










Penulis: Max yang sentiasa di jalan, 01Founder
Jika ingin memberikan ringkasan tahap untuk OpenAI pada tahun 2025, ramai orang mungkin akan menggambarkannya sebagai datar atau bahkan agak pasif.
Dalam lebih daripada setahun terakhir, mereka telah secara sistematik melaksanakan laluan penalaran, menerbitkan model penalaran dari o3pro hingga o4mini secara padat, serta melancarkan model dasar baharu seperti GPT-4.5 dan GPT-5.
Namun, di bidang penghasilan visual yang paling mudah dirasakan oleh pengguna biasa dan paling mudah membentuk penyebaran spontan, kehadiran mereka semakin berkurang.
Selepas kejutan awal keluaran Sora, OpenAI kelihatan memasuki tempoh senyap yang panjang dalam pasaran ini.
Sementara itu, pemain lain di meja tidak duduk membiarkan diri mereka pasif.
Dalam ekosistem sumber terbuka, model seperti Flux benar-benar meruntuhkan rintangan untuk menghasilkan gambar berkualiti tinggi secara tempatan;
Di perniagaan, bukan sahaja pesaing lama menguasai penghalang estetik yang ketat, tetapi juga muncul pesaing baharu seperti Nano-banana yang membawa fungsi carian dalam talian.
Sebaliknya, model gambar utama lama OpenAI, GPT-Image-1.5, sudah kelihatan ketinggalan zaman:
Kualiti gambar buruk, susunan kaku, dan sering rosak apabila menghadapi teks yang kompleks.
Perlahan-lahan, industri ini membentuk satu konsensus:
OpenAI menghadapi halangan teknikal dalam bidang penghasilan visual dan kini kelihatan kesulitan menghadapi serangan daripada pelbagai pesaing.
Hingga beberapa minggu yang lalu, titik balik muncul dengan cara yang sangat halus.
Di platform ujian buta model besar terkenal LM Arena, sebuah model gambar misterius dengan kod nama Duct Tape telah terselip masuk.
Pengguna yang menyertai ujian buta segera mendapati ada yang tidak kena:
Model ini tidak hanya mengawal rasio gambar ekstrem dengan sangat tepat, tetapi juga mampu menghasilkan poster tata letak yang mengandung banyak teks pelbagai bahasa tanpa cacat, bahkan seolah-olah terdapat proses perancangan logik tersirat sebelum menghasilkan gambar.
Pada masa itu, komuniti teknikal semua menebak-tebak siapa yang telah melancarkan senjata rahsia itu, tetapi pihak OpenAI terus berdiam diri.
Pada dini hari ini, kasut akhirnya jatuh.
Tanpa acara pelancaran yang panjang atau pemasaran promosi yang meluas, OpenAI secara langsung menamakan model dengan kod nama selotip itu sebagai ChatGPT GPT-Image-2 dan melancarkannya secara menyeluruh ke pasaran.
Seiring dengan itu, sebuah peringkat pertandingan Text-to-Image yang membuatkan rasa sesak juga dipaparkan.
GPT-Image-2 menduduki puncak dengan skor tinggi 1512, memimpin 242 mata lebih tinggi daripada pesaing kedua (Nano-banana-2 dengan fungsi carian dalam talian).
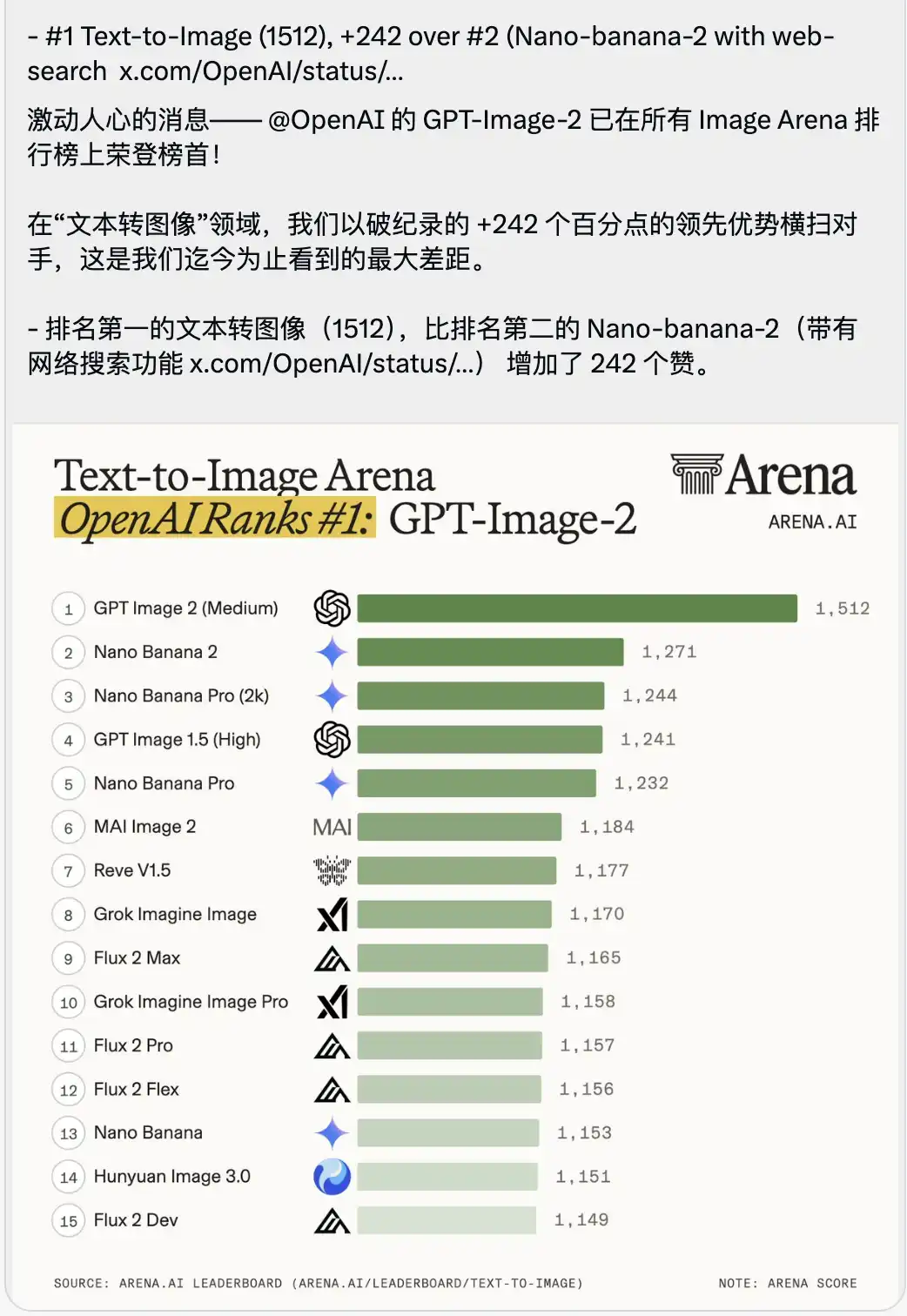
Dalam konteks penilaian model besar, orang biasanya akan memperbesar kelebihan sebanyak setengah atau unit, di mana skor antara model teratas sangat rapat.
