









Penyesuaian harga oleh DeepSeek ini, dengan penurunan tajam secara tak linear, secara paksa membawa industri ke sebuah era kos baru.
Penulis artikel, sumber: 0x9999in1, ME News
TL;DR
- Harga menembus garis dasar: Pada akhir April 2026, DeepSeek menurunkan harga output model V4-Pro menjadi $0.878 per juta Token melalui penggabungan diskaun terhadap masa terhad dan penurunan harga cache, dengan harga input yang mencapai cache hanya $0.0037 (sekitar RM0.025), secara menyeluruh menghancurkan titik rujukan harga industri model besar.
- Harga di China dan AS menunjukkan "jurang": Berbanding dengan pengeluar terkemuka global, kos penggunaan API DeepSeek-V4-Pro hanyalah sekitar satu-tigapuluh daripada OpenAI GPT-5.5 dan Anthropic Claude Opus 4.7, membentuk perbezaan kos yang sangat ketara.
- Tekanan terhadap struktur persaingan domestik: Di bawah penetapan harga agresif DeepSeek, model utama domestik seperti Zhipu GLM 5.1 dan Moonshot Kimi K2.6 menghadapi tekanan komersial yang besar, dan mungkin terpaksa mengikuti penurunan harga, mempercepat laju pembersihan industri.
- “Cache hit” menjadi ekonomi inti: DeepSeek menurunkan harga cache hit menjadi sepersepuluh dari harga asal, strategi ini secara mendasar sangat menguntungkan untuk skenario pemrosesan teks panjang, RAG (Retrieval-Augmented Generation), dan interaksi berulang berkelanjutan agen.
- Kesimpulan analisis think tank: Model dasar sedang mempercepat "infrastrukturasi seperti air dan listrik", dan fokus persaingan masa depan akan beralih sepenuhnya dari pertarungan ukuran parameter model tunggal kepada kemampuan mengoptimumkan kos inferens dan penguasaan ekosistem pembangun.
Pengenalan: Masa titik pelik dalam kos pengiraan model besar
Perkembangan teknologi sering kali disertai dengan penurunan kos secara eksponen, yang merupakan langkah tak terelakkan bagi sebarang teknologi revolusioner untuk mencapai penggunaan meluas. Pada 25 hingga 26 April 2026, industri AI menyaksikan satu momen yang sangat bersejarah: pengeluar model besar terkemuka, DeepSeek, melepaskan dua "bom dalam air" berturut-turut. Pertama, mereka mengumumkan promosi pantas selama masa terhad sebanyak 2.5 peratus untuk API model DeepSeek-V4-Pro; kemudian, mereka mengumumkan bahawa harga untuk cache input dalam keseluruhan rangkaian perkhidmatan API diturunkan secara langsung kepada 1/10 daripada harga asal.
Selepas dua rundingan strategi penyesuaian harga berturut-turut, harga cache masukan untuk DeepSeek-V4-Flash telah jatuh kepada angka menakjubkan 0.0029 dolar AS (kira-kira 0.02 yuan China) setiap sejuta token, manakala harga cache masukan untuk DeepSeek-V4-Pro yang dibandingkan dengan tahap teratas global hanya 0.0037 dolar AS (kira-kira 0.025 yuan China).
Sebelum ini, industri secara umum meramalkan kos inferens model besar akan menurun pada kadar sekitar 50% setiap tahun, tetapi penyesuaian harga kali ini oleh DeepSeek membawa penurunan tajam secara tak linear, memaksa industri memasuki era kos yang baru. Kami percaya, ini bukan sekadar aktiviti pemasaran biasa atau “perang harga” jangka pendek, tetapi hasil yang tak terelakkan daripada pengoptimuman arsitektur algoritma asas (seperti mekanisme perhatian jarang, perkembangan arsitektur MoE yang ekstrem) serta peningkatan kemampuan kejuruteraan kluster komputasi. Laporan ini akan menganalisis secara mendalam gangguan industri yang disebabkan oleh penurunan harga DeepSeek berdasarkan data harga terkini keseluruhan industri, serta membandingkan secara lintas negara daya saing komersial model besar utama global, bagi memberikan peta jalan evolusi industri yang jelas kepada pihak pengambil keputusan.
