










Bayangkan adegan ini:
Anda meminta AI Agent untuk membaiki ralat kod. Ia membuka projek, membaca 20 fail, membuat beberapa perubahan, menjalankan ujian, gagal, membaiki semula, menjalankan semula, masih gagal... Berulang kali mencuba selama belasan pusingan, akhirnya—masih belum dibaiki.
Anda mematikan komputer dan bernafas lega. Kemudian menerima bil API.
Nombor di atas mungkin membuat anda terkesima—AI Agent yang memperbaiki ralat secara autonomi di API rasmi luar negara sering membakar lebih daripada satu juta Token semasa tugas yang tidak diperbaiki, dengan kos sehingga puluhan hingga lebih seratus dolar.
Pada April 2026, sebuah kertas penyelidikan yang diterbitkan secara bersama oleh Stanford, MIT, dan Universiti Michigan membuka secara sistematik “kotak hitam” penggunaan AI Agent dalam tugas kod—di mana duit dibelanjakan, adakah ia bernilai, dan sama ada ia boleh diramal sebelumnya—jawapannya mengejutkan.
Penemuan satu: Kadar perbelanjaan Agent dalam menulis kod adalah 1000 kali ganda berbanding perbualan AI biasa.
Orang mungkin berfikir, meminta AI menulis kod untuk anda dan berbual dengan AI mengenai kod sepatutnya menghabiskan wang yang hampir sama.
Kertas kerja memberikan perbandingan yang menunjukkan:
Penggunaan token untuk tugas pengkodean Agentic adalah sekitar 1000 kali ganda berbanding tugas soal jawab kod dan penalaran kod biasa.
Beda sebanyak tiga peringkat sepuluh.
Mengapa ini berlaku? Kertas kerja tersebut menunjukkan satu fakta—wang tidak dibelanjakan untuk “menulis kod”, tetapi dibelanjakan untuk “membaca kod”.
Di sini, “membaca” bukan merujuk kepada manusia membaca kod, tetapi Agent perlu secara berterusan “memberi” seluruh konteks projek, rekod operasi sejarah, maklumat ralat, dan kandungan fail kepada model semasa proses kerjanya. Setiap putaran dialog tambahan akan membuat konteks ini menjadi lebih panjang; dan model dikenakan bayaran berdasarkan jumlah Token — semakin banyak yang anda berikan, semakin banyak yang perlu anda bayar.
Sebagai perbandingan: Ini seperti mempekerjakan seorang tukang servis yang meminta anda membacakan seluruh rencana bangunan dari awal kepadanya sebelum setiap kali ia memutar kunci pas—biaya membaca rencana jauh lebih mahal daripada biaya memutar sekrup.
Kertas ini merumuskan fenomena ini dalam satu ayat: Kos agen didorong oleh pertumbuhan eksponen token input, bukan token output.
Penemuan dua: Bug yang sama, dijalankan dua kali, kosnya boleh berbeza dua kali ganda—dan semakin mahal bug tersebut, semakin tidak stabil
Yang lebih membingungkan ialah kerawakan.
Penyelidik menjalankan Agent yang sama pada tugas yang sama sebanyak 4 kali, dan mendapati:
- Di antara tugas-tugas yang berbeza, tugas paling mahal membakar sebanyak 7 juta Token lebih banyak berbanding tugas paling murah (Rajah 2a)
- Dalam beberapa larian yang sama pada model dan tugas yang sama, larian paling mahal adalah kira-kira dua kali ganda larian paling murah (Rajah 2b)
- Sementara itu, jika membandingkan tugas yang sama di antara model yang berbeza, perbezaan antara penggunaan tertinggi dan terendah boleh mencapai sehingga 30 kali ganda.
Nombor terakhir ini patut diperhatikan khususnya: ini bermakna, perbezaan kos antara memilih model yang betul dan model yang salah bukan sekadar "sedikit lebih mahal", tetapi "lebih mahal satu peringkat".
Yang lebih menyakitkan lagi—berbelanja banyak tidak bermakna melakukan dengan baik.
