









Adakah kesan anda terhadap teks-ke-gambar masih berpaut pada Nano Banana?
Tetapi anakku, zaman telah berubah.

@johnAGI168 https://x.com/johnAGI168/status/2044781168151724067

@0115hippo https://x.com/0115hippo/status/2044722124611539160
Pada awal April, tiga model gambar anonim muncul di platform penilaian LM Arena, dengan kod nama maskingtape-alpha, packingtape-alpha, dan gaffertape-alpha. Mereka hilang beberapa jam kemudian.
OpenAI belum secara rasmi mengumumkan model ini, tetapi berdasarkan metadata yang dikembalikan oleh API dan rekod ujian di sisi pengguna, model ini telah memiliki nama yang diterima secara luas: GPT Image 2.

Screenshot tidak lagi boleh digunakan sebagai bukti
Dalam beberapa tahun terakhir, salah satu kelemahan paling jelas pada model gambar AI ialah teks dalam gambar. Pada era DALL-E 3, jika anda meminta ia menulis "Hello" dalam gambar, hasilnya mungkin "Hellp" atau bahkan "Hl10", dengan huruf-hurufnya bengkok seolah-olah mabuk. GPT Image 1 jauh lebih baik dan mampu menangani label bahasa Inggeris yang mudah. Pada GPT Image 1.5, ketepatan render teks bahasa Inggerisnya telah mendekati 95%, tetapi masih terdapat kelemahan jelas dalam sistem bukan Latin seperti Cina, Jepun, dan Korea.
Namun, gambar bocoran GPT Image 2 mengubah kesan ini.

@MrLarus https://x.com/MrLarus/status/2044824800909054181
@akokoi1 https://x.com/akokoi1/status/2044789531615056175
Teks dalam gambar, apa yang ada harus tetap seperti itu. Bahasa Cina jelas, bentuk huruf tepat, goresan penuh. Seseorang telah menguji menghasilkan gambar berformat kad pengenalan, nama, alamat, dan nombor kad semuanya dipaparkan dengan betul, susunan teratur, kelihatan seperti foto dokumen asli pada pandangan pertama.

Ini adalah berita baik. Kemajuan dalam pemprosesan teks bermakna penghasilan infografik, poster, pembungkusan produk, dan grafik dengan tata letak kompleks menjadi lebih boleh dipercayai.
Tetapi setiap koin mempunyai dua sisi. Model yang mampu menghasilkan gambar gaya dokumen palsu dan merender tangkapan layar UI secara tepat membuat perkara "tangkapan layar boleh dijadikan bukti" menjadi semakin meragukan.
Dari segi perbandingan, ini juga merupakan perbezaan utama antara siri GPT Image dan model-model lain. Midjourney masih belum berjaya dalam pemerataan teks, dan siri Stable Diffusion juga menghadapi masalah lama. Berdasarkan keputusan ujian Arena yang bocor, GPT Image 2 mengungguli Midjourney dalam empat aspek: pemerataan teks, pengikutan arahan, realisme foto, dan pengetahuan dunia, sementara kelebihan Midjourney masih terutama terletak pada gaya seni dan kawalan estetik.

Adakah ia benar-benar tahu bagaimana dunia ini kelihatan?
Seorang penguji meminta model untuk menghasilkan halaman penentuan harga produk GPT-8 fiksyen, dan gambar yang dihasilkan mempunyai gaya susunan yang sama seperti laman web rasmi OpenAI, kedudukan butang dan pilihan fon seolah-olah diambil daripada antaramuka sebenar, dan logik peringkat jadual harga juga betul.
