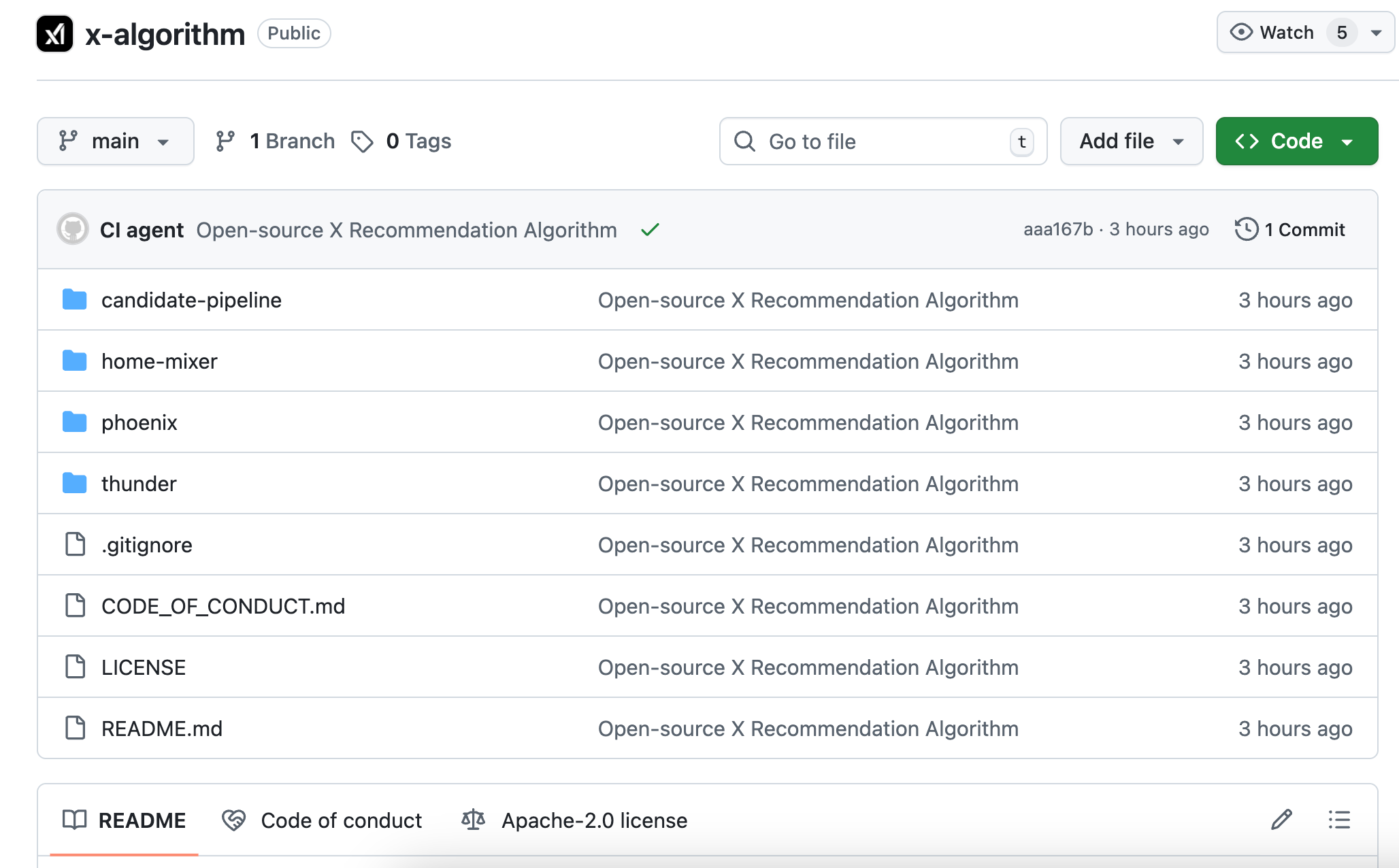
Sebagai contoh: algoritma lama seperti senarai markah yang disusun secara manual, setiap item diberi tanda dan dikira markahnya;
Algoritma baru ini seperti AI yang pernah melihat sejarah pelayaran anda,teka secara langsungApa yang anda mahu tonton pada saat seterusnya.