Kajian menemui satu lengkung "berbentuk U terbalik":
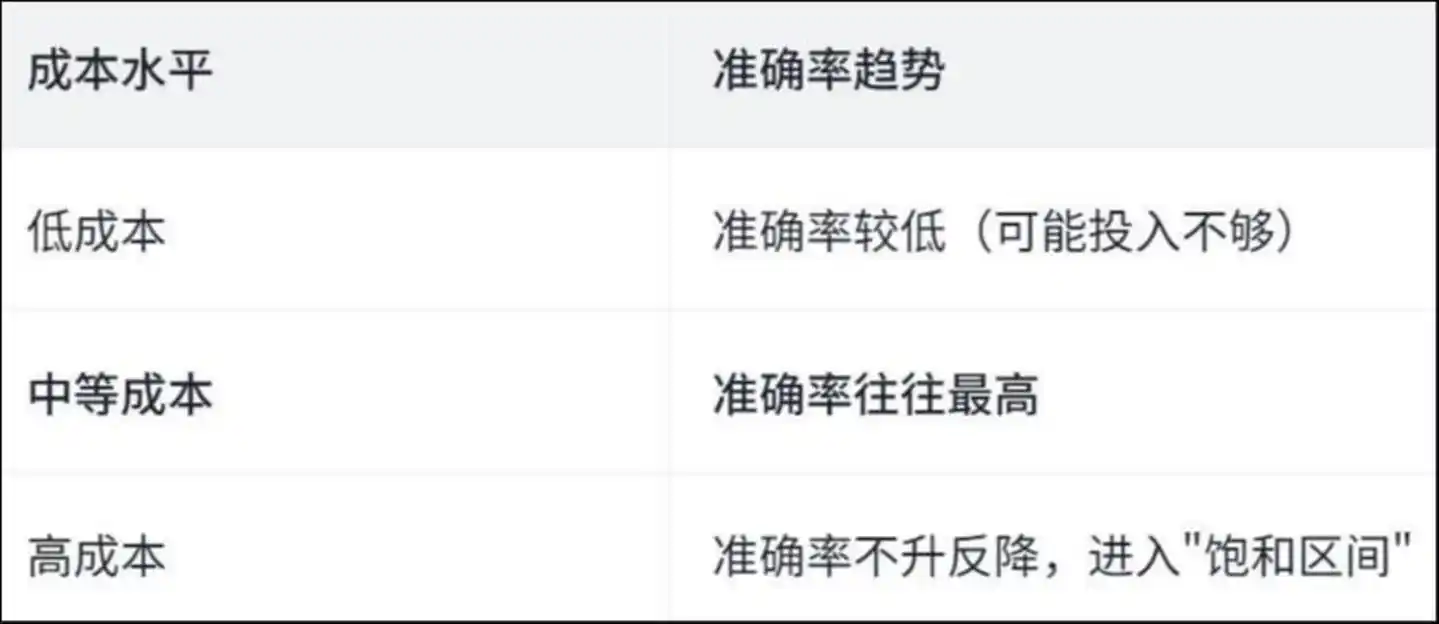
Trend ketepatan tahap kos: Kos rendah, ketepatan rendah (mungkin investasi tidak mencukupi); Kos sederhana, ketepatan biasanya paling tinggi; Kos tinggi, ketepatan tidak meningkat malah menurun, memasuki "zona jenuh"
Mengapa ini berlaku? Kertas kerja ini memberikan jawapan melalui analisis operasi spesifik Agen—
Dalam operasi berkos tinggi, agen menghabiskan banyak masa pada "kerja berulang".
Kajian mendapati bahawa sekitar 50% operasi melihat dan mengubah fail dalam pengoperasian berkos tinggi adalah berulang—iaitu, Agen membaca fail yang sama berulang kali dan mengubah baris kod yang sama berulang kali, seperti seseorang yang berputar-putar di dalam ruangan, semakin berputar semakin pening, semakin pening semakin berputar.
Duit tidak dibelanjakan untuk menyelesaikan masalah, tetapi dibelanjakan untuk “ tersesat”.
Penemuan Tiga: "Kefektifan tenaga" antara model berbeza secara drastik—GPT-5 paling menjimatkan, beberapa model menghabiskan hingga 1.5 juta token lebih banyak
Kertas kerja ini menguji prestasi 8 model besar terkini sebagai agen pada SWE-bench Verified, yang mengikuti piawaian industri (500 isu GitHub sebenar). Dalam istilah dolar, model dengan kecekapan token yang tinggi boleh menghabiskan puluhan dolar tambahan setiap tugas. Dalam konteks aplikasi perniagaan—di mana ratusan tugas dijalankan sehari—perbezaan ini menjadi wang benar.
Satu penemuan yang lebih menarik ialah: Kecekapan Token adalah "sifat asli" model, bukan disebabkan oleh tugas.
