










Sumber: Institut Penyelidikan CoinW
Ringkasan
Gradients ialah sub-jaringan pelatihan AI terdesentralisasi yang dibina di atas Bittensor (SN56), dengan inti utama dalam mekanisme seperti "penerbitan tugas, persaingan penambang, dan penyaringan pengesahan" untuk mengubah proses pelatihan model daripada prosedur teknikal yang kompleks kepada proses kerjasama rangkaian yang didorong pasaran. Dari segi架构, ia menggabungkan AutoML dengan kuasa pengiraan teragih untuk membentuk pasaran pelatihan yang berpusat pada mekanisme insentif, bukan sahaja mengurangkan halangan penggunaan AI tetapi juga meningkatkan kecekapan penggunaan kuasa pengiraan. Dari segi ekosistem dan prestasi data, Gradients telah menyelesaikan pembinaan rangka asas, tetapi insentif dan aliran dana pada masa ini masih terhad. Gradients melengkapi infrastruktur pelatihan dalam ekosistem TAO serta meneroka paradigma baharu "pengoptimuman AI yang didorong pasaran", dengan potensi jangka panjang untuk menjadi lapisan masuk penting dalam pelatihan AI terdesentralisasi.
1. Bermula dengan Web2 AutoML: Keadaan dan Keterbatasan Latihan AI
1.1 Apakah itu AutoML
Dalam pemahaman tradisional, melatih model AI adalah perkara yang memerlukan rintangan tinggi, di mana jurutera perlu mengurus data, memilih model, menyesuaikan parameter berulang kali, serta menilai keberkesanannya—keseluruhan proses ini kompleks dan memakan masa. Kehadiran AutoML (pembelajaran mesin automatik) pada dasarnya menggabungkan langkah-langkah rumit ini menjadi automatik. Ia boleh difahami sebagai "alat automatik untuk membina model": pengguna hanya perlu menyediakan data dan memberitahu sistem tujuan yang ingin dicapai, seperti pengelasan, ramalan, atau pengenalan, manakala seluruh proses seterusnya—termasuk memilih model, menyesuaikan parameter, dan melatih serta mengoptimumkan—diselesaikan secara automatik oleh sistem. Ini menjadikan AI berubah dari alat hanya untuk sedikit jurutera pakar kepada kemampuan yang boleh digunakan oleh pembangun biasa bahkan perusahaan, merupakan langkah penting dalam penyebaran AI.
1.2 Hadangan utama AutoML tradisional
Pengimplementasian utama AutoML semasa ini berfokus pada platform penyedia awan, seperti Google Vertex AI dan AWS SageMaker, yang menawarkan “latihan AI sebagai perkhidmatan”. Walaupun AutoML Web2 secara ketara mengurangkan halangan penggunaan AI, model dasarnya masih mempunyai kelemahan yang jelas. Pertama, masalah terpusat: kuasa pengiraan, penetapan harga, dan peraturan sepenuhnya dikendalikan oleh platform, menjadikan pengguna sangat bergantung kepada penyedia tunggal dan kurang memiliki kekuatan tawar-menawar. Kedua, kosnya tinggi dan tidak telus; sumber GPU yang diperlukan untuk latihan AI terutamanya dikendalikan oleh penyedia awan, dengan mekanisme harga yang kurang bersaing secara pasaran. Lebih penting lagi, kecekapan pengoptimuman mempunyai had. AutoML tradisional pada dasarnya masih “satu sistem yang membantu anda mencari penyelesaian terbaik”, sama ada sistem itu sekompleks apa pun, ia tetap merupakan pengoptimuman dalam satu lintasan teknologi tunggal. Ruang penjelajahannya terhad, dan sukar untuk mencuba pelbagai pendekatan yang sangat berbeza secara serentak. Oleh itu, latihan AI Web2 semasa ini merupakan “sistem tertutup”, di mana latihan, pengoptimuman, dan pengagihan sumber model berlaku dalam persekitaran yang dikawal oleh satu platform tunggal. Model ini walaupun cekap, semakin menunjukkan batasannya seiring dengan pertumbuhan permintaan.