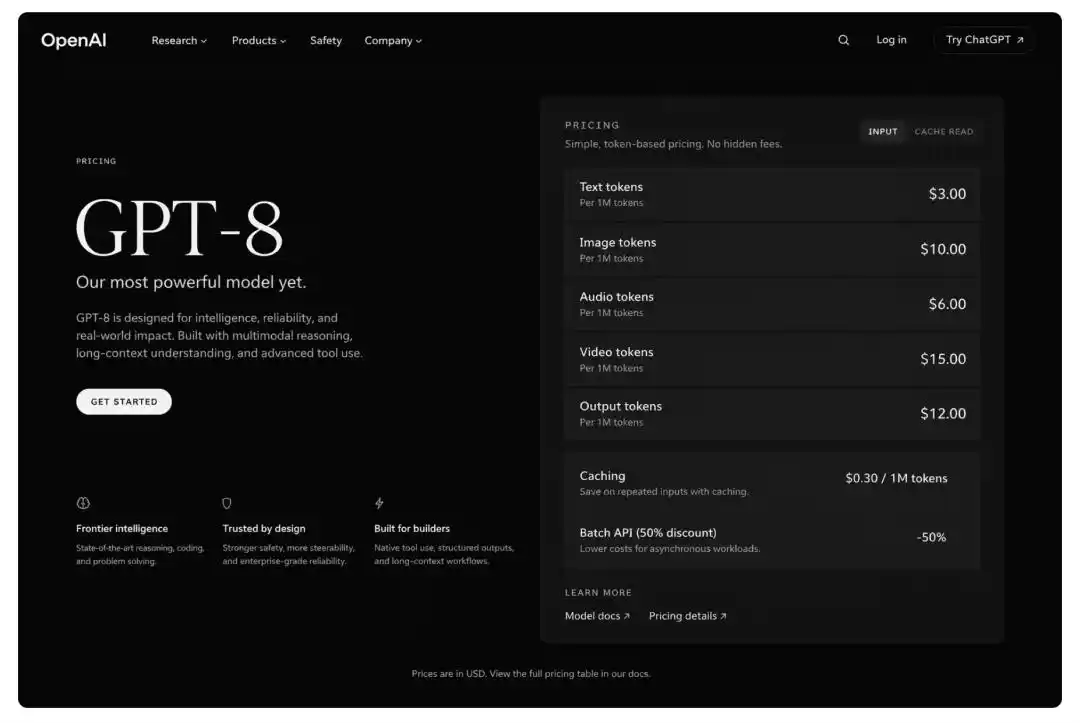
GPT Image 2 mampu menghasilkan gambar yang sangat serupa dengan antaramuka perisian sebenar, termasuk tetingkap browser, antaramuka aplikasi mudah alih, dan grafik visualisasi data, dengan ketepatan yang tidak dapat disamai oleh produk generasi sebelumnya.
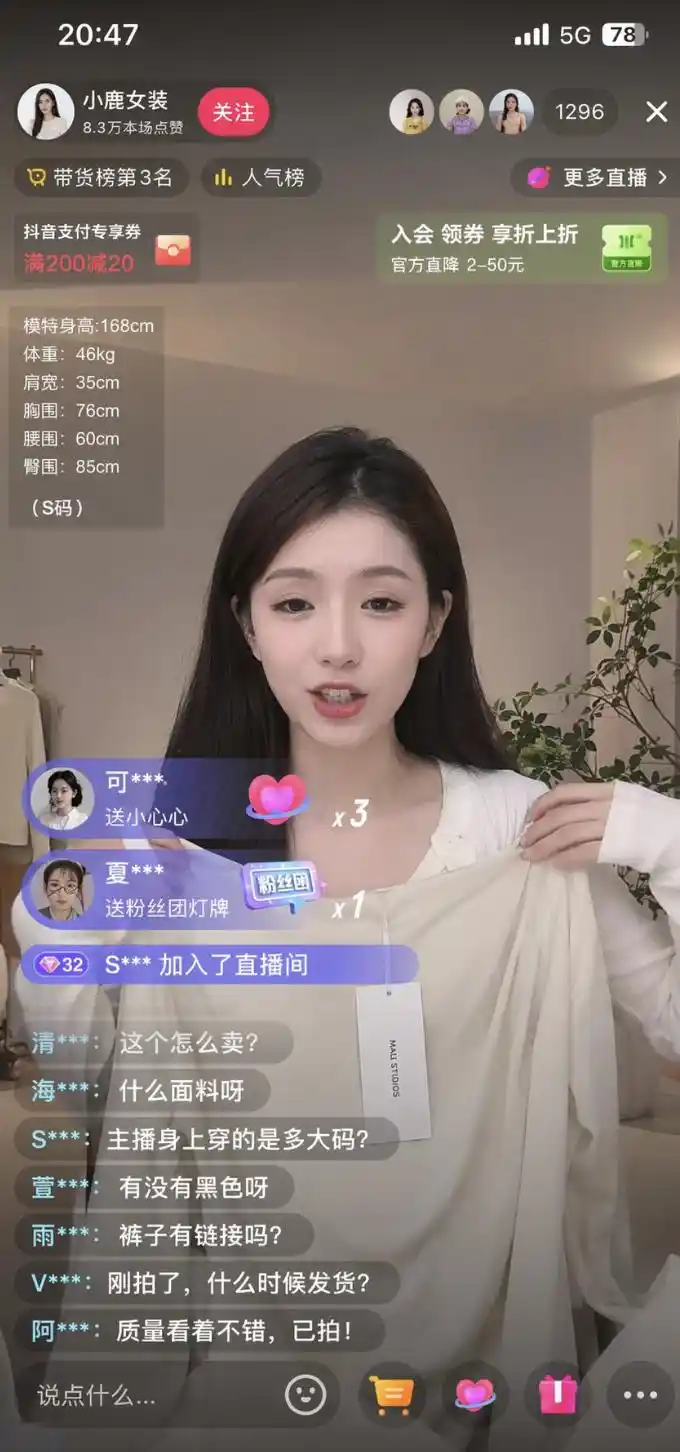
@johnAGI168 https://x.com/johnAGI168/status/2044781168151724067