Kesan kepimpinan 242 mata adalah tanpa contoh dalam sejarah arena.
Ini bukan sekadar peningkatan versi kecil, ini adalah keunggulan generasi yang kasar.
Saya menghabiskan sepanjang hari untuk memeriksa secara teliti pelbagai kemampuan ekstremnya serta dokumen API terkini.
Perasaan terbesar hanyalah satu:
OpenAI masih OpenAI yang sama.
Apabila ia memutuskan untuk merebut semula wilayahnya, ia melakukannya dengan cara menolak meja kad lama secara langsung.
Di hadapan model ini, pekerjaan reka bentuk visual yang kita sangka masih memerlukan dua hingga tiga tahun lagi sebelum digantikan sepenuhnya oleh AI, hari ini pada dasarnya telah sampai ke penghujungnya.
BAHAGIAN.01 Penghasilan Gambar Dari Model Kepada Agen Visual
Untuk memahami mengapa GPT-Image-2 mampu mencapai perbezaan skor yang begitu besar, anda perlu meninggalkan persepsi lama terhadap model teks-ke-gambar.
Sebelum ini, kami menggunakan AI untuk melukis, pada dasarnya adalah membuka kotak rahsia, memasukkan beberapa petunjuk dan menunggu ia menyusun piksel mengikut bentuk yang anda inginkan.
Namun, GPT-Image-2 lebih seperti agen yang dilengkapi dengan enjin visual.
Perubahan yang paling ketara ialah ia secara langsung memisahkan dua mod yang benar-benar berbeza dalam mekanismenya.
Satu ialah mod segera (Instant Mode) yang terbuka kepada semua pengguna.
Model ini menekankan respons pantas dan integrasi tanpa henti ke dalam alur kerja harian.
Misalnya anda menghantar arahan melalui telefon bimbit, ia akan memberikan gambar yang berstruktur lengkap dalam beberapa saat.
Kemampuan pemahaman visual dasarnya sangat kuat, tetapi ia terutama menyelesaikan keperluan transformasi visual berfrekuensi tinggi dan sekali jalan.
Modus Pemikiran (Thinking Mode) yang dibuka kepada pengguna berbayar.
Sebelum ia benar-benar memulai pemaparan sebarang piksel pun, ia akan memasuki proses penalaran logik dan carian dalam talian yang berlangsung selama belasan saat.
Tepat model ini, yang menyelesaikan satu pernyataan yang sangat penting tetapi sangat sukar:
Model pertama kali benar-benar tahu apa yang perlu dilukis.
Contoh yang paling langsung.
Ketik di kotak dialog:
Bantu saya membuat poster, cari di internet ulasan orang tentang model misteri Duct Tape ini, dan sertakan kod QR ChatGPT.

Dengan model lama, ia sama sekali tidak tahu apa yang dikatakan pengguna internet, hanya akan menghasilkan poster dengan huruf acak dan kod, dan kod QR juga merupakan gambar palsu yang tidak boleh dipindai.
Tetapi dalam mod pemikiran, alur kerjanya adalah seperti ini:
Ia akan terlebih dahulu menghentikan penggambaran, memulakan alat carian dalam talian, dan mengambil ulasan sebenar pengguna dari Reddit, Threads, atau LinkedIn;
Kemudian, ia mulai merancang tata letak poster, ruang kosong, dan hierarki fon;
Akhirnya, ia menghasilkan kod QR yang sah dan boleh digunakan secara langsung untuk dipindai dan diarahkan, serta merender keseluruhan gambar.

Ini bukan lagi sekadar melukis, ini sebenarnya adalah pekerjaan serba ada yang secara mandiri melakukan penyelidikan, perancangan, pengambilan teks, dan reka bentuk tata letak.
Di sini perlu dibuat perbandingan sejajar.
Semua yang mengikuti komuniti model besar tahu bahawa model penghasilan gambar dengan kemampuan dalam talian dan carian bukanlah ciptaan pertama OpenAI.
Nano-banana yang berada di tempat kedua dalam senarai peringkat sudah memiliki mekanisme ini.
Namun, semasa mengguna Nano-banana, anda akan mendapati ia agak kikuk di banyak tempat.
Pemikiran Nano-banana sering kali merupakan logik penyambungan mekanikal.
Contohnya, jika anda menyuruhnya mencari tren industri untuk membuat poster, ia memang mencarinya, tetapi biasanya hanya mengambil ayat-ayat dari Wikipedia secara kaku dan menempelkannya secara paksa ke dalam gambar.
Ia mudah kebingungan apabila menghadapi arahan yang memerlukan penafsiran permintaan perniagaan yang abstrak.

Rasa itu seolah-olah seorang amal yang faham arahan, tetapi tidak mempunyai pengalaman kerja sedikit pun, faham pelaksanaan, tetapi sama sekali tidak faham strategi.
Namun, prestasi GPT-Image-2 dalam aspek ini hanya boleh digambarkan sebagai berlebihan.
Pemikirannya bukan sekadar formaliti, tetapi benar-benar memahami konteks budaya dan niat perniagaan di sebaliknya.
Saya memasukkan arahan bahasa Cina yang sangat ringkas semasa pengujian: Bantu saya mengambil tangkapan layar Musk yang melakukan siaran langsung di TikTok untuk menjual Doubao.
Jika menggunakan model lukisan lama, kemungkinan besar ia akan melukis seorang lelaki kulit putih yang menyerupai Musk, memegang sebiji baozi, dengan latar belakang kabur, bahkan tidak tahu bagaimana bentuk TikTok.
Namun dalam modus pemikiran, hasil GPT-Image-2 agak mengejutkan.