Ini bermakna dua perkara kepada pencipta:
Pertama, teknik lama seperti "masa pasang berkala terbaik" atau "tag emas" kini kurang relevan.Kerana model kini tidak lagi memandang ciri-ciri tetap ini, sebaliknya ia melihat keutamaan peribadi setiap pengguna.
Kedua, samada kandungan anda boleh disiarkan atau tidak semakin bergantung kepada "bagaimana orang yang melihat kandungan anda akan bertindak balas."Tindak balas ini dikuantifikasikan kepada 15 ramalan tingkah laku, yang akan kita bincangkan dengan lebih terperinci dalam bab seterusnya.
Algoritma Memprediksi 15 Tindak Balas Anda
Setelah Phoenix mendapat satu entri yang perlu disyorkan, sistem akan meramal 15 tindakan yang mungkin dilakukan oleh pengguna semasa melihat kandungan tersebut:
- Perilaku positif: seperti menyukai, membalas, memetik semula, memetik semula dengan rujukan, mengklik pos, mengklik halaman utama penulis, menonton lebih separuh video, memperluaskan imej, berkongsi, berhenti melihat selama tempoh tertentu, mengikuti penulis
- Perkara negatif: Klik 'Tidak Berminat', Blok Pengarang, Mute Pengarang, Laporan
Setiap tindakan berkaitan dengan satu kebarangkalian ramalan. Contohnya, model menentukan anda mempunyai kebarangkalian 60% untuk menyukai pos ini, kebarangkalian 5% untuk menyekat pengarang ini, dan sebagainya.
Kemudian algoritma melakukan sesuatu yang mudah: mengalikan kebarangkalian ini dengan pemberat masing-masing, menambahkannya, dan mendapat satu skor keseluruhan.
Formula seperti ini:
Jumlah Markah = Σ ( pemberat × P( tindakan ) )
Pemberat tingkah laku positif adalah nombor positif, dan pemberat tingkah laku negatif adalah nombor negatif.
Kandungan dengan jumlah skor yang tinggi akan dipaparkan di hadapan, manakala yang rendah akan tenggelam ke bawah.
Secara jujur, melangkah keluar dari formula itu sebenarnya bermaksud:
Kini, sama ada kandungan itu baik atau tidak, sebenarnya tidak lagi ditentukan oleh sama ada kandungan itu ditulis dengan baik atau tidak (tentu sahaja keterbacaan dan sifat membantu orang lain adalah asas kepada penyebaran); tetapi lebih banyak bergantung kepada "apakah tindak balas yang akan kandungan ini buatkan anda lakukan". Algoritma tidak kisah tentang kualiti entri itu sendiri, ia hanya mementingkan tingkah laku anda.
Dengan memikirkan perkara ini, dalam keadaan ekstrem, satu entri kandungan tidak berkualiti tetapi membangkitkan reaksi dan komen dari pengguna mungkin mendapat skor yang lebih tinggi berbanding satu entri berkualiti tinggi tetapi tiada interaksi. Ini mungkin logik asas sistem tersebut.
Namun, versi algoritma sumber terbuka yang terkini tidak mendedahkan nilai berat tingkah laku spesifik, tetapi versi 2023 telah mendedahkannya.
Rujukan versi lama: 1 aduan = 738 undian jempol
Seterusnya kita boleh mengupas data dari tahun 2023, walaupun agak lama, tetapi ia boleh membantu anda memahami perbezaan "nilai" pelbagai tindakan di sisi algoritma.
Pada 5 April 2023, X memang pernah mendedahkan satu set data berat di GitHub.