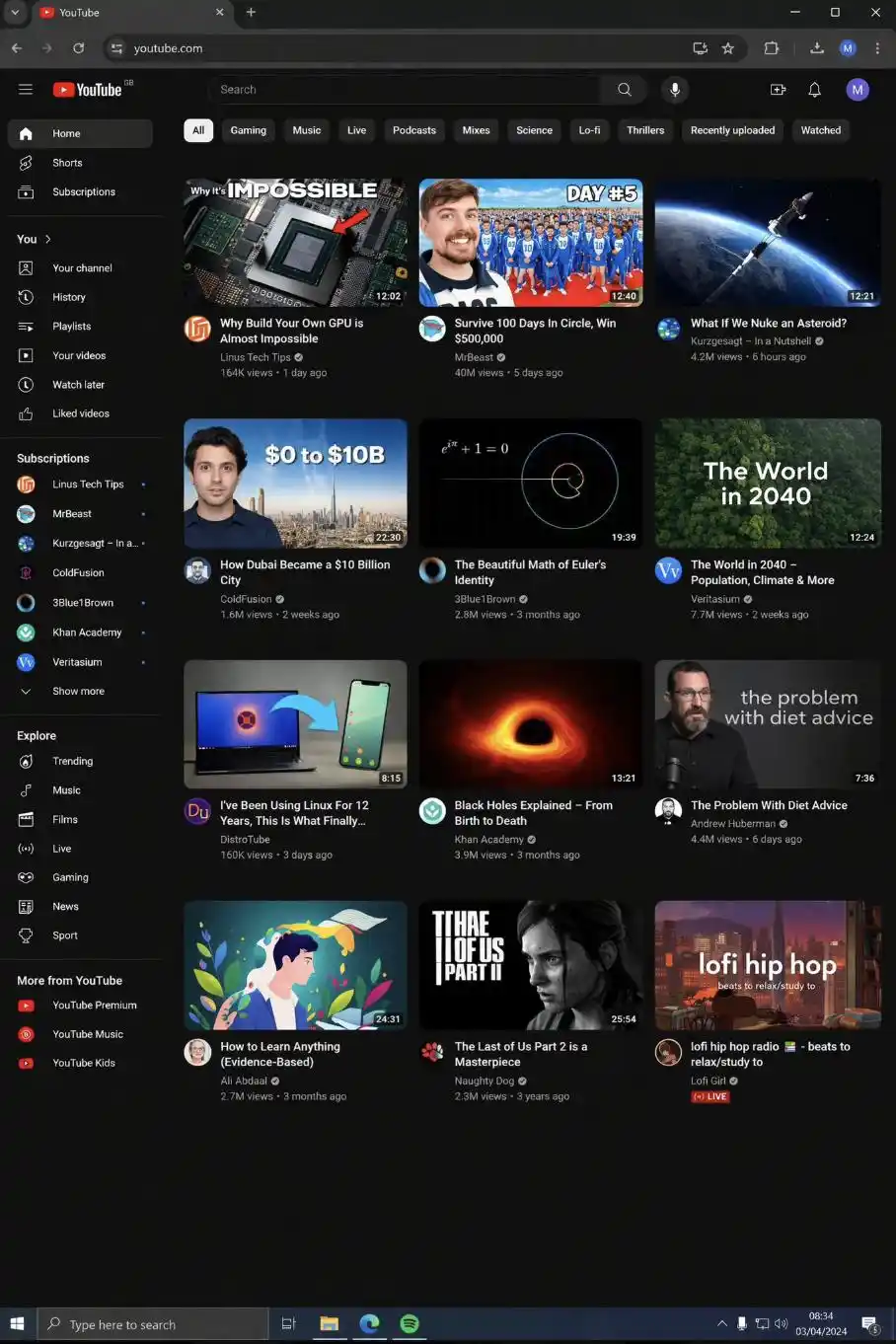
@levelsio https://x.com/levelsio/status/2040333489476681758
Ini akan membawa beberapa penggunaan praktikal yang menarik. Semasa merekabentuk prototaip produk, jururajah tidak perlu membuka Figma terlebih dahulu untuk melukis banyak kerangka; sebaliknya, mereka hanya perlu menggambarkan antaramuka yang diinginkan dengan teks, dan ia