Ia tidak sekadar menyusun elemen-elemen secara asal, tetapi secara autonom mengggunakan pemahaman terhadap internet China untuk menghasilkan skrin tangkapan UI ruang siaran TikTok yang disalin hingga per piksel.
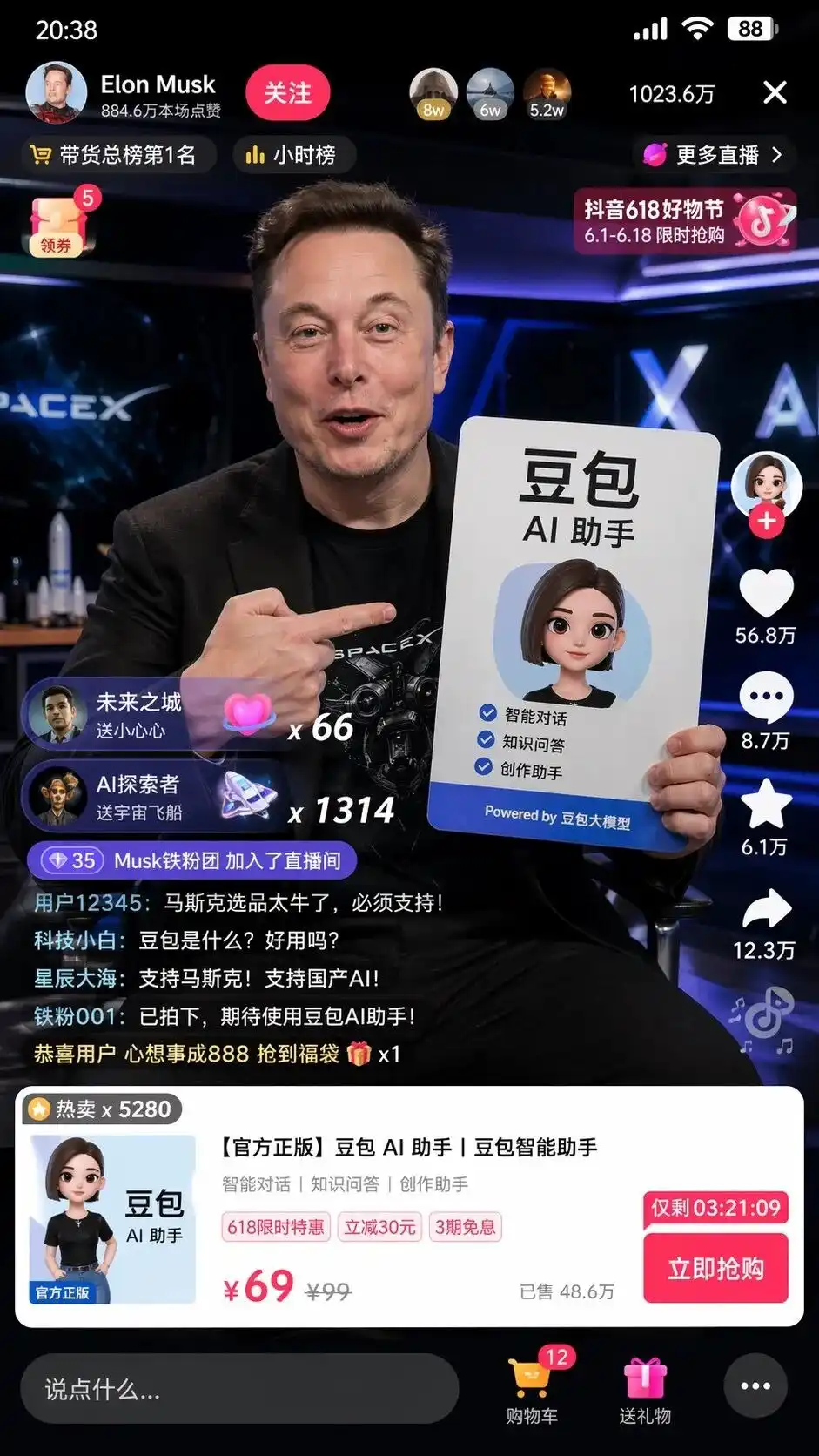
Layar tidak hanya menunjukkan Musk yang realistik memegang plakat iklan asisten AI DouBao dengan tata letak yang sempurna, tetapi juga butiran-butiran yang lebih menakutkan yang tidak disebutkan dalam petunjuk:
Tombol perhatian di kiri atas, senarai jam, jumlah pengguna dalam talian 10.23 juta di kanan atas, kad produk standard yang muncul di bahagian bawah, serta harga asal 99, harga promosi 69, dan butang "Beli Sekarang" dengan penghitung mundur.
Yang paling membuat rambut berdiri ialah ulasan pengguna yang bergerak secara sangat realistik di sudut kiri bawah:
Pengguna teknologi awam: Apakah Doudou? Adakah ia mudah digunakan?
Bintang dan lautan luas: Sokong Musk! Sokong AI tempatan!
Tiada siapa pun yang memberitahunya apa yang harus ditulis dalam papan ucapan, bagaimana antaramuka produk harus kelihatan, atau bagaimana harga harus ditetapkan.
Ini adalah reka bentuk antaramuka perniagaan dan perancangan operasi penuh yang dihasilkan dan dilaksanakan oleh model selepas menganalisis tag-tag 'penjualan di Douyin' dan 'model besar DouBao'.
Dimensi penilaian model besar dalam penghasilan gambar, pada saat ini secara rasmi berpindah dari sekadar mampu menghasilkan gambar yang cantik, kepada memahami strategi dan logik susunan.
BAHAGIAN.02 Ujian Kapasiti Inti
Untuk menguji batas bawahnya, saya menguji beberapa skenario yang sering berlaku dan kompleks mengikut piawaian reka bentuk perniagaan.
Ternyata, ketepatan ia menyelesaikan masalah telah hingga ke tahap yang menakutkan.
Skenario pertama: Pemahaman visual dan kitaran perniagaan (memakaikan pakaian kepada model)
Dalam visual e-dagang tradisional atau perancangan fesyen, kos pelaksanaan antara idea hingga melihat kesan pemakaian adalah sangat tinggi.
Anda perlu mencari model, meminjam pakaian, menyediakan studio foto, dan melakukan penyempurnaan akhir.
Kemudian, dengan munculnya AI, orang mulai melatih model LoRA untuk menetapkan bentuk wajah tokoh, tetapi ini masih memerlukan bahan gambar puluhan gambar dan kos pembelajaran yang besar.
