









Penulis:Tina, DongmeiInfoQ
1. Selepas hampir tiga tahun, Musk sekali lagi membuakannya algoritma syorkan X.
Baru-baru ini, pasukan kejuruteraan X membuat kekabaran di X mengumumkan bahawa algoritma cadangan X secara rasminya telah dibuka sumber. Menurut penerangan, pustaka sumber terbuka ini mengandungi sistem cadangan utama yang menyokong aliran maklumat "Cadangan untuk Anda" di X. Ia menggabungkan kandungan dalam rangkaian (daripada akaun yang diikuti oleh pengguna) dengan kandungan luar rangkaian (ditemui melalui penjelajahan berdasarkan pembelajaran mesin), dan menggunakan model Transformer berdasarkan Grok untuk menentukan kedudukan semua kandungan. Dengan kata lain, algoritma ini menggunakan arsitektur Transformer yang sama seperti Grok.
Alamat sumber terbuka: https://x.com/XEng/status/2013471689087086804
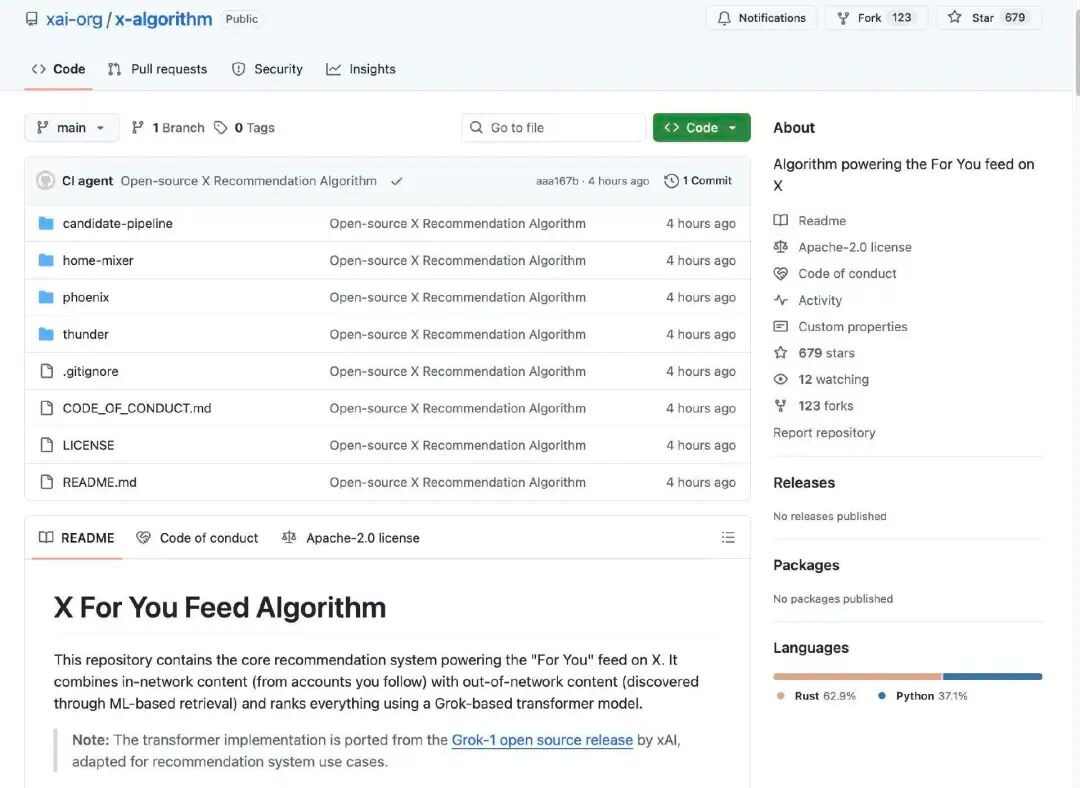
Algoritma cadangan X bertanggungjawab untuk menghasilkan kandungan yang pengguna lihat di muka utama mereka.Kandungan "Pelanjutan untuk Anda" (For You Feed)Ia mendapatkan pasangan daripada dua sumber utama:
Akaun yang anda ikuti (In-Network / Thunder)
Catatan lain yang ditemui di platform (Out-of-Network / Phoenix)
Kandungan-kandungan ini kemudian diproses secara seragam, disaring dan disusun mengikut ke relevannya.