akan menghasilkan gambar rujukan yang boleh digunakan untuk perbincangan dengan pasukan. Semasa membuat Deck pelabur, anda tidak perlu menunggu jurutera menulis kod untuk menunjukkan “screenshot produk”. Semasa menulis dokumen, contoh antaramuka yang digunakan sebagai gambar boleh dihasilkan secara langsung, tanpa perlu memikirkan daripada mana untuk mencari screenshot.
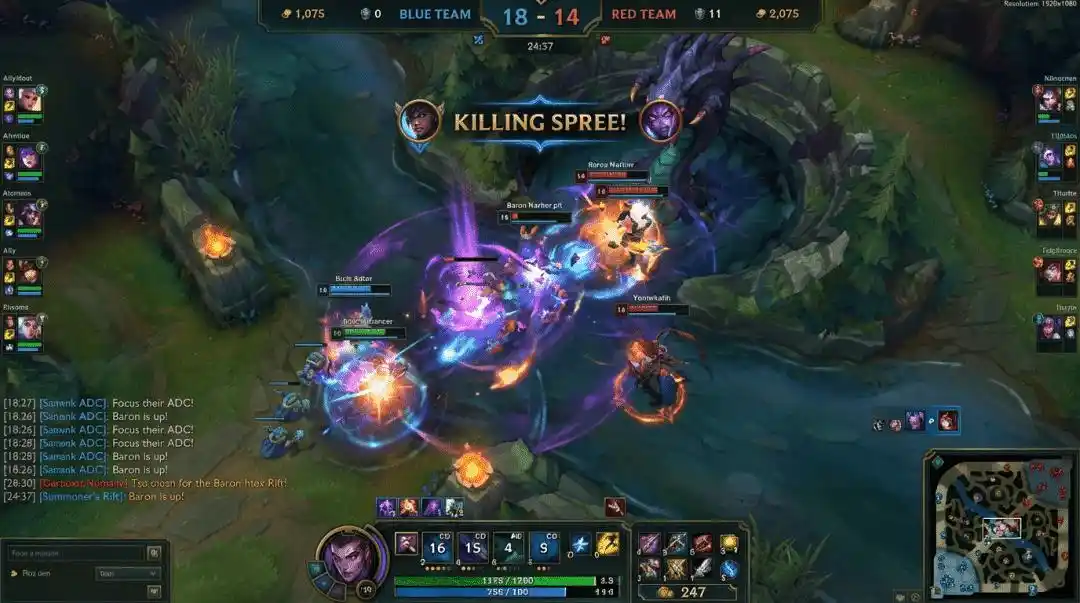

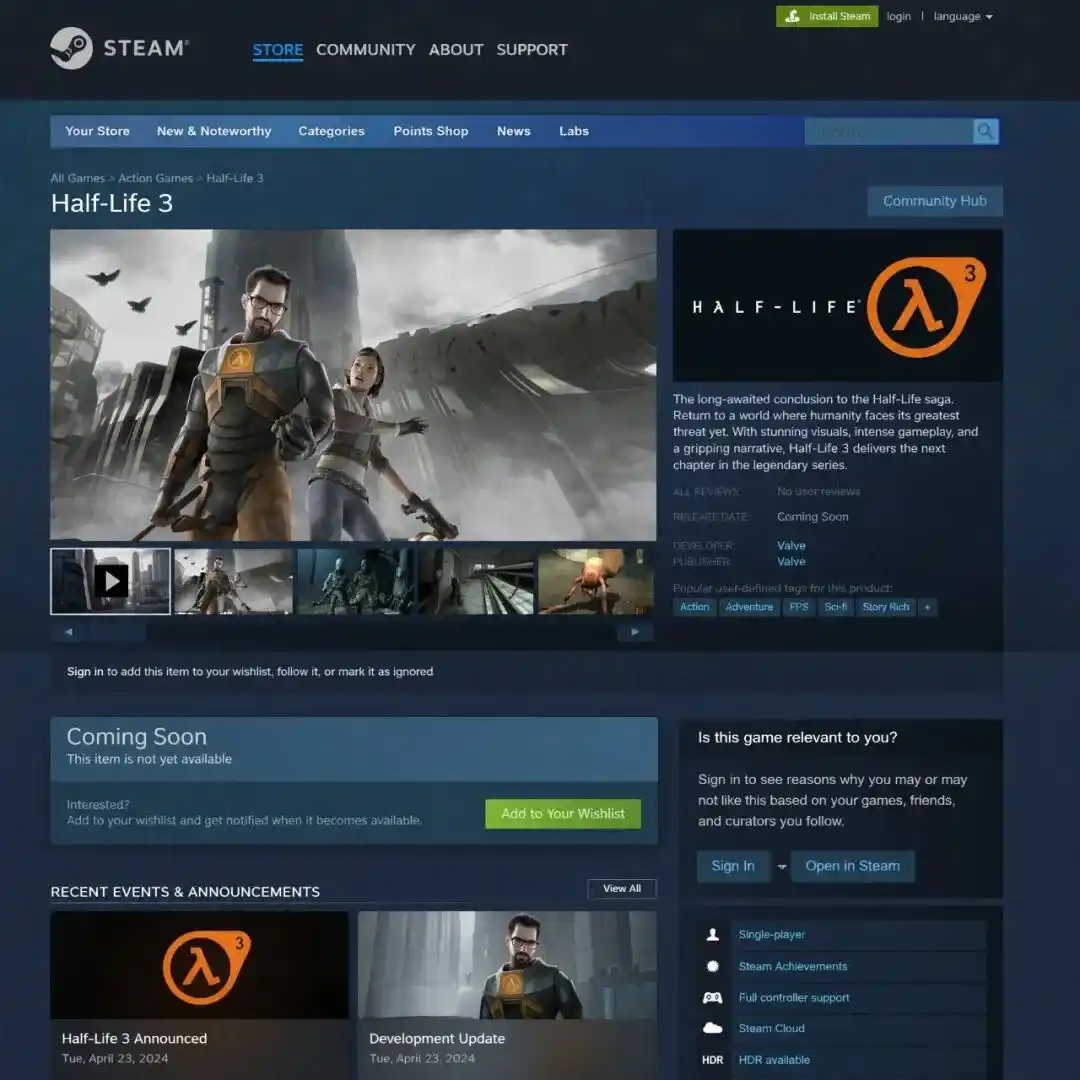
@marmaduke091 https://x.com/marmaduke091/status/2040338311873515597
Perkara menghasilkan gambar ini, sudah bukan sekadar "menghasilkan gambar" lagi
OpenAI telah mengumumkan bahawa DALL-E 2 dan DALL-E 3 akan dihentikan secara rasmi pada 12 Mei 2026. DALL-E 3 di Azure OpenAI telah diberhentikan lebih awal pada bulan Februari.