Dalam GPT-Image-2, proses ini telah dipadatkan sepenuhnya.
Saya mencuba menghantar satu gambar selfi harian saya, memberitahunya bahawa saya akan pergi bercuti ke pulau bulan depan, dan meminta ia membantu saya menyusun beberapa set pakaian.
Ia terlebih dahulu memberi saya 8 set gambar pakaian musim panas dengan gaya yang berbeza-beza, susunan kelihatan seperti Lookbook e-dagang profesional, dengan setiap item disertai label teks yang betul di sampingnya.
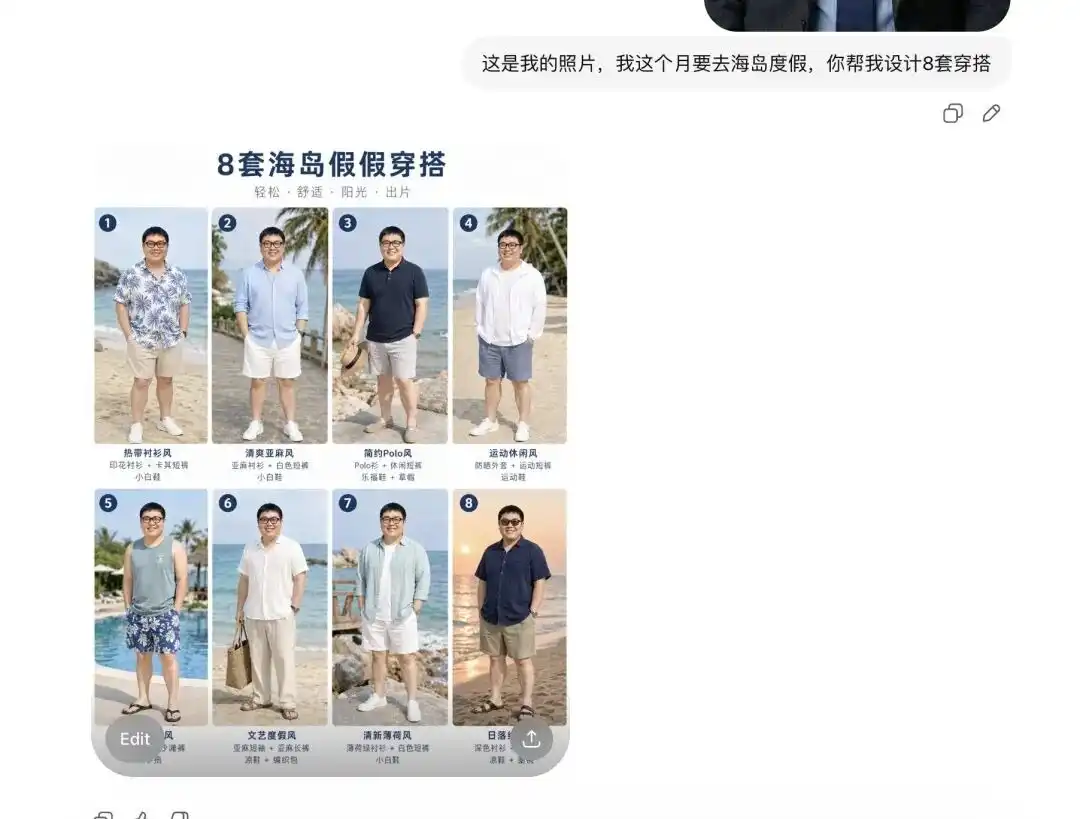
Lebih penting lagi, ia telah memahami ciri-ciri wajah dan nisbah tubuh saya dengan tepat pada saat ini.
Apabila saya memberitahunya bahawa saya ingin melihat kesan pakaian pertama yang dipakai, serta meminta beberapa gambar perincian dari sudut yang berbeza, ia terus mengeluarkan orang dalam gambar swafoto saya, menukar pakaian itu dengan pakaian musim panas, dan menghasilkan gambar dari pelbagai sudut seperti sisi dan separuh badan.

Perubahan ini sangat lancar. Ini bermakna, perlindungan terhadap render pakaian peringkat awal, atau kerja outsourced mencari model untuk mencuba pakaian, telah benar-benar diputuskan.
Skenario kedua: Menyelesaikan konsistensi dan narasi berterusan (menghasilkan komik dalam satu ayat)
Semua orang yang pernah mencuba gambar AI tahu bahawa mencipta satu gambar yang cantik bukanlah suatu masalah, tetapi mencipta sepuluh gambar dengan orang yang sama, dengan gerakan dan sudut pandang yang selari, adalah suatu cabaran.
Ini adalah apa yang dikenali sebagai masalah konsistensi (Consistency).
Namun dalam ujian sebenar ini, saya melihat satu kes yang sangat bertentangan dengan pengalaman lampau.
Anda boleh hanya muat naik satu gambar bersama rakan anda semalam, kemudian masukkan satu petua yang sangat ringkas:
Jadikan kita berdua sebagai tokoh utama, lukis tiga gambar komik Jepang tiga halaman, ceritanya kau tentukan
Beberapa saat kemudian, ia secara langsung menghasilkan tiga halaman komik hitam putih dengan panel standar.
Tempat yang paling menakutkan ialah, dua watak komik yang dihasilkan berdasarkan orang sebenar, berada dalam adegan yang berbeza di tiga muka surat.

Baik close-up, larian jauh, atau siluet, bahkan ciri-ciri wajah, butiran gaya rambut, dan kerutan pakaian mereka, semuanya mengekalkan konsistensi yang sempurna.
Lebih lagi, alur komiknya sepenuhnya konsisten, bahkan teks dalam petak dialog juga membentuk logik cerita yang utuh.

Kemampuan untuk mencapai konsistensi dalam masa dan ruang menunjukkan bahawa ia telah melangkah keluar dari lingkungan penghasilan gambar tunggal dan memiliki kemampuan pengarah untuk bercerita secara berterusan.
Skenario ketiga: Melintasi ambang terakhir dalam pemerataan teks (tata letak pelbagai bahasa)
Jika konsistensi menyelesaikan masalah naratif, maka render yang tepat untuk teks pelbagai bahasa benar-benar memaksa para reka bentuk grafik ke dinding.
Dahulu, sekiranya gambar mengandungi sedikit teks, model besar akan mulai menulis seperti coretan tak bermakna.
Kerana model memahami teks sebagai Token (blok makna), manakala gambar yang dihasilkan adalah titik pixel, keduanya dahulu dipisahkan.