2. Gradients: Menggunakan "rangkaian" untuk membina semula latihan AI
2.1 Gradients ialah: sebuah platform AutoML terdesentralisasi
Dalam bahagian sebelumnya, kita menyebutkan bahawa masalah utama AutoML Web2 tradisional ialah "sistem tertutup", di mana latihan model bergantung pada platform, laluan pengoptimuman terhad, dan pergerakan sumber terhad. Gradients merupakan reka semula terhadap model ini. Gradients berasal daripada komuniti jurutera terdesentralisasi yang diprakarsai oleh WanderingWeights, dibina di atas rangkaian Bittensor, dan merupakan subnet pelatihan AI yang berjalan di Subnet 56. Berbeza dengan platform tradisional, ia tidak menyediakan perkhidmatan terpusat, tetapi memecahkan proses latihan dan menyerahkannya kepada rangkaian terbuka. Pengguna hanya perlu menentukan objektif tugas, seperti jenis model dan data, manakala proses seterusnya termasuk pelaksanaan latihan, pengoptimuman parameter, dan penapisan hasil, semuanya akan diselesaikan secara automatik oleh rangkaian. Dalam model ini, pelatihan AI diabstrakkan daripada proses kejuruteraan yang kompleks kepada proses mudah "hantar permintaan, terima hasil", lebih dekat kepada keupayaan am, bukan kerja teknikal yang memerlukan tahap keahlian yang sangat tinggi.
2.2 Dari Sistem Tertutup kepada Kolaborasi Terbuka: Apakah Masalah yang Diselesaikan oleh Gradients
Perubahan utama Gradients terletak pada peralihan proses latihan yang sebelumnya tertutup dalam satu platform tunggal menjadi proses rangkaian kolaboratif terbuka. Tugas latihan tidak lagi diselesaikan oleh satu sistem tunggal, tetapi dibahagikan kepada pelbagai peserta untuk dicuba secara selari, kemudian disaring melalui mekanisme penilaian seragam untuk memilih hasil terbaik. Struktur ini pertama-tama mengurangkan ketergantungan kepada penyedia terpusat, menjadikan latihan berasaskan kuasa pengiraan terdistribusi; sambil mengintegrasikan sumber GPU yang tersebar ke dalam rangkaian yang sama, membentuk cara pengagihan sumber yang lebih mendekati pasaran melalui persaingan. Lebih penting lagi, pengoptimuman model tidak lagi terhad kepada satu laluan tunggal, tetapi terus mendekati penyelesaian yang lebih baik melalui eksplorasi selari pelbagai kaedah, seterusnya meningkatkan had pengoptimuman keseluruhan.
2.3 Perubahan esensial: Dari alat ke "pasar latihan"
Dalam AutoML tradisional, platform lebih seperti alat yang membantu pengguna mencari penyelesaian terbaik melalui algoritma dalaman. Namun, dalam Gradients, proses ini lebih mirip dengan "pasar" yang beroperasi secara berterusan: pengguna mempublikasikan keperluan mereka, pelbagai peserta bersaing untuk tugas yang sama, dan hasilnya disaring melalui mekanisme penilaian. Dengan ini, prestasi model tidak lagi bergantung pada kemampuan sistem tunggal, tetapi datang daripada persaingan dan iterasi berterusan di kalangan pelbagai pihak. AutoML juga berubah daripada masalah pengoptimuman teknikal yang相对 tertutup kepada proses dinamik yang didorong oleh insentif, membolehkan kapasiti pengoptimuman terus berkembang seiring dengan peningkatan bilangan peserta. Perubahan ini menjadikan latihan AI mula memiliki ciri evolusi diri yang serupa dengan pasaran.