Fenomena utama: Tembusan sempadan sistem harga siri DeepSeek-V4
Untuk memahami kekuatan penurunan harga ini, kita perlu menganalisis tiga dimensi utama penagihan API model besar: harga input (tidak tercakup dalam cache), harga input (tercakup dalam cache), dan harga output. Model penagihan sebelumnya biasanya hanya membezakan antara input dan output, tetapi dengan kematangan teknologi konteks panjang (Long-Context), " kadar kejayaan cache (Cache Hit) " sedang menjadi pemboleh ubah kunci yang membentuk semula ekonomi API.
Analisis strategi penentuan harga: Penambahan diskaun dan leverage cache
Berdasarkan data terkini yang diumumkan, DeepSeek mengambil strategi tiga langkah: penurunan harga dasar, diskaun terhadap masa, dan leverage pengekalan.
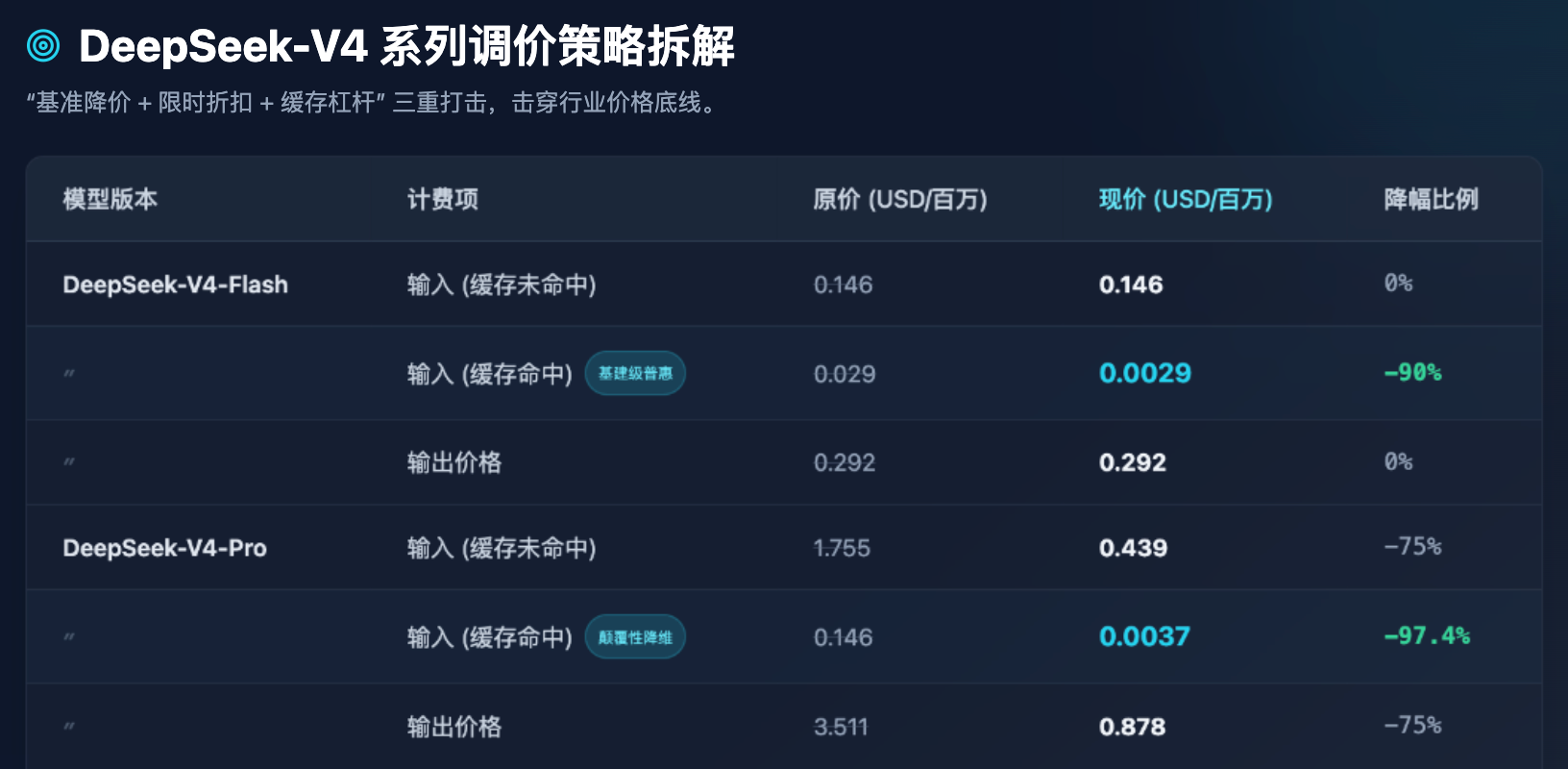
Jadual 1: Perbandingan sebelum dan selepas penyesuaian harga API terkini siri DeepSeek-V4 (unit: dolar per juta Token)
Dari Jadual 1, kita boleh menarik beberapa pemerhatian industri yang sangat jelas:
Pertama, pemerkasaan model Flash telah mencapai paras terendah. Bagi model Flash yang menonjolkan keupayaan tinggi dan latensi rendah, harga outputnya kekal pada $0.292 per juta Token, yang sudah sangat dekat dengan garis bawah kos keras kuasa pengkomputeran pelayan. DeepSeek tidak mempermainkan harga asas Flash, tetapi dengan bijak mengurangkan harga "cache hit" sebanyak 90%. Ini bermakna, semasa mengendalikan banyak petunjuk sistem (System Prompt) yang berulang atau soal jawab dokumen tetap, kos model Flash hampir boleh diabaikan.
Kedua, penurunan harga model Pro. Sebagai model unggulan yang sepadan dengan kelas teratas global (seperti GPT-5), harga output V4-Pro turun drastis dari $3.511 menjadi $0.878. Lebih ekstrem lagi, harga input cache hit yang sebelumnya $0.146, setelah digabungkan dengan diskon sementara 25% dan penurunan harga 1/10, langsung turun menjadi $0.0037. Ini adalah angka yang sangat menakjubkan—artinya biaya untuk memanggil kecerdasan teratas dunia kini telah ditekan hingga tingkat yang memungkinkan usaha kecil menengah bahkan pengembang perorangan untuk memanggilnya secara frekuensi tinggi tanpa ragu.