Jadi, apakah struktur dan logik operasi inti algoritma ini?
Algoritma terlebih dahulu menangkap kandungan calon dari dua sumber:
Kandungan yang diikuti: pos yang diterbitkan oleh akaun yang anda ikuti secara aktif.
Kandungan bukan pihak berkecuali: pos yang mungkin menarik minat anda yang ditemui oleh sistem dari seluruh perpustakaan kandungan.
Tujuan pada peringkat ini ialah "mencari dan menemui pos yang berkemungkinan berkaitan."
Sistem secara automatik membuang kandungan berkualiti rendah, berulang, melanggar peraturan atau tidak sesuai. Contohnya:
Kandungan akaun yang disekat
Topik yang jelas tidak menarik minat pengguna
Paparan yang tidak sah, usang atau tidak sah
Ini memastikan kandungan calon yang berharga sahaja diproses semasa pengelasan akhir.
Inti algoritma yang dinyahcangkakan kali ini ialah sistem menggunakan model Transformer berasaskan Grok (sama ada model bahasa besar atau rangkaian pembelajaran dalam) untuk memberi skor kepada setiap pos cadangan. Model Transformer meramal kebarangkalian setiap tindakan berdasarkan sejarah pengguna (suka, balas, kongsikan, klik, dll.). Pada akhirnya, kebarangkalian tindakan ini dikombinasi secara tertimbang untuk membentuk skor komprehensif, dan pos dengan skor yang lebih tinggi lebih mungkin disyorkan kepada pengguna.
Reka bentuk ini secara asasnya membuang kaedah mengekstrak ciri secara manual tradisional, dan menggunakan kaedah pembelajaran hujung-ke-hujung untuk meramal minat pengguna.
Ini bukanlah kali pertama Musk membuang algoritma syorkan X ke sumber terbuka.
Pada 31 Mac 2023, seperti yang dijanjikan oleh Musk ketika beliau membeli Twitter, beliau secara rasmi telah membuang sumber kod asal Twitter, termasuk algoritma yang digunakan untuk menyarankan tweet dalam talian masa pengguna.Pada hari sumber terbuka, projek ini telah menerima 10k+ bintang di GitHub.
Pada masa itu, Musk telah menyatakan di Twitter bahawa pelancungan ini ialah"Kebanyakan algoritma penganjuran"Algoritma yang lain juga akan diperkenalkan secara beransur-ansur. Beliau juga menyatakan, beliau berharap "pemegang kepentingan pihak ketiga yang bebas boleh menentukan dengan kejituan yang munasabah kandungan yang mungkin ditunjukkan oleh Twitter kepada pengguna."
Dalam perbincangan Space mengenai pelancaran algoritma, beliau berkata bahawa tujuan pelan sumber terbuka ini adalah untuk menjadikan Twitter sebagai "sistem paling telus di internet" dan menjadikannya sekuat projek sumber terbuka Linux yang paling terkenal dan berjaya. "Matlamat keseluruhannya ialah supaya pengguna yang terus menyokong Twitter dapat menikmati platform ini sebanyak mungkin."
Kini hampir tiga tahun selepas Musk memulakan sumber terbuka untuk algoritma X. Sebagai KOL teknologi yang hebat, Musk sudah lama mempromosikan sumber terbuka kali ini dengan penuh.
Pada 11 Januari, Musk memposting di X bahawa beliau akan membuangkan sumber kod baru X (termasuk semua kod yang digunakan untuk menentukan kandungan carian semula jadi dan iklan yang disyorkan kepada pengguna) dalam 7 hari.