2.4 Peranan dalam ekosistem TAO: Lapisan infrastruktur latihan AI
Dalam sistem subnetwork Bittensor, subnetwork yang berbeza menjalankan fungsi yang berbeza seperti inferens, pemprosesan data, dan latihan, manakala Gradients berada di lapisan latihan. Ia bertanggungjawab untuk menukar kuasa pengiraan yang tersebar menjadi hasil model sebenar, serta membolehkan sumber-sumber ini dijadualkan dan dioptimumkan secara berterusan melalui mekanisme pembahagian tugas dan penilaian. Sambil menghubungkan bekalan kuasa pengiraan dengan keperluan model, Gradients mengubah proses latihan daripada proses penggunaan sumber semata-mata kepada proses kerjasama rangkaian yang boleh diorganisasi dan dioptimumkan. Dalam sistem ini, Gradients lebih seperti satu elemen pusat yang menukar sumber teragih menjadi keupayaan AI yang boleh digunakan, serta menyokong perkembangan aplikasi lapisan atas.
3. Arsitek utama: Bagaimana latihan AI dilakukan dalam rangkaian
Dalam bahagian sebelumnya, kami menyebut bahawa Gradients mengubah latihan AI dari "selesai di dalam platform" kepada "diselesaikan secara kolaboratif melalui rangkaian". Jadi, bagaimanakah rangkaian ini berfungsi secara spesifik? Inti bahagian ini ialah untuk menguraikan proses ini dengan cara yang lebih intuitif.
3.1 Latihan teragih: Bagaimana satu tugas dilakukan oleh "banyak orang"
Anda boleh membayangkan Gradients sebagai "rangkaian kolaboratif latihan" yang berjalan secara berterusan. Apabila pengguna menghantar tugas latihan, tugas tersebut tidak akan diberikan kepada satu sistem sahaja, tetapi akan disebarkan serentak kepada pelbagai peserta dalam rangkaian. Peserta-peserta ini akan mencuba kaedah latihan yang berbeza berdasarkan data dan matlamat yang sama, serta menghantar hasil mereka dalam masa yang ditetapkan. Selepas itu, sistem akan menilai semua hasil tersebut secara seragam dan memilih kaedah terbaik. Hasil yang lebih baik akan menerima ganjaran, manakala kaedah lain akan dikeluarkan. Dari sudut pandangan pengguna, proses ini hanya memerlukan satu permintaan tugas, tetapi seolah-olah "memanggil" pelbagai pendekatan pengoptimuman secara serentak dan secara automatik memilih penyelesaian terbaik. Kunci kaedah ini bukanlah kekuatan setiap nod individu, tetapi pada percubaan selari oleh ramai orang + penapisan automatik, yang membuatkan hasil terus mendekati penyelesaian terbaik.
Dalam rangkaian ini, terdapat tiga kategori peserta utama: pengguna, penambang, dan penverifikasi. Pengguna bertanggung jawab untuk mengajukan permintaan pelatihan; penambang menyediakan daya komputasi dan mencuba pelbagai kaedah pelatihan; penverifikasi bertanggung jawab untuk menilai hasil dan memilih model terbaik. Pembahagian tugas ini membolehkan proses pelatihan berjalan secara berterusan dan terus memilih penyelesaian yang lebih baik. Secara keseluruhan, ia membentuk rangkaian kolaboratif yang didorong oleh “permintaan, bekalan, dan penilaian”.
3.2 AutoML yang didorong pasaran
Dalam dekomposisi mekanisme sebelumnya, dapat dilihat bahawa Gradients bukan sekadar memindahkan AutoML ke rantai, tetapi mengubah logik asas pengoptimuman model melalui pengenalan penyertaan pihak banyak dan mekanisme insentif. AutoML tradisional bergantung pada sistem tunggal untuk mencari penyelesaian terbaik dalam laluan terhad, manakala dalam Gradients, proses ini diperluaskan ke seluruh rangkaian: peserta yang berbeza terus mencuba kaedah yang berbeza untuk tugas yang sama, dan menyaring serta mengiterasi secara berterusan melalui penilaian seragam. Ini menjadikan pengoptimuman model bukan sekadar proses pengiraan sekali jadi, tetapi proses dinamik yang boleh berkembang berulang-ulang. Dalam mekanisme ini, hasil yang lebih cekap akan memperoleh keuntungan lebih tinggi, dengan begitu terus menarik penyertaan untuk mengoptimumkan strategi dan mendorong peningkatan keseluruhan.