GPT-Image-2 menyelesaikan masalah ini sepenuhnya.
Saya menjadikannya menghasilkan sampul majalah fesyen berbahasa Perancis, membuat menu restoran Jepun dengan kanji dan hiragana penuh, serta mencuba catatan bahasa Rusia dengan kepadatan tata letak yang sangat tinggi.

Hasilnya adalah satu bentuk, tiada kesalahan ejaan.
Yang paling membuat putus asa ialah, ia tidak hanya menulis huruf dengan betul, tetapi juga memahami cara menyesuaikan estetika budaya dan reka bentuk fon mengikut bahasa tempatan.
Sebagai contoh, huruf Kanji dalam pamflet bahasa Jepang menggunakan jenis huruf seni retro yang sangat autentik, dan susunan hiragana juga mematuhi kebiasaan membaca vertikal bahasa Jepang.
Reka bentuk tata letak dahulu merupakan bidang eksklusif juru reka grafik.
Pengaturan jarak antara huruf, pemisahan utama dan sekunder, serta keseimbangan visual antara teks dan latar belakang semuanya memerlukan latihan yang banyak.
Tetapi apabila AI mampu menangani begitu banyak bahasa tanpa kesalahan, dilengkapi dengan estetika tata letak canggih, poster harian, brosur, dan iklan aliran informasi benar-benar tidak lagi memerlukan manusia untuk secara manual menyelaraskan garis rujukan.
Skenario keempat: Rasio aspek yang terdistorsi dan kawalan mikro yang ekstrem (ukiran pada biji nasi)
Akhirnya, untuk melihat seberapa patuh ia, saya memberinya beberapa arahan yang sangat rumit.
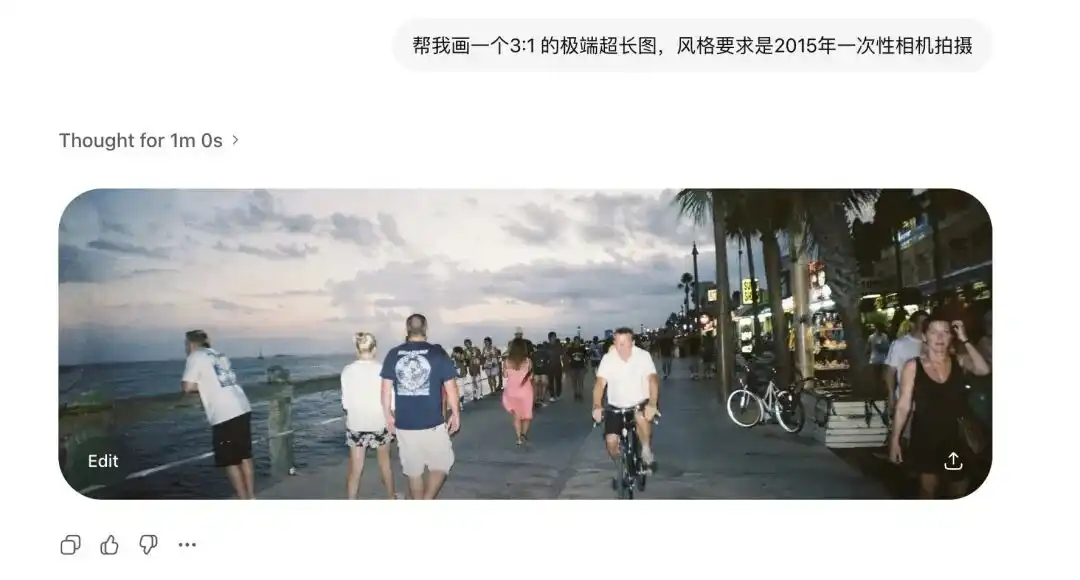
Saya pertama kali menguji rasio aspek ekstremnya.
Model penyebaran tradisional sangat takut kepada nisbah bukan piawai.
Sebelum ini, apabila sedikit memanjangkan gambar, dua kepala akan muncul dalam gambar.
Namun, saya meminta Images 2.0 untuk menghasilkan gambar super lebar 3:1 dan gambar tegak panjang 1:3, ia tidak hanya tidak rosak, malah menghasilkan gambar panorama 360 darjah yang sambung-menyambung dan logiknya tertutup.
Setelah menambahkan entri gambar kamera sekali pakai tahun 2015, distorsi lensa lama dan pantulan cahaya flash yang buruk di dinding pun direproduksi dengan jelas.
Namun, yang lebih menunjukkan kekuatan kawalan mikro ia adalah ujian biji beras yang agak gila yang dipaparkan oleh pihak rasmi di acara pelancaran.
Penyelidik memanggil API eksperimen 4K yang masih dalam ujian dalaman, mereka tidak menggunakan sebarang perkataan penerangan seperti fotografi makro, ultra-tinggi 8K, tetapi hanya memberikan arahan yang sangat abstrak:
Sejumlah beras. Pada satu biji beras dalam tumpukan beras ini tertulis GPT Image 2.
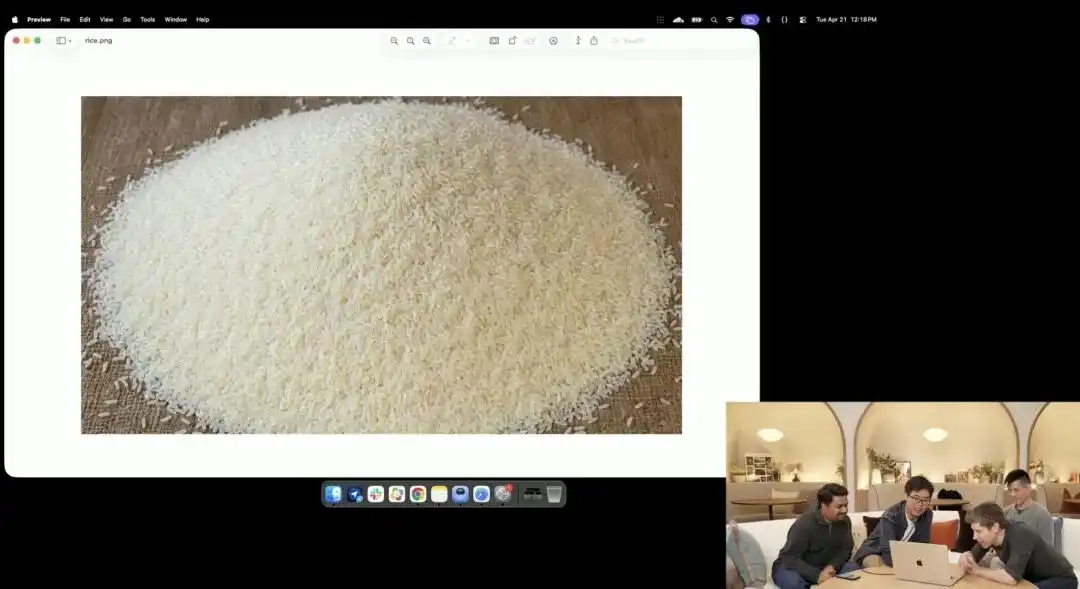
Apabila gambar diperbesar puluhan kali di skrin, bahkan hingga muncul butiran pixel, adakah anda benar-benar boleh menemui butiran halus yang ditulis huruf di antara sekumpulan beras?