Penyelidik memisahkan tugas yang semua model berjaya selesaikan (230 tugas) dan tugas yang semua model gagal selesaikan (100 tugas) untuk dibandingkan, dan mendapati kedudukan relatif model hampir tidak berubah.
Ini menunjukkan: beberapa model secara alami "banyak bicara", dan tidak berkaitan erat dengan kesukaran tugas.
Satu penemuan yang memikat lagi: model kekurangan "kesedaran stop-loss".
Dalam menghadapi tugas sukar yang tidak dapat diselesaikan oleh mana-mana model, agen ideal sepatutnya menyerah sejak awal, bukan terus membuang duit. Namun, dalam kenyataannya, model secara umum menghabiskan lebih banyak token pada tugas yang gagal—mereka tidak “menyerah”, tetapi terus menerus mencuba, mencuba semula, dan membaca semula konteks, seperti kereta tanpa lampu amaran bahan bakar yang terus bergerak hingga terhenti.
Penemuan empat: Apa yang dianggap sukar oleh manusia belum tentu dianggap mahal oleh Agent—persepsi kesukaran sepenuhnya salah arah
Anda mungkin berfikir: Setidaknya saya boleh menganggar kos berdasarkan kesukaran tugas?
Mengambil kertas kerja dari pakar manusia untuk menilai kesukaran 500 tugas, kemudian membandingkannya dengan penggunaan token sebenar oleh Agen—
Hasil: Hanya ada korelasi lemah di antara keduanya.
Dengan kata mudah: tugas yang manusia anggap sangat sukar mungkin boleh diselesaikan Agent dengan mudah dan tanpa banyak kos; sebaliknya, tugas yang manusia anggap mudah mungkin boleh membuat Agent menghabiskan banyak sumber sehingga terasa seperti hampir gila.
Ini kerana kesukaran yang "dilihat" oleh manusia dan AI benar-benar berbeza:
- Manusia melihat: kompleksiti logik, kesukaran algoritma, ambang pemahaman perniagaan
- Agen memperhatikan: seberapa besar projek, berapa banyak fail yang perlu dibaca, sejauh mana laluan penjelajahan, dan sama ada fail yang sama akan diubah suai berulang kali
Seorang pakar manusia mungkin menganggap bug yang “hanya perlu ubah satu baris” memerlukan agen untuk memahami struktur keseluruhan kod terlebih dahulu sebelum dapat mengesan baris tersebut—hanya proses “membaca” sudah menghabiskan banyak token. Sebaliknya, masalah algoritma yang manusia anggap “logiknya rumit” mungkin justru diketahui oleh agen sebagai penyelesaian standard, dan dapat diselesaikan dengan cepat.
Ini mengakibatkan realiti yang memalukan: pembangun hampir tidak mungkin menganggar kos operasi Agent secara intuitif.
Penemuan lima: Bahkan model itu sendiri tidak dapat mengira berapa banyak yang perlu dibelanjakan
Jika manusia tidak dapat memperkirakan dengan tepat, mengapa tidak biarkan AI membuat ramalan sendiri?
Penyelidik merekabentuk satu eksperimen yang cemerlang: membiarkan Agen “menginspeksi” repositori kod sebelum memulakan pembaikan Bug, kemudian menganggarkan berapa banyak Token yang akan digunakan—tetapi tidak melaksanakan pembaikan secara sebenar.
Bagaimana hasilnya?
Semua model, kalah sepenuhnya.
Pencapaian terbaik ialah korelasi ramalan Token keluaran Claude Sonnet-4.5—0.39 (maksimum 1.0). Korelasi ramalan kebanyakan model hanya antara 0.05 hingga 0.34, dengan Gemini-3-Pro paling rendah pada 0.04—hampir sama dengan tekaan acak.
Lebih parah lagi: semua model secara sistematik meremehkan penggunaan Token mereka. Dalam grafik serakan Rajah 11, hampir semua titik data berada di bawah “garis ramalan sempurna”—model merasa “tidak akan menghabiskan sebanyak itu”, tetapi sebenarnya menghabiskan lebih banyak. Selain itu, bias meremehkan ini menjadi lebih teruk apabila tidak memberikan contoh.
Yang lebih ironis—ramalan itu sendiri juga memerlukan bayaran.
Kos ramalan untuk Claude Sonnet-3.7 dan Sonnet-4 bahkan boleh melebihi dua kali ganda kos tugas itu sendiri. Dengan kata lain, meminta mereka “beri anggaran” dahulu lebih mahal daripada terus melakukan kerja.