4. Mekanisme insentif dan persaingan: Bagaimana latihan AI membentuk "siklus positif"
4.1 Mekanisme insentif (digerakkan oleh TAO): Dari tindakan latihan hingga pulangan keuntungan
Kekaluan operasi Gradients bergantung pada mekanisme insentif di belakangnya, yang bergantung pada sistem insentif asli yang disediakan oleh Bittensor. Di sini, TAO adalah token asli jaringan Bittensor, berfungsi sebagai "pembawa nilai" dalam keseluruhan jaringan: ia digunakan untuk memberi ganjaran kepada peserta yang menyumbangkan kekuatan komputasi dan sumbangan model, serta terlibat dalam pembahagian bobot sub-jaringan melalui cara-cara seperti penjagaan, yang mempengaruhi bagaimana sumber daya mengalir antara sub-jaringan yang berbeza.
Rangkaian utama Bittensor akan terus menghasilkan emisi insentif baru iaitu TAO (jumlah harian yang sesuai kini sekitar 3600 TAO), dan ia akan dibahagikan kepada sub-rangkaian yang berbeza mengikut peraturan tertentu. Jumlah TAO yang diterima oleh setiap sub-rangkaian bergantung kepada “prestasi”nya dalam keseluruhan rangkaian, seperti tahap keaktifan, kualiti sumbangan, dan sokongan pendanaan. Bagi sub-rangkaian tempat Gradients berada, TAO yang diperoleh ini akan dibahagikan semula di dalamnya kepada peserta. Dasar utama pembahagian ialah siapa yang menyumbang model yang lebih baik, mereka akan mendapat lebih banyak keuntungan.
Secara khusus, penambang menghantar keputusan latihan, manakala pemeriksa bertanggungjawab untuk menguji dan memberi markah keputusan-keputusan ini. Sistem akan mengira "gewang sumbangan" setiap peserta berdasarkan markah, kemudian membahagikan hadiah mengikut gewang tersebut. Model yang berprestasi lebih baik (contohnya, dengan kemampuan penggeneralisasian yang lebih kuat dan kestabilan yang lebih tinggi) akan memperoleh keuntungan yang lebih tinggi, sementara pemeriksa yang memberi markah lebih tepat dan lebih mencerminkan kualiti sebenar juga akan menerima insentif yang lebih banyak. Reka bentuk ini menjadikan "melakukan lebih baik" secara langsung berkaitan dengan "mendapat lebih banyak", yang mendorong peserta untuk terus mengoptimumkan model.
4.2 Persaingan antara sub-jaringan: bukan hanya persaingan dalaman, tetapi juga peringkat luaran
Selain persaingan di dalam sub-jaringan, Gradients juga menghadapi "persaingan lateral" di seluruh rangkaian Bittensor. Kerana agihan TAO adalah dinamik, sub-jaringan yang berbeza akan bersaing untuk mendapatkan bobot yang lebih tinggi. Hanya sub-jaringan yang terus menghasilkan hasil berkualiti tinggi dan menarik lebih banyak peserta yang akan mendapat bahagian ganjaran yang lebih besar. Oleh itu, insentif Gradients tidak hanya bergantung pada prestasi model dalaman, tetapi juga pada daya saing relatifnya dalam ekosistem keseluruhan. Seluruh sistem membentuk satu mekanisme umpan balik berlapis: di dalam sub-jaringan terdapat persaingan antara model; antara sub-jaringan terdapat persaingan prestasi keseluruhan. Pada akhirnya, input kuasa pengiraan, kesan model, dan pulangan ekonomi diikat bersama, membentuk satu mekanisme umpan balik positif yang berterusan.