DALL-E adalah tempat pertama banyak orang mengenali AI untuk menghasilkan gambar, dan hanya dalam beberapa tahun sahaja, dari karya awal yang kabur hingga hari ini.
Sementara itu, Google, yang baru saja menetapkan kedudukannya dalam industri awal tahun 2026 dengan Nano Banana Pro, mungkin akan merasa tertekan. Laporan ujian awal menunjukkan bahawa GPT Image 2 mengatasi Nano Banana Pro secara serentak dalam tiga dimensi: realisme, penghasilan teks, dan pengetahuan dunia—kemenangan berturut-turut seperti ini tidak biasa.
Bagi pencipta, perasaannya adalah kompleks. Ilustrator, reka bentuk grafik, dan fotografer bukan kali pertama menghadapi topik ini. Sejak pelancaran GPT Image 1, bilangan jawatan reka bentuk grafik bebas telah menurun sebanyak kira-kira 18%. AI memang menggantikan keputusan "Saya perlu upah seseorang untuk melakukan ini" dalam beberapa senario, tetapi ia juga mencipta cara kerja baru yang membolehkan seseorang melakukan lebih banyak perkara.
Kecepatan evolusi model gambar generatif sudah tidak lagi memberi masa yang banyak untuk penyesuaian. Dari pelancaran GPT Image 1 hingga 1.5, cuma beberapa bulan sahaja. Dari 1.5 hingga 2, kira-kira separuh tahun. Setiap generasi menyelesaikan kelemahan utama generasi sebelumnya, sambil membuka kemungkinan baru.
GPT Image 2 masih berada dalam peringkat ujian A/B, dan sebahagian pengguna ChatGPT telah diberi akses secara rawak. Jendela pelancaran rasmi dijangka berlaku pada Mei, sekitar masa DALL-E ditarik balik. Jika anda ingin mencuba lebih awal, anda boleh mencuba keberuntungan anda di platform penilaian LM Arena sekarang.

Alamat Ujian: https://arena.ai
Berdasarkan maklum balas komuniti dan kelebihan yang diketahui pada model ini, templat petunjuk berikut boleh memaksimumkan peluang kejayaan anda:
UI/ Petunjuk tangkapan layar: Tangkapan layar aplikasi perbankan telefon yang realistik, menunjukkan rekod transaksi dengan jelas, di mana tarikh, jumlah, dan nama pedagang boleh dikenal pasti. Skrin iPhone 16, telefon dipegang secara semula jadi, latar belakang kedai kopi.
Petunjuk label produk: Gambar produk botol bir buatan tangan secara fotografi, butiran label jelas, menunjukkan nama pabrik bir «Oakridge Brewing Co.», kandungan alkohol 6.8%, tanda gunung, dan senarai bahan. Pencahayaan di dalam bangunan, latar belakang putih.
Petunjuk identiti: Gambar pemandangan jalan malam di Tokyo, menunjukkan pelbagai papan iklan neon dwibahasa Jepun-Inggeris, termasuk papan tanda restoran ramen yang bertulis 'Ichiban Ramen — Est. 1987', papan tanda bar karaoke, dan pelbagai papan iklan bercahaya. Jalan pejalan kaki yang licin selepas hujan memantulkan cahaya.
Petunjuk antaramuka/dunia: Screenshot video YouTube yang realistik seperti foto, menunjukkan video berjudul "Cara Membina Komputer Pada Tahun 2026" dengan 2.3 juta tontonan, dilengkapi ruang komen yang realistik, video cadangan sisi, dan maklumat saluran. Pemandangan browser desktop.
Pemberitahuan skrin lebar: Ini adalah gambar skrin lebar bergaya filem, menunjukkan rupa luar kedai IKEA pada waktu senja, dengan tanda IKEA yang bercahaya, kereta yang realistik di tempat letak kereta, serta pembeli yang datang dan pergi. Pencahayaan masa emas, format 16:9.
Sumber gambar dan rujukan tidak dinyatakan: https://miraflow.ai/blog/how-to-use-duct-tape-ai-model-arena-gpt-image-2-guide
Artikel ini berasal daripada akaun微信公众号 "APPSO", penulis: Menemui produk masa depan