Kesimpulan kertas tersebut secara langsung:
Pada peringkat ini, model canggih tidak dapat meramal penggunaan Token mereka dengan tepat. Klik "Jalankan Agent", seperti membuka kotak kejutan—anda baru tahu berapa banyak yang dibelanjakan apabila bilangan datang.
Di sebalik “buku yang kabur” ini, tersembunyi masalah industri yang lebih besar
Setelah membaca ini, anda mungkin bertanya: Apa maknanya penemuan ini terhadap perusahaan?
Model harga "langgan bulanan" sedang dipecahkan oleh Agent
Kertas kerja tersebut menunjukkan bahawa model berlanggan seperti ChatGPT Plus boleh berfungsi kerana penggunaan Token untuk perbualan biasa relatif boleh dikawal dan boleh diramal. Namun, tugas Agen sepenuhnya memecahkan anggapan ini—satu tugas boleh menghabiskan jumlah Token yang sangat besar kerana Agen terperangkap dalam kitaran.
Ini bermakna, penetapan harga berdasarkan langganan semata mungkin tidak berterusan untuk skenario Agent, dan pembayaran mengikut penggunaan (Pay-as-you-go) masih akan menjadi pilihan paling realistik untuk jangka masa yang panjang. Namun, masalah dengan pembayaran mengikut penggunaan ialah—penggunaan itu sendiri tidak dapat diramalkan.
2. Kecekapan token seharusnya menjadi "indikator ketiga" dalam memilih model
Secara tradisional, perusahaan memilih model berdasarkan dua dimensi: kemampuan (bolehkah ia lakukan) dan kelajuan (seberapa pantas ia lakukan). Kertas ini memberikan dimensi ketiga yang sama pentingnya: kecekapan tenaga (berapakah kos yang diperlukan untuk menyelesaikannya).
Model yang sedikit kurang cekap tetapi 3 kali lebih berkesan mungkin mempunyai nilai ekonomi yang lebih tinggi dalam skala besar berbanding model “terkuat tetapi paling mahal”.
3. Agen memerlukan "petrol gauge" dan "brek"
Kertas kerja tersebut menyebut satu arah masa depan yang perlu diperhatikan—polisi penggunaan alat yang peka terhadap bajet. Dengan kata mudah, ia bererti memasang "alat pengukur bahan bakar" kepada Agen: apabila penggunaan Token mendekati bajet, paksa ia berhenti daripada menjalankan eksplorasi yang tidak berkesan, bukannya terus membazir sehingga habis.
Sekarang, hampir semua rangka kerja Agent utama tidak memiliki mekanisme ini.
Masalah "pengeluaran wang" agen bukan bug, tetapi kesakitan yang perlu dilalui oleh industri
Kertas ini mengungkap bukan kelemahan model tertentu, tetapi cabaran struktural keseluruhan paradigma Agent—apabila AI bergerak dari "tanya-jawab" kepada "perancangan autonomi, pelaksanaan berbilang langkah, dan penyesuaian berulang", ketidakbolehramalan penggunaan Token hampir merupakan kepastian.
Berita baiknya, ini adalah pertama kalinya seseorang mengungkap dan menghitung kekacauan ini secara sistematis. Dengan data ini, pengembang dapat membuat keputusan yang lebih bijak dalam memilih model, menetapkan anggaran, dan merancang mekanisme stop-loss; sementara pabrikan model memiliki arah pengoptimalan baru—tidak hanya menjadi lebih kuat, tetapi juga lebih hemat.
Setelah semua, sebelum AI Agent benar-benar masuk ke lingkungan produksi di berbagai industri, menghabiskan setiap ringgit dengan jelas lebih penting daripada menulis setiap baris kod dengan indah. (Artikel ini pertama kali diterbitkan di aplikasi Titanium Media, penulis | Silicon Valley Tech news, penyunting | Zhao Hongyu)
Catatan: Artikel ini berdasarkan kertas pra-cetak yang diterbitkan pada 24 April 2026 di arXiv, *How Do AI Agents Spend Your Money? Analyzing and Predicting Token Consumption in Agentic Coding Tasks* (Bai, Huang, Wang, Sun, Mihalcea, Brynjolfsson, Pentland, Pei). Penulis berasal dari institusi seperti Universiti Virginia, Stanford, MIT, Universiti Michigan, dan lain-lain. Kajian ini belum melalui proses penilaian rakan sebaya.