Proses ini akan diulang setiap 4 minggu dan disertakan dengan penerangan terperinci untuk pembangun, bagi membantu pengguna memahami perubahan yang berlaku.
Hari ini, janjinya sekali lagi dipenuhi.
2. Mengapakah Musk mahu sumber terbuka?
Apabila Elon Musk menyebut "sumber terbuka" sekali lagi, tindak balas pertama dari luar bukanlah idealisme teknikal, tetapi tekanan kenyataan.
Dalam setahun yang lalu, X sering terlibat kontroversi berkenaan mekanisme pengedaran kandungan mereka. Platform ini selalu dikritik hebat kerana algoritma mereka yang dikatakan memihak dan memperkuatkan pandangan kanan, dan kecenderungan ini bukan sekadar kes-kes sporadik, tetapi dianggap mempunyai ciri sistemik. Satu laporan kajian yang dikeluarkan tahun lepas menunjukkan bahawa sistem syorkan X menunjukkan prejudis politik yang jelas dalam penyebaran kandungan.
Pada masa yang sama, beberapa kes ekstrem telah memperburuk lagi kebimbangan luar. Tahun lepas, satu video yang tidak disemak yang melibatkan pembunuhan aktivis kanan Amerika Syarikat, Charlie Kirk, menyebar dengan cepat di platform X, mencetuskan kegemparan di kalangan pendapat awam. Kritikus berpendapat, ini bukan sahaja menzahirkan kegagalan mekanisme semakan platform, tetapi juga sekali lagi menyoroti algoritma dalam "memperbesar apa yang patut dan tidak patut diperbesar". Kuasa tersirat.
Dalam konteks ini, tiba-tiba Musk menekankan kejelasan algoritma, mustahil diterjemahkan sebagai keputusan teknikal yang murni.

3. Apa kata pengguna internet?
Selepas algoritma cadangan X dibuka sumbernya, terdapat pengguna di platform X yang membuat lima kesimpulan berikut mengenai mekanisme algoritma cadangan:
- Balas komen andaAlgoritma memberi pemberat sebanyak 75 kali ganda daripada butang suka kepada "balasan + tindak balas penulis". Tidak membalas komen akan mempengaruhi jangkauan secara besar-besaran.
- Pautan akan mengurangkan jangkauan.Sila letakkan pautan dalam profil peribadi atau di dalam utama, jangan sesekali letakkan pautan dalam kandungan utama.
- Jumlah tontonan adalah yang paling penting.Jika mereka menggelongsorkan skrin untuk melompatinya, anda tidak akan dapat menarik perhatian mereka. Video / pos hanya dapat mendapat perhatian yang tinggi kerana mereka dapat membuat pengguna berhenti.
- Bersikap setia kepada bidangmu"Kumpulan simulasi" adalah nyata. Jika anda menyimpang dari bidang khusus anda (kripto, teknologi dll), anda tidak akan mendapat apa-apa dari saluran pengedaran.
- Menyekat / Berdiam diri akan secara besar-besaran mengurangkan skor anda.Ia perlu membangkitkan kontroversi, tetapi jangan menyakitkan hati.
Secara ringkas: berkomunikasi dengan audiens anda, bina hubungan, dan tahan pengguna di dalam aplikasi. Ia sebenarnya sangat mudah.
Pengguna internet juga telah menyedari bahawa walaupun struktur adalah sumber terbuka, masih ada kandungan yang belum dibuka. Pengguna ini berkata, pelancaran kali ini pada dasarnya adalah sebuah rangka kerja tanpa enjin. Apa yang sebenarnya kurang?
Tiada parameter pemberat diberikan. - Kod mengesahkannya sebagai "markah tambah untuk tingkah laku positif" dan "markah tolak untuk tingkah laku negatif", tetapi berbeza dengan versi 2023, nilai spesifiknya telah dihapuskan.
Sembunyikan pemberat model - Tidak termasuk parameter dalaman dan pengiraan model itu sendiri.