Tekstur nasi ini masih mematuhi hukum fizikal, dan teks tertanam dengan tepat mengikuti kelengkungan halus butir nasi.
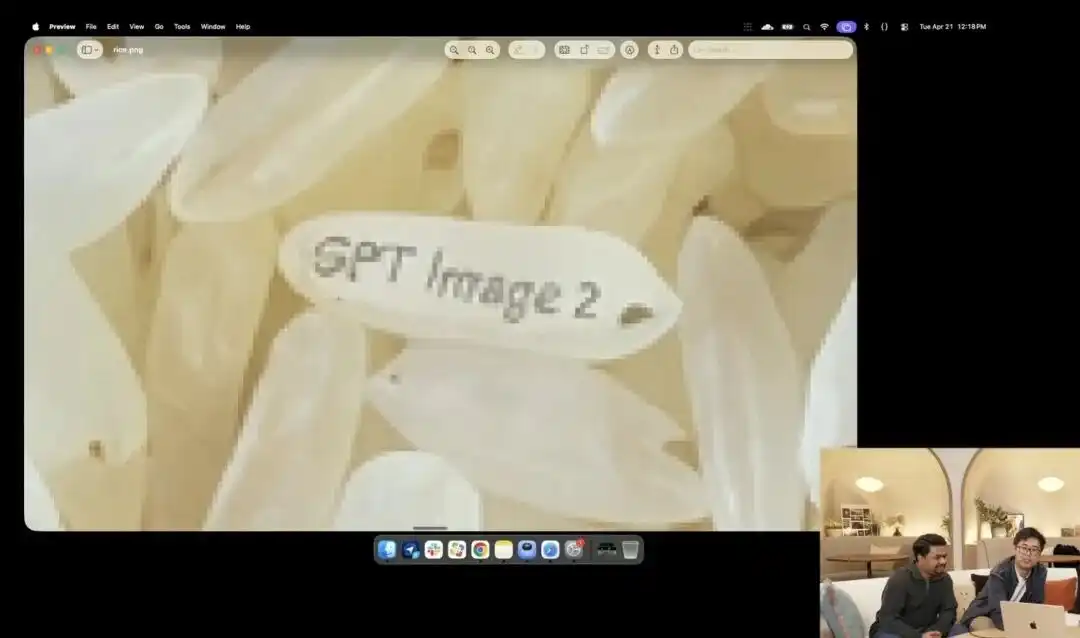
Semua kerja yang tinggal—memanggil sudut mikroskopik, mengira kedalaman fokus, mencari koordinat fizikal biji nasi dalam ruang laten, dan mencetak hurufnya—semuanya dilakukan secara automatik oleh model besar semasa mod pemikiran.
Kes ini secara intuitif menunjukkan bahawa model memahami kedudukan ruang dengan ketepatan skala pixel seperti scalpel.
Ini bermakna, dalam kerja sebenar di masa depan, anda boleh memperbaiki mana-mana bahagian kecil dalam reka bentuk dengan tepat, tepat di mana anda ingin, bukan seperti dahulu, apabila anda ingin mengubah kolar, tetapi keseluruhan gambar berubah bersama.
BAHAGIAN.03 Beberapa butiran teknikal
Kekuatan dan kecerdasan strategik yang ekstrem ini tidak mungkin dicapai hanya dengan membanjiri dengan kekuatan pengiraan tanpa pemikiran.
Untuk memahami apa sebenarnya kekuatan utamanya, saya menjalankan beberapa ujian penjajakan terhadap GPT-Image-2.
Ternyata ditemui satu perkara yang sangat menarik.
Walaupun dokumen rasmi menyatakan tarikh akhir pangkalan pengetahuan keseluruhan GPT-Image-2 telah dikemas kini hingga Disember 2025, tetapi dalam ujian sebenar saya.
Tarikh akhir data latihan Mod Pantas (Instant Mode) masih berada pada akhir Mei 2024;

Sementara itu, modus pemikiran (Thinking Mode) yang memerlukan pertimbangan panjang mempunyai perpustakaan pengetahuan asalnya sekitar Jun 2024 (tetapi boleh mendapatkan tarikh semasa melalui pautan internet secara nyata).

Mengikut dua titik masa ini, asas keseluruhan GPT-Image-2 kelihatan ada jejaknya.
Pertama, nyatakan modus segera yang menonjolkan pengeluaran gambar frekuensi tinggi.
Tarikh akhir Mei 2024 bermakna ia kemungkinan besar secara langsung menggunakan o4-mini, atau versi ringan dari keluarga GPT-5 (GPT-5 mini atau bahkan GPT-5 nano dengan parameter sangat kecil).
Kerana basis ringan ini sudah memiliki kemampuan perancangan ruang yang sangat kuat dan memahami arahan kompleks, penghasilan imej lapisan atas dapat tetap stabil dan tidak kacau.
Dan pola pemikiran yang sangat bijak dan memahami strategi perniagaan itu tidak mungkin berasal dari model utama GPT-5.
Kerana pangkalan pengetahuan asas GPT-5 berakhir pada September 2024.
Modus pemikiran kemungkinan besar menghubungkan model inferensi siri O yang terus diperbaharui di latar belakang (contohnya o4, atau o3 yang telah dikemaskini).
Model besar terlebih dahulu menggunakan mekanisme pemikiran panjang khas siri O, mengira dengan jelas logik perniagaan, psikologi penonton, dan koordinat tata letak dalam ruang tersembunyi, sebelum menyerahkan kepada modul visual untuk render piksel akhir.