4.3 Gradien 5.0: Dari Persaingan ke "Mekanisme Turnamen"
Berdasarkan persaingan berterusan pada peringkat awal, Gradients telah berkembang menjadi mekanisme yang lebih terstruktur, iaitu "latihan bertarung". Ia boleh difahami sebagai pertandingan berkala: setiap putaran latihan akan menetapkan jendela masa, di mana pelbagai peserta bersaing dalam tugas yang sama dan secara berperingkat diterima atau disingkirkan melalui beberapa pusingan, sehingga akhirnya memilih penyelesaian terbaik. Bentuk ini menekankan perbandingan berperingkat dan penilaian terfokus. Satu perubahan penting ialah penambang tidak lagi menghantar hasil latihan secara langsung, tetapi menghantar "kaedah latihan" (kod), yang kemudian dilaksanakan secara seragam oleh nod pengesahan. Tindakan ini meningkatkan keadilan dengan mengelakkan gangguan daripada persekitaran pengiraan yang berbeza, serta lebih baik melindungi privasi data dan proses latihan. Selain itu, penyelesaian pemenang seringkali akan disimpan sebagai kaedah yang boleh digunakan semula, serupa dengan "amalan terbaik" yang terus dikumpulkan. Dalam jangka panjang, mekanisme ini bukan sahaja menyaring model terbaik, tetapi juga membina perpustakaan kaedah latihan yang terus berkembang.
5. Status ekosistem
5.1 Struktur peserta: Rangkaian kolaborasi yang terdiri daripada permintaan, penawaran, dan penilaian
Ekosistem Gradients terdiri daripada tiga peranan utama: pengguna (sisi permintaan), penambang (sisi penawaran), dan pengesah (sisi penilaian). Pengguna terutamanya termasuk pembangun AI, usaha kecil dan sederhana, serta pembina Web3, yang biasanya memiliki asas teknikal tertentu tetapi kurang memiliki kekuatan pengiraan atau kemampuan latihan model yang lengkap, oleh itu lebih cenderung menggunakan Gradients untuk membina model dengan kos yang lebih rendah. Penambang menyediakan kekuatan GPU dan bersaing dalam tugas latihan, dengan motivasi utama mereka ialah memperoleh ganjaran TAO; pengesah bertanggungjawab untuk menilai dan mengurutkan hasil latihan, menjadi elemen penting dalam memastikan kualiti model dan keberkesanan mekanisme berfungsi.
Dari segi profil pengguna yang lebih halus, kumpulan pengguna sebenar Gradients menunjukkan ciri "separuh pembangun": berbeza daripada makmal AI terkemuka dan bukan pengguna biasa tanpa latar belakang teknikal, tetapi terutamanya terdiri daripada pembangun dengan kemampuan kejuruteraan dan pengguna teknologi Web3. Ini juga tercermin dalam struktur komuniti mereka, di mana ekosistem semasa didominasi oleh bahasa Inggeris, dengan pengguna utama terletak di kalangan pembangun di Amerika Utara dan Eropah, sambil merangkumi sebahagian penambang Asia Tenggara dan penyedia sumber GPU global. Secara keseluruhan, ia hampir seperti komuniti pembangun yang digerakkan oleh teknologi.
5.2 Status Semasa Ekosistem
Pada 12 Mei, harga token alpha Gradients adalah sekitar 0.0255 TAO, dengan jumlah alamat pemegang sebanyak 4,890, penambang 243, dan validator 12, dengan peratusan Emission sebanyak 1.61%. Pada masa yang sama, peratusan TAO dalam kolam likuiditi adalah 2.19%, manakala Alpha adalah 97.81%. Dari segi harga dan jumlah pemegang, Gradients telah memiliki asas pengguna dan perhatian tertentu, tetapi keseluruhan masih berada dalam peringkat awal penyebaran. Berbanding dengan projek terkemuka dalam ekosistem TAO, Chutes, harga token alpha pada hari tersebut adalah 0.0877 TAO, dengan jumlah alamat pemegang sebanyak 13,409.