Data latih yang tidak dinyatakan secara rasmi - Kami tidak tahu apa-apa mengenai data yang digunakan untuk melatih model, kaedah pengambilan sampel tingkah laku pengguna, dan bagaimana membangunkan sampel "baik" dan sampel "buruk".
Bagi pengguna X biasa, pendedahan algoritma X sebagai sumber terbuka tidak akan menyebabkan kesan yang besar. Namun, keupayaan keterbukaan yang lebih tinggi dapat menerangkan mengapa sesetengah pasangan mendapat paparan manakala yang lain tidak, dan membolehkan penyelidik mengkaji bagaimana platform menetapkan kedudukan kandungan.
4. Mengapakah sistem penganjuran disarankan menjadi kawasan pertandingan yang penting?
Dalam kebanyakan perbincangan teknikal,Sistem PencadanganBiasanya dianggap sebagai sebahagian daripada kejuruteraan belakang, rendah keyakinan, kompleks, dan jarang berada di bawah sorotan. Tetapi jika kita benar-benar mengupas bagaimana syarikat gergasi internet beroperasi secara komersial, kita akan mendapati sistem cadangan bukanlah modul pinggir, tetapi sebaliknya merupakan "kewujudan infrastruktur" yang menyokong keseluruhan model perniagaan. Oleh itu, ia boleh dianggap sebagai "haiwan besar yang senyap" dalam industri internet.
Data awam telah berkali-kali mengesahkan perkara ini. Amazon pernah mendedahkan bahawa kira-kira 35% daripada pembelian di platformnya secara langsung datang daripada sistem penganjuran; Netflix lebih radikal, kira-kira 80% daripada masa tontonan dikuasai oleh algoritma penganjuran; keadaan di YouTube juga serupa, kira-kira 70% daripada tontonan berasal daripada sistem penganjuran, terutamanya aliran kandungan (feed). Bagi Meta, walaupun mereka tidak pernah memberi nisbah yang jelas, pasukan teknikal mereka pernah menyatakan kira-kira 80% daripada siklus kuasa pengiraan dalam kumpulan pengiraan dalaman syarikat digunakan untuk tugas-tugas penganjuran.
Apa maksud nombor-nombor ini?Jika sistem pangsikan daripada produk-produk ini, hampir setara dengan mengeluarkan asasnya.Ambil Meta sebagai contoh, penempatan iklan, jangka masa penggunaan, dan penjanaan keuntungan perniagaan hampir sepenuhnya bergantung kepada sistem syor. Sistem syor bukan sahaja menentukan apa yang dilihat oleh pengguna, tetapi lebih langsung menentukan bagaimana platform menjana pendapatan.
Namun, sistem yang menentukan antara hidup dan mati ini sendiri telah lama menghadapi masalah kekompleksan kejuruteraan yang sangat tinggi.
Dalam arsitek sukan sistem penganjuran tradisional, mustahil untuk menampung semua senario dengan satu model yang seragam. Sistem pengeluaran di dunia nyata biasanya sangat terpecah. Ambil contoh syarikat seperti Meta, LinkedIn, dan Netflix, biasanya terdapat 30 model khas atau lebih yang berjalan serentak di belakang satu rantai penganjuran lengkap: model panggilan semula, model penyusunan kasar, model penyusunan teliti, model penyusunan semula, masing-masing dioptimumkan untuk fungsi objektif dan matlamat perniagaan yang berbeza. Setiap model biasanya berkaitan dengan satu atau lebih pasukan yang bertanggungjawab untuk kejuruteraan ciri, latihan, kala suai, pelancaran, dan iterasi berterusan.
Kos yang dikenakan oleh mod ini adalah jelas: kekompleksan kejuruteraan, kos pengurusan yang tinggi, dan kesukaran dalam kerjasama antara tugas. Sekiranya sesiapa sahaja mengemukakan soalan "Adakah satu model boleh menyelesaikan pelbagai masalah pengesyorkan?", ini bermakna pengurangan magnitud kekompleksan keseluruhan sistem. Ini adalah matlamat yang selama ini diingini oleh industri tetapi sukar dicapai.
