









Malam ini, ChatGPT Images 2.0 dilancarkan dengan dahsyat, menjadi AI gambar pertama yang "berfikir". Otoman memuji ini sebagai lompatan dari GPT-3 ke GPT-5. Ia tidak hanya mampu memahami arahan bahasa Cina dengan tepat, merender UI yang kompleks, bahkan boleh mengukir teks pada biji beras.
Penulis artikel, sumber: XinZhiYuan
OpenAI yang sudah dikenal itu kembali!
Pada waktu subuh, Ultraman secara langsung memimpin siaran langsung dalam talian selama 20 minit, mengakhiri keheningan selama beberapa hari.
OpenAI akhirnya melancarkan ChatGPT Images 2.0 yang telah lama dirumorkan, secara rasmi memulakan era baharu dalam penghasilan imej.

Images 2.0 merupakan lompatan kualitatif, dengan kemajuan besar dalam memahami arahan panjang dengan tepat, meletakkan objek secara akurat dan mengklarifikasikan hubungan antara objek-objek, serta merender teks yang padat.
Yang paling penting, ia adalah model imej pertama yang mempunyai "keupayaan berfikir", boleh mencari maklumat semasa secara dalam talian dan semak semula sendiri.
Ia juga mampu menghasilkan lapan gambar dengan gaya yang selari dalam satu masa, dengan resolusi super jelas hingga 2K.
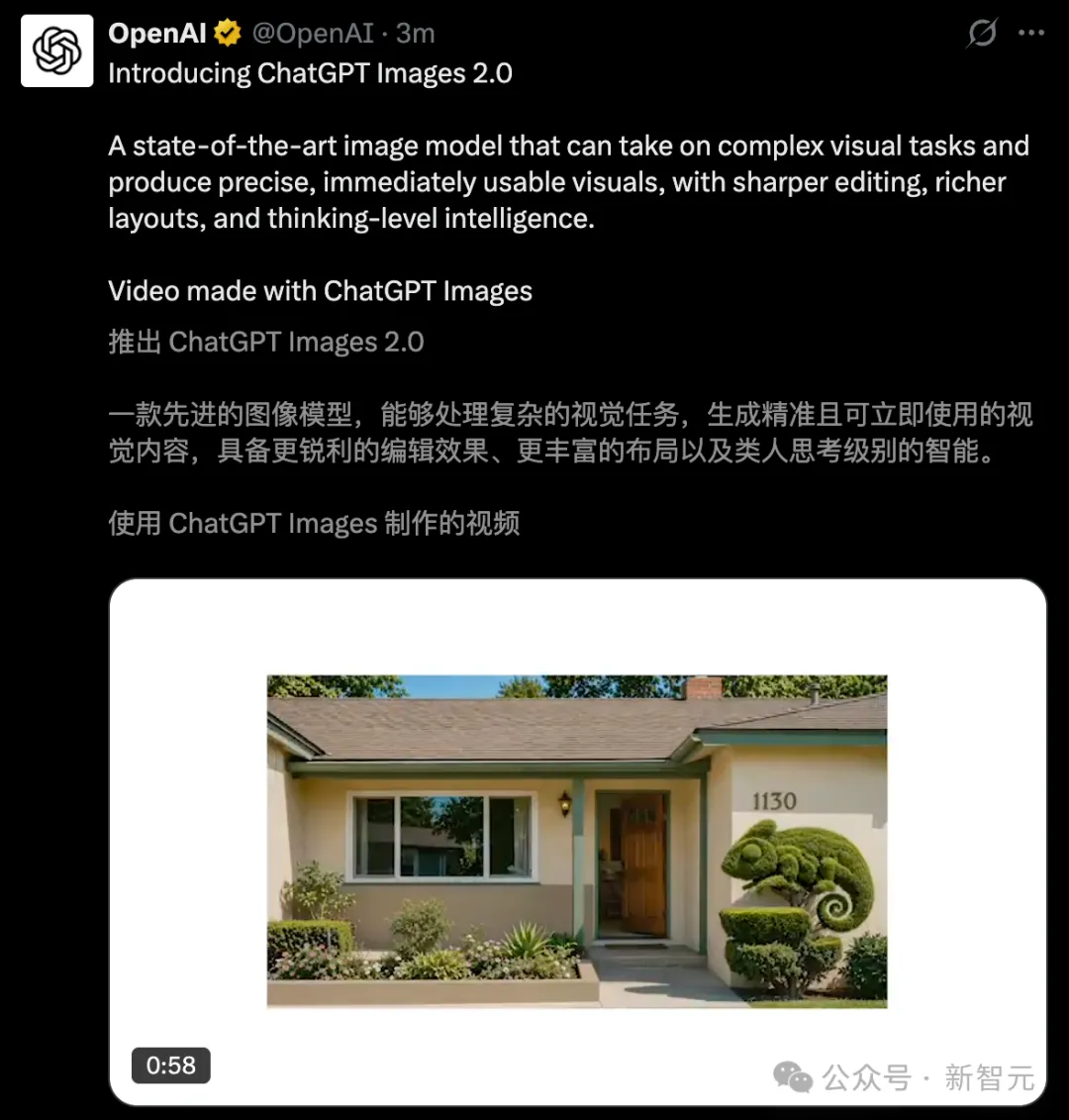
Katakanlah bahawa kelahiran Images 2.0 telah mentakrif semula kekuasaan dalam penghasilan visual—
- Ketepatan piksel demi piksel: hasilkan secara segera butiran kompleks seperti teks saiz kecil, ikon, dan elemen UI; menyokong output penuh dari 3:1 hingga 1:3;
- Perubahan kualitatif pelbagai bahasa: Pemaparan tepat untuk teks bukan Latin seperti Cina, Jepun, dan Korea, bukan sahaja ejaan betul, tetapi juga ayat lancar dan koheren;
- Gaya matang: mampu menguasai bahasa visual seperti kesan fotografi realistik, still filem, seni pixel, dan komik;
- Will Think: Model gambar pertama dengan kemampuan penalaran, boleh mencari dalam talian, memeriksa output sendiri, dan maklumat dikemas kini hingga Disember 2025.
Dalam senarai terkini Arena, Images 2.0 mendominasi dan naik ke puncak takhta AI penghasil gambar global. Mengalahkan Google Nano Banana 2/Pro dengan keunggulan 242 mata.
Ia berada di tempat pertama di semua 7 kategori teks-ke-gambar.