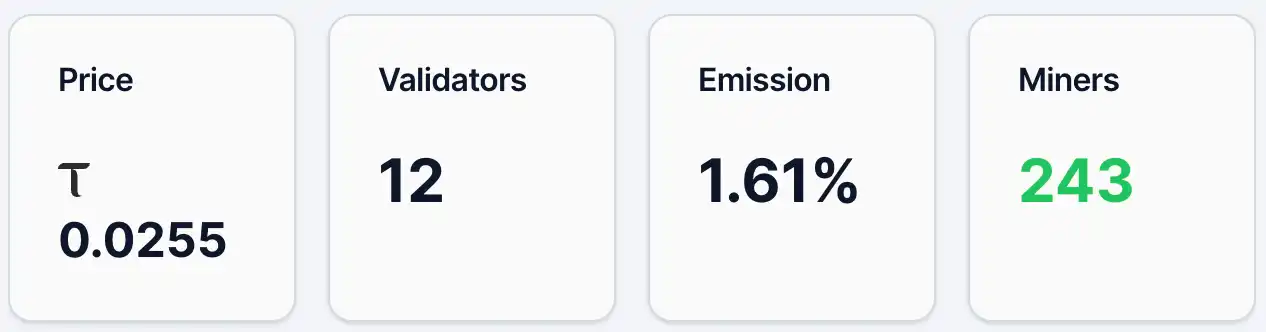
Rajah 1. Data gradien.
Sumber:https://bittensormarketcap.com/subnets/56
Seterusnya adalah mekanisme insentif Emission. Dalam sistem Bittensor, Emission merujuk kepada bobot pengagihan semasa bagi sub-jaringan dalam tambahan ganjaran keseluruhan rangkaian. Rangkaian Bittensor terus menghasilkan TAO baru dan mengagihkannya mengikut bobot kepada setiap sub-jaringan, dan 1.61% semasa Gradients bermakna ia hanya menerima sebahagian kecil daripada tambahan insentif keseluruhan rangkaian. Indikator ini pada dasarnya mencerminkan “keputusan undian” pasaran terhadap sub-jaringan yang berbeza melalui arus dana (seperti staking). Oleh itu, tahap 1.61% biasanya bermakna pengiktirafan pasaran dan aliran dana pada masa ini masih terhad, tetapi di sisi lain juga menunjukkan bahawa terdapat ruang untuk meningkatkan bobot di masa depan. Dari segi struktur dana (kolam likuiditi), peratusan TAO hanya 2.19%, manakala Alpha pula mencapai 97.81%, yang menunjukkan bahawa aliran dana luar masih terhad, dan pada masa ini lebih banyak didorong oleh bekalan dalaman sub-jaringan. Harga sangat sensitif terhadap dana tambahan; sekiranya lebih banyak TAO mengalir masuk, ia mungkin membawa kesan ganda yang lebih ketara.
6. Landsekap persaingan dan kelebihan serta kekurangan
6.1 Posisi industri: Infrastruktur latihan AutoML terdesentralisasi
Gradients berada di segmen "infrastruktur latihan AI + AutoML terdesentralisasi". Ia berusaha membebaskan latihan model daripada platform terpusat dan mencapai penggunaan sumber daya serta pengoptimuman model yang lebih cekap melalui mekanisme rangkaian. Dalam sistem Web2, segmen ini sudah relatif matang, dengan perwakilan klasik termasuk Google Vertex AI dan AWS SageMaker. Platform-platform ini menyediakan perkhidmatan latihan dan pelaksanaan model satu atap kepada pembangun melalui komputasi awan, tetapi esensinya masih merupakan arsitektur terpusat. Sebaliknya, perbezaan Gradients bukan terletak pada "lebih banyak fungsi", tetapi pada logik asas yang berbeza: ia mengubah latihan daripada "perkhidmatan platform" kepada "kerjasama rangkaian", dan menggunakan mekanisme persaingan untuk memilih hasil terbaik, menjadikannya lebih hampir kepada sistem latihan yang beroperasi secara pasaran.