Kemunculan model bahasa yang besar telah membuka jalan baru yang mungkin untuk sistem penganjuran.
LLM telah membuktikan dalam praktiknya bahawa ia boleh menjadi model umum yang sangat kuat: mempunyai keupayaan untuk berpindah antara tugas-tugas yang berbeza, dan prestasinya juga boleh ditingkatkan secara berterusan apabila skala data dan kapasiti pengiraan diperluaskan. Sebaliknya, model perekomendasi tradisional biasanya "dikhususkan untuk tugas tertentu", dan sukar berkongsi keupayaan antara pelbagai skenario.
Lebih penting lagi, model tunggal bukan sahaja menyederhanakan aspek kejuruteraan, tetapi juga membawa potensi "pembelajaran silang". Apabila model yang sama menangani pelbagai tugas pengesyorkan serentak, isyarat daripada tugas-tugas berbeza boleh saling melengkapi antara satu sama lain, dan apabila saiz data berkembang, model ini lebih mudah berkembang secara keseluruhannya. Ini adalah ciri yang selama ini dicari oleh sistem pengesyorkan, tetapi sukar dicapai melalui kaedah tradisional.
LLM telah menukar apa? Ia sebenarnya telah menukar dari kejuruteraan ciri kepada keupayaan memahami.
Secara metodologi, perubahan terbesar yang berlaku dalam sistem beresyorkan disebabkan oleh LLM berlaku pada aspek "jurutera ciri" yang menjadi inti.
Dalam sistem perekomendasi tradisional, jurutera perlu membina sejumlah besar isyarat secara manual: sejarah klik pengguna, tempoh masa penggunaan, kecenderungan pengguna yang serupa, tag kandungan dan sebagainya, kemudian memberitahu model secara jelas "sila membuat keputusan berdasarkan ciri-ciri ini". Model itu sendiri tidak memahami semantik isyarat ini, hanya belajar hubungan peta dalam ruang nombor.
Dengan pengenalan model bahasa, proses ini menjadi sangat abstrak. Anda tidak lagi perlu menentukan satu persatu "perhatikan isyarat ini, abaikan isyarat itu", tetapi sebaliknya, anda boleh terus menghuraikan masalah kepada model: ini adalah seorang pengguna, ini adalah kandungan; pengguna ini sebelumnya menyukai kandungan yang serupa, pengguna lain juga memberi maklum balas positif terhadap kandungan ini - sekarang sila tentukan, adakah kandungan ini patut disyorkan kepada pengguna ini?
Model bahasa itu sendiri sudah mempunyai keupayaan memahami, ia boleh menentukan sendiri maklumat mana yang merupakan isyarat penting, dan bagaimana menyelaraskan isyarat-isyarat ini untuk membuat keputusan. Dalam erti kata tertentu, ia bukan sahaja melaksanakan peraturan penganjuran, tetapi sebenarnya "memahami perkara penganjuran ini".
Sumber keupayaan ini terletak pada fakta bahawa LLM telah terdedah kepada data yang besar dan pelbagai semasa fasa latihan, menjadikannya lebih mudah untuk menangkap corak-corak halus tetapi penting. Sebaliknya, sistem perekomendasi tradisional mesti bergantung kepada jurutera untuk secara eksplisit menyenaraikan corak-corak ini, dan sekiranya terlepas, model tidak akan dapat mengesan.
Secara perspektif backend, perubahan ini tidak asing. Seperti apabila anda bertanya kepada GPT, ia akan menjana jawapan berdasarkan maklumat konteks; dengan cara yang sama, apabila anda bertanya kepada ia "adakah saya akan berminat dengan kandungan ini", ia juga boleh membuat penilaian berdasarkan maklumat yang sedia ada. Pada suatu tahap, model bahasa itu sendiri sebenarnya sudah mempunyai keupayaan "perekomendasi" secara semula jadi.