Langsung ke nombor:
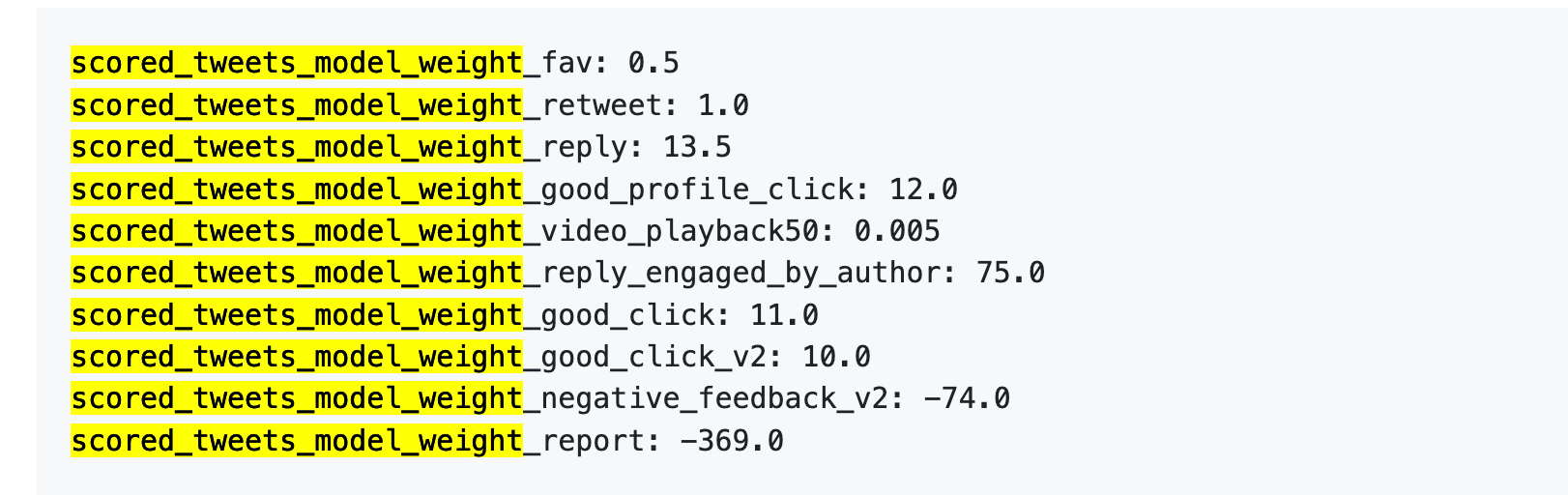
Terjemahkan dengan lebih jelas:
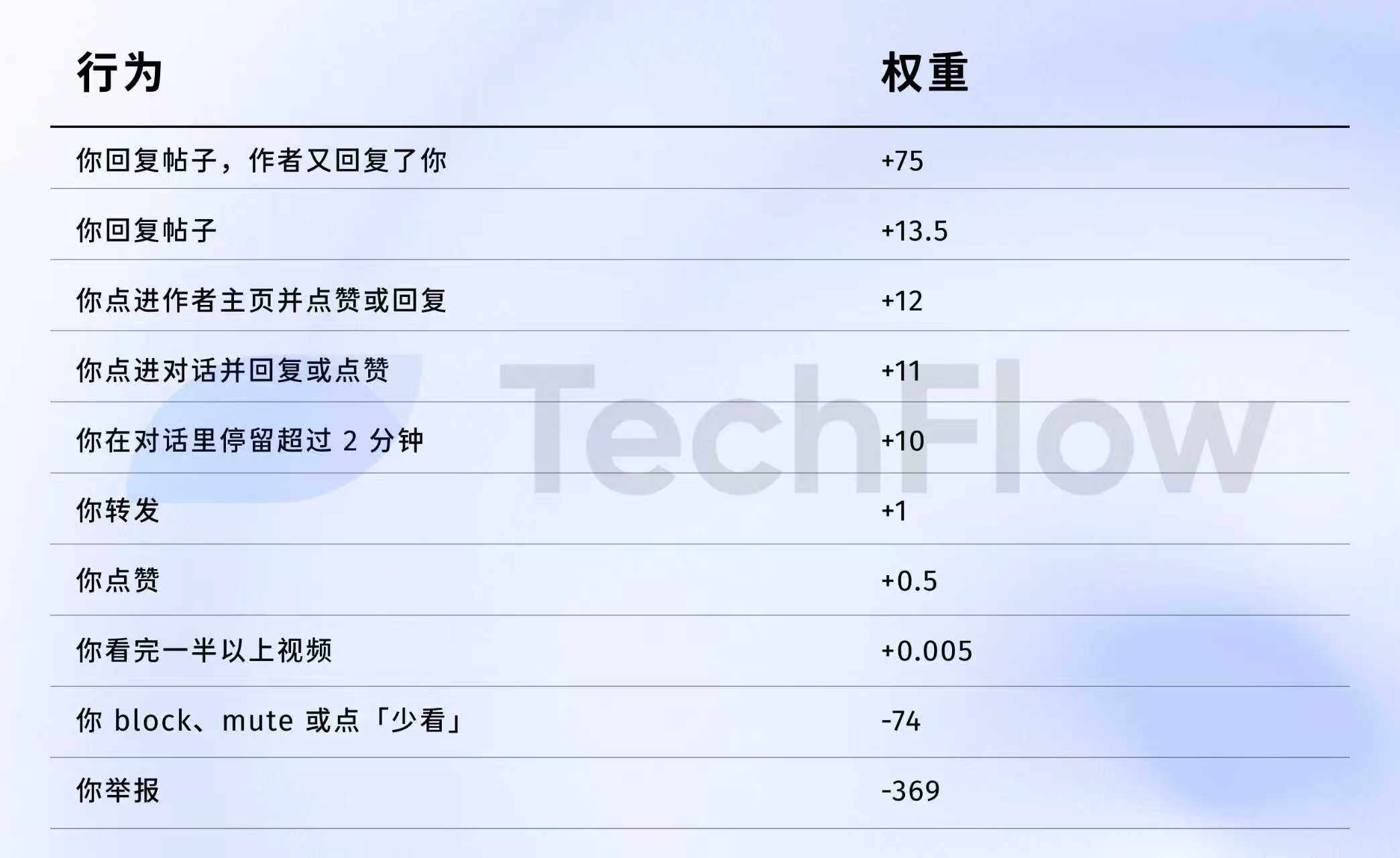
Sumber data: versi lama GitHub twitter/the-algorithm-ml repositori, klik untuk melihat algoritma asalnya.
Beberapa nombor patut diperhatikan dengan teliti.
Pertama, mesej jempol hampir tidak bernilai apa-apa. Pemberat hanya 0.5, yang paling rendah di antara semua tingkah laku positif. Dalam pandangan algoritma, nilai satu suka kira-kira bersamaan dengan sifar.
Kedua, interaksi perbualan sahajalah yang paling penting. Berat untuk ``anda menjawab, dan penulis menjawab semula'' ialah 75, iaitu 150 kali ganda daripada suka. Yang paling diingini oleh algoritma bukanlah pujian satu hala, tetapi perbualan dua hala.
Ketiga, kos untuk maklum balas negatif adalah sangat tinggi. Satu pengeboman atau penyahdiaman (-74) memerlukan 148 keklikan untuk menampakkan. Satu laporan (-369) memerlukan 738 keklikan. Dan markah negatif ini akan dikumpulkan ke dalam reputasi akaun anda, kesan penghantaran semua pos seterusnya.
Keempat, pemberat kadar tontonan video habis ditonton adalah terlalu rendah. Hanya 0.005, hampir boleh diabaikan. Ini membentuk kontras yang ketara dengan Douyin dan TikTok, dua platform tersebut menjadikan kadar tontonan habis sebagai indeks utama.
Pihak rasmi juga menulis dalam dokumen yang sama: "Pemberat tepat dalam fail boleh disesuaikan bila-bila masa... Sejak itu, kami telah secara berkala menyesuaikan pemberat tersebut untuk mengoptimumkan metrik platform."