Ketiga, memaksa pengembang untuk mengoptimumkan kejuruteraan Prompt. Menetapkan harga yang berjaya dipanggil dari cache sebagai satu perpuluhan beberapa daripada harga yang gagal dipanggil (contohnya, dalam model Pro, $0.0037 berbanding $0.439, perbezaan sekitar 118 kali), ini bukan sahaja strategi penentuan harga, tetapi juga cara untuk membimbing ekosistem teknikal melalui pendekatan perniagaan. DeepSeek secara jelas memberitahu pengembang: sekiranya struktur anda direka dengan baik (contohnya, konteks panjang tetap di depan, dan soalan pendek yang berubah di belakang), anda akan menikmati kuasa pengiraan input yang hampir percuma.
Perbandingan mendatar: Perbezaan tajam dalam penetapan harga model besar global dan tempatan
Hanya membandingkan penurunan harga DeepSeek secara vertikal tidak cukup untuk melihat gambaran keseluruhan; apabila kita menempatkannya dalam kerangka pasaran model besar global tahun 2026, perbezaan “terputus” yang diciptakan oleh strategi penetapan harga ini benar-benar membuat bulu roma berdiri.
Berdasarkan OpenRouter dan maklumat awam daripada pelbagai pihak, kami telah menghimpun data harga API terkini bagi 9 model besar domestik dan antarabangsa yang paling mewakili di pasaran semasa ini.

Jadual 2: Perbandingan harga API model besar utama global pada 2026 (unit: dolar AS / juta Token)
Menghadapi raksasa global: Menghancurkan mitos "kecerdasan tinggi dan premium tinggi"
Dalam naratif AI dua tahun terakhir, OpenAI dan Anthropic telah mengekalkan satu perjanjian diam-diam: model paling pintar sepatutnya menikmati margin keuntungan tertinggi. Kini, harga output GPT-5.5 dan Claude Opus 4.7 masing-masing mencapai $30 dan $25 per juta Token. Dua raksasa Silicon Valley ini cuba mengekalkan cukai komputasi yang tinggi dengan memonopoli kemampuan penalaran paling terkemuka.