6.2 Perbandingan mendatar: Perbezaan antara Web2 dan Web3 AutoML
Dari perspektif yang lebih luas, perbezaan antara Web2 dan Web3 dalam arah AutoML pada dasarnya adalah perbandingan antara dua paradigma yang berbeza. Model Web2 menekankan kecekapan dan kestabilan, dengan memusatkan sumber dan pengoptimuman kejuruteraan untuk memberikan pengalaman perkhidmatan yang terkawal dan matang; manakala model Web3 pula lebih menekankan keterbukaan dan mekanisme insentif, dengan memperkenalkan penyertaan pelbagai pihak supaya pengoptimuman model terus berkembang melalui persaingan. Secara khusus, AutoML Web2 lebih seperti "alat yang kuat", di mana pengguna menyerahkan tugas kepada platform dan sistem secara dalaman mencari penyelesaian terbaik; manakala AutoML Web3 yang diwakili oleh Gradients pula lebih seperti "pasar terbuka", di mana pengguna mengumumkan keperluan mereka, dan pelbagai peserta menyediakan penyelesaian, kemudian hasilnya disaring melalui mekanisme penilaian. Perbezaan ini membawa kesan langsung: yang pertama lebih stabil dan terkawal, tetapi laluan pengoptimuman terhad; yang kedua mempunyai ruang eksplorasi yang lebih besar dan had potensi yang lebih tinggi, tetapi masih memerlukan peningkatan dalam hal kestabilan dan kematangan.
6.3 Perbezaan Gradients dalam Web3
Dalam lanskap Web3 AI semasa, kebanyakan projek masih berfokus pada lapisan inferens atau arah AI Agent, sementara projek yang secara khusus menekankan “infrastructure latihan”相对较少。Sebahagian projek cuba menggabungkan rangkaian komputasi atau rangkaian data untuk menyediakan kemampuan latihan, tetapi secara keseluruhan, kebanyakan masih berada pada tahap pengurusan sumber atau pasaran komputasi. Perbezaan Gradients ialah ia tidak hanya menyediakan penyesuaian komputasi, tetapi juga melangkah lebih jauh ke “mekanisme pengoptimuman model” itu sendiri, dengan memperkenalkan sistem penilaian dan persaingan, menjadikan proses latihan mampu berkembang secara berterusan. Ini bermakna, ia tidak hanya menyelesaikan “komputasi datang dari mana”, tetapi juga menyelesaikan “bagaimana menggunakan komputasi ini dengan lebih cekap”. Dari segi penempatan, Gradients lebih dekat kepada rangkaian “berorientasikan hasil latihan”, bukan sekadar pasaran komputasi atau platform alat, dan inilah perbezaan utamanya dengan kebanyakan projek Web3 AI.
6.4 Kelebihan Utama: Peningkatan Kecekapan yang Digerakkan oleh Mekanisme
Secara keseluruhan, kelebihan Gradients terutama terletak pada reka bentuk mekanismenya. Pertama, ia mengurangkan rintangan penggunaan melalui abstraksi tugas, membolehkan pengguna mendapatkan hasil model tanpa perlu terlibat secara mendalam dalam proses latihan yang kompleks, dengan demikian memperluas kalangan pengguna potensial. Kedua, dari segi sumber, pengenalan kuasa komputasi teragih menjadikan latihan tidak lagi bergantung kepada penyedia awan tunggal, dan secara teori boleh membentuk struktur kos yang lebih fleksibel melalui persaingan. Lebih penting lagi, perubahan dalam cara pengoptimuman. Dengan eksplorasi selari oleh pelbagai peserta dan penggabungan mekanisme penapisan, Gradients menawarkan satu pendekatan berbeza daripada pengoptimuman laluan tunggal tradisional, membolehkan model mencapai prestasi yang lebih baik dalam masa yang lebih singkat. Model “pengoptimuman yang didorong oleh persaingan” ini merupakan kelebihan paling asasnya.