Yang paling menakutkan adalah, ia mampu menghasilkan pada peringkat piksel.
Sebuah gambar padi yang dihasilkan dalam siaran langsung, di mana satu biji padi diberi tulisan "GPT image 2".
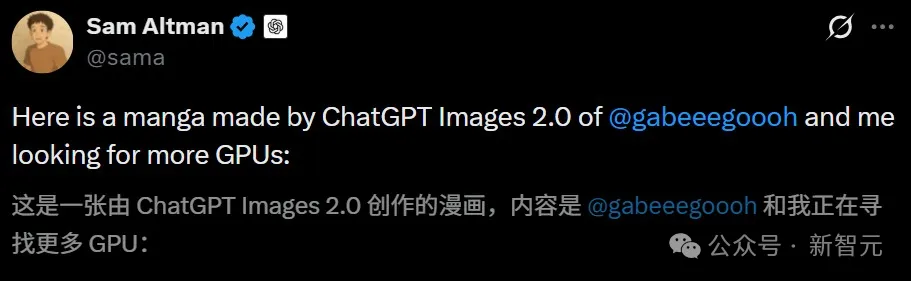
Ultraman juga memperlihatkan lagi, bersama Gabriel Goh, pengendali gambar 4o, lebih banyak gambar komik dengan GPU.