Namun, kehadiran DeepSeek-V4-Pro dan harga outputnya sebanyak 0.878 dolar AS secara langsung menembus lapisan kertas jendela ini. Andaikan V4-Pro mampu mencapai atau mendekati tahap GPT-5.5 dalam semua ujian piawai (Benchmarks) dan pengalaman sebenar, maka perbezaan harga output sebanyak 34 kali ganda antara keduanya akan menghancurkan sepenuhnya logik premium raksasa luar negara di pasaran B2B.
「ME News智库」 mengira, bagi sebuah perusahaan yang sangat bergantung pada kandungan yang dihasilkan AI, jika menghabiskan 1 miliar token output setiap bulan, kos tetap menggunakan GPT-5.5 ialah US$30,000; tetapi apabila beralih ke DeepSeek-V4-Pro, kos ini akan turun drastik kepada US$878. Perbezaan kos pada skala ini cukup untuk mempengaruhi kelangsungan hidup sebuah perusahaan rintisan. Ini menunjukkan bahawa perusahaan AI China telah mengambil jalan yang berbeza sepenuhnya dari Silicon Valley dalam hal kecekapan latihan model asas dan pengoptimuman kluster inferens, dengan menekankan kedua-dua "estetik kekerasan" dan "kejuruteraan ekstrem".
Menggempur rakan seindustry tempatan: Mempercepatkan pembersihan besar-besaran industri
Jika DeepSeek merupakan serangan menurunkan dimensi terhadap raksasa luar negara, maka terhadap rakan seindustry tempatan, ia merupakan permainan nol-sum yang kejam.
Daripada Jadual 2, boleh dilihat bahawa pengeluar terkemuka tempatan seperti Zhipu (GLM 5.1, output $4.40) dan Moonshot (Kimi K2.6, output $4.00) berada dalam situasi yang memalukan dari segi penetapan harga. Harga-harga ini beberapa bulan yang lalu dianggap “wajar dan bernilai baik”, tetapi di hadapan DeepSeek-V4-Pro (output $0.878), mereka segera kehilangan semua pertahanan harga. Bahkan Alibaba Cloud, yang selama ini dikenal kerana sifat open-source dan harga rendahnya (Qwen3.6 Plus, output $1.96), kini tidak lagi kelihatan “murah”.
Di medan pertempuran model Flash ringan, pertarungan juga sengit. Step 3.5 Flash daripada Jieyue Xingchen mempunyai input serendah $0.028 dan output hanya $0.299, berdekat rapat dengan DeepSeek-V4-Flash (output $0.292). Ini menunjukkan bahawa dalam bidang model ringan, tekanan terhadap kos pengiraan telah mencapai tahap nanometer, dengan semua pihak terbang tepat di atas garis kos.
Secara keseluruhan, DeepSeek sebenarnya menggunakan kemampuan tingkat Pro untuk menyerang harga pesaing domestik versi Plus bahkan versi standar; sementara menggunakan harga tingkat Flash untuk menarik semua arus lalu lintas panjang dengan kepadatan nilai rendah dalam jumlah besar. Taktik “penguncian dua sisi” ini secara besar-besaran mempersempit ruang hidup perusahaan model besar lainnya, dan perlombaan penghapusan model AI domestik akan dipercepat setelah penurunan harga ini.
Penglihatan Mendalam: Teknologi dan Logik Perniagaan di Sebalik Harga Paling Rendah
Harga rendah yang tidak berasaskan asas tidak boleh dipertahankan. DeepSeek berani menerapkan strategi penurunan harga yang begitu tegas pada tahun 2026 kerana didukung oleh sokongan teknikal yang mendalam dan hasrat perniagaan yang sangat ambisius.
Logik teknikal: Dari "Kekuatan Membuat Bata Terbang" ke "Kemenangan Melalui Arsitektur"
Penurunan tajam harga pada dasarnya adalah pelepasan manfaat dari perkembangan arsitektur teknikal.