Tentu, terdapat juga jalan alternatif lain:
Di bawah mekanisme pengagihan kekuatan pengiraan yang sangat halus di dalam OpenAI, mod pantas mungkin secara langsung menggunakan GPT-5 nano sebagai dasar, manakala mod pemikiran menggunakan GPT-5 mini yang sedikit lebih besar bersama alat luar.
Tetapi sama ada kombinasi dasar yang mana pun, jika anda terus memperhatikan ekosistem API OpenAI, anda akan mendapati bahawa logik penghasilan asasnya sudah lama tidak lagi sejajar dengan Midjourney.
BAHAGIAN.04 Harga yang paling diperhatikan oleh semua orang
Tetapi lebih penting daripada menebak dasar, bagi pengembang dan perusahaan yang benar-benar ingin mengintegrasikannya ke dalam alur kerja mereka, adalah jadual penentuan harga API yang sangat realistik dan bertentangan dengan intuisi itu.
DALL-E 3 sebelum ini dikenakan caj berdasarkan gambar (contohnya, 0.04 dolar AS sebelum gambar).
Namun, sejak GPT-Image-1 generasi pertama, OpenAI telah mengubahnya sepenuhnya kepada kerangka penagihan berdasarkan Token.
GPT-Image-2 kali ini masih meneruskan standard ini, dan malah menawarkan peningkatan kuantiti dengan harga yang lebih rendah.
Berdasarkan senarai harga yang baru sahaja diumumkan oleh pihak rasmi, harga setiap juta Token adalah seperti berikut.
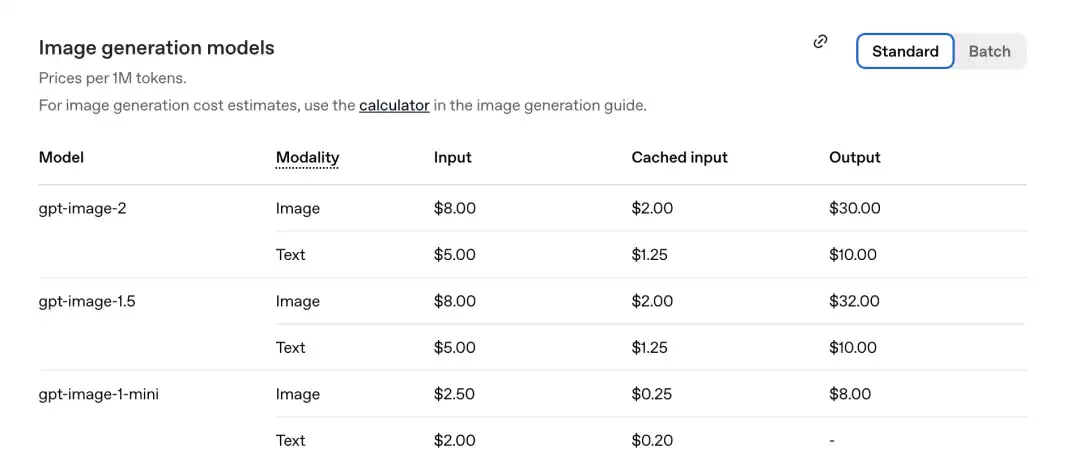
Bahagian imej GPT-Image-2: Masukkan 8.00, masukkan cache (Cached inputs) 2.00, keluaran $30.00.
Dibandingkan dengan generasi sebelumnya gpt-image-1.5: output ialah $32.00.
Model baru pula lebih murah.
Mari kita hitung angkanya.
Dalam model lama, menghasilkan satu gambar berkualiti tinggi biasanya memerlukan penggunaan sebanyak 1000 hingga 1500 Token output.
Berdasarkan harga $30 setiap juta token yang dihasilkan, kos sebenar untuk menghasilkan satu gambar berkisar antara $0.03 hingga $0.045 (kira-kira RM2 hingga RM3).
Jika anda tidak memerlukan respons pantas, tetapi menggunakan modus API Batch yang disediakan secara rasmi, harga ini akan terus berkurang separuhnya (output akan turun terus kepada $15.00).
Dihitung, kos terendah untuk menghasilkan satu gambar hanyalah lebih daripada 10 sen.
Harga untuk satu keping ini sudah cukup berbaloi, tetapi senjata utamanya yang sebenarnya ialah input yang disimpan (Cached inputs) dalam jadual harga.
Dahulu, apabila anda membuat komik bergambar atau mereka reka poster dalam siri yang sama, setiap kali anda menghasilkan semula, anda perlu memuat naik semula banyak gambar rujukan watak, ringkasan sebelumnya, dan petikan panjang—kos input sangat tinggi.
Namun, dalam model penagihan Token semasa ini, apabila anda meminta ia menghasilkan 8 gambar komik yang berterusan secara serentak, elemen visual pada gambar pertama akan disimpan secara langsung sebagai konteks cache.
Dari gambar kedua, kos input imej turun secara terus dari $8.00 kepada $2.00 (hanya dikenakan 25% sahaja).
Ini bermakna, semasa melakukan pengeluaran batch komersial dalam skala besar, atau penghasilan berterusan yang memerlukan konsistensi peranan yang sangat tinggi, kos marjinalnya akan menurun secara terus-menerus.
Semakin pintar model dan semakin banyak gambar yang dihasilkan, kos purata per gambar menjadi semakin rendah.
Logik penagihan yang diindustrikan inilah yang benar-benar akan memaksa para pelukis jalur produksi ke titik terakhir.
BAHAGIAN.05 Mendedahkan Pasukan Di Belakang Layar
Akhirnya, kita kembali melihat pasukan visual dalaman OpenAI yang menunjukkan di acara pelancaran langsung ini; banyak fungsi yang sebelumnya dianggap tidak masuk akal kini menjadi jelas.
Sebagai contoh, bagaimana ia sebenarnya menyelesaikan masalah susunan pelbagai bahasa dan teks yang tidak dapat dibaca.
Ini tidak mungkin tanpa saintis berpengalaman dalam pasukan, Gabriel Goh.

Dalam kalangan akademik, beliau paling terkenal sebagai penulis utama model multimodal inovatif CLIP.
CLIP has laid the foundation for contemporary AI to understand how human language and image pixels correspond.
Dengan pakar pemetaan makna lintas modality ini memimpin, GPT-Image-2 tidak lagi menebak bentuk teks secara sembarangan, tetapi benar-benar menulis pada tahap piksel.