Pengguna internet segera mencuba dan terkesan semula dengan kekuatan Images 2.0.
Bahkan, ada yang menyatakan, "OpenAI akhirnya kembali memimpin bidang penghasilan gambar!"
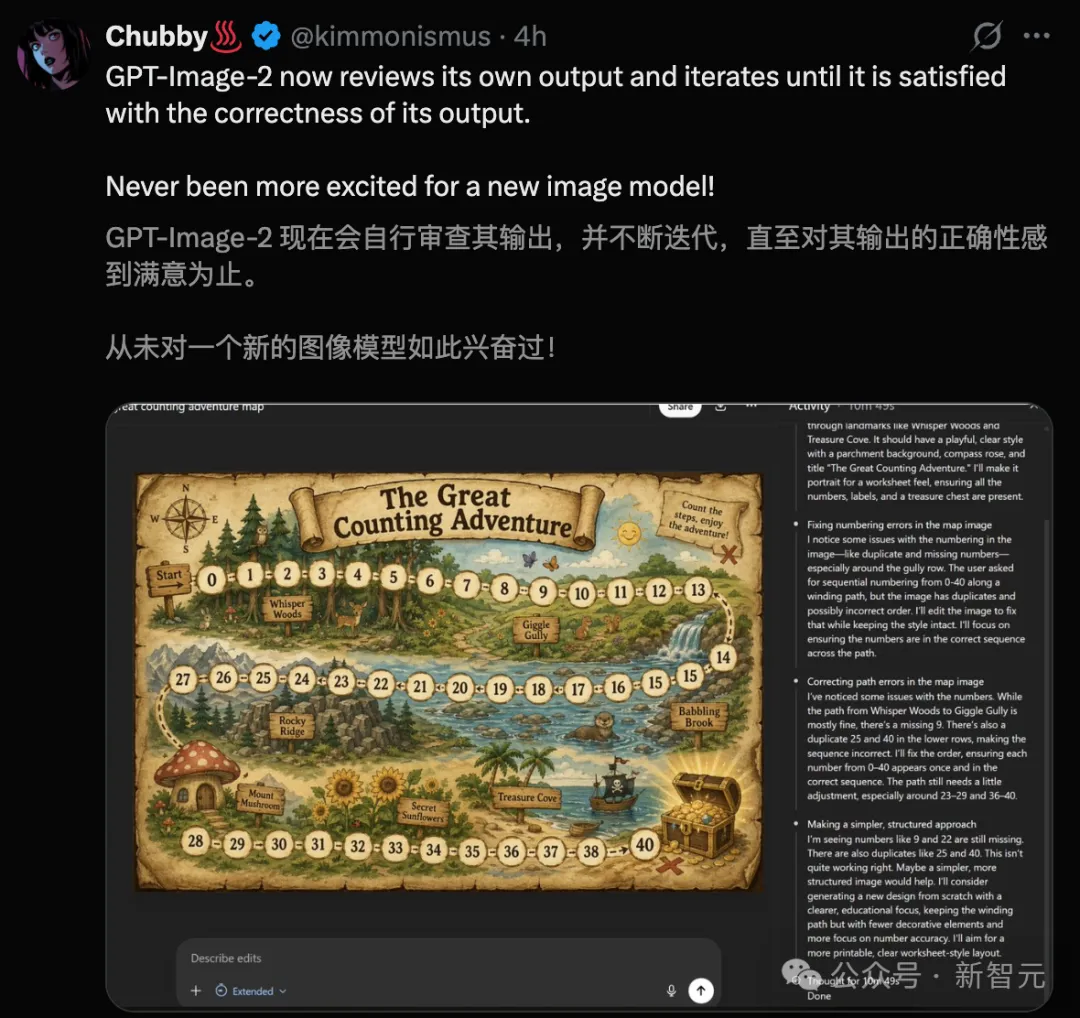

Bahasa Cina secara langsung menjadi dewa, OpenAI sendiri membuat lelucon "menangkapmu dengan mantap"
Model gambar sebelum ini, performa dalam bahasa Inggeris dan bahasa beraksen Latin agak baik, tetapi bila terjumpa dengan teks Cina, Jepun, atau Korea, ia menjadi seperti coretan hantu.
Kali ini, demo bahasa Cina yang dikeluarkan di blog rasmi benar-benar meledak.
Penyelidik OpenAI, Chen Boyuan, muncul secara langsung (kemungkinan besar juga menulis prompt sendiri), menghasilkan satu halaman penuh komik berwarna dalam bahasa Cina, menceritakan kisahnya mengoptimumkan render teks Cina untuk ChatGPT Image 2 di OpenAI.