- Manfaat mendalam dari arsitektur MoE (Mixture of Experts): Berbeza dengan model padat besar awal OpenAI, model canggih semasa ini secara umum menggunakan arsitektur MoE yang sangat dioptimalkan. DeepSeek sangat mungkin mengurangkan nisbah parameter yang diaktifkan dalam arsitektur V4. Ini bermakna walaupun jumlah parameter besar, hanya sebahagian kecil “pakar” yang dinyalakan semasa setiap inferens, dengan begitu mengurangkan secara ketara jumlah pengiraan (FLOPs) dan tekanan bandwidth memori grafik untuk setiap panggilan.
- Terobosan revolusioner dalam pengurusan KV Cache: Kelebihan utama dalam penyesuaian harga ini ialah "kejadian cache input berkurang hingga 1/10". Dalam arsitektur Transformer, bottleneck utama dalam inferensi teks panjang bukanlah pengiraan, tetapi penggunaan memori grafik yang besar oleh KV Cache yang menyimpan maklumat konteks. DeepSeek jelas telah mencapai teknologi penggabungan KV Cache secara global dan antar-permintaan pada peringkat sistem (contohnya, versi peningkatan teknologi RadixAttention). Apabila banyak permintaan serentak pengguna mengandungi tetapan sistem atau perpustakaan pengetahuan latar belakang yang sama, model tidak perlu mengira semula Token-token ini, tetapi boleh membaca secara langsung dari memori atau kolam memori grafik teragih. Ini menjadikan kos marjinal "input teks panjang" mendekati sifar.
Logik perniagaan: Menukar keuntungan untuk ruang, membentuk semula parit ekosistem
「ME News智库」percaya bahawa strategi diskaun terhad dan harga asas DeepSeek mempunyai tujuan perniagaan yang jelas dan tegas:
Pertama, hancurkan sepenuhnya ekosistem "fine-tuning berpura-pura", memaksa aplikasi asli AI meledak. Apabila kos pemanggilan model asas paling kuat mendekati percuma, para usahawan tidak lagi bermakna secara ekonomi untuk menghabiskan dana besar dalam melatih atau menyesuaikan model kecil industri mereka sendiri. DeepSeek melalui harga rendah, cuba menarik semua pembangun AI di seluruh masyarakat ke dalam ekosistem API-nya, menjadikannya seperti "infrastruktur asas AI" seperti Amazon AWS atau Microsoft Azure.
Kedua, fajar kebangkitan agen penempatan. Aplikasi agen sejati memerlukan model melakukan pemikiran, refleksi, perancangan, dan pemanggilan berulang (Loop) dalam jumlah besar. Proses ini menghasilkan penggunaan token tersirat yang sangat besar. API yang mahal merupakan rintangan terbesar dalam penerapan agen. DeepSeek dengan menurunkan harga keberhasilan cache ke $0.0037 sebenarnya memberikan kelayakan ekonomi bagi “membiarkan AI berjalan sepuluh ribu putaran”. Siapa yang menyediakan kos percubaan paling murah, dialah yang akan memupuk aplikasi super berasaskan AI paling hebat.
Dampak industri dan analisis tren: Dari "perang model" ke "perang ekosistem"
Untuk menunjukkan kesan perubahan harga terhadap keputusan perusahaan secara lebih intuitif, kami menjalankan simulasi kos aplikasi perusahaan.