Ketumpatan boleh diubah bila-bila masa dan memang telah diubah sebelum ini.
Versi baharu tidak mendedahkan nilai spesifik, tetapi kerangka logik yang ditulis dalam README adalah sama: tambah markah positif, tolak markah negatif, jumlahkan dengan pemberat.
Nombor sebenar mungkin berubah, tetapi hubungan magnitud kebarangkalian masih ada. Membalas komen orang lain lebih bermanfaat berbanding menerima 100 kekaguman. Membuatkan orang mahu memblok anda lebih teruk berbanding tiada interaksi langsung.
Setelah mengetahui ini, apakah yang boleh kami, para pencipta lakukan?
Analisis kod algoritma lama dan baru Twitter, dan menarik beberapa kesimpulan yang boleh diaplikasikan.
1. Menjawab pengulas anda. Dalam jadual pemberat, "penulis membalas komen" adalah item paling tinggi (+75), iaitu 150 kali ganda lebih tinggi daripada pihak pengguna hanya memberi jempol. Ia bukan bermaksud meminta komen, tetapi jika seseorang memberi komen, balaslah. Walaupun hanya menjawab "terima kasih", algoritma akan merekodkannya.
2. Jangan biarkan orang mahu pergi. Satu kali penggunaan blok memerlukan 148 kali kekaguman untuk menampung kesan negatifnya. Kandungan kontroversial memang mudah membangkitkan interaksi, tetapi jika bentuk interaksinya ialah "Orang ini menyusahkan, blok", skor reputasi akaun anda akan terus terjejas, mempengaruhi pengedaran semua pos seterusnya. Aliran kontroversi adalah pedang bermata dua, potong diri sendiri sebelum memotong orang lain.