Gambar ini membuktikan tiga perkara secara serentak: kemampuan render teks Cina yang berubah drastis, kawalan ketepatan pada saiz fon yang sangat kecil, serta kemampuan menghasilkan komik pelbagai panel yang kompleks dalam satu kali proses.
Komik terbahagi kepada lima baris; baris pertama menunjukkan Chen Boyuan bekerja rapat di depan komputer, dengan minuman bubble tea di latar belakang, dan sebiji pisang dilekatkan dengan pita pelekat di dinding (penghormatan kepada adegan terkenal dalam dunia seni).
Baris kedua ialah poster infografik bergaya lukisan tangan yang dihasilkannya untuk kampung halamannya, Wuxi, dengan teks kecil Cina yang padat ditampilkan dengan betul.
Barisan ketiga adalah adegan kegembiraan bersama pasukan setelah melihat kesannya.
Di barisan keempat, suasana berubah, Chen Boyuan sedang beristirahat dengan telefon bimbitnya dan menerima pesan teks dari Ultraman yang mengucapkan selamat atas hasil render bahasa Cina pasukannya.
Kemudian, aksi utama bermula.
Barisan kelima, Chen Boyuan melihat gambar ucapan yang dihasilkan oleh Ultraman, di tengah-tengah tertulis jelas: "Menangkapmu dengan pasti."
Yang faham, pasti faham.

GPT dalam perbualan bahasa Cina sering berkata, “Saya akan menangkapmu dengan pasti,” “Perasaan anda adalah masuk akal,”—bau konseling psikologi Amerika yang berminyak namun ikhlas ini telah menjadi bahan ejekan hebat oleh pengguna Cina selama lebih dari setahun.
Chen Boyuan dalam komik langsung kalah mental, berteriak marah dengan gaya komik, "Astaga! Ia dah belajar menangkap lagi!" Teman sepasukannya berubah menjadi kepala kecil yang berkeringat sejuk, berkata lemah, "Kami sedang berusaha membaikinya!"
Penghinaan diri ini boleh dapat markah penuh. (manual dog head)

Selain bahasa Cina, OpenAI juga melepaskan komik petualangan remaja dengan dialog sepenuhnya dalam bahasa Jepun, sampul buku dalam sembilan bahasa termasuk Hindi, Bengali, dan Telugu untuk kedai buku India, serta iklan penginapan韩屋 tingkat tinggi dalam bahasa Korea.
Bahasa bukan lagi "warga kelas dua" dalam penghasilan imej.

Penghasilan pixel-perfect, lompatan besar dari GPT-3 hingga GPT-5
ChatGPT Images 2.0 boleh dikatakan sebagai langkah bersejarah seterusnya dalam pengeluaran gambar OpenAI.
Dalam siaran langsung, Ultraman menyebutnya, "Rasanya seperti melompat langsung dari GPT-3 ke GPT-5."
Unggah satu gambar bersama empat orang, ChatGPT menghasilkan satu sampul majalah, dengan perancangan halaman dan susunan teks yang sangat teliti.
Selain itu, poster tersebut mengandungi banyak butiran, pengurusan teks kecil, dan konsistensi wajah watak, yang memberikan kesan "boy group".