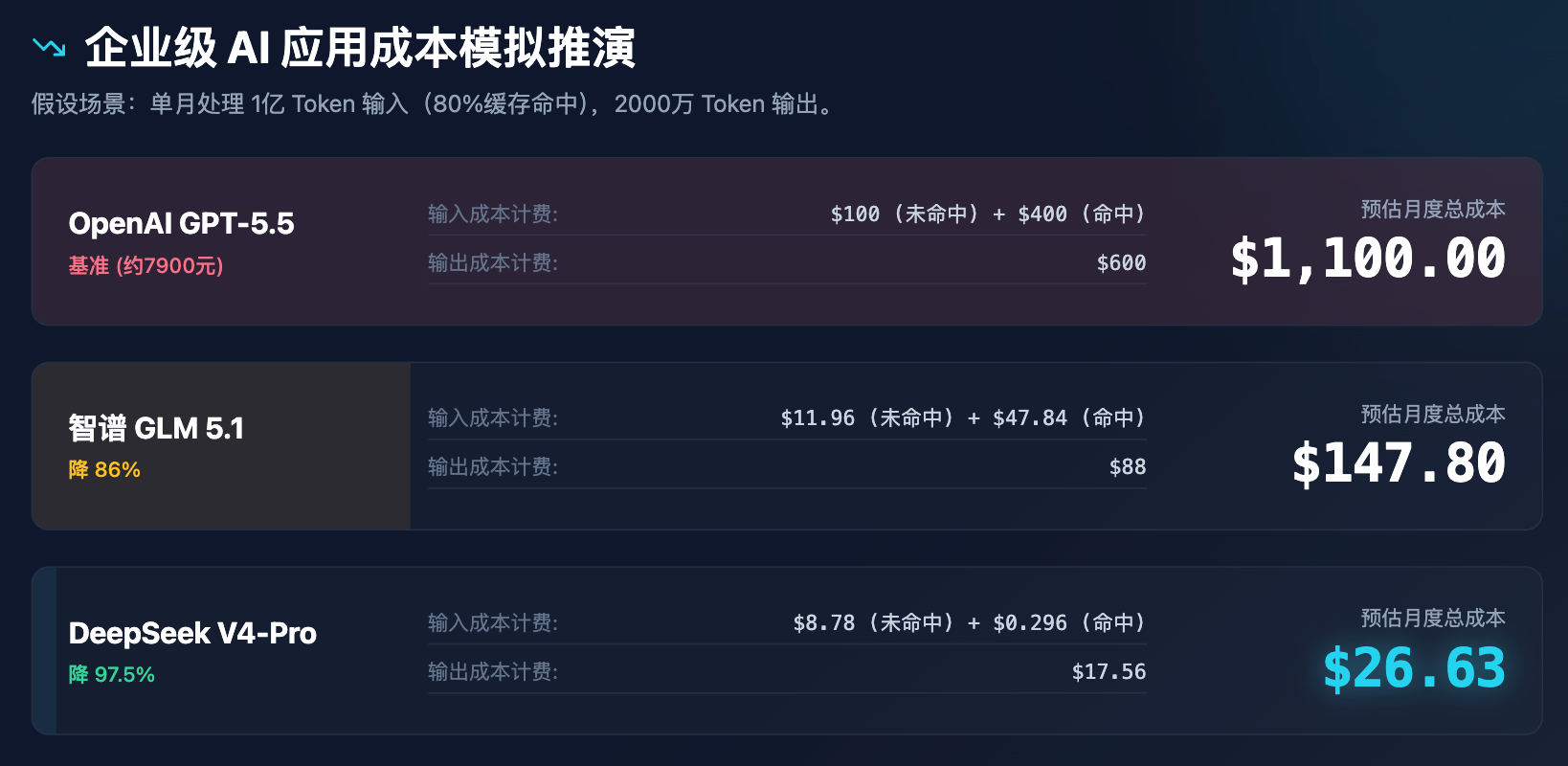
Jadual 3: Analisis simulasi kos aplikasi AI perniagaan (mengandaikan pemprosesan 100 juta token input dan 20 juta token output sebulan)
Melalui simulasi di atas, jelas bahawa penentuan harga DeepSeek bukan sekadar diskon, tetapi lebih kepada membina semula model kos. Dengan kos kurang daripada US$30 sebulan, ia mampu memenuhi semua keperluan bantuan perkhidmatan pelanggan, penyelesaian dokumen, dan pemeriksaan kod untuk sebuah perusahaan sederhana, yang pasti akan memicu siri tindakan berterusan:
- Perubahan mendasar dalam logik pelaburan AI: modal akan kehilangan minat sepenuhnya terhadap “mencipta semula model besar generik”. Kecuali untuk beberapa pihak negara atau raksasa internet, pintu model besar asas generik telah dilas tetap. Pelaburan masa depan akan mengalir sepenuhnya ke lapisan aplikasi (Application Layer) dan perantara infrastruktur (router infrastruktur, AI gateway, dll).