3. Tautan luar diletakkan di ruangan komen.Algoritma tidak mahu mengalihkan pengguna ke luar laman web. Teks bersama pautan akan dikurangkan keutamaannya.Musk sendiri pernah menyatakannya secara terbuka. Jika mahu mengalihkan trafik, tulis kandungan dalam badan utama, dan letakkan pautan di komen pertama.
4. Jangan spam. Kod versi baharu mempunyai Author Diversity Scorer, yang berfungsi menurunkan kepentingan pos yang muncul secara berturut-turut dari penulis yang sama. Niat reka bentuknya ialah membuatkan feed pengguna lebih pelbagai, kesan sampingannya ialah memaparkan sepuluh pos secara berturut-turut tidak sebaik memaparkan satu pos berkualiti.
6. Tiada lagi "masa terbaik untuk berkongsi kandungan". Algoritma lama mempunyai ciri buatan seperti "masa penerbitan", tetapi versi baharu terus membuangnya. Phoenix hanya memerhatikan jujukan tingkah laku pengguna, dan tidak memandang masa di mana sesuatu kiriman diterbitkan. Strategi-strategi seperti "kesan terbaik apabila menerbitkan kiriman pada pukul tiga petang setiap hari Selasa" semakin kehilangan nilai rujukannya.
Di atas adalah perkara-perkara yang boleh dilihat pada peringkat kod.
Terdapat juga beberapa item tambahan dan pengurangan yang berasal daripada dokumen awam X, yang tidak terdapat dalam repositori sumber terbuka kali ini: pengiktirafan biru menambah kelebihan, semua huruf besar akan dikurangkan kepentingannya, dan kandungan sensitif memicu pengurangan 80% kadar capaian. Kebanyakan peraturan ini tidak dibuka sumbernya, jadi saya tidak akan mengembangkannya lagi.
Secara keseluruhannya, benda yang dikeluarkan kali ini agak memuaskan.
Senarai lengkap arsitek sistem, logik pemanggilan kandungan calon, proses pengelasan dan penilaian, pelaksanaan pelbagai penapis. Kod utamanya adalah Rust dan Python, struktur jelas, README ditulis lebih terperinci berbanding banyak projek komersial.
Tetapi beberapa perkara penting tidak dikeluarkan.
1. Parameter pemberat tidak dikongsi. Kod hanya menyatakan "tindakan positif menambah skor, tindakan negatif mengurangkan skor", tetapi tidak menyebutkan berapa banyak skor yang ditambahkan untuk setiap pujian, atau berapa banyak skor yang dikurangkan apabila disekat. Versi 2023 sekurang-kurangnya mendedahkan nombornya, tetapi kali ini hanya memberi kerangka formula.
2. Pemberat model tidak dikongsi. Phoenix menggunakan Grok transformer, tetapi parameter sebenar model tidak dinyatakan. Anda boleh lihat bagaimana model itu dipanggil, tetapi tidak dapat melihat bagaimana pengiraan dalaman model dilakukan.
3. Data latih tidak dikongsi. Tiada maklumat diberikan mengenai data apakah model ini dilatihkan, bagaimana sampel tingkah laku pengguna diambil, dan bagaimana sampel positif dan negatif dibina.
Sebagai contoh, kali ini sumber terbuka seolah-olah berkata kepada kamu "kami menggunakan jumlah keseluruhan dengan jumlah tertimbang", tetapi tidak memberitahu kamu berapa pemberatnya; memberitahu kamu "kami menggunakan transformer untuk meramal kebarangkalian tindakan", tetapi tidak memberitahu kamu bagaimana bentuk transformer itu.
Secara membandingkan secara mendatar, TikTok dan Instagram pun tidak pernah mendedahkan maklumat sebegini. Jumlah maklumat sumber terbuka yang diberikan oleh X kali ini memang lebih banyak berbanding platform utama yang lain. Namun, ia masih jauh daripada "kejelasan sepenuhnya".
Ini bukan bermakna sumber terbuka tiada nilai. Bagi pencipta dan penyelidik, lebih baik melihat kod berbanding tidak dapat melihat langsung.