Dalam segi butiran, output ChatGPT mencapai kesan "fotografik" sepenuhnya, begitu realistik sehingga sukar dikenali sebagai hasil generasi AI.
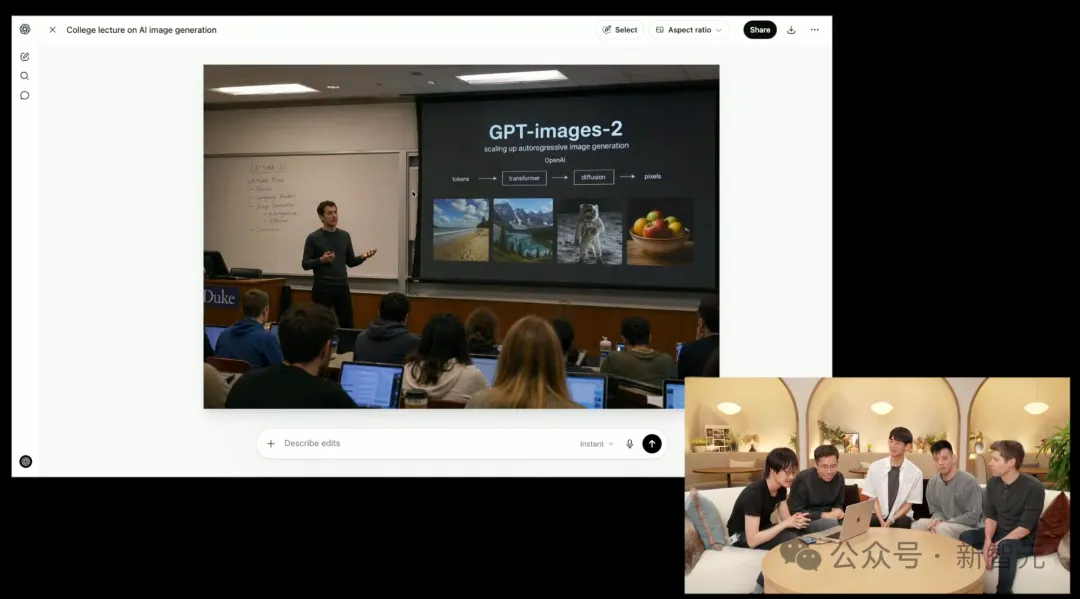
Sebagai contoh, gambar di bawah ini membawa anda kembali ke tahun 2015, ketika OpenAI baru ditubuhkan, suasana cahaya di ruang teater bertingkat dan teks PPT membuat terkejut.
Yang benar-benar membuat seluruh ruangan terkejut ialah gambar panorama 360° seorang manusia mendarat di bulan.
Memasukkan gambar yang dihasilkan oleh ChatGPT ke dalam peninjau panorama membolehkan kesan berikut: kedudukan matahari, arah bayangan, dan beberapa butiran semuanya kelihatan jelas.
Dalam demo yang dikeluarkan oleh pihak rasmi, terdapat tangkapan skrin tingkap ChatGPT di peramban macOS.
Tetingkap bertindih, terminal terbuka di latar belakang, meja kerja berantakan, butiran visual terlalu banyak sehingga hasil yang dihasilkan hampir serupa dengan tangkapan layar sebenarnya.
Ketepatan render pada tahap ini menunjukkan bahawa model telah melintasi titik kritikal dalam pengawasan terhadap setiap piksel dalam gambar.
Gambar yang dihasilkan AI dengan realisme fotografi akhirnya tidak kelihatan seperti AI lagi
Kedalaman gaya adalah lompatan besar lainnya.
Gambar yang dihasilkan oleh AI sebelum ini selalu mempunyai rasa “AI” yang sukar dijelaskan—kulit terlalu licin, cahaya terlalu seragam, komposisi terlalu sempurna, dan boleh dikenali sebagai bukan gambar yang diambil oleh manusia.
Images 2.0 berlawanan arah, mulai belajar "ketidaksempurnaan".
Dalam demo rasmi, terdapat satu set tangkapan layar dengan kesan filem 35mm, kelihatan butiran, komposisi sedikit menyimpang dari pusat, pakaian dan rambut bergerak ditiup angin.
Jika tidak diberitahu bahawa ia dihasilkan oleh AI, anda akan menyangka ia adalah hasil tekanan rana secara kebetulan oleh seorang jurufoto di tepi jalan.