Sebagai contoh, bagaimana ia memahami hubungan ruang tiga dimensi, bahkan mampu membuat pemandangan 360 darjah dengan nisbah lebar-tinggi yang ekstrem, serta memahami cahaya dan bayangan mikroskopik pada biji beras?
Ini berkat ahli utama lain, Alex Yu.

Sebelum menyertai OpenAI, beliau ialah rakan pengetua dan mantan CTO syarikat rintisan terkenal di bidang penghasilan 3D, Luma AI, serta seorang akademik terkemuka yang secara khusus meneliti render neural 3D (seperti NeRF).
Dengan kehadirannya, GPT-Image-2 sebenarnya telah melangkah keluar daripada penggosokan pixel 2D tradisional.
Ia kemungkinan besar membina satu adegan tiga dimensi dalam fikiran, menetapkan cahaya, kemudian merender satu potongan 2D yang tepat untuk anda.
Bagaimana konsistensi komik berbilang halaman yang sangat menakutkan itu dicapai.
Ini merujuk kepada pasangan muda dari pasukan yang baru sahaja lulus dari MIT CSAIL:
Boyuan Chen (kiri) dan Kiwhan Song (kanan).
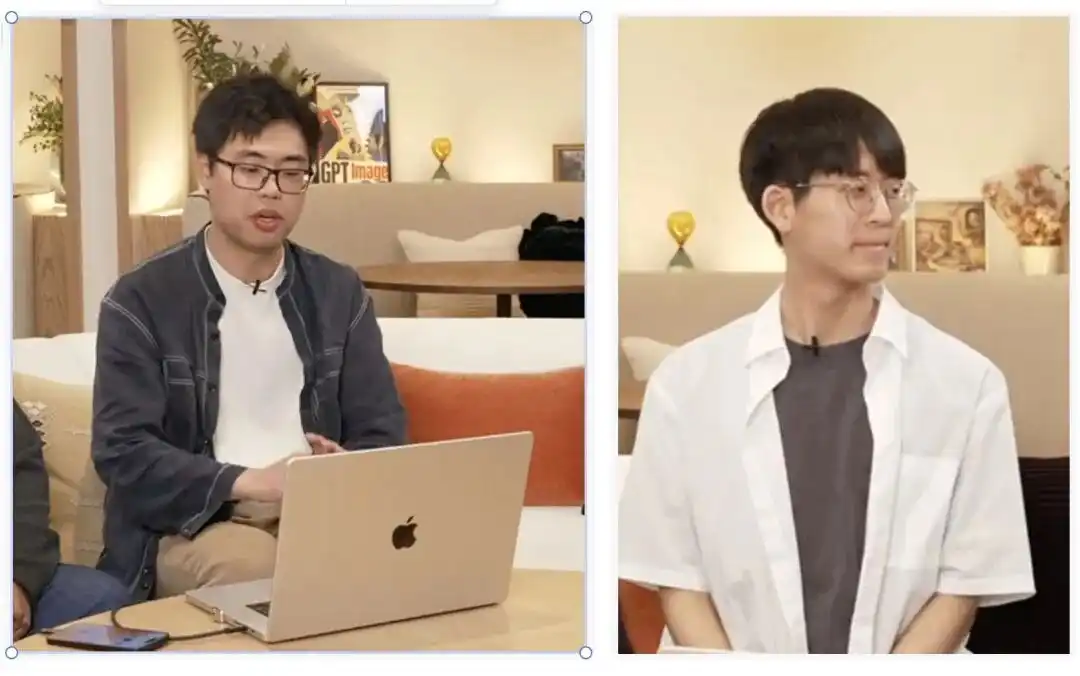
Arah utama mereka di kalangan akademik ialah model dunia (World Models) dan kecerdasan berbadan.
Mengajar mesin untuk memahami bagaimana dunia fizikal berfungsi, supaya watak-watak kekal konsisten dan tidak mengalami perubahan bentuk di bawah adegan yang berbeza dalam masa dan ruang, tepatnya merupakan tesis yang dua akademik ini cuba selesaikan.
Akhirnya, tambahkan Nithanth Kudige (kiri, penulis utama model inferensi siri O) yang terus berusaha menghubungkan model inferensi besar dengan logikas asas visual, dan Kenji Hata (kanan, penyelidik mantan Google yang lulus dari Laboratori Visual Stanford).

Apabila sekumpulan orang ini berkumpul, logik penalaran dasar, render ruang 3D, penyelarasan grafik dan teks yang sempurna, serta hukum dunia fizikal, secara alami digabungkan ke dalam satu model yang sama.
PART.06 Sempadan GPT-Image-2
Setiap model mempunyai sempadan.
Pihak rasmi juga mengakui bahawa ia masih berjuang apabila menghadapi beberapa keadaan ekstrem.
Contohnya, panduan origami yang memerlukan pembalikan ruang fizikal yang ketat, menyelesaikan rubik’s cube, atau butiran berulang yang sangat padat seperti pasir yang sangat halus, masih akan mencapai had kemampuannya.
Namun, dalam konteks aplikasi perniagaan, ini sudah merupakan kecacatan yang sangat kecil.
Untuk seluruh industri reka bentuk, kita tidak perlu menjual kebimbangan, ini tidak bermakna kemusnahan estetika.
Orang yang berselera, mempunyai wawasan perniagaan, dan memahami strategi masih boleh menghasilkan perkara yang sangat baik dengannya.
Namun, fakta yang ada secara objektif ialah, parit perlindungan bagi juru reka sebagai sebuah kerjaya telah benar-benar dihancurkan.
Dahulu, hidup bergantung pada hafalan pintasan perisian reka bentuk, kemampuan menyelaraskan teks secara mendatar dan tegak, memahami penataan teks mengikut bahasa, serta kemahiran menyempurnakan dan mengeluarkan gambar dengan tepat.
Tetapi akan menjadi lebih sukar di masa depan, kerana kemahiran-kemahiran yang dahulu boleh dinyatakan harganya dan diperdagangkan, kini telah menjadi arahan asas yang boleh dipanggil secara percuma dengan satu ayat sahaja oleh sesiapa sahaja.
Setelah sekian lama tidak aktif, OpenAI benar-benar membuktikan sekali lagi bahwa di meja ini, siapa yang benar-benar memegang kartu terbaik dengan cara yang sangat tenang namun sangat mematikan.
Rantai alat pelaksanaan lama sedang putus, masalah yang tinggal untuk industri bukan lagi sama ada AI akan menggantikan kita, tetapi bagaimana kita harus menyesuaikan diri dengan garis pengeluaran baharu ini.