6.5 Cabaran berpotensi
Kualiti model mungkin menghadapi isu kestabilan. Latihan terpusat bergantung pada penyertaan pihak banyak, walaupun boleh meningkatkan had atas, ia juga boleh membawa kepada fluktuasi hasil, dan berbanding sistem terpusat, ia mempunyai ketidakpastian tertentu dalam kawalan. Kedua, isu kepercayaan perniagaan. Bagi pengguna perniagaan, keselamatan data dan kebolehverifikasian proses latihan adalah sangat penting, dan bagaimana memastikan data tidak disalahgunakan serta hasil boleh diaudit dalam persekitaran terdesentralisasi masih menjadi ujian utama. Akhir sekali, ketergantungan terhadap ekonomi Token. Operasi Gradients sangat bergantung kepada mekanisme insentif; jika tarikan pulangan TAO menurun, ia mungkin mempengaruhi tahap penyertaan penambang dan aktiviti rangkaian keseluruhan. Oleh itu, kelestarian jangka panjangnya sebahagiannya bergantung kepada sama ada model ekonomi mampu membentuk kitaran positif yang stabil.
7. Prospek Masa Depan: Adakah AutoML terpusat boleh berjaya?
Dari perspektif peringkat semasa, Gradients masih berada dalam peringkat awal, dan keberjayaan masa depannya bergantung kepada beberapa faktor utama. Yang paling penting ialah sama ada ia mampu menarik permintaan latihan sebenar secara berterusan, bukan sekadar partisipasi yang didorong oleh insentif; seterusnya, kualiti model—adakah pendekatan terdesentralisasi mampu menghasilkan hasil yang boleh digunakan, atau bahkan lebih baik, secara stabil; serta sama ada mekanisme ekonomi mampu membentuk kitaran positif, memastikan keseimbangan jangka panjang antara bekalan kuasa pengiraan dan keuntungan.
Dalam konteks industri yang lebih luas, latihan AI sedang memisahkan menjadi dua lintasan. Satu adalah model Web2, yang dipimpin oleh syarikat teknologi terkemuka, yang terus memperkuat prestasi model melalui sumber daya dan kemampuan kejuruteraan yang terpusat, dengan kelebihan dalam kestabilan dan kematangan; yang lain adalah lintasan Web3 yang diwakili oleh Gradients, yang membolehkan lebih banyak peserta menyertai pengoptimuman model melalui rangkaian terbuka dan mekanisme insentif, terus meningkatkan had atas dalam persaingan. Yang pertama adalah “membina sistem yang lebih kuat”, manakala yang kedua lebih seperti “membina rangkaian yang berubah sendiri”.
Dari sudut pandang ini, eksplorasi Gradients mewakili kemungkinan baru: pelatihan AI tidak lagi sekadar masalah teknis, tetapi gabungan dari “kekuatan komputasi + data + mekanisme pasaran”. Jika model ini berjaya, ia berpotensi menjadi pintu masuk untuk pelatihan AI terdesentralisasi dan memainkan peranan infrastruktur penting dalam ekosistem Bittensor. Tentu saja, arah ini masih memerlukan masa untuk diverifikasi, tetapi ia telah memberikan satu jalan evolusi berbeza untuk AutoML yang berbeza daripada laluan tradisional.
Rujukan
1. Dokumentasi Bittensor:https://docs.learnbittensor.org
2. Laman web Gradients:https://www.gradients.io/
3. Gradien: https://bittensormarketcap.com/subnets/56
4. Gradients X: https://x.com/gradients_ai
5. Taostats:https://taostats.io/subnets/56/chart