Satu set gambar gaya kamera sekali pakai yang mensimulasikan adegan ruang komputer sekolah menengah Amerika awal 2000-an, di mana pelajar-pelajar berdesak-desakan di hadapan monitor CRT krem sambil menggunakan ChatGPT.
Flash terlalu terang, kabur pergerakan ringan, stempel tarikh oren bertulis "02 18 04" di sudut, semua "ketidaksempurnaan zaman filem" telah dipulihkan dengan tepat.

Dalam keragaman gaya, Images 2.0 juga menciptakan jurang.
Nisbah aspek kini menyokong lebar hingga 3:1 dan tinggi hingga 1:3. Untuk tujuan ini, OpenAI secara khusus memaparkan lukisan pemandangan tradisional Tiongkok dalam bentuk mendatar, dengan teknik tinta dan ruang kosong yang dilakukan dengan cermat.
Poster filem Nouvelle Vague Perancis tahun 1960, penanda buku gaya Art Deco, gambar pengaturan watak anime, setiap bahasa visual mengekalkan konsistensi gaya yang tinggi, bukan sekadar "kelihatan agak serupa".

Model gambar yang berfikir, menghasilkan lapan gambar berterusan dalam satu kali proses
Dalam siaran langsung, Gabriel Goh, ketua imej ChatGPT, menyatakan bahawa Images 2.0 telah melancarkan dua mod—
- Mod Pantas
- Modus Pemikiran
Peningkatan paling revolusioner semuanya tersembunyi dalam "Mod Pemikiran".
Apabila memilih model pemikiran di ChatGPT, Images 2.0 bukan lagi sekadar perender "katakan kepada saya, saya lukis", tetapi berubah menjadi rakan pemikir visual.
Ia akan mengambil lebih banyak masa untuk memahami niat anda, mencari maklumat masa nyata dari internet, membuat inferens tentang struktur imej, sebelum memulakan penulisan.
Lebih penting lagi, dalam modus pemikiran, ia boleh menghasilkan sehingga lapan gambar sekaligus dengan gaya yang selari, watak yang konsisten, dan kandungan yang berterusan.
Hanya muat naik satu gambar wajah, ChatGPT akan segera memberikan lapan set padanan pakaian musim panas. Memilih satu set akan menghasilkan butiran terperinci pakaian dari pelbagai sudut.
Dalam tugas ini, ChatGPT memanggil dua jenis「kecerdasan visual」yang berbeza:
Pertama ialah kemampuan “pemahaman visual”, yang perlu benar-benar “melihat” gambar. Memahami penampilan seseorang, kemudian merancang cadangan pakaian yang sesuai.
Dimensi lain ialah kemampuan «penghasilan visual». Ia perlu menukar susunan pakaian yang telah dirancang menjadi satu gambar yang selari dan teratur.
Dahulu, untuk membuat set bahan media sosial, anda perlu menghasilkan satu persatu dan menyusunnya sendiri. Sekarang, dengan satu prompt sahaja, empat saiz—Twitter, Instagram Stories, Instagram Feed, LinkedIn—dikeluarkan serentak, dengan warna dan gaya komposisi yang seragam.
Demo rasmi menunjukkan bahan iklan untuk kedai matcha Brooklyn, 'kizuki', dengan gambar matcha strawberi sejuk di bawah sinar matahari, dikombinasikan dengan estetik pakaian jalan dan kesederhanaan Jepun, dengan saiz untuk empat platform sosial dalam satu langkah.

Terdapat demo poster kertas akademik, muat naik PDF secara langsung, model akan mengekstrak grafik, data, dan struktur utama secara automatik, serta menyusunnya menjadi satu poster landskap.