- Strategi penghalaan model pelbagai (LLM Routing) menjadi piawai: syarikat tidak lagi bergantung pada model tunggal. Sistem akan secara automatik menghantar berdasarkan kekompleksan tugas. Sebagai contoh, 90% pembersihan data harian dan pengelasan ringan akan diselesaikan oleh DeepSeek-V4-Flash atau Step 3.5 Flash dengan kos yang sangat rendah; 10% penalaran logik kompleks dan penghasilan laporan pengurusan tinggi akan memanggil DeepSeek-V4-Pro atau GPT-5.5 mengikut keperluan.
- Aplikasi teks panjang mencapai titik balik komersial sejati: sebelum ini, “menghantar laporan keuangan berjuta-juta perkataan untuk AI ringkaskan” walaupun kedengaran menarik, tetapi kos API yang setiap kali mencapai beberapa dolar membuat syarikat B2B berfikir dua kali. Dengan harga kejayaan cache input diturunkan kepada tahap 0.02 yuan China per juta Token, “membaca seluruh dokumen perpustakaan dan berinteraksi secara masa nyata” akan menjadi fungsi piawai bagi semua perisian OA dan ERP syarikat.
Kesimpulan dan Cadangan Strategi
Badai penurunan harga pada April 2026 menandakan penghujung era romantik klasik industri model besar, di mana para pemain bersaing melalui parameter dan skor ujian, dan memasuki era industri yang kejam, di mana persaingan berfokus pada kos, kuasa pengiraan, dan penguasaan ekosistem. DeepSeek melalui strategi penetapan harga yang agresif tidak hanya memperlihatkan keahlian mendalam perusahaan AI China dalam kejuruteraan model kepada dunia, tetapi juga secara aktif menembus gelembung premium kuasa pengiraan AI.
Untuk ini, "ME News Think Tank" mempunyai tiga cadangan:
- Untuk pembangun peringkat aplikasi: Tinggalkan ketakutan terhadap kos panggilan model besar. Berhenti segera membina dan menyesuaikan model asas dengan parameter di bawah sepuluh miliar, dan arahkan semua sumber daya pembangunan kepada pengalaman produk, penyesuaian sisi hujung, pembinaan rintangan data khas, serta penyempurnaan alur kerja Agent. Manfaatkan keuntungan “kuasa pengiraan pintar yang murah” ini untuk dengan cepat menguasai skenario.
- Untuk CIO/CTO perusahaan tradisional: Semak semula strategi AI perusahaan. Projek-projek seperti soal jawab pengetahuan, perkhidmatan pelanggan automatik, dan Code Copilot yang sebelumnya dihentikan kerana pertimbangan kos kini memiliki ROI (pulangan pelaburan) yang sangat tinggi di bawah harga API semasa. Disarankan untuk memperkenalkan platform LLMOps yang matang dan membina gateway AI perusahaan supaya boleh menghubungkan model-model paling berkesan dari segi kos secara fleksibel.
- Untuk rakan seindustry model asas: harus meninggalkan strategi mengikuti. Di hadapan perang harga, either melalui pengoptimuman sinergi cip-kerangka yang lebih ekstrem untuk menurunkan kos, atau membina rintangan teknikal yang tidak boleh digantikan di bidang perbezaan seperti kecerdasan badani, multimodal asli (penghasilan video/3D), dan penalaran logik mendalam industri tegak. Model bahasa besar semata-mata telah menjadi biasa dan tidak lagi mempunyai jalan keluar.
Model besar bukan lagi dewa yang dipuja di laboratorium; ia sedang turun dari takhta dengan kelajuan yang belum pernah terjadi sebelumnya, berubah menjadi arus besar yang menggerakkan kecerdasan segala sesuatu. Dan semua ini baru saja bermula.
Sumber rujukan:
- OpenRouter. (2026). Database Perbandingan Harga API.
- Pengumuman Rasmi DeepSeek. (2026, 25 April). Rancangan Promosi Terhad untuk API DeepSeek-V4-Pro.
- Pengumuman Rasmi DeepSeek. (2026, 26 April). Keupayaan Akses Mudah di Era Model Besar: Skema Penyesuaian Harga Pemenuhan Cache API Global.