Perlu ditekankan bahawa selepas Images 2.0 menghidupkan mod pemikiran, ia boleh mencari maklumat secara langsung melalui internet.
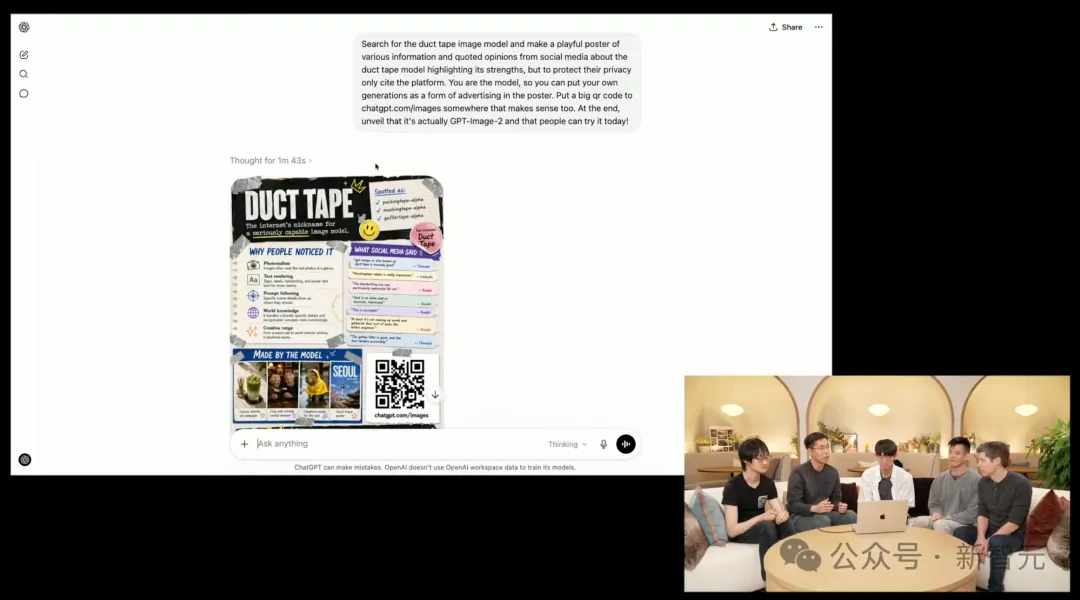
Pasukan mengungkapkan bahawa "DuckTape" yang diuji secara buta di Arena beberapa hari yang lalu ialah Images 2.0 hari ini.
Kemudian, mereka meminta Images 2.0 mengumpulkan maklum balas daripada pengguna internet dan menjadikannya sebagai satu gambar. Tidak disangka, model tersebut juga menghasilkan「kod QR」yang boleh dipindai terus.
ChatGPT, Codex dibuka sepenuhnya
Mulai hari ini, semua ChatGPT dan Codex boleh menggunakan ChatGPT Images 2.0.
Fungsi penghasilan imej dengan proses "berfikir" telah dibuka kepada pengguna ChatGPT Plus, Pro, dan Business. Model asas gpt-image-2 juga telah dilancarkan dalam API.

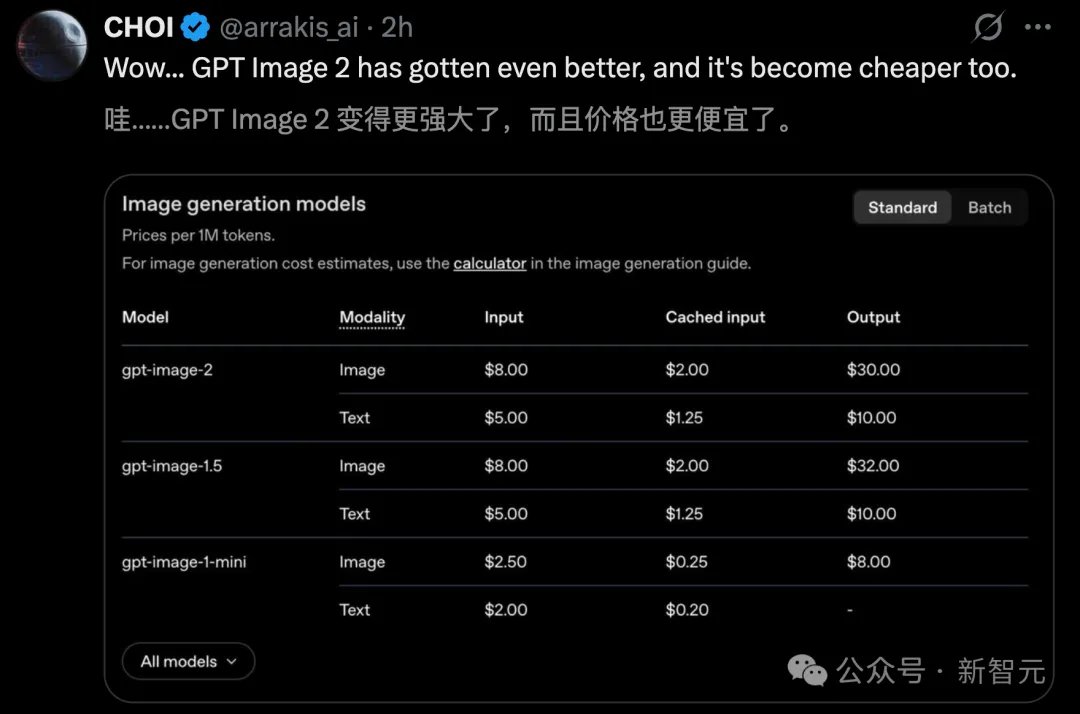
Dalam hal penentuan harga, ChatGPT Images 2.0 menjadi lebih kuat, sementara harga input/output token tidak meningkat.
Bagi pengguna biasa, kerja-kerja yang dahulu memerlukan masa lama untuk mengolah gambar presentasi, poster media sosial, atau kad promosi produk dengan Photoshop, kini boleh diselesaikan dengan satu prompt sahaja.
Bagi pembangun dan perusahaan, alur kerja visual yang memerlukan banyak usaha manual seperti iklan dilokalkan, infografik berbilang bahasa, kandungan pendidikan, dan alat reka bentuk kini boleh diotomatiskan secara berjumlah melalui API.
Codex juga mengintegrasikan penghasilan gambar ke dalam ruang kerja, membolehkan pasukan reka bentuk mencipta penyelesaian UI, membandingkan pilihan, dan beralih ke produk dalam satu persekitaran tanpa perlu menukar alat.
Momen iPhone untuk penghasilan gambar?
Melihat semula, dari DALL·E hingga Midjourney hingga Stable Diffusion, penghasilan imej AI sentiasa berada dalam keadaan “cukup guna tetapi tidak terlalu baik”.
Masalah pemaparan teks yang gagal, sokongan pelbagai bahasa yang lemah, gaya yang seragam, dan komposisi yang jelas dibuat oleh AI, setiap masalah ini menghalang orang yang ingin menggunakan gambar AI dalam konteks serius.
Images 2.0 memperbaiki semua kelemahan ini sekaligus, serta menambahkan kemampuan berfikir dan menghasilkan banyak gambar sekaligus.
Walaupun ia masih jauh dari "sempurna", ia mungkin merupakan model imej AI pertama yang membuat pelanggan, pemasar, dan pencipta kandungan merasa, "Ini adalah perkara yang benar-benar boleh saya gunakan dalam kerja saya."
Sekarang, para reka bentuk mungkin perlu memikirkan semula di mana parit pertahanan mereka sebenarnya.
Rujukan:
https://x.com/OpenAI/status/2046661795327459677
https://x.com/OpenAI/status/2046670977145372771
https://openai.com/index/introducing-chatgpt-images-2-0/
https://x.com/sama/status/2046672912833458597